жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңPythonзј–иҜ‘з»“жһңд№ӢеҰӮдҪ•зҗҶи§ЈcodeеҜ№иұЎдёҺpycж–Ү件вҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
дёҺjavaзұ»дјјпјҢPythonе°Ҷ.pyзј–иҜ‘дёәеӯ—иҠӮз ҒпјҢ然еҗҺйҖҡиҝҮиҷҡжӢҹжңәжү§иЎҢгҖӮзј–иҜ‘иҝҮзЁӢдёҺиҷҡжӢҹжңәжү§иЎҢиҝҮзЁӢеқҮеңЁpython25.dllдёӯгҖӮPythonиҷҡжӢҹжңәжҜ”javaжӣҙжҠҪиұЎпјҢзҰ»еә•еұӮжӣҙиҝңгҖӮ
зј–иҜ‘иҝҮзЁӢдёҚд»…з”ҹжҲҗеӯ—иҠӮз ҒпјҢиҝҳиҰҒеҢ…еҗ«еёёйҮҸгҖҒеҸҳйҮҸгҖҒеҚ з”Ёж Ҳзҡ„з©әй—ҙзӯүпјҢPytonдёӯзј–иҜ‘иҝҮзЁӢз”ҹжҲҗcodeеҜ№иұЎPyCodeObjectгҖӮе°ҶPyCodeObjectеҶҷе…ҘдәҢиҝӣеҲ¶ж–Ү件пјҢеҚі.pycгҖӮ

жңүеҝ…иҰҒеҲҷеҶҷе…ҘA.pycжҢҮзҡ„жҳҜиҜҘ.pyжҳҜеҗҰеҸӘиҝҗиЎҢдёҖж¬ЎпјҢеҰӮжһңimportзҡ„жЁЎеқ—пјҢиӮҜе®ҡдјҡз”ҹжҲҗ.pycгҖӮ
Pythonи§ЈйҮҠеҷЁе°Ҷ.pyзЁӢеәҸзј–иҜ‘дёәPyCodeObjectеҜ№иұЎпјҢе…·дҪ“иҝҮзЁӢдёҺзј–иҜ‘еҺҹзҗҶзұ»дјјгҖӮ
typedef struct {
PyObject_HEAD
int co_argcount; // Code Blockзҡ„еҸӮж•°зҡ„дёӘж•°пјҢжҜ”еҰӮиҜҙдёҖдёӘеҮҪж•°зҡ„еҸӮж•°
int co_nlocals; // Code BlockдёӯеұҖйғЁеҸҳйҮҸзҡ„дёӘж•°
int co_stacksize; // жү§иЎҢиҜҘж®өCode BlockйңҖиҰҒзҡ„ж Ҳз©әй—ҙ
int co_flags; // N/A
PyObject *co_code; // Code Blockзј–иҜ‘жүҖеҫ—зҡ„byte codeпјҢд»ҘPyStringObjectзҡ„еҪўејҸеӯҳеңЁ
PyObject *co_consts; // PyTupleObjectеҜ№иұЎпјҢдҝқеӯҳCode Blockдёӯзҡ„еёёйҮҸ
PyObject *co_names; // PyTupleObjectеҜ№иұЎпјҢдҝқеӯҳCode Blockдёӯзҡ„жүҖжңүз¬ҰеҸ·
PyObject *co_varnames; // Code BlockдёӯеұҖйғЁеҸҳйҮҸеҗҚйӣҶеҗҲ
PyObject *co_freevars; // е®һзҺ°й—ӯеҢ…жүҖйңҖдёңиҘҝ
PyObject *co_cellvars; // Code BlockеҶ…йғЁеөҢеҘ—еҮҪж•°жүҖеј•з”Ёзҡ„еұҖйғЁеҸҳйҮҸеҗҚйӣҶеҗҲ
PyObject *co_filename; // Code BlockжүҖеҜ№еә”зҡ„.pyж–Ү件зҡ„е®Ңж•ҙи·Ҝеҫ„
PyObject *co_name; // Code Blockзҡ„еҗҚеӯ—пјҢйҖҡеёёжҳҜеҮҪж•°еҗҚжҲ–зұ»еҗҚ
int co_firstlineno; // Code BlockеңЁеҜ№еә”зҡ„.pyж–Ү件дёӯзҡ„иө·е§ӢиЎҢ
PyObject *co_lnotab; // byte codeдёҺ.pyж–Ү件дёӯsource codeиЎҢеҸ·зҡ„еҜ№еә”е…ізі»пјҢд»ҘPyStringObjectзҡ„еҪўејҸеӯҳеңЁ
void *co_zombieframe;
PyObject *co_weakreflist;
