жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
ж–Ү件еӯҳеӮЁеҲҶиЎҢеӯҳеӮЁе’ҢеҲ—еӯҳеӮЁпјҢжҜҸдёӘеӯҳеӮЁж јејҸйҮҢйқўеҸҲеҲҶдёҚеҗҢзҡ„зұ»еһӢпјҢеңЁе®һйҷ…зҡ„еә”з”ЁдёӯеҰӮдҪ•еҺ»дҪҝз”ЁпјҹжҖҺж ·еҺ»дҪҝз”Ёпјҹеҝ«жқҘеӣҙи§Ӯеҗ§пјҒ
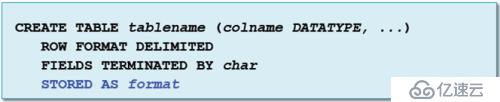
ж–Ү件еӯҳеӮЁж јејҸпјҢжҲ‘们еңЁд»Җд№Ҳж—¶еҖҷеҺ»жҢҮе®ҡе‘ўпјҹжҜ”еҰӮеңЁHveе’ҢIpalaдёӯеҺ»еҲӣе»әиЎЁзҡ„ж—¶еҖҷпјҢжҲ‘们йҷӨдәҶжҢҮе®ҡеҲ—е’ҢеҲҶйҡ”з¬ҰпјҢеңЁе®ғзҡ„е‘Ҫд»ӨиЎҢз»“е°ҫжңүSTORED ASеҸӮж•°пјҢиҝҷдёӘеҸӮж•°й»ҳи®ӨжҳҜж–Үжң¬ж јејҸпјҢдҪҶжҳҜж–Үжң¬дёҚйҖӮеҗҲжүҖжңүзҡ„еңәжҷҜпјҢйӮЈд№ҲеңЁиҝҷйҮҢжҲ‘们е°ұеҸҜд»Ҙж”№еҸҳж–Үжң¬зҡ„дҝЎжҒҜгҖӮ
йӮЈд№ҲеҲ°еә•жҲ‘们еә”иҜҘйҖүжӢ©е“Әдәӣж јејҸе‘ўпјҹжҜҸз§Қж јејҸйғҪжңүд»Җд№Ҳж ·зҡ„зү№зӮ№е‘ўпјҹжҲ‘们дёәд»Җд№ҲиҰҒеҺ»йҖүжӢ©иҝҷз§Қж јејҸе‘ўпјҹ
дёҖгҖҒж–Үжң¬ж–Ү件пјҡ
ж–Үжң¬ж–Ү件жҳҜHadoopйҮҢйқўжңҖеҹәжң¬зҡ„ж–Ү件зұ»еһӢпјҢеҸҜд»Ҙд»Һд»»дҪ•зј–зЁӢиҜӯиЁҖиҝӣиЎҢиҜ»жҲ–еҶҷпјҢе…је®№йҖ—еҸ·е’ҢtabеҲҶйҡ”зҡ„ж–Ү件д»ҘеҸҠе…¶е®ғеҫҲеӨҡзҡ„еә”з”ЁгҖӮиҖҢдё”ж–Үжң¬ж–Ү件зӣҙжҺҘеҸҜиҜ»зҡ„пјҢеӣ дёәйғҪжҳҜеӯ—з¬ҰдёІпјҢжүҖд»ҘеңЁDebugзҡ„ж—¶еҖҷйқһеёёжңүз”ЁгҖӮ然иҖҢпјҢж•°жҚ®еҲ°иҫҫдёҖе®ҡ规模пјҢиҝҷз§Қж јејҸжҳҜеҫҲдҪҺж•Ҳзҡ„пјҡпјҲ1пјүж–Үжң¬ж–Ү件жҠҠж•°еҖјиЎЁзӨәдёәstringжөӘиҙ№дәҶеӯҳеӮЁз©әй—ҙпјӣпјҲ2пјүеҫҲйҡҫиЎЁзӨәдәҢиҝӣеҲ¶зҡ„ж•°жҚ®пјҢжҜ”еҰӮеӣҫзүҮпјҢйҖҡеёёдҫқйқ е…¶д»–жҠҖжңҜпјҢжҜ”еҰӮBase64зј–з Ғ
