жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңжҖҺд№Ҳз”ЁPythonзҲ¬иҷ«йў„жөӢд»Ҡе№ҙеҸҢеҚҒдёҖй”Җе”®йўқвҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңжҖҺд№Ҳз”ЁPythonзҲ¬иҷ«йў„жөӢд»Ҡе№ҙеҸҢеҚҒдёҖй”Җе”®йўқвҖқеҗ§!
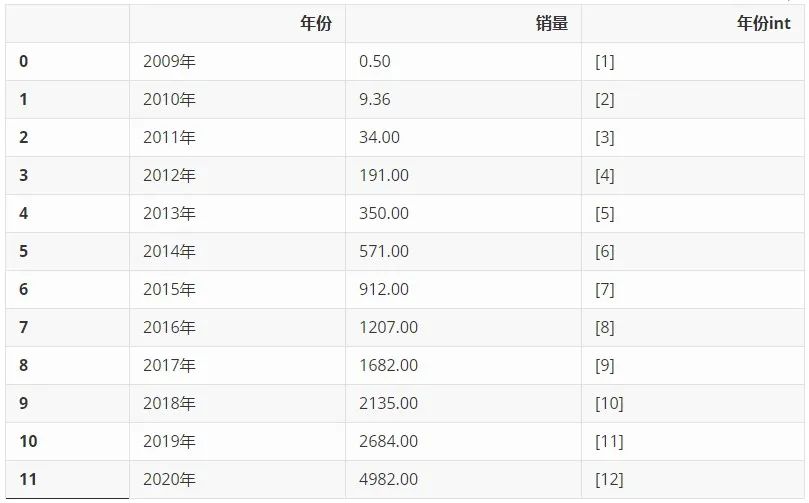
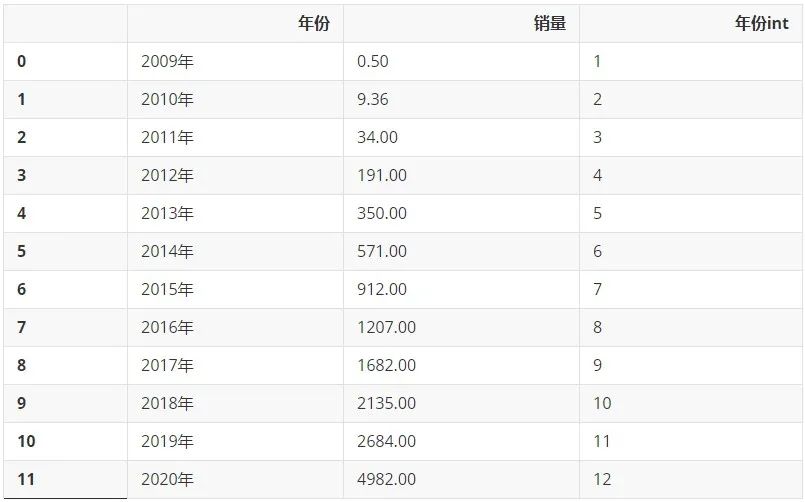
д»ҺзҪ‘дёҠжҗңйӣҶжқҘеҺҶе№ҙж·ҳе®қеӨ©зҢ«еҸҢеҚҒдёҖй”Җе”®йўқж•°жҚ®пјҢеҚ•дҪҚдёәдәҝе…ғпјҢеҲ©з”Ё Pandas ж•ҙзҗҶжҲҗ DataframeпјҢеҸҲж·»еҠ дәҶдёҖеҲ—'е№ҙд»Ҫint'пјҢз•ҷдҪңеҗҺз»ӯзҡ„и®Ўз®—дҪҝз”ЁгҖӮ
import pandas as pd
# ж•°жҚ®дёәзҪ‘з»ң收йӣҶпјҢеҺҶе№ҙж·ҳе®қеӨ©зҢ«еҸҢеҚҒдёҖй”Җе”®йўқж•°жҚ®пјҢеҚ•дҪҚдёәдәҝе…ғпјҢд»…еҒҡзӨәиҢғ
double11_sales = {'2009е№ҙ': [0.50],
'2010е№ҙ':[9.36],
'2011е№ҙ':[34],
'2012е№ҙ':[191],
'2013е№ҙ':[350],
'2014е№ҙ':[571],
'2015е№ҙ':[912],
'2016е№ҙ':[1207],
'2017е№ҙ':[1682],
'2018е№ҙ':[2135],
'2019е№ҙ':[2684],
'2020е№ҙ':[4982],
}
df = pd.DataFrame(double11_sales).T.reset_index()
df.rename(columns={'index':'е№ҙд»Ҫ',0:'й”ҖйҮҸ'},inplace=True)
