您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“函数式编程处理树结构数据的方法”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“函数式编程处理树结构数据的方法”吧!
在学习完函数式编程的思考方法之后,尝试一下更高级的例子吧。这次考虑一下处理类似于XML的树结构数据的程序。既不使用循环也不使用变量如何来描述复杂的处理呢?
先出一个处理XML数据的题目。例如有如下的XML数据,有目录和文件,目录下有目录和文件两种元素。
< xml> < dir name="com"> < dir name="mamezou"> < file name="aaa.txt">< /file> < file name="bbb.txt">< /file> < /dir> < file name="ccc.txt">< /file> < /dir> < file name="ddd.txt">< /file> < /xml>
题目的内容是从中取出文件的部分,并打印出文件名。程序的执行结果因该如下:
file:aaa.txt file:bbb.txt file:ccc.txt file:ddd.txt
好,会变成怎样的程序呢?另外,Scala有非常强大的XML处理功能,以上的功能实际上只要一两行程序就可以完成了。但是这次为了说明函数式编程,特地不使用哪些功能,而使用简单功能来从头开始编码。
Scala中XML语句可以作为语言文本(Literal)像数字和字符串一样被处理。像下面这样
scala> val xml = < xml> | < dir name="com"> | < dir name="mamezou"> | < file name="aaa.txt">< /file> | < file name="bbb.txt">< /file> | < /dir> | < file name="ccc.txt">< /file> | < /dir> | < file name="ddd.txt">< /file> | < /xml> xml: scala.xml.Elem = < xml> < dir name="com"> :(以下略)
没有双引号,一开始就写XML文本,然后将其赋值给变量(这里是xml)。他的类型是scala.xml.Elem,父类型为scala.xml.Node,表示XML的标记。在这里包含在< xml>< /xml>标记对中的内容被绑定在变量xml上。该Node类型里有名为child的方法,返回该标记的所有子元素。例如,这里xml.child将返回以如下两个标记为成员的类似于ArrayBuffer的数组对象。
< dir name="com"> : < /dir>
和
< file name="ddd.txt"/>
这里可以认为ArrayBuffer是列表一样的东西。进一步调用子元素的child方法则可以得到再下一层的元素。调用。< dir name="com">标签对象的child方法将返回紧邻该标签的子元素(目录标记)。
仅使用这个方法该如何写取得文件名的程序呢?如果是面向对象方式,则可以首先定义Dir类和File类,然后定义Dir和File类的抽象父类Node,然后沿着树结构定义showFiles方法,然后递归调用该方法来取得文件名。也就是所谓的组合模式(图1)。
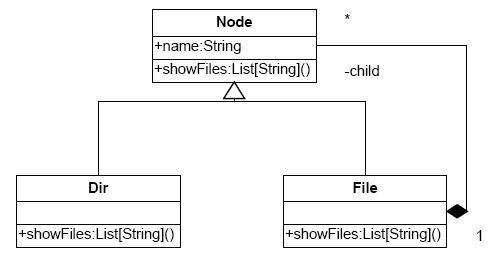
Scala讲座 图1:组合模式
如果放弃面向对象而考虑纯粹的命令式方法的话就会很头疼了。因为只用for语句的话,对于每一个Dir都要用一个for循环,层次一多将会将会变得很复杂,这里省略了命令式方法的实现。
接下来用函数式方法来考虑一下。函数式的情况下,因为考虑的是对于各个元素应用函数,先从***元素开始考虑应用什么函数。这个函数功能是“在某一时刻返回某一元素下的文件列表”。这样就可以想到,那元素如果是file则可直接返回包含该file的列表,如果是Dir的话则返回包含所有子文件的列表。先来看看该函数的实例。
def fileFinder(node:scala.xml.Node):List[scala.xml.Node] = node.label match { case "xml" => node.child.toList.flatMap(fileFinder) case "dir" => node.child.toList.flatMap(fileFinder) case "file" => List(node) case _ => List() }其中toList()方法为将类列表对象(ArrayBuffer)转换为列表对象。刚才用的是类似于ArrayBuffer类的对象,这里将其转换为标准列表后再操作,而node.label则返回XML标记的名称。
这里开始是正题了,除了file和无匹配处理(case _ => List())部分,xml和dir处理部分是问题的关键,也就是node.child.toList.flatMap(fileFinder)部分。如果这里关注的是Node对象,那处理过程因该是这样的,首先用child方法取出Node的所有子元素,然后用前面说明过的类似于map的函数对每一个子元素应用fileFinder方法并递归重复这一过程。那为什么这样编码之后就能得到Node下的所有file元素了呢?
