您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了Python的进程及进程池是什么,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
进程是操作系统分配资源的基本单元,是程序隔离的边界。
程序只是一组指令的集合,它本身没有任何运行的含义,它是静态的。
进程程序的执行实例,是动态的,有自己的生命周期,有创建有撤销,存在是暂时的。
进程和程序不是一一对应的,一个程序可以对应多个进程,一个进程也可以执行一个或者多个程序。
我们可以这样理解:编写完的代码,没有运行时称为程序,正在运行的代码,会启动一个(或多个)进程。
在我们的操作系统⼯作时,任务数往往⼤于cpu核心数,即⼀定有⼀些任务正在执⾏,⽽另外⼀些任务在等待cpu,因此导致了进程有不同的状态。
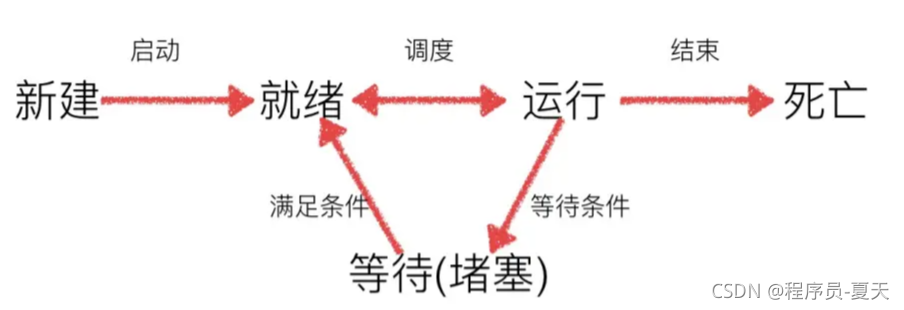
就绪状态:已满⾜运⾏条件,等待cpu执⾏
执⾏状态:cpu正在执⾏
等待状态:等待某些条件满⾜,比如⼀个程序sleep了,此时就处于等待状态
在Python中,进程是通过multiprocessing多进程模块来创建的,multiprocessing模块提供了⼀个Process类来创建进程对象。
Process语法结构:
Process(group, target, name, args, kwargs)
group:指定进程组,⼤多数情况下⽤不到
target:表示调用对象,即子进程要执行的任务
name:子进程的名称,可以不设定
args:给target指定的函数传递的参数,以元组的⽅式传递
kwargs:给target指定的函数传递命名参数
Process常用方法
p.start() 启动进程,并调用该子进程中的p.run()方法
p.join(timeout):主进程等待⼦进程执⾏结束再结束,timeout是可选的超时时间
is_alive():判断进程⼦进程是否还存活
p.run() 进程启动时运行的方法,正是它去调用target指定的函数
p.terminate() ⽴即终⽌⼦进程
Process创建的实例对象的常⽤属性
name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
pid:当前进程的pid(进程号)
import multiprocessing
import os
import time
def work(name):
print("子进程work正在运行......")
time.sleep(0.5)
print(name)
# 获取进程的名称
print("子进程name", multiprocessing.current_process())
# 获取进程的pid
print("子进程pid", multiprocessing.current_process().pid, os.getpid())
# 获取父进程的pid
print("父进程pid", os.getppid())
print("子进程运行结束......")
if __name__ == '__main__':
print("主进程启动")
# 获取进程的名称
print("主进程name", multiprocessing.current_process())
# 获取进程的pid
print("主进程pid", multiprocessing.current_process().pid, os.getpid())
# 创建进程
p = multiprocessing.Process(group=None, target=work, args=("tigeriaf", ))
# 启动进程
p.start()
print("主进程结束")
通过上述代码我们发现,multiprocessing.Process帮我们创建一个子进程,并且成功运行,但是我们发现,在子进程还没执行完的时候主进程就已经死了,那么这个子进程在主进程结束后就是一个孤儿进程,那么我们可以让主进程等待子进程结束后再结束吗?答案是可以的。 那就是通过p.join(),join()的作用是让主进程等子进程执行完再退出。
import multiprocessing
import os
import time
def work(name):
print("子进程work正在运行......")