жүҖд»Ҙж–Үжң¬ж–Үд»¶ж јејҸжҖ»з»“иө·жқҘе°ұжҳҜпјҡжҳ“ж“ҚдҪңпјҢдҪҶжҖ§иғҪдҪҺ
дәҢгҖҒеәҸеҲ—ж–Ү件
еәҸеҲ—ж–Ү件жң¬иҙЁжҳҜеҹәдәҺkey-valueй”®еҖјеҜ№зҡ„дәҢиҝӣеҲ¶е®№еҷЁж јејҸпјҢе®ғжҜ”ж–Үжң¬ж јејҸеҶ—дҪҷжӣҙе°‘пјҢжӣҙй«ҳж•ҲпјҢйҖӮеҗҲеӯҳеӮЁдәҢиҝӣеҲ¶ж•°жҚ®пјҢжҜ”еҰӮеӣҫзүҮгҖӮиҖҢдё”е®ғжҳҜJavaдё“жңүж јејҸ并且и·ҹHadoopзҙ§еҜҶз»“еҗҲгҖӮ
жүҖд»ҘеәҸеҲ—ж–Үд»¶ж јејҸжҖ»з»“иө·жқҘе°ұжҳҜпјҡжҖ§иғҪеҘҪпјҢдҪҶйҡҫж“ҚдҪң
дёүгҖҒAvroж•°жҚ®ж–Ү件
Avroж•°жҚ®ж–Ү件жҳҜдәҢиҝӣеҲ¶зј–з ҒпјҢеӯҳеӮЁж•ҲзҺҮжӣҙеҘҪгҖӮе®ғдёҚд»…еҸҜд»ҘеңЁHadoopз”ҹжҖҒзі»з»ҹеҫ—еҲ°е№ҝжіӣж”ҜжҢҒпјҢиҝҳеҸҜд»ҘеңЁHadoopд№ӢеӨ–дҪҝз”ЁгҖӮе®ғжҳҜй•ҝжңҹеӯҳеӮЁйҮҚиҰҒж•°жҚ®зҡ„зҗҶжғійҖүжӢ©пјҢеҸҜд»ҘйҖҡиҝҮеӨҡз§ҚиҜӯиЁҖиҜ»еҶҷгҖӮ
иҖҢдё”е®ғеҶ…еөҢschemaж–Ү件пјҢйҖҡиҝҮиҝҷдёӘж–Ү件жҲ‘们еҸҜд»ҘеҫҲиҪ»жқҫзҡ„еғҸиЎЁдёҖж ·еҺ»е®ҡд№үж•°жҚ®зҡ„жЁЎејҸпјҢеҸҜд»ҘзҒөжҙ»еҲ¶е®ҡеӯ—ж®өеҸҠеӯ—ж®өзұ»еһӢгҖӮSchemaжј”еҢ–еҸҜд»ҘйҖӮеә”еҗ„з§ҚеҸҳеҢ–пјҢжҜ”еҰӮеҪ“еүҚжҢҮе®ҡдёҖдёӘSchemaзұ»еһӢпјҢе°ҶжқҘеўһеҠ дәҶдёҖдәӣж•°жҚ®з»“жһ„гҖҒеҲ йҷӨдәҶдёҖдәӣж•°жҚ®гҖҒзұ»еһӢеҸ‘з”ҹдәҶеҸҳжӣҙгҖҒй•ҝеәҰеҸ‘з”ҹдәҶеҸҳжӣҙпјҢйғҪжҳҜеҸҜд»Ҙеә”еҜ№зҡ„гҖӮ
жүҖд»ҘAvroж•°жҚ®ж–Үд»¶ж јејҸжҖ»з»“иө·жқҘе°ұжҳҜпјҡжһҒеҘҪзҡ„ж“ҚдҪңжҖ§е’ҢжҖ§иғҪпјҢжҳҜHadoopйҖҡз”ЁеӯҳеӮЁзҡ„жңҖдҪійҖүжӢ©гҖӮ