df['е№ҙд»Ҫint'] = [[i] for i in list(range(1,len(df['е№ҙд»Ҫ'])+1))]
df.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
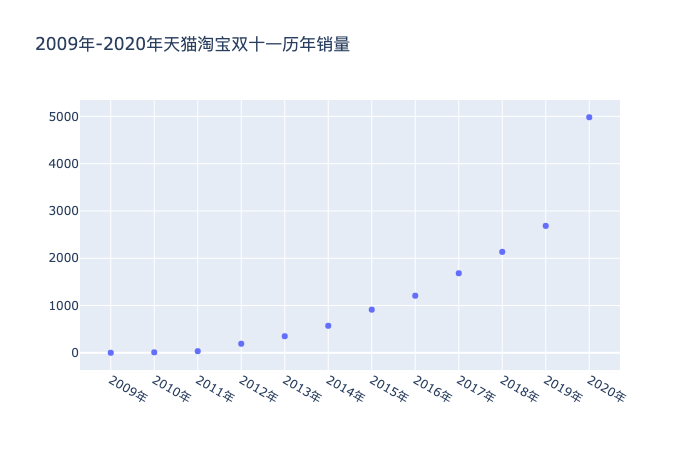
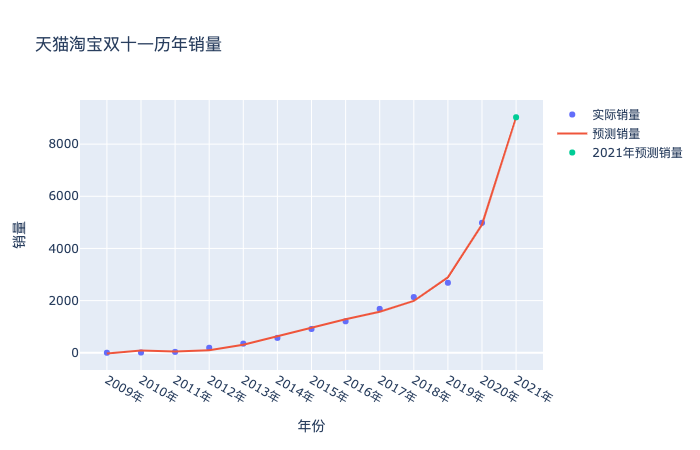
еҲ©з”Ё plotly е·Ҙе…·еҢ…пјҢе°Ҷе№ҙд»ҪеҜ№еә”й”Җе”®йҮҸзҡ„ж•ЈзӮ№еӣҫз»ҳеҲ¶еҮәжқҘпјҢеҸҜд»ҘжҳҺжҳҫзңӢеҲ°2020е№ҙзҡ„ж•°жҚ®з«Ӣ马йЈҷеҚҮгҖӮ
# ж•ЈзӮ№еӣҫ import plotly as py import plotly.graph_objs as go import numpy as np year = df[:]['е№ҙд»Ҫ'] sales = df['й”ҖйҮҸ'] trace = go.Scatter( x=year, y=sales, mode='markers' ) data = [trace] layout = go.Layout(title='2009е№ҙ-2020е№ҙеӨ©зҢ«ж·ҳе®қеҸҢеҚҒдёҖеҺҶе№ҙй”ҖйҮҸ') fig = go.Figure(data=data, layout=layout) fig.show()
дёҖе…ғеӨҡж¬ЎзәҝжҖ§еӣһеҪ’
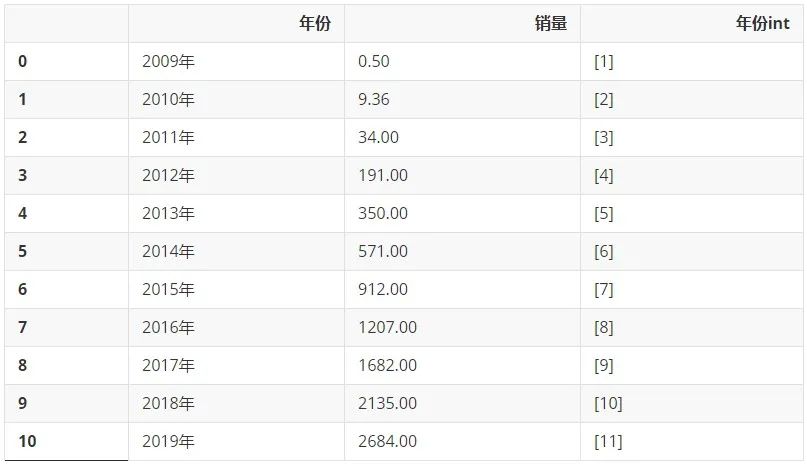
жҲ‘们е…ҲжқҘеӣһйЎҫдёҖдёӢ2009-2019е№ҙзҡ„ж•°жҚ®еӨҡд№ҲзҫҺеҰҷгҖӮе…ҲеҸӘйҖүеҸ–2009-2019е№ҙзҡ„ж•°жҚ®пјҡ
df_2009_2019 = df[:-1] df_2009_2019
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
йҖҡиҝҮд»ҘдёӢд»Јз Ғз”ҹжҲҗдәҢж¬ЎйЎ№ж•°жҚ®пјҡ
