您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》

本周热门学术研究
对于机器人应用来说,回答目标是什么以及目标在哪这一问题,并提供一种空间和语义不确定性的衡量标准,是目标检测需要优先解决的问题。
日前,由Google支持的澳大利亚研究委员会旗下的机器人卓越视觉中心开启了第一场关于概率目标检测的挑战赛。计算机和机器人视觉的挑战要求参与者检测视频数据中的对象,并提供空间和语义不确定性的准确估计。

图1:示例图片来自用来产生挑战测试数据的模拟环境,第一排和左下图是用于测试序列的环境,右下图是用于验证序列。
这场挑战没有设置门槛,人工智能社区中对目标检测有兴趣的人都可以参加,这是一场很不错的挑战。挑战的测试数据集包含来自18个模拟室内视频序列中的56,000多张图像,将在用于挑战的公共服务器中进行评估,该服务器仅在公开比赛阶段开放。参与者将获得名次并共享5000澳元奖金。
这一新的挑战是对概率目标检测的介绍,将现有的目标检测任务提升到高端机器人应用中的空间和语义不确定性。总的来说,它将提高机器人应用在物体检测方面的技术水平。
更多细节:
https://nikosuenderhauf.github.io/roboticvisionchallenges/object-detection
原文:
https://arxiv.org/abs/1903.07840
研究人员设计了一种系统,该系统可以使用单个输入图像从期望的视点为特定对象生成一组图像,供移动操作机器人使用。
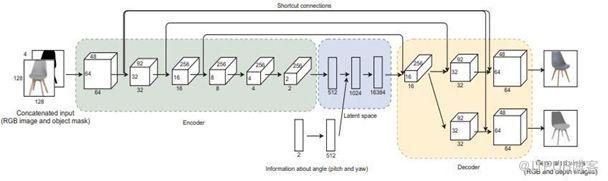
所提出的方法是一种深层神经网络,训练它从多个视角“想象”物体的外观。它将对象的单个RGB图像作为输入,并返回一组RGB和深度图像(位深度图像),从而消除了传统、耗时的扫描。
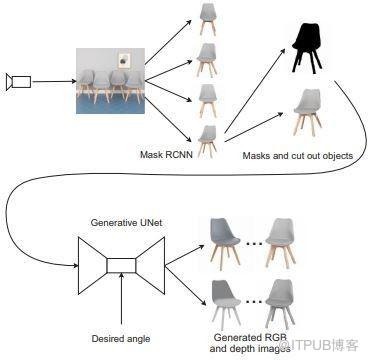
虽然深层神经网络已经实现了单视角重建,但由于重建过程计算量大,很难直接获得重建对象的精准细节。该方法采用基于CNN模型的目标检测器从自然环境中提取目标,由神经网络生成一组RGB和深度图像(位深度图像,目前Ps软件中的位深度为16位)。该方法已在生成图像和真实图像上进行了测试,证明其是非常有效的。
基于图像生成具有为重建物体提供更好的空间分辨率的潜力。因此,该方法在移动操作机器人领域中是有必要的。这种方法有可能帮助机器人更好地理解一个物体的空间属性,而不需要做一个完整的扫描。
原文:
https://arxiv.org/abs/1903.06814
由于实际数据和合成数据之间存在着领域差距,而且很难将在模拟器中学习到的策略传输到真实场景中。在过去,领域随机化(随机领域数据生成,domain randomization)通过使用随机变换(如随机对象形状和纹理)增强合成数据来解决这一挑战。
近年来,研究人员对领域随机化的研究做出了新的贡献,对Sim2Real迁移的增强技术进行了优化,使其能够在没有真实图像的情况下实现与领域无关的策略学习。
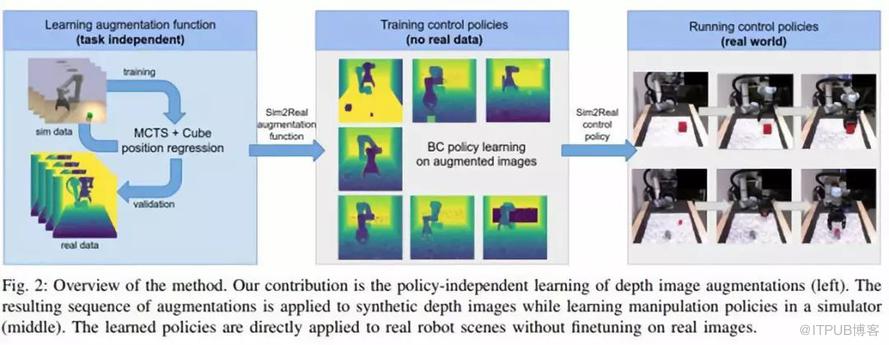
他们设计了一种利用目标定位进行深度图像增强的高效搜索方法。在策略学习过程中,利用生成的随机变换序列来增强合成深度图像。
为了评估这种迁移的程度,研究人员提出了一种目标位置估计的委托任务,这种任务只需要很少的真实数据。新方法大大提高了在真实机器人上评估操作任务的准确性。
该方法在模拟环境中促进了操作策略的有效学习。这是非常有益的,因为模拟器可以促进可伸缩性,并在模型训练期间提供对底层空间的访问。此外,新的方法不需要真实图像来实现策略学习,可以应用于各种操作任务。
原文:
https://arxiv.org/abs/1903.07740
研究人员提出了一种DC-SPP-YOLO方法来提高YOLOv2目标的检测精度。DC-SPP方法通过优化基础网络的连接结构来改进YOLOv2,并引入了多尺度局部区域特征提取。因此,这个提出的新方法比YOLOv2更精确。
