您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“如何理解MyBatis动态SQL”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“如何理解MyBatis动态SQL”吧!
前言
动态sql
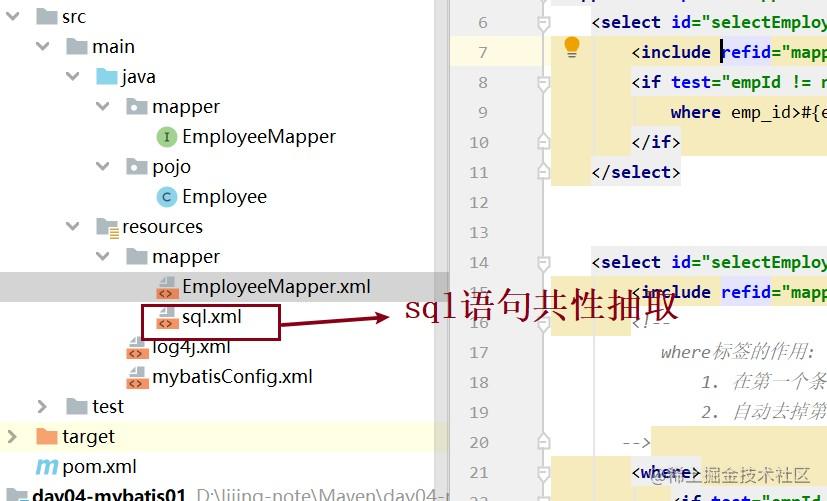
1.先看一下模块目录结构
2.物理建模和逻辑建模
3. 引入依赖
4.全局配置文件
5.sql共性抽取文件
6.mapper接口
if
静态sql:
动态sql:
where
用if标签的动态sql:
where和if的动态sql:
trim
trim的动态sql
trim标签:
set
trim的动态sql:
set的动态sql
set标签的作用:
choose、when、otherwise
动态sql
foreach
1.动态sql
2.动态sql
批量查询:foreach标签
测试程序
前面mysql都是通过静态sql进行查询的,但是如果业务复杂的时候,我们会遇到引号问题,或者多一个空格,这就使得sql代码编写错误了,所以为了解决这个问题,我们有了动态sql。
Mybatis框架的动态SQL技术是一种根据特定条件动态拼装SQL语句的功能,它存在的意义是为了解决拼接SQL语句字符串时的痛点问题。具体是通过标签来实现的。
在类路径的resources下的mapper包下创建sql.xml文件(共性抽取)
这里省略物理建模步骤,要求数据库的表与pojo类要对应。
package pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Employee {
private Integer empId;
private String empName;
private Double empSalary;
}把之前的log4j复制到类路径resouces下,另外我们引入依赖后的pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>day03-mybatis02-dynamic</artifactId> <version>1.0-SNAPSHOT</version> <packaging>jar</packaging> <dependencies> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.8</version> <scope>provided</scope> </dependency> <!-- Mybatis核心 --> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.5.7</version> </dependency> <!-- junit测试 --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> <!-- MySQL驱动 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.3</version> <scope>runtime</scope> </dependency> <!-- log4j日志 --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> </dependencies> </project>
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!--驼峰映射--> <settings> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings> <!--类型别名映射--> <typeAliases> <package name="pojo"/> </typeAliases> <!--环境配置--> <environments default="dev"> <environment id="dev"> <transactionManager type="JDBC"></transactionManager> <dataSource type="POOLED"> <property name="username" value="root"/> <property name="password" value="888888"/> <property name="url" value="jdbc:mysql://localhost:3306/mybatis-example"/> <property name="driver" value="com.mysql.jdbc.Driver"/> </dataSource> </environment> </environments> <!--路径映射--> <mappers> <mapper resource="mapper/sql.xml"/> <package name="mapper"/> </mappers> </configuration>
注意: 这里有驼峰映射,别名映射,路径映射和路径映射。和以前的不同的是,我们这里做了sql语句的共性抽取,所以得加一个sql的路径映射 <mapper resource="mapper/sql.xml"/>。
在类路径resources下的包mapper下创建一个sql.xml(因为我们sql是要写在映射文件中,自己本身也是映射文件,所以需要写在mapper下)。到要用的时候,在映射路径文件中需要用到这个sql语句的地方加入 <include refid="mapper.sql.mySelectSql"></include>。
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="mapper.sql"> <sql id="mySelectSql"> select emp_id,emp_name,emp_salary from t_emp </sql> </mapper>
共性抽取文件也可以不配置,这时候直接在映射文件中把要执行的语句重新编写就行了。
一共有七个方法
package mapper;
import org.apache.ibatis.annotations.Param;
import pojo.Employee;
import java.util.List;
public interface EmployeeMapper {
//根据员工的empId查询大于该empId的所有员工,如果empId为null,则查询全体员工
List<Employee> selectEmployeeListByEmpId(Integer empId);
/**
* 查询大于传入的empId并且工资大于传入的empSalary的员工集合,如果传入的empId为null,则不考虑empId条件
* 传入的empSalary为null则不考虑empSalary的条件
*/
List<Employee> selectEmployeeListByEmpIdAndEmpSalary(@Param("empId") Integer empId, @Param("empSalary") Double empSalary);
/**
* 根据empId更新员工信息,如果某个值为null,则不更新这个字段
*/
void updateEmployee(Employee employee);
/**
* 根据emp_id查询员工信息,如果0<emp_id<6,那么就查询所有大于该emp_id的员工,如果emp_id是大于6,那么就查询所有小于该emp_id的员工