from sklearn.preprocessing import PolynomialFeatures poly_reg = PolynomialFeatures(degree=2) X_ = poly_reg.fit_transform(list(df_2009_2019['е№ҙд»Ҫint']))
1.第дёҖиЎҢд»Јз Ғеј•е…Ҙз”ЁдәҺеўһеҠ дёҖдёӘеӨҡж¬ЎйЎ№еҶ…е®№зҡ„жЁЎеқ— PolynomialFeatures
2.第дәҢиЎҢд»Јз Ғи®ҫзҪ®жңҖй«ҳж¬ЎйЎ№дёәдәҢж¬ЎйЎ№пјҢдёәз”ҹжҲҗдәҢж¬ЎйЎ№ж•°жҚ®пјҲxе№іж–№пјүеҒҡеҮҶеӨҮ
3.第дёүиЎҢд»Јз Ғе°ҶеҺҹжңүзҡ„XиҪ¬жҚўдёәдёҖдёӘж–°зҡ„дәҢз»ҙж•°з»„X_пјҢиҜҘдәҢз»ҙж•°жҚ®еҢ…еҗ«ж–°з”ҹжҲҗзҡ„дәҢж¬ЎйЎ№ж•°жҚ®пјҲxе№іж–№пјүе’ҢеҺҹжңүзҡ„дёҖж¬ЎйЎ№ж•°жҚ®пјҲxпјү
X_ зҡ„еҶ…е®№дёәдёӢж–№д»Јз ҒжүҖзӨәзҡ„дёҖдёӘдәҢз»ҙж•°з»„пјҢе…¶дёӯ第дёҖеҲ—ж•°жҚ®дёәеёёж•°йЎ№пјҲе…¶е®һе°ұжҳҜXзҡ„0ж¬Ўж–№пјүпјҢжІЎжңүзү№ж®Ҡеҗ«д№үпјҢеҜ№еҲҶжһҗз»“жһңдёҚдјҡдә§з”ҹеҪұе“Қпјӣ第дәҢеҲ—ж•°жҚ®дёәеҺҹжңүзҡ„дёҖж¬ЎйЎ№ж•°жҚ®пјҲxпјүпјӣ第дёүеҲ—ж•°жҚ®дёәж–°з”ҹжҲҗзҡ„дәҢж¬ЎйЎ№ж•°жҚ®пјҲxзҡ„е№іж–№пјүгҖӮ
X_
array([[ 1., 1., 1.], [ 1., 2., 4.], [ 1., 3., 9.], [ 1., 4., 16.], [ 1., 5., 25.], [ 1., 6., 36.], [ 1., 7., 49.], [ 1., 8., 64.], [ 1., 9., 81.], [ 1., 10., 100.], [ 1., 11., 121.]])
