жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
PythonеҮҪж•°еҠ йҖҹж•°жҚ®еҲҶжһҗеӨ„зҗҶйҖҹеәҰзҡ„зӨәдҫӢеҲҶжһҗпјҢеҫҲеӨҡж–°жүӢеҜ№жӯӨдёҚжҳҜеҫҲжё…жҘҡпјҢдёәдәҶеё®еҠ©еӨ§е®¶и§ЈеҶіиҝҷдёӘйҡҫйўҳпјҢдёӢйқўе°Ҹзј–е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§ЈпјҢжңүиҝҷж–№йқўйңҖжұӮзҡ„дәәеҸҜд»ҘжқҘеӯҰд№ дёӢпјҢеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
еүҚиЁҖпјҡ
Pandas жҳҜ Python дёӯжңҖе№ҝжіӣдҪҝз”Ёзҡ„ж•°жҚ®еҲҶжһҗе’Ңж“ҚдҪңеә“гҖӮе®ғжҸҗдҫӣдәҶи®ёеӨҡеҠҹиғҪе’Ңж–№жі•пјҢеҸҜд»ҘеҠ еҝ« гҖҢж•°жҚ®еҲҶжһҗгҖҚ е’Ң гҖҢйў„еӨ„зҗҶгҖҚ жӯҘйӘӨгҖӮ
дёәдәҶжӣҙеҘҪзҡ„еӯҰд№ PythonпјҢжҲ‘е°Ҷд»Ҙе®ўжҲ·жөҒеӨұж•°жҚ®йӣҶдёәдҫӢпјҢеҲҶдә«еңЁж•°жҚ®еҲҶжһҗиҝҮзЁӢдёӯжңҖеёёдҪҝз”Ёзҡ„еҮҪж•°е’Ңж–№жі•гҖӮ
ж•°жҚ®еҰӮдёӢжүҖзӨәпјҡ
import numpy as np
import pandas as pd
df = pd.read_csv("Churn_Modelling.csv")
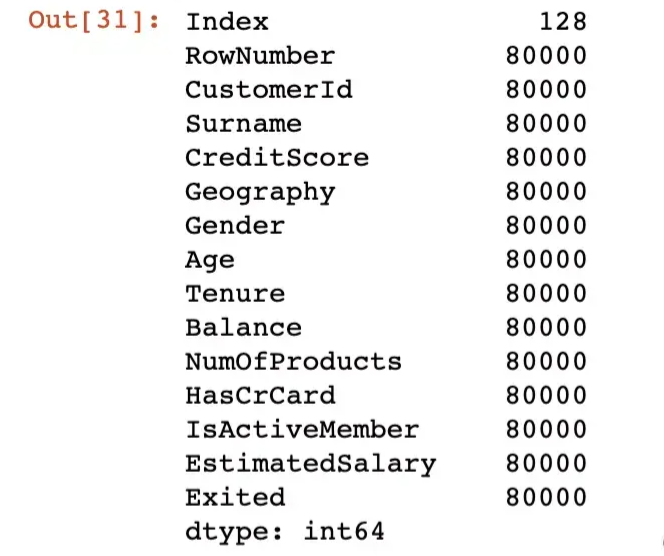
print(df.shape)
df.columnsз»“жһңиҫ“еҮәпјҡ
(10000, 14)
Index(['RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography','Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard','IsActiveMember', 'EstimatedSalary', 'Exited'],dtype='object')
df.drop(['RowNumber', 'CustomerId', 'Surname', 'CreditScore'], axis=1, inplace=True) print(df[:2]) print(df.shape)
з»“жһңиҫ“еҮәпјҡ
Geography Gender Age Tenure Balance NumOfProducts HasCrCard
0 France Female 42 2 0.0 1 1IsActiveMember EstimatedSalary Exited
0 1 101348.88 1
(10000, 10)
иҜҙжҳҺпјҡгҖҢaxisгҖҚ еҸӮж•°и®ҫзҪ®дёә 1 д»Ҙж”ҫзҪ®еҲ—пјҢ0 и®ҫзҪ®дёәиЎҢгҖӮгҖҢinplace=TrueгҖҚ еҸӮж•°и®ҫзҪ®дёә True д»Ҙдҝқеӯҳжӣҙж”№гҖӮжҲ‘们еҮҸдәҶ 4 еҲ—пјҢеӣ жӯӨеҲ—ж•°д»Һ 14 дёӘеҮҸе°‘еҲ° 10 еҲ—гҖӮ
