жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңд»Җд№ҲжҳҜеҚ·з§ҜзҘһз»ҸзҪ‘з»ңLeNetвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁд»Җд№ҲжҳҜеҚ·з§ҜзҘһз»ҸзҪ‘з»ңLeNetй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқд»Җд№ҲжҳҜеҚ·з§ҜзҘһз»ҸзҪ‘з»ңLeNetвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
LeNet
жЁЎеһӢи®ӯз»ғ
еңЁжң¬иҠӮдёӯпјҢжҲ‘们е°Ҷд»Ӣз»ҚLeNetпјҢе®ғжҳҜжңҖж—©еҸ‘еёғзҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңд№ӢдёҖгҖӮиҝҷдёӘжЁЎеһӢжҳҜз”ұAT&Tиҙқе°”е®һйӘҢе®Өзҡ„з ”з©¶йҷўYann LeCunеңЁ1989е№ҙжҸҗеҮәзҡ„пјҲ并д»Ҙе…¶е‘ҪеҗҚпјүпјҢзӣ®зҡ„жҳҜиҜҶеҲ«жүӢеҶҷж•°еӯ—гҖӮеҪ“ж—¶пјҢLeNetеҸ–еҫ—дәҶдёҺж”ҜжҢҒеҗ‘йҮҸжңәжҖ§иғҪзӣёеӘІзҫҺзҡ„жҲҗжһңпјҢжҲҗдёәзӣ‘зқЈеӯҰд№ зҡ„дё»жөҒж–№жі•гҖӮLeNetиў«е№ҝжіӣз”ЁдәҺиҮӘеҠЁеҸ–ж¬ҫжңәдёӯпјҢеё®еҠ©иҜҶеҲ«еӨ„зҗҶж”ҜзҘЁзҡ„ж•°еӯ—гҖӮ
жҖ»дҪ“жқҘзңӢпјҢLeNetпјҲLeNet-5пјүз”ұдёӨдёӘйғЁеҲҶз»„жҲҗпјҡ
еҚ·з§Ҝзј–з ҒеҷЁпјҡ з”ұдёӨдёӘеҚ·з§ҜеұӮз»„жҲҗ
е…ЁиҝһжҺҘеұӮеҜҶйӣҶеҝ«пјҡ з”ұдёүдёӘе…ЁиҝһжҺҘеұӮз»„жҲҗ
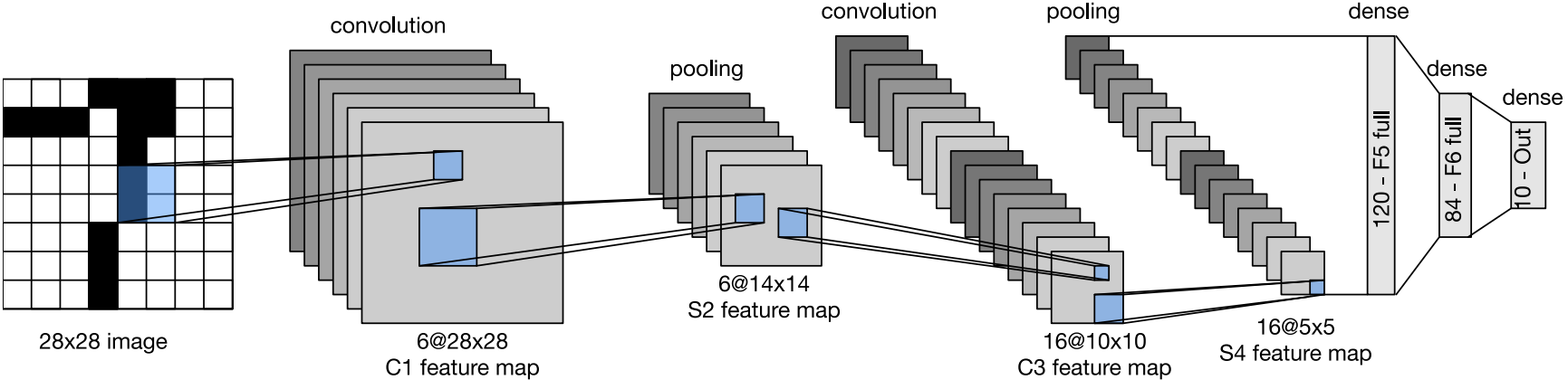
жҜҸдёӘеҚ·з§Ҝеқ—дёӯзҡ„еҹәжң¬еҚ•е…ғжҳҜдёҖдёӘеҚ·з§ҜеұӮгҖҒдёҖдёӘsigmoidжҝҖжҙ»еҮҪж•°е’Ңе№іеқҮжұ еҢ–еұӮгҖӮиҝҷйҮҢпјҢиҷҪ然ReLUе’ҢжңҖеӨ§жұ еҢ–еұӮжӣҙжңүж•ҲпјҢдҪҶе®ғ们еңЁ20дё–зәӘ90е№ҙд»ЈиҝҳжІЎжңүеҮәзҺ°гҖӮжҜҸдёӘеҚ·з§ҜеұӮдҪҝз”Ё 5 Г— 5 5\times5 5Г—5еҚ·з§Ҝж ёе’ҢдёҖдёӘsigmoidжҝҖжҙ»еҮҪж•°гҖӮиҝҷдәӣеұӮе°Ҷиҫ“е…Ҙжҳ е°„еҲ°еӨҡдёӘдәҢз»ҙзү№еҫҒиҫ“еҮәпјҢйҖҡеёёеҗҢж—¶еўһеҠ йҖҡйҒ“зҡ„ж•°йҮҸгҖӮ第дёҖеҚ·з§ҜеұӮжңү6дёӘиҫ“еҮәйҖҡйҒ“пјҢиҖҢ第дәҢдёӘеҚ·з§ҜеұӮжңү16дёӘиҫ“еҮәйҖҡйҒ“гҖӮжҜҸдёӘ 2 Г— 2 2\times2 2Г—2жұ ж“ҚдҪңйҖҡиҝҮз©әй—ҙдёӢйҮҮж ·е°Ҷз»ҙж•°еҮҸе°‘4еҖҚгҖӮ