д»ҘдёҠд»Ӣз»Қзҡ„дёүз§Қж јејҸйғҪжҳҜиЎҢеӯҳеӮЁпјҢдҪҶжҳҜHadoopйҮҢйқўиҝҳжңүдёҖдәӣеҲ—еӯҳеӮЁж јејҸгҖӮе…ёеһӢзҡ„OLTPд»ҘиЎҢзҡ„еҪўејҸжқҘеӯҳеӮЁпјҢе°ұжҳҜд»Ҙиҝһз»ӯзҡ„иЎҢжқҘеӯҳеӮЁеҲ°иҝһз»ӯзҡ„еқ—пјҢеҪ“жҲ‘们иҝӣиЎҢйҡҸжңәзҡ„еҜ»еҖји®ҝй—®зҡ„ж—¶еҖҷпјҢжҲ‘们йҖҡеёёдјҡеҺ»еҠ дёҖдәӣжқЎд»¶пјҢеҜ№дәҺиЎҢеӯҳеӮЁиҖҢиЁҖеҸҜд»Ҙиҝ…йҖҹе®ҡд№үеҲ°еқ—жүҖеңЁдҪҚзҪ®пјҢ然еҗҺжҸҗеҸ–иЎҢзҡ„ж•°жҚ®гҖӮиҖҢеҲ—еӯҳеӮЁд»ҘеҲ—дёәеҚ•дҪҚиҝӣиЎҢеӯҳеӮЁпјҢеҰӮжһңе°ҶеҲ—еӯҳеӮЁеә”з”ЁдәҺOLTPжҲ‘们иҰҒе®ҡд№үеҲ°зү№е®ҡиЎҢиҝӣиЎҢжү«жҸҸзҡ„ж—¶еҖҷпјҢе®ғдјҡжү«жҸҸеҲ°жүҖжңүзҡ„еҲ—гҖӮеҜ№дәҺеҲ—еӯҳеӮЁеә”з”ЁеҲ°еңЁзәҝдәӢеҠЎеңәжҷҜеӨ„зҗҶе°ұжҳҜдёҖдёӘеҫҲжҒҗжҖ–зҡ„дәӢжғ…пјҢеҲ—еӯҳеӮЁзҡ„ж„Ҹд№үеңЁдәҺеә”з”ЁдәҺеӨ§ж•°жҚ®еҲҶжһҗеңәжҷҜпјҢжҜ”еҰӮиҝӣиЎҢзү№еҫҒеҖјзҡ„жҠҪеҸ–пјҢеҸҳйҮҸзҡ„зӯӣйҖүпјҢйҖҡеёёеңЁеӨ§ж•°жҚ®еңәжҷҜеә”з”ЁдёӯжҲ‘们дјҡеӨ§йҮҸзҡ„еә”з”Ёе®ҪиЎЁпјҢеҸҜиғҪеҜ№дәҺжҹҗдёҖдёҡеҠЎеҲҶжһҗиҖҢиЁҖпјҢжҲ‘们еҸӘйңҖиҰҒдҪҝз”Ёе…¶дёӯдёҖдёӘжҲ–еҮ еҚҒдёӘиҝҷж ·зҡ„еҲ—пјҢйӮЈд№Ҳе°ұеҸҜеҺ»йҖүжӢ©дёҖдәӣеҲ—иҝӣиЎҢжү«жҸҸпјҢдёҚдјҡжү«жҸҸеҲ°е…ЁиЎЁгҖӮиЎҢеӯҳеӮЁдёҺеҲ—еӯҳеӮЁе№¶жІЎжңүз»қеҜ№зҡ„еҘҪеқҸд№ӢеҲҶпјҢеҸӘжҳҜеҪјжӯӨйҖӮз”Ёзҡ„еңәжҷҜдёҚдёҖж ·гҖӮ
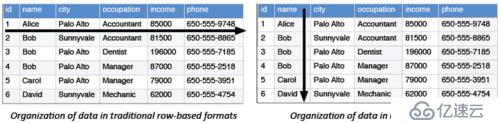
дёӢйқўжҲ‘们зңӢдёҖдёӢеҲ—еӯҳеӮЁйҮҚиҰҒзҡ„еӯҳеӮЁж–№ејҸпјҡ
дёҖгҖҒParquetж–Ү件