жҲ‘们д»Һ csv ж–Ү件дёӯиҜ»еҸ–йғЁеҲҶеҲ—ж•°жҚ®гҖӮеҸҜд»ҘдҪҝз”Ё usecols еҸӮж•°гҖӮ
df_spec = pd.read_csv("Churn_Modelling.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])
df_spec.head()еҸҜд»ҘдҪҝз”Ё nrows еҸӮж•°пјҢеҲӣе»әдәҶдёҖдёӘеҢ…еҗ« csv ж–Ү件еүҚ 5000 иЎҢзҡ„ж•°жҚ®её§гҖӮиҝҳеҸҜд»ҘдҪҝз”Ё skiprows еҸӮж•°д»Һж–Ү件жң«е°ҫйҖүжӢ©иЎҢгҖӮSkiprows=5000 иЎЁзӨәжҲ‘们е°ҶеңЁиҜ»еҸ– csv ж–Ү件时跳иҝҮеүҚ 5000 иЎҢгҖӮ
df_partial = pd.read_csv("Churn_Modelling.csv", nrows=5000)
print(df_partial.shape)еҲӣе»әж•°жҚ®жЎҶеҗҺпјҢжҲ‘们еҸҜиғҪйңҖиҰҒдёҖдёӘе°Ҹж ·жң¬жқҘжөӢиҜ•ж•°жҚ®гҖӮжҲ‘们еҸҜд»ҘдҪҝз”Ё n жҲ– frac еҸӮж•°жқҘзЎ®е®ҡж ·жң¬еӨ§е°ҸгҖӮ
df= pd.read_csv("Churn_Modelling.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])
df_sample = df.sample(n=1000)
df_sample2 = df.sample(frac=0.1)isna еҮҪж•°зЎ®е®ҡж•°жҚ®её§дёӯзјәеӨұзҡ„еҖјгҖӮйҖҡиҝҮе°Ҷ isna дёҺ sum еҮҪж•°дёҖиө·дҪҝз”ЁпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°жҜҸеҲ—дёӯзјәеӨұеҖјзҡ„ж•°йҮҸгҖӮ
df.isna().sum()
дҪҝз”Ё loc е’Ң iloc ж·»еҠ зјәеӨұеҖјпјҢдёӨиҖ…еҢәеҲ«еҰӮдёӢпјҡ
locпјҡйҖүжӢ©еёҰж Үзӯҫ
ilocпјҡйҖүжӢ©зҙўеј•
жҲ‘们йҰ–е…ҲеҲӣе»ә 20 дёӘйҡҸжңәзҙўеј•иҝӣиЎҢйҖүжӢ©
missing_index = np.random.randint(10000, size=20)
жҲ‘们е°ҶдҪҝз”Ё loc е°ҶжҹҗдәӣеҖјжӣҙж”№дёә np.nanпјҲзјәеӨұеҖјпјүгҖӮ
df.loc[missing_index, ['Balance','Geography']] = np.nan
"Balance"е’Ң"Geography"еҲ—дёӯзјәе°‘ 20 дёӘеҖјгҖӮи®©жҲ‘们用 iloc еҒҡеҸҰдёҖдёӘзӨәдҫӢгҖӮ
df.iloc[missing_index, -1] = np.nan
fillna еҮҪж•°з”ЁдәҺеЎ«е……зјәеӨұзҡ„еҖјгҖӮе®ғжҸҗдҫӣдәҶи®ёеӨҡйҖүйЎ№гҖӮжҲ‘们еҸҜд»ҘдҪҝз”Ёзү№е®ҡеҖјгҖҒиҒҡеҗҲеҮҪж•°пјҲдҫӢеҰӮеқҮеҖјпјүжҲ–дёҠдёҖдёӘжҲ–дёӢдёҖдёӘеҖјгҖӮ