* 如果是其它情况,则查询所有员工信息
*/
List<Employee> selectEmployeeList(Integer empId);
/**
* 添加员工信息
*/
void insertEmployee(Employee employee);
/**
* 批量添加员工集合
*/
void insertEmployeeList(@Param("employeeList") List<Employee> employeeList);
/**
* 根据员工的id集合查询员工集
*/
List<Employee> selectEmployeeListByEmpIdList(List<Integer> idList);
}目标:根据员工的empId查询大于该empId的所有员工,如果empId为null,则查询全体员工。
Dao接口的方法为:List<Employee> selectEmployeeListByEmpId(Integer empId);
<select id="selectEmployeeListByEmpId" resultType="Employee">
<include refid="mapper.sql.mySelectSql"></include> where emp_id>#{empId}
</select><select id="selectEmployeeListByEmpId" resultType="Employee">
<include refid="mapper.sql.mySelectSql"></include>
<if test="empId != null">
where emp_id>#{empId}
</if>
</select><include refid="mapper.sql.mySelectSql"></include>表示引用抽取出的sql片段,也可以直接写sql语句。如果是静态sql,当id为null时,查询出来的是空,动态sql则可以查出全部。if标签里面有test属性名,作为判断语句。
目标:
查询大于传入的empId并且工资大于传入的empSalary的员工集合
如果传入的empId为null,则不考虑empId条件
传入的empSalary为null则不考虑empSalary的条件
Dao接口方法:
List<Employee> selectEmployeeListByEmpIdAndEmpSalary(@Param("empId") Integer empId, @Param("empSalary") Double empSalary);
<select id="selectEmployeeListByEmpIdAndEmpSalary" resultType="Employee">
<include refid="mapper.sql.mySelectSql"></include> where
<if test="empId != null">
emp_id>#{empId}
</if>
<if test="empSalary != null">
and emp_salary>#{empSalary}
</if>这里可以看到,如果empSalary为空,那么sql语句为select * from t_emp where emp_id >#{empId},但是如果empId为空,那么sql语句为select * from t_emp where and emp_salary>#{empSalary},很明显这个是错的,if标签在这里就不适用了。所以我们用where标签,或者trim标签。
<select id="selectEmployeeListByEmpIdAndEmpSalary" resultType="Employee">
<include refid="mapper.sql.mySelectSql"></include>
<where>
<if test="empId != null">
emp_id>#{empId}
</if>
<if test="empSalary != null">
and emp_salary>#{empSalary}
</if>
</where>
</select>where标签的作用:
在第一个条件之前自动添加WHERE关键字
自动去掉第一个条件前的连接符(AND、OR等等)
trim是修建的意思,其实就是去头去尾,这里还是根据上面那个方法
<select id="selectEmployeeListByEmpIdAndEmpSalary" resultType="Employee">
<include refid="mapper.sql.mySelectSql"></include>
<trim prefix="WHERE" prefixOverrides="AND|OR">
<if test="empId != null">
emp_id>#{empId}
</if>
<if test="empSalary != null">
AND emp_salary>#{empSalary}
</if>
</trim>
</select>prefix:指定要动态添加的前缀
suffix属性:指定要动态添加的后缀
prefixOverrides:指定要动态去掉的前缀,使用“|”分隔有可能的多个值
suffixOverrides属性:指定要动态去掉的后缀,使用“|”分隔有可能的多个值
目标:根据empId更新员工信息,如果某个值为null,则不更新这个字段
Dao接口方法:void updateEmployee(Employee employee);
我们先用上面的trim标签来解决一下这个问题,
<update id="updateEmployee" >
<trim prefix="set" prefixOverrides=",">
<if test="empName!=null">
emp_name=#{empName}
</if>
<if test="empSalary!=null">
, emp_salary=#{empSalary}
</if>
</trim>
where emp_id=#{empId}
</update><update id="updateEmployee" >
update t_emp
<set >
<if test="empName!=null">
emp_name=#{empName}
</if>
<if test="empSalary!=null">
, emp_salary=#{empSalary}
</if>
</set>可以看出
自动在要修改的第一个字段之前添加SET关键字
去掉要修改的第一个字段前的连接符(,)
目标:
根据emp_id查询员工信息,如果0<emp_id<6,那么就查询所有大于该emp_id的员工
如果emp_id是大于6,那么就查询所有小于该emp_id的员工
如果是其它情况,则查询所有员工信息
Dao接口方法:List<Employee> selectEmployeeList(Integer empId);
<select id="selectEmployeeList" resultType="employee">
<include refid="mapper.sql.mySelectSql"></include> where
<choose>
<!--<是<号的转义字符-->
<when test="empId>0 and empId<6">
emp_id>#{empId}
</when>
<when test="empId>6">
emp_id<#{empId}
</when>
<otherwise>
1==1
</otherwise>
</choose>