Parquetж–Үд»¶ж јејҸйқһеёёйҮҚиҰҒпјҢеңЁжңӘжқҘд№ҹе°Ҷдјҡиў«е№ҝжіӣзҡ„дҪҝз”ЁгҖӮжҲ‘们жҠҠHDFSз§°дҪңжҳҜеӨ§ж•°жҚ®еӯҳеӮЁдәӢе®һж ҮеҮҶзҡ„иҜқпјҢйӮЈд№ҲParquetж–Ү件е°ұжҳҜж–Ү件еӯҳеӮЁж јејҸзҡ„дәӢе®һж ҮеҮҶгҖӮзӣ®еүҚsparkе·Із»ҸжҠҠе®ғдҪңдёәй»ҳи®Өзҡ„ж–Ү件еӯҳеӮЁж јејҸпјҢеҸҜи§Ғе®ғзҡ„йҮҚиҰҒжҖ§гҖӮжңҖеҲқз”ұclouderaе’ҢtwitterејҖеҸ‘зҡ„ејҖжәҗеҲ—еӯҳеӮЁж јејҸпјҢеңЁMapReduceгҖҒHiveгҖҒPigгҖҒImpalaгҖҒSparkгҖҒCrunchе’Ңе…¶д»–йЎ№зӣ®дёӯж”ҜжҢҒеә”з”ЁгҖӮе®ғе’ҢAvroж•°жҚ®ж–Ү件йғҪжңүSchemaе…ғж•°жҚ®пјҢеҢәеҲ«еҸӘжҳҜParquetж–Ү件жҳҜеҲ—еӯҳеӮЁпјҢAvroж•°жҚ®ж–Ү件жҳҜиЎҢеӯҳеӮЁгҖӮиҝҷйҮҢеҝ…йЎ»иҰҒејәи°ғзҡ„жҳҜParquetж–Ү件еңЁзј–з Ғж–№йқўиҝӣиЎҢдәҶдёҖдәӣйўқеӨ–дјҳеҢ–пјҢеҮҸе°‘еӯҳеӮЁз©әй—ҙпјҢеўһеҠ дәҶжҖ§иғҪгҖӮ
жүҖд»ҘParquetж–Ү件жҖ»з»“иө·жқҘе°ұжҳҜпјҡжһҒеҘҪзҡ„ж“ҚдҪңжҖ§е’ҢжҖ§иғҪпјҢжҳҜеҹәдәҺеҲ—и®ҝй—®жЁЎејҸзҡ„жңҖдҪійҖүжӢ©гҖӮ
ж–Ү件еӯҳеӮЁж јејҸпјҢйңҖиҰҒйҮҚзӮ№еҺ»жҠҠжҸЎе’ҢеӯҰд№ пјҢе°Өе…¶жҳҜжҜҸз§ҚеӯҳеӮЁж јејҸдјҳеҠЈеҠҝпјҢеҝ…йЎ»зҶҹз»ғжҺҢжҸЎпјҢжүҚеҸҜд»ҘеңЁдҪҝз”ЁдёӯжӣҙеҘҪзҡ„еҺ»йҖүжӢ©дҪҝз”ЁгҖӮеҸҰеӨ–пјҢжҲ‘们еңЁе№іеёёзҡ„е·ҘдҪңдёӯд№ҹиҰҒеӨҡеҺ»е’ҢеҲ«дәәеҲҶдә«дәӨжөҒпјҢиҝҷж ·жүҚдјҡжӣҙеҘҪзҡ„е®Ңе–„иҮӘе·ұзҡ„зҹҘиҜҶжһ¶жһ„пјҢжҸҗеҚҮиҮӘе·ұзҡ„жҠҖжңҜж°ҙе№іпјҢеҸӢжғ…жҺЁиҚҗвҖңеӨ§ж•°жҚ®cnвҖқеҫ®дҝЎе…¬дј—еҸ·пјҢзӯүдҪ жқҘдәӨжөҒпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