avg = df['Balance'].mean() df['Balance'].fillna(value=avg, inplace=True)
fillna еҮҪж•°зҡ„ж–№жі•еҸӮж•°еҸҜз”ЁдәҺж №жҚ®еҲ—дёӯзҡ„дёҠдёҖдёӘжҲ–дёӢдёҖдёӘеҖјпјҲдҫӢеҰӮж–№жі•="ffill"пјүеЎ«е……зјәеӨұеҖјгҖӮе®ғеҸҜд»ҘеҜ№йЎәеәҸж•°жҚ®пјҲдҫӢеҰӮж—¶й—ҙеәҸеҲ—пјүйқһеёёжңүз”ЁгҖӮ
еӨ„зҗҶзјәеӨұеҖјзҡ„еҸҰдёҖдёӘж–№жі•жҳҜеҲ йҷӨе®ғ们гҖӮд»ҘдёӢд»Јз Ғе°ҶеҲ йҷӨе…·жңүд»»дҪ•зјәеӨұеҖјзҡ„иЎҢгҖӮ
df.dropna(axis=0, how='any', inplace=True)
еңЁжҹҗдәӣжғ…еҶөдёӢпјҢжҲ‘们йңҖиҰҒйҖӮеҗҲжҹҗдәӣжқЎд»¶зҡ„и§ӮжөӢеҖјпјҲеҚіиЎҢпјү
france_churn = df[(df.Geography == 'France') & (df.Exited == 1)] france_churn.Geography.value_counts()
жҹҘиҜўеҮҪж•°жҸҗдҫӣдәҶдёҖз§ҚжӣҙзҒөжҙ»зҡ„дј йҖ’жқЎд»¶зҡ„ж–№жі•гҖӮжҲ‘们еҸҜд»Ҙз”Ёеӯ—з¬ҰдёІжқҘжҸҸиҝ°е®ғ们гҖӮ
df2 = df.query('80000 < Balance < 100000')
# и®©жҲ‘们йҖҡиҝҮз»ҳеҲ¶е№іиЎЎеҲ—зҡ„зӣҙж–№еӣҫжқҘзЎ®и®Өз»“жһңгҖӮ
df2['Balance'].plot(kind='hist', figsize=(8,5))жқЎд»¶еҸҜиғҪжңүеӨҡдёӘеҖјгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢжңҖеҘҪдҪҝз”Ё isin ж–№жі•пјҢиҖҢдёҚжҳҜеҚ•зӢ¬зј–еҶҷеҖјгҖӮ
df[df['Tenure'].isin([4,6,9,10])][:3]

Pandas Groupby еҮҪж•°жҳҜдёҖдёӘеӨҡеҠҹиғҪдё”жҳ“дәҺдҪҝз”Ёзҡ„еҠҹиғҪпјҢеҸҜеё®еҠ©иҺ·еҸ–ж•°жҚ®жҰӮиҝ°гҖӮе®ғдҪҝжөҸи§Ҳж•°жҚ®йӣҶе’ҢжҸӯзӨәеҸҳйҮҸд№Ӣй—ҙзҡ„еҹәжң¬е…ізі»жӣҙеҠ е®№жҳ“гҖӮ
жҲ‘们е°ҶеҒҡеҮ дёӘз»„жҜ”еҮҪж•°зҡ„зӨәдҫӢгҖӮи®©жҲ‘们д»Һз®ҖеҚ•зҡ„ејҖе§ӢгҖӮд»ҘдёӢд»Јз Ғе°ҶеҹәдәҺ GeographyгҖҒGender з»„еҗҲеҜ№иЎҢиҝӣиЎҢеҲҶз»„пјҢ然еҗҺз»ҷеҮәжҜҸдёӘз»„зҡ„е№іеқҮжөҒеӨұзҺҮгҖӮ
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).mean()
agg еҮҪж•°е…Ғи®ёеңЁз»„дёҠеә”з”ЁеӨҡдёӘиҒҡеҗҲеҮҪж•°пјҢеҮҪж•°зҡ„еҲ—иЎЁдҪңдёәеҸӮж•°дј йҖ’гҖӮ
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).agg(['mean','count'])