time.sleep(0.5)
print(name)
# 获取进程的名称
print("子进程name", multiprocessing.current_process())
# 获取进程的pid
print("子进程pid", multiprocessing.current_process().pid, os.getpid())
# 获取父进程的pid
print("父进程pid", os.getppid())
print("子进程运行结束......")
if __name__ == '__main__':
print("主进程启动")
# 获取进程的名称
print("主进程name", multiprocessing.current_process())
# 获取进程的pid
print("主进程pid", multiprocessing.current_process().pid, os.getpid())
# 创建进程
p = multiprocessing.Process(group=None, target=work, args=("tigeriaf", ))
# 启动进程
p.start()
p.join()
print("主进程结束")运行结果:
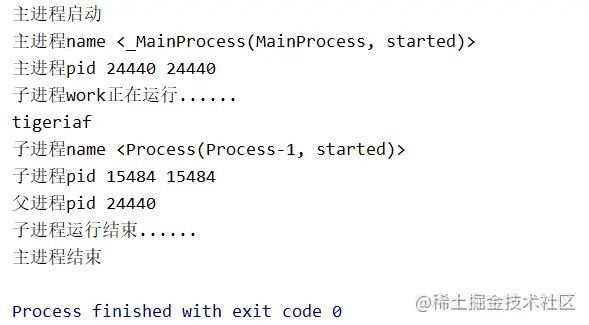
可以看出,主进程是在子进程结束后才结束的。
全局变量在多个进程中不共享,进程之间的数据是独立的,默认情况下互不影响。
import multiprocessing
# 定义全局变量
num = 99
def work1():
print("work1正在运行......")
global num # 在函数内部声明使⽤全局变量num
num = num + 1 # 对num值进⾏+1
print("work1 num = {}".format(num))
def work2():
print("work2正在运行......")
print("work2 num = {}".format(num))
if __name__ == '__main__':
# 创建进程p1
p1 = multiprocessing.Process(group=None, target=work1)
# 启动进程p1
p1.start()
# 创建进程p2
p2 = multiprocessing.Process(group=None, target=work2)
# 启动进程p2
p2.start()运行结果:
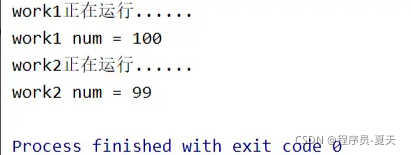
从运⾏结果可以看出,work1()函数对全局变量num的修改,在work2中并没有获取到,⽽还是原来的99,所以,进程之间是不够共享变量的。
上面说到,可以使用p.join()让主进程等待子进程结束后再结束,那么可不可以让子进程在主进程结束的时候就结束呢?答案是肯定的。 我们可以使用p.daemon = True或者p2.terminate()进行设置:
import multiprocessing
import time
def work1():
print("work1正在运行......")
time.sleep(4)
print("work1运行完毕")
def work2():
print("work2正在运行......")
time.sleep(10)
print("work2运行完毕")
if __name__ == '__main__':
# 创建进程p1
p1 = multiprocessing.Process(group=None, target=work1)
# 启动进程p1
p1.start()
# 创建进程p2
p2 = multiprocessing.Process(group=None, target=work2)
# 设置p2守护主进程
# 第⼀种⽅式
# p2.daemon = True 在start()之前设置,不然会抛异常
# 启动进程p2
p2.start()
time.sleep(2)
print("主进程运行完毕!")