它达到了接近YOLOv2的目标检测速度,并且比传统的目标检测方法如反卷积单镜头检测器(DSSD)、标度可转移检测网络(STDN)和YOLOv3更高。
DC-SPP-YOLO特别利用YOLOv2基础网络中卷积层的连接来加强特征提取,使消失梯度问题最小化。在此基础上,提出了一种改进的空间金字塔池,并将多尺度局部区域特征串联起来,使网络能够更全面地学习目标特征。
基于一种新的损失函数训练DC-SPP-YOLO模型,该损失函数由均方误差和交叉熵组成,能更准确地实现目标检测。实验结果表明,DC-SPP-YOLO在PASCAL VOC和UA-DETRAC数据集上的mAP均大于YOLOv2。
潜在用途及影响
通过加强特征提取,利用多尺度局部区域特征,DC-SPP-YOLO实现了优于YOLOv2的实时目标检测精度。在安全监控、医疗诊断、自动驾驶等方面,该方法可用于实现更精确的、最先进的计算机视觉应用。
详情请见:
https://arxiv.org/abs/1903.08589
最近的研究提出了一种“智能”的深度学习半自动分割方法,能够在医学图像中对感兴趣的区域进行交互描述。这种提出的方法采用了一种FCNN的架构来执行交互式二维医学图像分割。
那么它是如何使用交互的?网络被训练成每次只分割一个感兴趣的区域,并考虑到用户以单击一次或多次鼠标的形式输入的内容。该模型还被训练去使用原始2D图像和一个“引导信号”作为输入。然后它会输出特定分割对象的二进制掩码。研究人员已经证明了它可以被用于在腹部CT中分割各种器官。这种新方法提供了非常准确的结果,可以根据用户的选择以快速、智能和自发的方式进行纠正。
潜在用途及影响
该方法可以快速地提供高端的二维分割结果。它也有潜力解决紧迫的临床挑战,并可用于提高分割精度的众多医学成像应用,如肿瘤定位、手术规划、诊断、手术内导航、虚拟手术模拟、组织体积测量等。其他应用包括可视化、放射治疗规划、3D打印、图像分类、自然语言处理等等。
原文:
https://arxiv.org/abs/1903.08205
其他爆款论文
利用3D点云增强可穿戴机器人的环境分类。
原文:
https://arxiv.org/abs/1903.06846v1
用于道路驾驶图像实时语义分割的预训练模型。
原文:
https://arxiv.org/abs/1903.08469
第一种基于事件的运动分割数据集学习方法和事件相机的学习管道。
原文:
https://arxiv.org/abs/1903.07520
即插即用的磁共振成像(MRI)。
原文:
https://arxiv.org/abs/1903.08616
AI新闻
谷歌在德国作曲家巴赫生日当天发布了AI涂鸦来纪念他。
详情请见:First ever AI doodle that allows users to make music.
https://www.newsweek.com/google-doodle-bach-birthday-when-march-21-22-1366826
结合计算密集型的人工智能应用程序和最近发布的新人工智能服务器。
详情请见:AI Server Enabled with NVIDIA GPUs for edge computing
https://www.marketwatch.com/press-release/inspur-releases-edge-computing-ai-server-enabled-with-nvidia-gpus-2019-03-19?mod=mw_quote_news
真的有可能创造出类似人类的人工智能吗?
详情请见:How to create AI that is more human

Christopher Dossman是Wonder Technologies的首席数据科学家,在北京生活5年。他是深度学习系统部署方面的专家,在开发新的AI产品方面拥有丰富的经验。除了卓越的工程经验,他还教授了1000名学生了解深度学习基础。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。