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg({'Exited':'sum', 'Balance':'mean'})
df_summary.rename(columns={'Exited':'# of churned customers', 'Balance':'Average Balance of Customers'},inplace=True)жӯӨеӨ–пјҢгҖҢNamedAgg еҮҪж•°гҖҚе…Ғи®ёйҮҚе‘ҪеҗҚиҒҡеҗҲдёӯзҡ„еҲ—
import pandas as pd
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg(Number_of_churned_customers = pd.NamedAgg('Exited', 'sum'),Average_balance_of_customers = pd.NamedAgg('Balance', 'mean'))
print(df_summary)
жӮЁжҳҜеҗҰе·Із»ҸжіЁж„ҸеҲ°дёҠеӣҫзҡ„ж•°жҚ®ж јејҸдәҶгҖӮжҲ‘们еҸҜд»ҘйҖҡиҝҮйҮҚзҪ®зҙўеј•жқҘжӣҙж”№е®ғгҖӮ
print(df_summary.reset_index())
еӣҫзүҮ
еңЁжҹҗдәӣжғ…еҶөдёӢпјҢжҲ‘们йңҖиҰҒйҮҚзҪ®зҙўеј•е№¶еҗҢж—¶еҲ йҷӨеҺҹе§Ӣзҙўеј•гҖӮ
df[['Geography','Exited','Balance']].sample(n=6).reset_index(drop=True)
жҲ‘们еҸҜд»Ҙе°Ҷж•°жҚ®её§дёӯзҡ„д»»дҪ•еҲ—и®ҫзҪ®дёәзҙўеј•гҖӮ
df_new.set_index('Geography')group = np.random.randint(10, size=6) df_new['Group'] = group
е®ғз”ЁдәҺж №жҚ®жқЎд»¶жӣҝжҚўиЎҢжҲ–еҲ—дёӯзҡ„еҖјгҖӮй»ҳи®ӨжӣҝжҚўеҖјдёә NaNпјҢдҪҶжҲ‘们д№ҹеҸҜд»ҘжҢҮе®ҡиҰҒдҪңдёәжӣҝжҚўеҖјгҖӮ
df_new['Balance'] = df_new['Balance'].where(df_new['Group'] >= 6, 0)
зӯүзә§еҮҪж•°дёәеҖјеҲҶй…ҚдёҖдёӘжҺ’еҗҚгҖӮи®©жҲ‘们еҲӣе»әдёҖдёӘеҲ—пјҢж №жҚ®е®ўжҲ·зҡ„дҪҷйўқеҜ№е®ўжҲ·иҝӣиЎҢжҺ’еҗҚгҖӮ
df_new['rank'] = df_new['Balance'].rank(method='first', ascending=False).astype('int')е®ғдҪҝз”ЁеҲҶзұ»еҸҳйҮҸж—¶жҙҫдёҠз”ЁеңәгҖӮжҲ‘们еҸҜиғҪйңҖиҰҒжЈҖжҹҘе”ҜдёҖзұ»еҲ«зҡ„ж•°йҮҸгҖӮжҲ‘们еҸҜд»ҘжЈҖжҹҘеҖји®Ўж•°еҮҪж•°иҝ”еӣһзҡ„еәҸеҲ—зҡ„еӨ§е°ҸжҲ–дҪҝз”Ё nunique еҮҪж•°гҖӮ
df.Geography.nunique
дҪҝз”ЁеҮҪж•° memory_usage,иҝҷдәӣеҖјжҳҫзӨәд»Ҙеӯ—иҠӮдёәеҚ•дҪҚзҡ„еҶ…еӯҳ.
