您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下怎么用Python实现爬取百度热搜信息,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
何为爬虫,其实就是利用计算机模拟人对网页的操作
例如 模拟人类浏览购物网站
使用爬虫前一定要看目标网站可刑不可刑 :-)
可以在目标网站添加/robots.txt 查看网页具体信息
例如对天猫 可输入 https://brita.tmall.com/robots.txt 进行查看
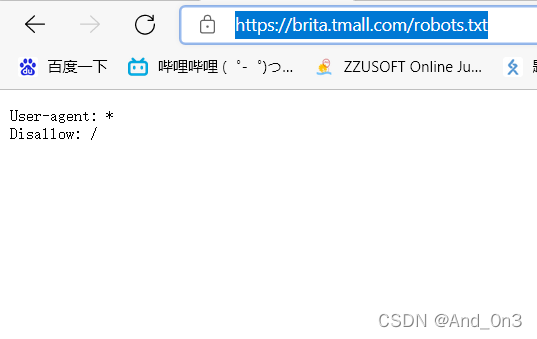
User-agent 代表发送请求的对象
星号*代表任何搜索引擎
Disallow 代表不允许访问的部分
/代表从根目录开始
Allow代表允许访问的部分
在本例中 我爬取的百度热搜前30的新闻(本人原本打算爬取英雄联盟主页 数据中心 大乱斗胜率前五十的英雄信息 奈何不会实现延时爬取网页的操作 无奈只能爬百度热搜) 并且其大致信息放到Excel表格以及Flask网页中实现数据可视化 感兴趣的同学也可以对其它内容进行爬取
由于本人水平有限 本文章中的爬虫都是比较基础的东西
Python库的安装方法:
打开cmd命令提示符输入pip install XXX(这个是你要装的库名称)
关于这些库的具体使用 可以接下来看我的操作
只需要简单掌握几个常用的函数即可
bs4
即BeautifulSoup
用来解析HTML网页,提取指定数据的。
其中详细的用法待会看我的演示。
re
正则表达式 用来匹配字符串中响应的字串。
关于正则表达式 可以去看菜鸟教程 里边讲的很详细
urllib
是一个Python自带的HTTP请求库,可以操作一系列URL。
xlwt/xlrt
用于写入(write) / 读取(read),Excel表中的数据。
flask
这个库是用来只做一个简单的Web框架即网站,用于数据的可视化。
其实本人对于数据可视化的掌握也很浅薄,只是简单的将数据导入Web网页中。
jinja2
这个库的作用是为了实现在HTML网页中的字符中插入自变量的功能。
后端:
name="HQ"
前端:
<p>{{name}}长得真帅!</p>
显示:
HQ长得真帅!markupsafe
与Jinja共用 在渲染页面时用于避免不可信的输入,防止注入攻击(虽然没人会攻击你....)
数据爬取 和 数据可视化 两个py文件是分开的
数据爬取需要导入re bs4 urllib xlwt 四个库文件
使用一下的方法调用函数可以使函数调用关系更加清晰
if __name__=="__main__": #当程序执行时 调用一下函数 main()
def askurl(url):
head={
"User-Agent":'''Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'''
}
#用户代理 告诉服务器我只是一个普普通通的浏览器
requset=urllib.request.Request(url)
#发送请求
response=urllib.request.urlopen(requset)
#响应的为一个request对象
#通过read()转化为 bytes类型字符串
#再通过decode()转化为 str类型的字符串
#接受响应
html=response.read().decode('utf-8')
将抓取到的网页存入文档中 方便观察
path=r"C:\Users\XXX\Desktop\Python\text.txt"
#这里在字符串前加入r 防止字符串中的\发生转义
f=open(r"path",'w',encoding='utf-8')
f.write(html)
f.close()
#这样在txt文件中就可以查看网页的源码
return htmlheaders的值可以在网页中按F12
然后点击网络变化 对于任意一个请求标头 下拉到最下方即为 user-agent 代理信息
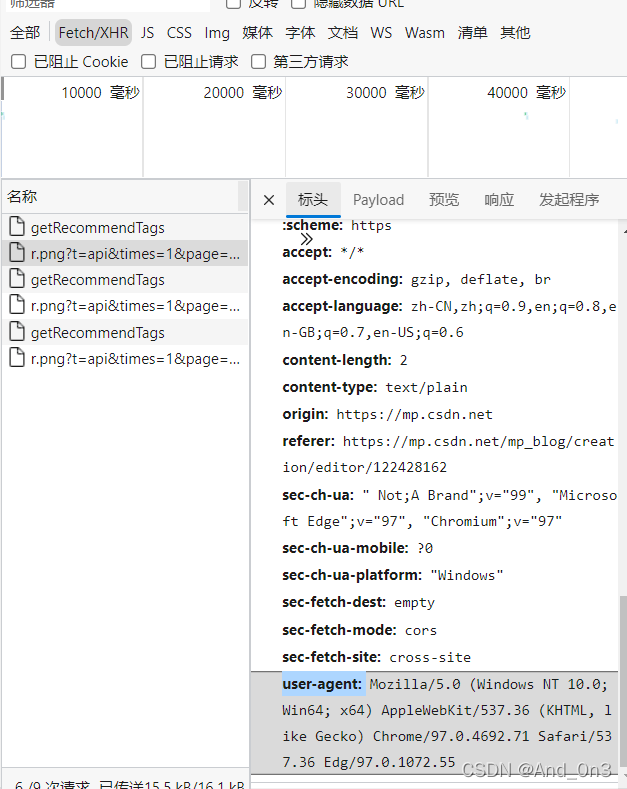
值得注意的是 请求中如果不设置headers 则服务器会返回一个418的状态码
代表服务器识别出来你是一个爬虫 并且表示:“ I'm a teapot ”
表明服务器拒绝冲煮咖啡,因为它永远是一个茶壶(这是一个梗)
将抓取的txt文件后缀改为html后打开即为一个本地的网页
如果在vscode中因为行过长而产生报错 可以参考以下博客
打开后的网页如图所示
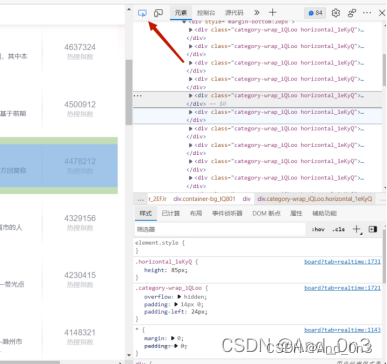
使用这个功能查看需要爬取信息的位置
在本项目中 我们抓取目标信息的标题 内容 热度 以及链接
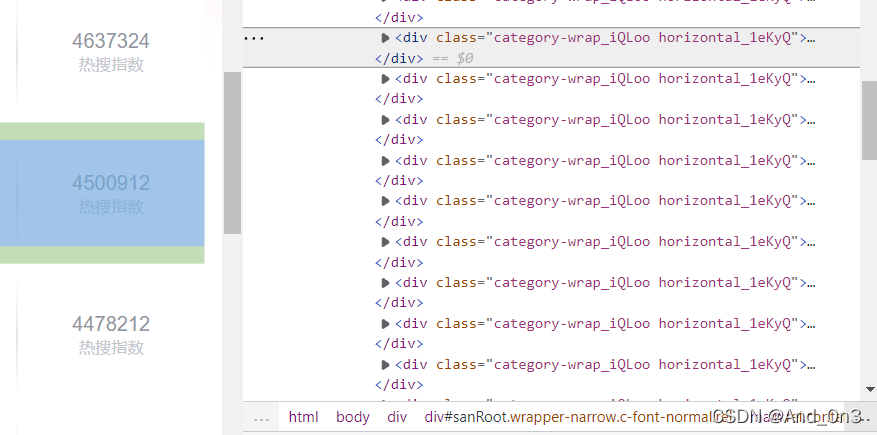
我们可以发现 我们需要的信息全部在class为以下类型的表中

于是我们用Beautifulsoup对网页进行解析