дёәдәҶе°ҶеҚ·з§Ҝеқ—дёӯзҡ„иҫ“еҮәдј йҖ’з»ҷзЁ еҜҶеқ—пјҢжҲ‘们еҝ…йЎ»еңЁе°Ҹжү№йҮҸдёӯжҲҳе№іжҜҸдёӘж ·жң¬гҖӮLeNetзҡ„зЁ еҜҶеҝ«жңүдёүдёӘе…ЁиҝһжҺҘеұӮпјҢеҲҶеҲ«жңү120гҖҒ84е’Ң10дёӘиҫ“еҮәгҖӮеӣ дёәжҲ‘们д»ҚеңЁжү§иЎҢеҲҶзұ»пјҢжүҖд»Ҙиҫ“еҮәеұӮзҡ„10з»ҙеҜ№еә”дәҺжңҖеҗҺиҫ“еҮәз»“жһңзҡ„ж•°йҮҸгҖӮ
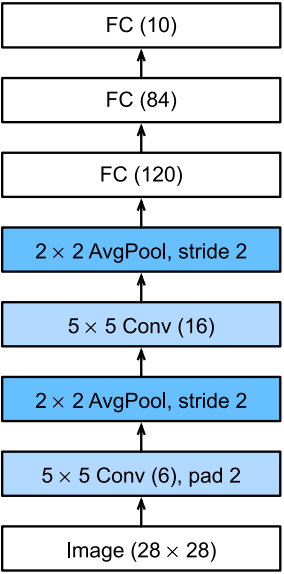
йҖҡиҝҮдёӢйқўзҡ„LeNetд»Јз ҒпјҢжҲ‘们дјҡзӣёдҝЎж·ұеәҰеӯҰд№ жЎҶжһ¶е®һзҺ°жӯӨзұ»жЁЎеһӢйқһеёёз®ҖеҚ•гҖӮжҲ‘们еҸӘйңҖиҰҒе®һдҫӢеҢ–дёҖдёӘSequentialеқ—并е°ҶйңҖиҰҒзҡ„еұӮиҝһжҺҘеңЁдёҖиө·гҖӮ
import torch from torch import nn from d2l import torch as d2l class Reshape(torch.nn.Module): def forward(self, x): return x.view(-1, 1, 28, 28) net = torch.nn.Sequential( Reshape(), nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(), nn.Linear(120, 84), nn.Sigmoid(), nn.Linear(84, 10) )
жҲ‘们еҜ№еҺҹе§ӢжЁЎеһӢеҒҡдәҶдёҖзӮ№е°Ҹж”№еҠЁпјҢеҺ»жҺүдәҶжңҖеҗҺдёҖеұӮзҡ„й«ҳж–ҜжҝҖжҙ»гҖӮйҷӨжӯӨд№ӢеӨ–пјҢиҝҷдёӘзҪ‘з»ңдёҺжңҖеҲқзҡ„LeNet-5дёҖиҮҙгҖӮдёӢйқўпјҢжҲ‘们е°ҶдёҖдёӘеӨ§е°Ҹдёә 28 Г— 28 28\times28 28Г—28зҡ„еҚ•йҖҡйҒ“пјҲй»‘зҷҪпјүеӣҫеғҸйҖҡиҝҮLeNetгҖӮйҖҡиҝҮеңЁжҜҸдёҖеұӮжү“еҚ°иҫ“еҮәзҡ„еҪўзҠ¶пјҢжҲ‘们еҸҜд»ҘжЈҖжҹҘжЁЎеһӢпјҢд»ҘзЎ®дҝқе…¶ж“ҚдҪңдёҺжҲ‘们жңҹжңӣзҡ„дёӢеӣҫдёҖиҮҙгҖӮ
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32) for layer in net: X = layer(X) print(layer.__class__.__name__, 'output shape: \t', X.shape)