df.memory_usage()
й»ҳи®Өжғ…еҶөдёӢпјҢеҲҶзұ»ж•°жҚ®дёҺеҜ№иұЎж•°жҚ®зұ»еһӢдёҖиө·еӯҳеӮЁгҖӮдҪҶжҳҜпјҢе®ғеҸҜиғҪдјҡеҜјиҮҙдёҚеҝ…иҰҒзҡ„еҶ…еӯҳдҪҝз”ЁпјҢе°Өе…¶жҳҜеҪ“еҲҶзұ»еҸҳйҮҸе…·жңүиҫғдҪҺзҡ„еҹәж•°гҖӮ
дҪҺеҹәж•°ж„Ҹе‘ізқҖеҲ—дёҺиЎҢж•°зӣёжҜ”еҮ д№ҺжІЎжңүе”ҜдёҖеҖјгҖӮдҫӢеҰӮпјҢең°зҗҶеҲ—е…·жңү 3 дёӘе”ҜдёҖеҖје’Ң 10000 иЎҢгҖӮ
жҲ‘们еҸҜд»ҘйҖҡиҝҮе°Ҷе…¶ж•°жҚ®зұ»еһӢжӣҙж”№дёә"зұ»еҲ«"жқҘиҠӮзңҒеҶ…еӯҳгҖӮ
df['Geography'] = df['Geography'].astype('category')жӣҝжҚўеҮҪж•°еҸҜз”ЁдәҺжӣҝжҚўж•°жҚ®её§дёӯзҡ„еҖјгҖӮ
df['Geography'].replace({0:'B1',1:'B2'})pandas дёҚжҳҜдёҖдёӘж•°жҚ®еҸҜи§ҶеҢ–еә“пјҢдҪҶе®ғдҪҝеҫ—еҲӣе»әеҹәжң¬з»ҳеӣҫеҸҳеҫ—йқһеёёз®ҖеҚ•гҖӮ
жҲ‘еҸ‘зҺ°дҪҝз”Ё Pandas еҲӣе»әеҹәжң¬з»ҳеӣҫжӣҙе®№жҳ“пјҢиҖҢдёҚжҳҜдҪҝз”Ёе…¶д»–ж•°жҚ®еҸҜи§ҶеҢ–еә“гҖӮ
и®©жҲ‘们еҲӣе»әе№іиЎЎеҲ—зҡ„зӣҙж–№еӣҫгҖӮ
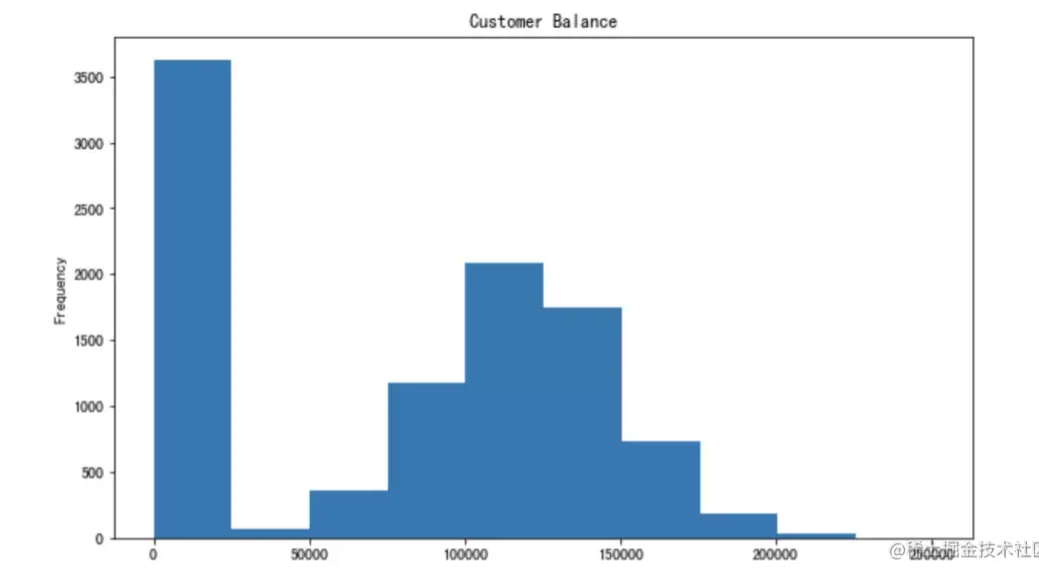
pandas еҸҜиғҪдјҡдёәжө®зӮ№ж•°жҳҫзӨәиҝҮеӨҡзҡ„е°Ҹж•°зӮ№гҖӮжҲ‘们еҸҜд»ҘиҪ»жқҫең°и°ғж•ҙе®ғгҖӮ
df['Balance'].plot(kind='hist', figsize=(10,6), title='Customer Balance')
жҲ‘们еҸҜд»Ҙжӣҙж”№еҗ„з§ҚеҸӮж•°зҡ„й»ҳи®ӨжҳҫзӨәйҖүйЎ№пјҢиҖҢдёҚжҳҜжҜҸж¬ЎжүӢеҠЁи°ғж•ҙжҳҫзӨәйҖүйЎ№гҖӮ
get_optionпјҡиҝ”еӣһеҪ“еүҚйҖүйЎ№
set_optionпјҡжӣҙж”№йҖүйЎ№ и®©жҲ‘们е°Ҷе°Ҹж•°зӮ№зҡ„жҳҫзӨәйҖүйЎ№жӣҙж”№дёә 2гҖӮ
