您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》

NameNode在启动的时候,需要将Mettadata加载到内存中去,随着集群扩大,元数据的量也随之增加,内存压力过大。
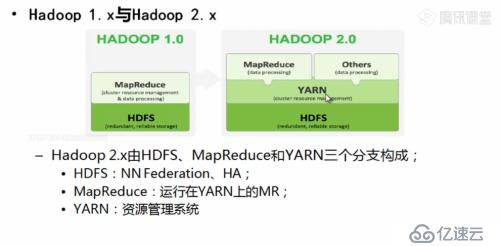
Hadoop1.x的缺点和解决办法:
单点故障------à HA 一主多备
内存受限 -----àNN Federation
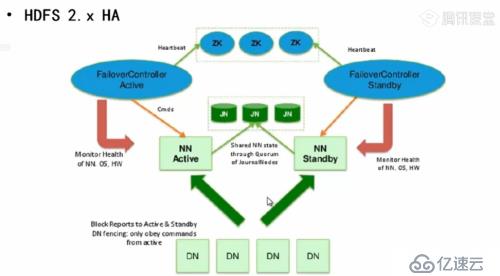
Hadoop节点之间的通信都是采用心跳机制。
元数据放在一片共享区(主NN和备NN共享)称为Journal Node 集群
所有DN节点都要实时向主NN或备NN通信,告知NN自己有哪么些block等信息。
至于DN具体要向NN(主)还是NN(备),它会向zookeeper请示,zookeer知道那个节点是主,并知道它的状态。
当主NN的状态由FailoverControllerActive进行心跳检测,通知zookeeper,并在它发生故障时,做切换,同样备NN也有相应的FailoverControllerStandby 。
通过命令可手动停止主NN启动备NN,甚至调换角色,用于HDFS升级等场合


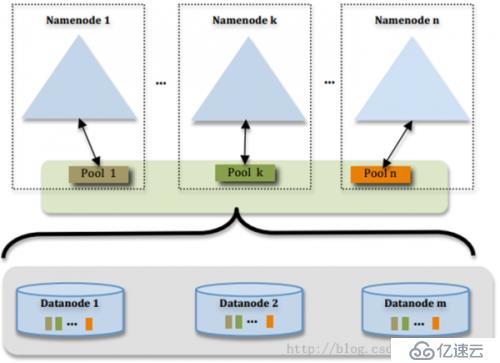
NN Fderation:将HDFS分成多个完全独立的NN的运行,彼此互不干扰,但是集群共享DN
多个NN共用一个集群里DN上的存储资源,每个NN都可以单独对外提供服务
每个NN都会定义一个存储池,有单独的id,每个DN都为所有存储池提供存储
DN会按照存储池id向其对应的NN汇报块信息,同时,DN会向所有NN汇报本地存储可用资源情况
如果需要在客户端方便的访问若干个NN上的资源,可以使用客户端挂载表,把不同的目录映射到不同的NN,但NN上必须存在相应的目录

Yarn主要功能:
负责资源管理,任务调度
支持多种第三方计算框架

免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。