您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“Python中Pandas库的用法”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python中Pandas库的用法”吧!
1、Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
2、Pandas 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
3、数据结构:
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
Time- Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
Panel :三维的数组,可以理解为DataFrame的容器。
Pandas 有两种自己独有的基本数据结构。读者应该注意的是,它固然有着两种数据结构,因为它依然是 Python 的一个库,所以,Python 中有的数据类型在这里依然适用,也同样还可以使用类自己定义数据类型。只不过,Pandas 里面又定义了两种数据类型:Series 和 DataFrame,它们让数据操作更简单了。
修改列数据:
df['price']=df['price'].str.replace('人均','') # 删除多余文字
df['price']=df['price'].str.split("¥").str[-1] # 分割文本串
df['price']=df['price'].str.replace('-','0') # 替换文本
df['price']=df['price'].astype(int) # 文本转整型把pandas转换int型为str型的方法
切分列数据:
df['kw']=df['commentlist'].str.split().str[0].str.replace("口味",'')
df['hj']=df['commentlist'].str.split().str[1].str.replace("环境",'')
df['fw']=df['commentlist'].str.split().str[2].str.replace("服务",'')注意:pandas中操作如果不明确指定参数,则不会修改原数据,而是返回一个新对象。
删除列数据:
del df['commentlist']
排序列数据:
df.sort_values(by=['kw','price'],axis=0,ascending=[False,True],inplace=True)
注意:排序前先用astype转换正确的类型,如str、int或float
重新设置索引列标签顺序:
df.columns=['类型','店铺名称','点评数量','星级','人均消费','店铺地址','口味','环境','服务']
打印前几行数据:
print(df.loc[:,['店铺名称','口味','人均消费']].head(6)) # 或者 # print(df.iloc[0:6,[1,6,4]]) # 前6行(整数) # 但不能是 # print(df.loc[0:6,['店铺名称','口味','人均消费']]) # 从索引0到索引6的行(对象)
https://www.yisu.com/article/155602.htm
综合示例:
图例:
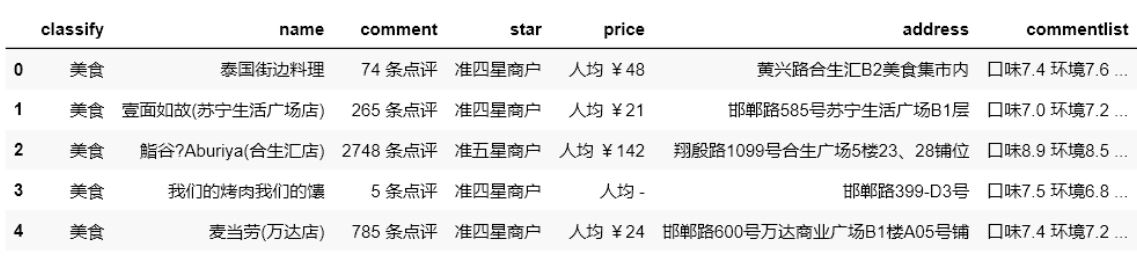
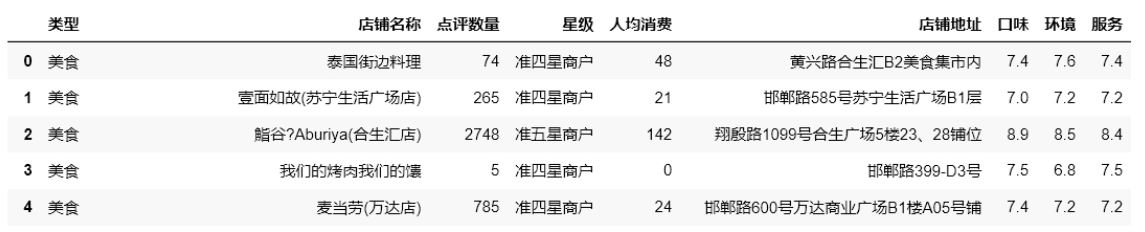
结果:
要求:
(1)对该数据中的comment、price进行数据清洗整理,
(2)将commentlist数据拆分为“口味”、“环境”和“服务”三列后再进行数据清洗整理,
(3)去除commentlist列数据
(4)将此数据按“口味”降序、“人均消费”升序进行排序,
(5)输出排序后前6条数据中的“店铺名称”、“口味”和“人均消费”三列数据。
代码:
import pandas as pd
df=pd.read_csv('spdata.csv',encoding='gbk') #读入文件,编码为gbk # 注意编码,重要
#对数据进行清洗
df['comment']=df['comment'].str.replace('条点评','')
df['price']=df['price'].str.replace('人均','')
df['price']=df['price'].str.split("¥").str[-1]
df['price']=df['price'].str.replace('-','0')
df['price']=df['price'].astype(int)
df['kw']=df['commentlist'].str.split().str[0].str.replace("口味",'')
df['hj']=df['commentlist'].str.split().str[1].str.replace("环境",'')
df['fw']=df['commentlist'].str.split().str[2].str.replace("服务",'')
del df['commentlist']
#按口味降序,人均消费升序进行排序
df.sort_values(by=['kw','price'],axis=0,ascending=[False,True],inplace=True)
#重新设置列索引标签
df.columns=['类型','店铺名称','点评数量','星级','人均消费','店铺地址','口味','环境','服务']
print(df.loc[:,['店铺名称','口味','人均消费']].head(6))方法二:
import pandas as pd
df=pd.read_csv('spdata.csv',encoding='gbk')
df['comment']=df['comment'].str.replace('条点评','')
df['price']=df['price'].str.replace('人均','').str.replace('¥','').str.replace('-','0').str.replace(' ','').astype(int)
df[['kw','hj','fw']]=df['commentlist'].str.replace('口味','').str.replace('环境','').str.replace('服务','').str.split(expand=True).astype(float) # expand将普通的列表转为DataFrame对象
del df['commentlist']
df.sort_values(by=['kw','price'],axis=0,ascending=[False,True],inplace=True) # 注意inplace=True
df.columns=['类型','店铺名称','点评数量','星级','人均消费','店铺地址','口味','环境','服务']
print(df[['店铺名称','口味','人均消费']].head(6))注意:df.str.split是列表,加了expand=True之后才是DataFrame对象,或者用.str[x]提取某一列,注意不是df.str.split()[x]而是df.str.split().str[x],前者是对list(二维)操作,后者是对DataFrame操作(取某一列)
感谢各位的阅读,以上就是“Python中Pandas库的用法”的内容了,经过本文的学习后,相信大家对Python中Pandas库的用法这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。