from sklearn.linear_model import LinearRegression regr = LinearRegression() regr.fit(X_,list(df_2009_2019['й”ҖйҮҸ']))
LinearRegression()
1.第дёҖиЎҢд»Јз Ғд»Һ Scikit-Learn еә“еј•е…ҘзәҝжҖ§еӣһеҪ’зҡ„зӣёе…іжЁЎеқ— LinearRegressionпјӣ
2.第дәҢиЎҢд»Јз Ғжһ„йҖ дёҖдёӘеҲқе§Ӣзҡ„зәҝжҖ§еӣһеҪ’жЁЎеһӢ并е‘ҪеҗҚдёә regrпјӣ
3.第дёүиЎҢд»Јз Ғз”Ёfit() еҮҪж•°е®ҢжҲҗжЁЎеһӢжҗӯе»әпјҢжӯӨж—¶зҡ„regrе°ұжҳҜдёҖдёӘжҗӯе»әеҘҪзҡ„зәҝжҖ§еӣһеҪ’жЁЎеһӢгҖӮ
жҺҘдёӢжқҘе°ұеҸҜд»ҘеҲ©з”Ёжҗӯе»әеҘҪзҡ„жЁЎеһӢ regr жқҘйў„жөӢж•°жҚ®гҖӮеҠ дёҠиҮӘеҸҳйҮҸжҳҜ12пјҢйӮЈд№ҲдҪҝз”Ё predict() еҮҪж•°е°ұиғҪйў„жөӢеҜ№еә”зҡ„еӣ еҸҳйҮҸжңүпјҢд»Јз ҒеҰӮдёӢпјҡ
XX_ = poly_reg.fit_transform([[12]])
XX_
array([[ 1., 12., 144.]])
y = regr.predict(XX_) y
array([3282.23478788])
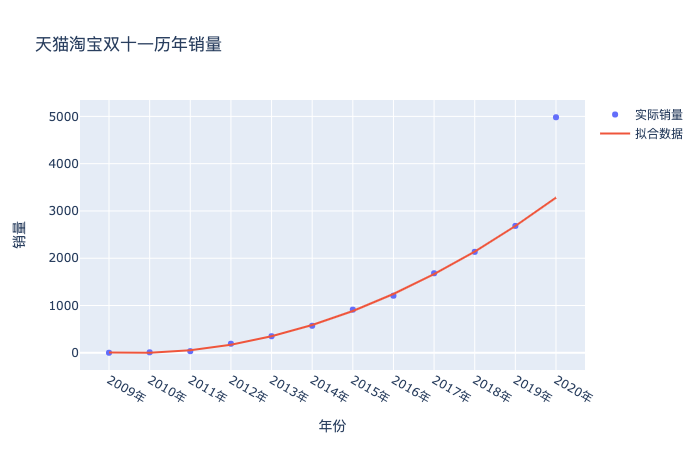
иҝҷйҮҢжҲ‘们е°ұеҫ—еҲ°дәҶеҰӮжһңжҢүз…§иҝҷдёӘи¶ӢеҠҝ2009-2019зҡ„и¶ӢеҠҝйў„жөӢ2020зҡ„з»“жһңпјҢе°ұжҳҜ3282пјҢдҪҶе®һйҷ…еҚҙжҳҜ4982дәҝпјҢеҺҹеӣ е°ұжҳҜдёҠж–ҮжҸҗеҲ°зҡ„еҗҲ并计算дәҶпјҢйҮ‘йўқдёҖдёӢеӯҗеҸҳеӨ§дәҶпјҢз»ҳеҲ¶жҲҗеӣҫпјҢе°ұжҳҜдёӢйқўиҝҷж ·пјҡ
# ж•ЈзӮ№еӣҫ import plotly as py import plotly.graph_objs as go import numpy as np year = list(df['е№ҙд»Ҫ']) sales = df['й”ҖйҮҸ'] trace1 = go.Scatter( x=year, y=sales, mode='markers', name="е®һйҷ…й”ҖйҮҸ" # 第дёҖдёӘеӣҫдҫӢеҗҚз§° ) XX_ = poly_reg.fit_transform(list(df['е№ҙд»Ҫint'])+[[13]]) regr = LinearRegression() regr.fit(X_,list(df_2009_2019['й”ҖйҮҸ'])) trace2 = go.Scatter( x=list(df['е№ҙд»Ҫ']), y=regr.predict(XX_), mode='lines', name="жӢҹеҗҲж•°жҚ®", # 第2дёӘеӣҫдҫӢеҗҚз§° ) data = [trace1,trace2] layout = go.Layout(title='еӨ©зҢ«ж·ҳе®қеҸҢеҚҒдёҖеҺҶе№ҙй”ҖйҮҸ', xaxis_title='е№ҙд»Ҫ', yaxis_title='й”ҖйҮҸ') fig = go.Figure(data=data, layout=layout) fig.show()
既然数жҚ®еҸ‘з”ҹдәҶе·ЁеӨ§зҡ„еҒҸзҰ»пјҢе’ұ们д№ҹеҲ«ж·ұ究дәҶпјҢе°ұеӨ§еҠӣеҮәеҘҮиҝ№гҖӮеҗҢж ·зҡ„ж–№жі•пјҢжҠҠ2020е№ҙзҡ„зңҹе®һж•°жҚ®зәіе…ҘиҝӣжқҘпјҢдәҢиҜқдёҚиҜҙжӢҹеҗҲдёҖж ·пјҢзңӢзңӢдјҡеҫ—еҲ°д»Җд№Ҳз»“жһңпјҡ