} PyCodeObject;дёҖдёӘCode Blockз”ҹжҲҗдёҖдёӘPyCodeObjectпјҢиҝӣе…ҘдёҖдёӘеҗҚеӯ—з©әй—ҙжҲҗдёәиҝӣе…ҘдёҖдёӘCode BlockгҖӮеҰӮдёӢ.pyж–Ү件编иҜ‘е®ҢжҲҗеҗҺдјҡз”ҹжҲҗдёүдёӘPyCodeObjectпјҢдёҖдёӘеҜ№еә”ж•ҙдёӘ.pyж–Ү件дёҖдёӘеҜ№еә”Class AпјҢдёҖдёӘеҜ№еә”def FunгҖӮе®һйҷ…иҝҷдёүдёӘcodeеҜ№иұЎжҳҜеөҢеҘ—зҡ„пјҢеҗҺдёӨдёӘcodeеҜ№иұЎдҪҚдәҺ第дёҖдёӘcodeеҜ№иұЎзҡ„co_constsеұһжҖ§дёӯгҖӮе…¶е®һпјҢеӯ—иҠӮз ҒдҪҚдәҺco_codeдёӯгҖӮ
class A: pass def Fun(): pass a = A() Fun()
pycж–Ү件еҢ…жӢ¬дёүйғЁеҲҶпјҡ
пјҲ1пјүеӣӣеӯ—иҠӮзҡ„Magic intпјҢиЎЁзӨәpycзүҲжң¬дҝЎжҒҜ
пјҲ2пјүеӣӣеӯ—иҠӮзҡ„intпјҢжҳҜpycдә§з”ҹж—¶й—ҙпјҢиӢҘдёҺpyж–Ү件时й—ҙдёҚеҗҢдјҡйҮҚж–°з”ҹжҲҗ
пјҲ3пјүеәҸеҲ—еҢ–дәҶзҡ„PyCodeObjectеҜ№иұЎгҖӮ
еҶҷе…Ҙpycж–Ү件зҡ„еҮҪж•°еҢ…жӢ¬д»ҘдёӢеҮ дёӘжӯҘйӘӨпјҡ
PyMarshal_WriteLongToFile(pyc_magic, fp, Py_MARSHAL_VERSION); // еҶҷе…ҘзүҲжң¬дҝЎжҒҜ PyMarshal_WriteLongToFile(0L, fp, Py_MARSHAL_VERSION); // еҶҷе…Ҙж—¶й—ҙдҝЎжҒҜ PyMarshal_WriteObjectToFile((PyObject *)co, fp, Py_MARSHAL_VERSION); // еҶҷе…ҘPyCodeObjectеҜ№иұЎ
е…ій”®еңЁдәҺcodeеҜ№иұЎзҡ„еҶҷе…Ҙпјҡ
{
WFILE wf;
wf.fp = fp;
вҖҰвҖҰ
w_object(x, &wf);
}з”ЁеҲ°дәҶдёҖдёӘWFILEз»“жһ„дҪ“пјҢеҸҜд»Ҙи®ӨдёәжҳҜеҜ№FILE *fp зҡ„дёҖдёӘе°ҒиЈ…пјҡ
typedef struct {
FILE *fp;
int error;
int depth;
PyObject *strings; // еӯҳеӮЁеӯ—з¬ҰдёІпјҢеҶҷе…Ҙж—¶д»ҘdictеҪўејҸпјҢиҜ»еҮәж—¶д»ҘlistеҪўејҸ
} WFILE;е…ій”®еңЁдәҺw_object()еҮҪж•°пјҡ
static void w_object(PyObject *v, WFILE *p){
if (v == NULL) вҖҰвҖҰ
else if (PyInt_CheckExact(v)) вҖҰвҖҰ
else if (PyFloat_CheckExact(v)) вҖҰвҖҰ
else if (PyString_CheckExact(v)) вҖҰвҖҰ
else if (PyList_CheckExact(v)) вҖҰвҖҰ
}w_codeе®һиҙЁдёәж №жҚ®дёҚеҗҢзҡ„еҜ№иұЎзұ»еһӢйҖүеҸ–дёҚеҗҢзҡ„зӯ–з•ҘпјҢдҫӢеҰӮtupleеҜ№иұЎпјҡ
else if (PyTuple_CheckExact(v)) {
w_byte(TYPE_TUPLE, p);
n = PyTuple_Size(v);
W_SIZE(n, p);
for (i = 0; i < n; i++)
w_object(PyTuple_GET_ITEM(v, i), p);иҖҢжүҖжңүзұ»еһӢжңҖз»ҲеҸҜеҲҶи§ЈдёәеҶҷе…Ҙж•°еҖјдёҺеҶҷе…Ҙеӯ—з¬ҰдёІдёӨз§Қж“ҚдҪңпјҢж¶үеҸҠд»ҘдёӢеҮ йғЁеҲҶпјҡ
#define w_byte(c, p) putc((c), (p)->fp) // з”ЁдәҺеҶҷе…Ҙзұ»еһӢ
static void w_long(long x, WFILE *p){ // з”ЁдәҺеҶҷе…Ҙж•°еӯ—
w_byte((char)( x & 0xff), p); // е®һиҙЁдёәз”ЁеӣӣдёӘеӯ—иҠӮеӯҳеӮЁдёҖдёӘж•°еӯ—