pd.set_option("display.precision", 2)еҸҜиғҪиҰҒжӣҙж”№зҡ„дёҖдәӣе…¶д»–йҖүйЎ№еҢ…жӢ¬пјҡ
max_colwidthпјҡеҲ—дёӯжҳҫзӨәзҡ„жңҖеӨ§еӯ—з¬Ұж•°
max_columnsпјҡиҰҒжҳҫзӨәзҡ„жңҖеӨ§еҲ—ж•°
max_rowsпјҡиҰҒжҳҫзӨәзҡ„жңҖеӨ§иЎҢж•°
pct_changeз”ЁдәҺи®Ўз®—еәҸеҲ—дёӯеҖјзҡ„еҸҳеҢ–зҷҫеҲҶжҜ”гҖӮеңЁи®Ўз®—ж—¶й—ҙеәҸеҲ—жҲ–е…ғзҙ йЎәеәҸж•°з»„дёӯжӣҙж”№зҡ„зҷҫеҲҶжҜ”ж—¶пјҢе®ғеҫҲжңүз”ЁгҖӮ
ser= pd.Series([2,4,5,6,72,4,6,72]) ser.pct_change()
жҲ‘们еҸҜиғҪйңҖиҰҒж №жҚ®ж–Үжң¬ж•°жҚ®пјҲеҰӮе®ўжҲ·еҗҚз§°пјүзӯӣйҖүи§ӮжөӢеҖјпјҲиЎҢпјүгҖӮжҲ‘е·Із»ҸеңЁж•°жҚ®её§дёӯж·»еҠ дәҶdf_newеҗҚз§°гҖӮ
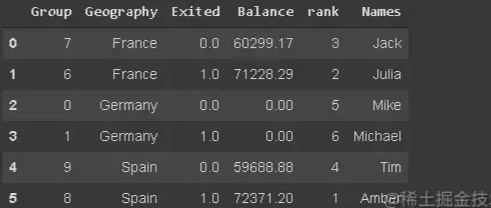
df_new[df_new.Names.str.startswith('Mi')]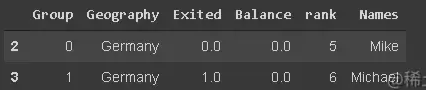
жҲ‘们еҸҜд»ҘйҖҡиҝҮдҪҝз”Ёиҝ”еӣһ Style еҜ№иұЎзҡ„ Style еұһжҖ§жқҘе®һзҺ°жӯӨзӣ®зҡ„пјҢе®ғжҸҗдҫӣдәҶи®ёеӨҡз”ЁдәҺж јејҸеҢ–е’ҢжҳҫзӨәж•°жҚ®жЎҶзҡ„йҖүйЎ№гҖӮдҫӢеҰӮпјҢжҲ‘们еҸҜд»ҘзӘҒеҮәжҳҫзӨәжңҖе°ҸеҖјжҲ–жңҖеӨ§еҖјгҖӮ
е®ғиҝҳе…Ғи®ёеә”з”ЁиҮӘе®ҡд№үж ·ејҸеҮҪж•°гҖӮ
df_new.style.highlight_max(axis=0, color='darkgreen')
зңӢе®ҢдёҠиҝ°еҶ…е®№жҳҜеҗҰеҜ№жӮЁжңүеё®еҠ©е‘ўпјҹеҰӮжһңиҝҳжғіеҜ№зӣёе…ізҹҘиҜҶжңүиҝӣдёҖжӯҘзҡ„дәҶи§ЈжҲ–йҳ…иҜ»жӣҙеӨҡзӣёе…іж–Үз« пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўжӮЁеҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