那么flatMap原本的功能又是什么呢?让我们将其转换成map函数,然后看一下执行过程。将XML的结构简单化之后将如下所示
< xml> ←这里 < dir> < dir> < file name="aaa.txt"/> < file name="bbb.txt"/> < /dir> < file name="ccc.txt"/> < /dir> < file name="ddd.txt"/> < /xml>
假如现在的要素位置是xml标记,将其子元素转换成列表后对其各个项目应用函数。
List(fileFinder(~), fileFinder())
file的话保持原样,如果是dir则对其子元素应用函数。
List(List(fileFinder(~),fileFinder(< file name="ccc.txt"/>)),List(< file name="ddd.txt">))
接着对于***个Node元素应用函数。
List(List(List(< file name="aaa.txt"/>,< file name="bbb.txt"/>), List(< file name="ccc.txt"/>)), List(< file name="ddd.txt">))
理解上述工作过程是比较困难的,重要的是在我的脑中考虑的并不是这样复杂的逻辑,而仅仅是实现“从一个Node元素中取出file列表”的函数的逻辑。这需要一定程度的思路切换,考虑用命令式方法来实现时实际上花了我2-3小时,而想到这个函数式方法后不到10分钟就想通了。
感觉上好像已经完成了,但是这还不够。刚才用map来假想的过程完成后,得到的是List里面还有List的一个复合结构,光这样还不能被使用。那么,flatMap函数就出场了。这个函数在Scala的机制上具有同map函数同等的重要层度,将map和flatMap说成Scala函数机制的核心都不为过分。
“flatMap “函数对每一个元素应用函数参数之后将其结果以列表形式返回,这时返回结果是列表类型是关键。接着看一下简单的例子吧
首先是map函数的例子。对于内容为“1,2,3,4,5 “的列表,应用x*2函数。
scala> List(1,2,3,4,5) res134: List[Int] = List(1, 2, 3, 4, 5) scala> res134.map(x => x * 2) res135: List[Int] = List(2, 4, 6, 8, 10)
结果是List(2, 4, 6, 8, 10),即将每一个元素乘以2。题外话,还有一个叫做filter的函数,他返回过滤结果。
scala> res134.filter(x => x != 3) res136: List[Int] = List(1, 2, 4, 5)这里是返回3以外的元素。那么,接下来对于List(1, 2, 3, 4, 5)应用如下函数。 x => x match { case 3 => List(3.1, 3.2, 3.3) case _ => List(x * 2) }也就是,3以外的情况下使元素值翻倍,3的时候将元素分割为“3.1, 3.2, 3.3“。因此,表面上对于List(1,2,3,4,5)适用该函数后希望返回的是List(1, 2, 3.1, 3.2, 3.3, 4, 5),但用了map函数后实际上不是。
scala> res134.map(x => x match { | case 3 => List(3.1, 3.2, 3.3) | case _ => x * 2 | }) res138: List[Any] = List(2, 4, List(3.1, 3.2, 3.3), 8, 10)结果中的确包含了3.1, 3.2, 3.3,但是以List中包含List为形式的。这样只完成了一半,同前面的XML处理一样现象。那么,使用一下flatMap函数吧。
scala> res134.flatMap(x => x match { | case 3 => List(3.1, 3.2, 3.3) | case _ => List(x * 2) | }) res139: List[AnyVal] = List(2, 4, 3.1, 3.2, 3.3, 8, 10)噢!就是想要的结果。不仅包含了希望的元素,还将所有元素平摊成了一个列表。
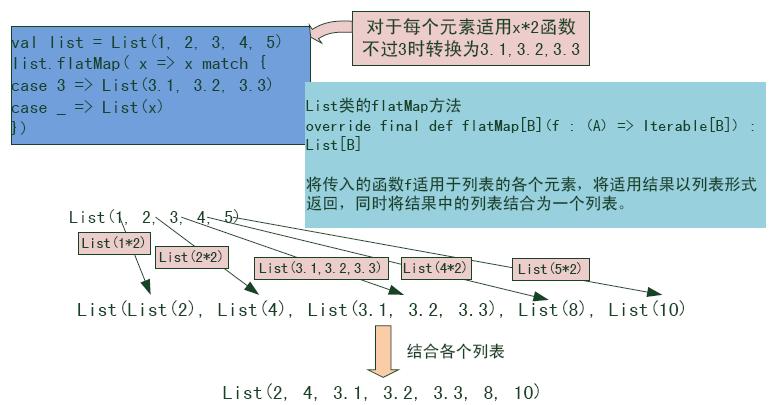
Scala讲座 图2:组合模式flatMap函数概念图
回到XML的例子中,正因为用flatMap函数代替了map函数,所以对于< xml>和< dir>部分来说,原本在递归调用中返回的是List,但是flatMap函数将其互相合并,摊平为单一列表了。
scala> def fileFinder(node:scala.xml.Node):List[scala.xml.Node] = node.label match { case "xml" => node.child.toList.flatMap(fileFinder) case "dir" => node.child.toList.flatMap(fileFinder) case "file" => List(node) case _ => List()} fileFinder: (scala.xml.Node)List[scala.xml.Node] scala> fileFinder(xml).foreach(x => println("file:" + x.attribute("name").getOrElse(""))) file:aaa.txt file:bbb.txt file:ccc.txt file:ddd.txt正如所愿的结果就一下子得到了,函数式编程真是恐怖呀!这次学的map和flatMap函数在Scala中有非常重要的意义。这可以说是函数式编程的一个高潮,理解了这个之后领悟的大门就可以说向你敞开了。这实际上还与单子(monado)这一思考方法有关,理解了map和flatMap函数之后可以说是踏出了完全掌握该思考方法的一大步。关于“单子”在本连载中还会着重说明。
感谢各位的阅读,以上就是“函数式编程处理树结构数据的方法”的内容了,经过本文的学习后,相信大家对函数式编程处理树结构数据的方法这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。