from sklearn.preprocessing import PolynomialFeatures poly_reg = PolynomialFeatures(degree=5) X_ = poly_reg.fit_transform(list(df['е№ҙд»Ҫint']))
## йў„жөӢ2020е№ҙ regr = LinearRegression() regr.fit(X_,list(df['й”ҖйҮҸ']))
LinearRegression()
XXX_ = poly_reg.fit_transform(list(df['е№ҙд»Ҫint'])+[[13]])
# ж•ЈзӮ№еӣҫ import plotly as py import plotly.graph_objs as go import numpy as np year = list(df['е№ҙд»Ҫ']) sales = df['й”ҖйҮҸ'] trace1 = go.Scatter( x=year+['2021е№ҙ','2022е№ҙ','2023е№ҙ'], y=sales, mode='markers', name="е®һйҷ…й”ҖйҮҸ" # 第дёҖдёӘеӣҫдҫӢеҗҚз§° ) trace2 = go.Scatter( x=year+['2021е№ҙ','2022е№ҙ','2023е№ҙ'], y=regr.predict(XXX_), mode='lines', name="йў„жөӢй”ҖйҮҸ" # 第дёҖдёӘеӣҫдҫӢеҗҚз§° ) trace3 = go.Scatter( x=['2021е№ҙ'], y=[regr.predict(XXX_)[-1]], mode='markers', name="2021е№ҙйў„жөӢй”ҖйҮҸ" # 第дёҖдёӘеӣҫдҫӢеҗҚз§° ) data = [trace1,trace2,trace3] layout = go.Layout(title='еӨ©зҢ«ж·ҳе®қеҸҢеҚҒдёҖеҺҶе№ҙй”ҖйҮҸ', xaxis_title='е№ҙд»Ҫ', yaxis_title='й”ҖйҮҸ') fig = go.Figure(data=data, layout=layout) fig.show()
еңЁйҖүжӢ©жЁЎеһӢдёӯзҡ„ж¬Ўж•°ж–№йқўпјҢеҸҜд»ҘйҖҡиҝҮи®ҫзҪ®зЁӢеәҸпјҢеҫӘзҺҜи®Ўз®—еҗ„дёӘж¬Ўж•°дёӢйў„жөӢиҜҜе·®пјҢ然еҗҺеҶҚж №жҚ®з»“жһңеҸҚйҖүеҸӮж•°гҖӮ
df_new = df.copy() df_new['е№ҙд»Ҫint'] = df['е№ҙд»Ҫint'].apply(lambda x: x[0]) df_new
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
# еӨҡйЎ№ејҸеӣһеҪ’йў„жөӢж¬Ўж•°йҖүжӢ©
# и®Ўз®— m ж¬ЎеӨҡйЎ№ејҸеӣһеҪ’йў„жөӢз»“жһңзҡ„ MSE иҜ„д»·жҢҮж Ү并з»ҳеӣҫ
from sklearn.pipeline import make_pipeline
from sklearn.metrics import mean_squared_error
train_df = df_new[:int(len(df)*0.95)]
test_df = df_new[int(len(df)*0.5):]
# е®ҡд№үи®ӯз»ғе’ҢжөӢиҜ•дҪҝз”Ёзҡ„иҮӘеҸҳйҮҸе’Ңеӣ еҸҳйҮҸ
train_x = train_df['е№ҙд»Ҫint'].values
train_y = train_df['й”ҖйҮҸ'].values