# 第⼆种⽅式
p2.terminate()执行结果如下:
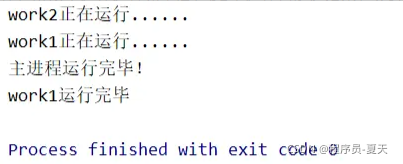
由于p2设置了守护主进程,所以主进程运行完毕后,p2子进程也随之结束,work2任务停止,而work1继续运行至结束。
当需要创建的⼦进程数量不多时, 可以直接利⽤multiprocessing.Process动态生成多个进程, 但如果要创建很多进程时,⼿动创建的话⼯作量会非常大,此时就可以⽤到multiprocessing模块提供的Pool去创建一个进程池。
multiprocessing.Pool常⽤函数:
apply_async(func, args, kwds):使⽤⾮阻塞⽅式调⽤func(任务并⾏执⾏),args为传递给func的参数列表,kwds为传递给func的关键字参数列表
apply(func, args, kwds):使⽤阻塞⽅式调⽤func,必须等待上⼀个进程执行完任务后才能执⾏下⼀个进程,了解即可,几乎不用
close():关闭Pool,使其不再接受新的任务
terminate():不管任务是否完成,⽴即终⽌
join():主进程阻塞,等待⼦进程的退出,必须在close或terminate之后使⽤
初始化Pool时,可以指定⼀个最⼤进程数,当有新的任务提交到Pool中时,如果进程池还没有满,那么就会创建⼀个新的进程⽤来执⾏该任务,但如果进程池已满(池中的进程数已经达到指定的最⼤值),那么该任务就会等待,直到池中有进程结束才会创建新的进程来执⾏。
from multiprocessing import Pool
import time
def work(i):
print("work'{}'执行中......".format(i), multiprocessing.current_process().name, multiprocessing.current_process().pid)
time.sleep(2)
print("work'{}'执行完毕......".format(i))
if __name__ == '__main__':
# 创建进程池
# Pool(3) 表示创建容量为3个进程的进程池
pool = Pool(3)
for i in range(10):
# 利⽤进程池同步执⾏work任务,进程池中的进程会等待上⼀个进程执行完任务后才能执⾏下⼀个进程
# pool.apply(work, (i, ))
# 使⽤异步⽅式执⾏work任务
pool.apply_async(work, (i, ))
# 进程池关闭之后不再接受新的请求
pool.close()
# 等待po中所有子进程结束,必须放在close()后面, 如果使⽤异步⽅式执⾏work任务,主线程不再等待⼦线程执⾏完毕再退出!
pool.join()执行结果为:
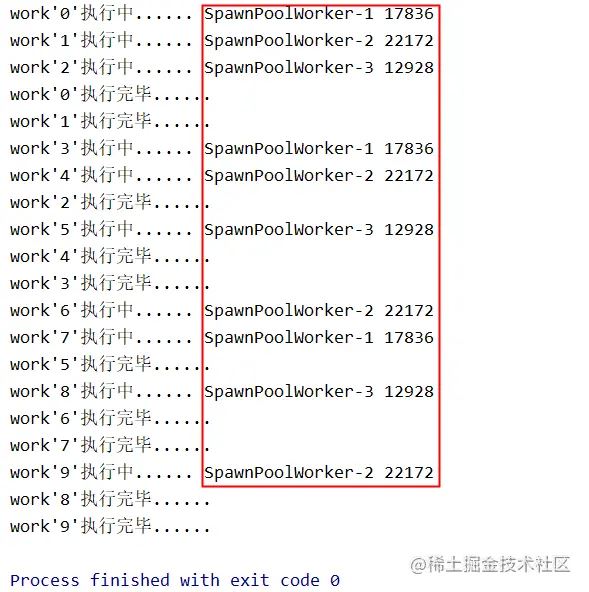
从结果我们可以看出,只有3个子进程在执行任务,此处我们使用的是异步⽅式(pool.apply_async(work, (i, )))执⾏work任务,如果是以同步方式(pool.apply(work, (i, )))执行,进程池中的进程会等待上⼀个进程执行完任务后才能执⾏下⼀个进程。
感谢你能够认真阅读完这篇文章,希望小编分享的“Python的进程及进程池是什么”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。