def getData(html):
datalist=[]
soup=BeautifulSoup(html,"html.parser") #定义一个解析对象
#soup.find_all(a,b) 其中a为标签的类型 class_ 对div的class进行匹配
#返回的是所有class为category-wrap_iQLoo horizontal_1eKyQ的列表
for item in soup.find_all('div',class_="category-wrap_iQLoo horizontal_1eKyQ"):
item=str(item)
#将列表中每一个子标签转换为字符串用于re匹配接下来对每一个item进行re匹配
首先使用re.compile()创建匹配规则 然后用findall进行匹配
匹配规则的创建方式为在HTML文件中查看目标信息前后的特殊字符
而(.*?)即为要匹配的字符串 其中*后加?代表非贪婪匹配
例如

标题前后信息即为ellipsis">和</div> <div cla
其它同理
#匹配规则 #链接 findlink=re.compile(r' href="(.*?)" rel="external nofollow" target="_blank') #标题 findtitle=re.compile(r'ellipsis"> (.*?) </div> <div cla') #内容 findcontent1=re.compile(r'ellipsis_DupbZ"> (.*?) <a class=') findcontent2=re.compile(r'small_Uvkd3"> (.*?) <a class=') #热度 findnumber=re.compile(r'ex_1Bl1a"> (.*?) </div>')
而内容部分 我在后续运行的时候发现报错 原因是
部分内容前缀为'ellipsis_DupbZ"> 部分内容前缀为small_Uvkd3">
因此我编写了两种匹配方式
具体代码如下
def getData(html):
datalist=[]
soup=BeautifulSoup(html,"html.parser") #定义一个解析对象
#soup.find_all(a,b) 其中a为标签的类型 class_ 对div的class进行匹配
#返回的是所有class为category-wrap_iQLoo horizontal_1eKyQ的列表
for item in soup.find_all('div',class_="category-wrap_iQLoo horizontal_1eKyQ"):
item=str(item)
#将列表中每一个子标签转换为字符串用于re匹配
data=[]
#标题
title=re.findall(findtitle,item)[0]
#简介
#判断是否对第一种匹配 如果不是的话返回为空列表 此时应采用第二种匹配
if (len(re.findall(findcontent1,item))!=0):
content=re.findall(findcontent1,item)[0]
else:
content=re.findall(findcontent2,item)[0]
#热度
number=re.findall(findnumber,item)[0]
#链接
link=re.findall(findlink,item)[0]
#将数据存入数组
data.append(title)
data.append(number)
data.append(content)
data.append(link)
datalist.append(data)
print(datalist)
return datalistdef Savedata(datalist):
#存入数据的目标路径
path=r'C:\Users\XXX\Desktop\Python\爬虫\data.xls'
workbook=xlwt.Workbook(encoding='utf-8')
#创建工作表对象
worksheet=workbook.add_sheet('sheet1')
#创建表单
col=("标题","热度","内容","链接")
#定义表含有的属性
for i in range(4):
worksheet.write(0,i,col[i])
#write(i,j,value) 向 表单的 [i][j] 位置写入value
for i in range(30):
for j in range(4):
worksheet.write(i+1,j,datalist[i][j])
#将excel表保存
workbook.save(path)看完了这篇文章,相信你对“怎么用Python实现爬取百度热搜信息”有了一定的了解,如果想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。