w_byte((char)((x>> 8) & 0xff), p);
w_byte((char)((x>>16) & 0xff), p);
w_byte((char)((x>>24) & 0xff), p);
}
static void w_string(char *s, int n, WFILE *p){ //з”ЁдәҺеҶҷе…Ҙеӯ—з¬ҰдёІ
fwrite(s, 1, n, p->fp);
}з”ұдәҺеәҸеҲ—еҢ–еҶҷе…Ҙж–Ү件еҗҺдёўеӨұдәҶз»“жһ„дҝЎжҒҜпјҢж•…еҶҷе…ҘжҜҸдёӘеҜ№иұЎж—¶еҶҷе…Ҙзұ»еһӢдҝЎжҒҜw_byteпјҡ
#define TYPE_INT 'i'
#define TYPE_LIST '['
#define TYPE_DICT '{'
#define TYPE_CODE 'c'з”ұдәҺPythonзҡҶеҜ№иұЎпјҢw_object(PyObject*)дҫҝеҸҜй’ҲеҜ№дёҚеҗҢзұ»еһӢйҖүеҸ–дёҚеҗҢеҶҷе…Ҙж–№жі•пјҢдёҚж–ӯз»ҶеҲҶпјҢжңҖз»ҲеҲҶи§ЈдёәPyInt_ObjectжҲ–PyString_ObjectпјҢеҲ©з”Ёw_longжҲ–w_stringеҶҷе…ҘгҖӮ
ж•°еӯ—жҜ”иҫғз®ҖеҚ•пјҡ
else if (PyInt_CheckExact(v)) {
w_byte(TYPE_INT, p);
w_long(x, p);
}еӯ—з¬ҰдёІеҲҷжҜ”иҫғеӨҚжқӮпјҡ
else if (PyString_CheckExact(v)) {
if (p->strings && PyString_CHECK_INTERNED(v)) {
PyObject *o = PyDict_GetItem(p->strings, v); // иҺ·еҸ–еңЁstringsдёӯзҡ„еәҸеҸ·
if (o) { // interеҜ№иұЎзҡ„йқһйҰ–ж¬ЎеҶҷе…Ҙ
long w = PyInt_AsLong(o);
w_byte(TYPE_STRINGREF, p);
w_long(w, p);
goto exit;
}
else { // internеҜ№иұЎзҡ„йҰ–ж¬ЎеҶҷе…Ҙ
int ok;
ok = o && PyDict_SetItem(p->strings, v, o) >= 0;
Py_XDECREF(o);
w_byte(TYPE_INTERNED, p);
}
}
else { // еҶҷе…Ҙжҷ®йҖҡstring
w_byte(TYPE_STRING, p);
}
n = PyString_GET_SIZE(v);
W_SIZE(n, p);
w_string(PyString_AS_STRING(v), n, p);
} пјҲ1пјүиӢҘеҶҷе…Ҙжҷ®йҖҡеӯ—з¬ҰдёІпјҢеҶҷе…Ҙеӯ—з¬ҰдёІзұ»еһӢдҝЎжҒҜ"S"пјҢ然еҗҺеҶҷе…Ҙеӯ—з¬ҰдёІй•ҝеәҰеҸҠstringеҖјгҖӮ
пјҲ2пјүиӢҘеҶҷе…Ҙinterеӯ—з¬ҰдёІпјҢе…ҲеҲ°WFILEзҡ„stringsдёӯжҹҘжүҫпјҡ
пјҲaпјүиӢҘжүҫеҲ°пјҢеҲҷеҶҷе…Ҙеј•з”Ёзұ»еһӢдҝЎжҒҜ"R"пјҢ然еҗҺеҶҷе…ҘеәҸеҸ·
пјҲbпјүиӢҘжңӘжүҫеҲ°пјҢеҲӣе»әеҜ№иұЎж”ҫе…ҘstringsпјҢ并еҶҷе…Ҙinternзұ»еһӢдҝЎжҒҜ"t"пјҢ然еҗҺеҶҷе…Ҙеӯ—з¬ҰдёІй•ҝеәҰеҸҠstringеҖјгҖӮ
иӢҘдҫқж¬ЎеҶҷе…Ҙ"efei"гҖҒ"snow"гҖҒ"efei"пјҢеҲҷдјҡеҰӮдёӢпјҡ
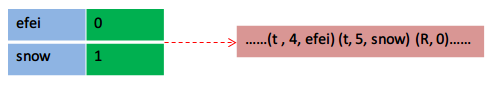
д»Һpycж–Ү件иҜ»е…Ҙж—¶пјҢдҫқйқ listпјҢйӮЈд№ҲеәҸеҸ·е°ұеҸҜд»ҘеҲ©з”ЁдёҠдәҶгҖӮ
вҖңPythonзј–иҜ‘з»“жһңд№ӢеҰӮдҪ•зҗҶи§ЈcodeеҜ№иұЎдёҺpycж–Ү件вҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