# print(train_x)
test_x = test_df['е№ҙд»Ҫint'].values
test_y = test_df['й”ҖйҮҸ'].values
train_x = train_x.reshape(len(train_x),1)
test_x = test_x.reshape(len(test_x),1)
train_y = train_y.reshape(len(train_y),1)
mse = [] # з”ЁдәҺеӯҳеӮЁеҗ„жңҖй«ҳж¬ЎеӨҡйЎ№ејҸ MSE еҖј
m = 1 # еҲқе§Ӣ m еҖј
m_max = 10 # и®ҫе®ҡжңҖй«ҳж¬Ўж•°
while m <= m_max:
model = make_pipeline(PolynomialFeatures(m, include_bias=False), LinearRegression())
model.fit(train_x, train_y) # и®ӯз»ғжЁЎеһӢ
pre_y = model.predict(test_x) # жөӢиҜ•жЁЎеһӢ
mse.append(mean_squared_error(test_y, pre_y.flatten())) # и®Ўз®— MSE
m = m + 1
print("MSE и®Ўз®—з»“жһң: ", mse)
# з»ҳеӣҫ
plt.plot([i for i in range(1, m_max + 1)], mse, 'r')
plt.scatter([i for i in range(1, m_max + 1)], mse)
# з»ҳеҲ¶еӣҫеҗҚз§°зӯү
plt.title("MSE of m degree of polynomial regression")
plt.xlabel("m")
plt.ylabel("MSE")MSE и®Ўз®—з»“жһң: [1088092.9621201046, 481951.27857828484, 478840.8575107471, 477235.9140442428, 484657.87153138855, 509758.1526412842, 344204.1969956556, 429874.9229308078, 8281846.231771571, 146298201.8473966]
Text(0, 0.5, 'MSE')
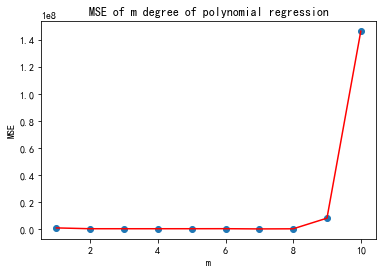
д»ҺиҜҜе·®з»“жһңеҸҜд»ҘзңӢеҲ°пјҢж¬Ўж•°еҸ–2еҲ°8иҜҜе·®еҹәжң¬зЁіе®ҡпјҢжІЎжңүжҳҺжҳҫзҡ„еҮҸе°‘дәҶпјҢдҪҶе…¶е®һдҪ иҜ•иҜ•е°ұзҹҘйҒ“пјҢж¬Ўж•°йҖүжӢ©3зҡ„ж—¶еҖҷпјҢйў„жөӢзҡ„й”ҖйҮҸжҳҜ6213дәҝе…ғпјҢж¬Ўж•°йҖүжӢ©5зҡ„ж—¶еҖҷпјҢйў„жөӢзҡ„й”ҖйҮҸжҳҜ9029дәҝе…ғпјҢеҜ№дәҺй”Җе”®йҮҸжқҘиҜҙпјҢиҝҷдёӘиҢғеӣҙе·Із»ҸеӨҹеӨ§зҡ„дәҶгҖӮжҲ‘д№ҹе°ұж–—иғҶзҢңеҲ°9029дәҝе…ғпјҢжҲ‘зҡ„иғҶйҮҸд№ҹе°ұйў„жөӢеҲ°иҝҷйҮҢдәҶпјҢз ҙдёҮдәҝе°ұеӨӘеӨёеј дәҶпјҢж¬ўиҝҺиғҶеӯҗеӨ§зҡ„еҗҢеӯҰз•ҷдёӢдҪ 们зҡ„йў„жөӢз»“жһңпјҢи®©жҲ‘们11жңҲ11ж—ҘпјҢжӢӯзӣ®д»Ҙеҫ…еҗ§гҖӮ
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңжҖҺд№Ҳз”ЁPythonзҲ¬иҷ«йў„жөӢд»Ҡе№ҙеҸҢеҚҒдёҖй”Җе”®йўқвҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