Reshape output shape: torch.Size([1, 1, 28, 28]) Conv2d output shape: torch.Size([1, 6, 28, 28]) Sigmoid output shape: torch.Size([1, 6, 28, 28]) AvgPool2d output shape: torch.Size([1, 6, 14, 14]) Conv2d output shape: torch.Size([1, 16, 10, 10]) Sigmoid output shape: torch.Size([1, 16, 10, 10]) AvgPool2d output shape: torch.Size([1, 16, 5, 5]) Flatten output shape: torch.Size([1, 400]) Linear output shape: torch.Size([1, 120]) Sigmoid output shape: torch.Size([1, 120]) Linear output shape: torch.Size([1, 84]) Sigmoid output shape: torch.Size([1, 84]) Linear output shape: torch.Size([1, 10])
иҜ·жіЁж„ҸпјҢеңЁж•ҙдёӘеҚ·з§Ҝеқ—дёӯпјҢдёҺдёҠдёҖеұӮзӣёжҜ”пјҢжҜҸдёҖеұӮзү№еҫҒзҡ„й«ҳеәҰе’Ңе®ҪеәҰйғҪеҮҸе°ҸдәҶгҖӮ第дёҖдёӘеҚ·з§ҜеұӮдҪҝз”Ё2дёӘеғҸзҙ зҡ„еЎ«е……пјҢжқҘиЎҘеҒҝ 5 Г— 5 еҚ·з§Ҝж ёеҜјиҮҙзҡ„зү№еҫҒеҮҸе°‘гҖӮзӣёеҸҚпјҢ第дәҢдёӘеҚ·з§ҜеұӮжІЎжңүеЎ«е……пјҢеӣ жӯӨй«ҳеәҰе’Ңе®ҪеәҰйғҪеҮҸе°‘дәҶ4дёӘеғҸзҙ гҖӮйҡҸзқҖеұӮеҸ зҡ„дёҠеҚҮпјҢйҖҡйҒ“зҡ„ж•°йҮҸд»Һиҫ“е…Ҙж—¶зҡ„1дёӘпјҢеўһеҠ еҲ°з¬¬дёҖдёӘеҚ·з§ҜеұӮд№ӢеҗҺзҡ„6дёӘпјҢеҶҚеҲ°з¬¬дәҢдёӘеҚ·з§ҜеұӮд№ӢеҗҺзҡ„16дёӘгҖӮеҗҢж—¶пјҢжҜҸдёӘжұҮиҒҡеұӮзҡ„й«ҳеәҰе’Ңе®ҪеәҰйғҪеҮҸеҚҠгҖӮжңҖеҗҺпјҢжҜҸдёӘе…ЁиҝһжҺҘеұӮеҮҸе°‘з»ҙеәҰпјҢжңҖз»Ҳиҫ“еҮәдёҖдёӘз»ҙж•°дёҺз»“жһңеҲҶзұ»ж•°зӣёеҢ№й…Қзҡ„иҫ“еҮәгҖӮ
зҺ°еңЁжҲ‘们已з»Ҹе®һзҺ°дәҶLeNetпјҢи®©жҲ‘们зңӢзңӢLeNetеңЁFashion-MNISTж•°жҚ®йӣҶдёҠзҡ„иЎЁзҺ°гҖӮ
batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size = batch_size)
иҷҪ然еҚ·з§ҜзҘһз»ҸзҪ‘з»ңзҡ„еҸӮж•°иҫғе°‘пјҢдҪҶдёҺж·ұеәҰзҡ„еӨҡеұӮж„ҹзҹҘжңәзӣёжҜ”пјҢе®ғ们зҡ„и®Ўз®—жҲҗжң¬д»Қ然еҫҲй«ҳпјҢеӣ дёәжҜҸдёӘеҸӮж•°йғҪеҸӮдёҺжӣҙеӨҡзҡ„д№ҳжі•гҖӮ
еҰӮжһңжҲ‘们жңүжңәдјҡдҪҝз”ЁGPUпјҢеҸҜд»Ҙз”Ёе®ғеҠ еҝ«и®ӯз»ғгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңд»Җд№ҲжҳҜеҚ·з§ҜзҘһз»ҸзҪ‘з»ңLeNetвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