</select>choose、when、otherwise
相当于if ... else if... else if ... else
如果某一个when的条件成立,则不会继续判断后续的when
如果所有的when都不成立,则会拼接otherwise标签中的内容
目标1:批量添加员工信息
Dao接口方法:
void insertEmployeeList(@Param("employeeList") List employeeList);
<insert id="insertEmployeeList">
insert into t_emp(emp_name,emp_salary)values
<!--collection标签可以写list,collection,
或者自己自己定义参数名@Param("employeeList") List<Employee> employeeList-->
<foreach collection="employeeList" separator="," item="emp">
(#{emp.empName},#{emp.empSalary})
</foreach>
</insert>目标2:根据多个id查询多个员工信息
Dao接口
List selectEmployeeListByEmpIdList(List idList);
<select id="selectEmployeeListByEmpIdList" resultType="employee">
<include refid="mapper.sql.mySelectSql"></include>
<foreach collection="collection" item="id" separator="," open="where emp_id in (" close=")">
#{id}
</foreach>
</select>collection属性: 表示要遍历的对象,如果要遍历的参数使用@Param注解取名了就使用该名字,如果没有取名List,或者collection。
item属性: 表示遍历出来的元素,我们到时候要拼接SQL语句就得使用这个元素: 如果遍历出来的元素是POJO对象, 那么我们就通过 #{遍历出来的元素.POJO的属性} 获取数据;如果遍历出来的元素是简单类型的数据,那么我们就使用 #{遍历出来的元素} 获取这个简单类型数据
separator属性: 遍历出来的元素之间的分隔符
open属性: 在遍历出来的第一个元素之前添加前缀
close属性: 在遍历出来的最后一个元素之后添加后缀
import mapper.EmployeeMapper;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.After;
import org.junit.Before;
import pojo.Employee;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
public class Test {
private EmployeeMapper employeeMapper;
private InputStream is;
private SqlSession sqlSession;
@Before
public void init() throws Exception{
//目标:获取EmployeeMapper接口的代理对象,并且使用该对象调用selectEmployee(1)方法,然后返回Employee对象
//1. 将全局配置文件转成字节输入流
is = Resources.getResourceAsStream("mybatisConfig.xml");
//2. 创建SqlSessionFactoryBuilder对象
SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder();
//3. 使用构建者模式创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(is);
//4. 使用工厂模式创建一个SqlSession对象
sqlSession = sqlSessionFactory.openSession();
//5. 使用动态代理模式,创建EmployeeMapper接口的代理对象
employeeMapper = sqlSession.getMapper(EmployeeMapper.class);
}
@After
public void after() throws Exception{
//提交事务!!!
sqlSession.commit();
//7. 关闭资源
is.close();
sqlSession.close();
}
@org.junit.Test
public void testSelectEmployeeListByEmpId(){
System.out.println(employeeMapper.selectEmployeeListByEmpId(null));
}
@org.junit.Test
public void testSelectEmployeeListByEmpIdAndEmpSalary(){
System.out.println(employeeMapper.selectEmployeeListByEmpIdAndEmpSalary(2, 300d));
}
@org.junit.Test
public void testUpdateEmployee(){
Employee employee = new Employee(3,"celia", 9000d);
employeeMapper.updateEmployee(employee);
}
@org.junit.Test
public void testSelectEmployeeList(){
System.out.println(employeeMapper.selectEmployeeList(7));
}
@org.junit.Test
public void testInsertEmployee(){
employeeMapper.insertEmployee(new Employee(null,"tom",300d));
}
@org.junit.Test
public void testInsertEmployeeList(){
List<Employee> employeeList = new ArrayList<>();
for (int i = 11; i <=20 ; i++) {
employeeList.add(new Employee(null,"aobama"+i,2000d));
}
employeeMapper.insertEmployeeList(employeeList);
}
@org.junit.Test
public void testSelectEmployeeListByEmpIdList(){
List<Integer> idList = new ArrayList<>();
idList.add(23);
idList.add(33);
idList.add(32);
idList.add(21);
idList.add(22);
System.out.println(employeeMapper.selectEmployeeListByEmpIdList(idList));
}
}到此,相信大家对“如何理解MyBatis动态SQL”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。