您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关Python如何实现PDF扫描件生成DOCX或EXCEL功能,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
应项目需求需要获取PDF扫描文件的内容,但寻遍整个网络能达到这种功能的产品,都要会员充值。苦于囊中羞涩也只好编写功能代码来实现了。
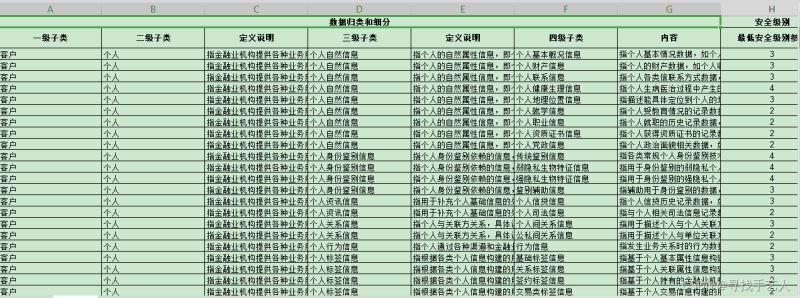
如PDF中表格图片图-1效果生成图-2
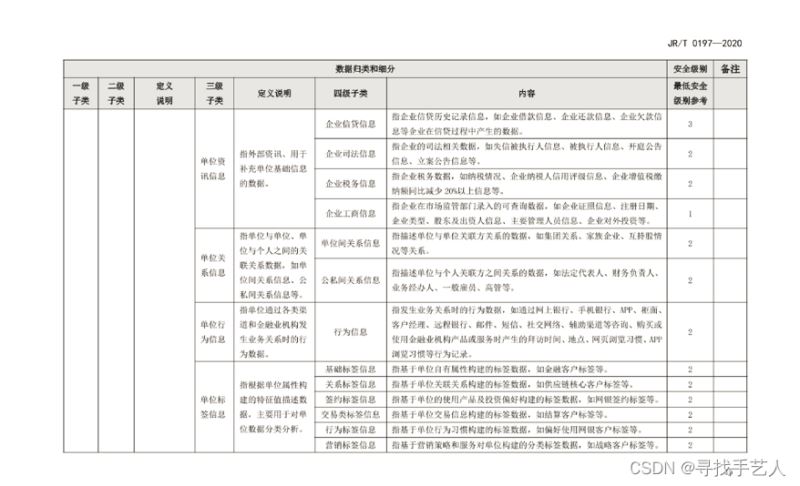
图-1

图-2
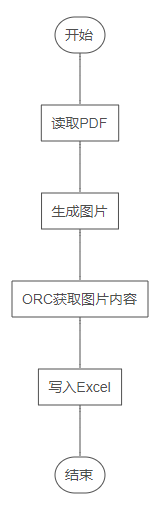
整个步骤为:读取PDF文件->生成图片->ORC获取图片内容->写入Excel
import fitz # pdf转为图片
from aip import AipOcr # 图片文字识别
import time # 程序运行时间间隔以避免出错
import docx # 将识别结果保存为docx文件
from docx.oxml.ns import qn # 设置docx文件的字体
""" 你的 APPID AK SK """
APP_ID = 'xxxxxx'
API_KEY = 'xxxxxxxx'
SECRET_KEY = 'xxxxxxxxxxxxxxxxxxxxxxx'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
'''
将PDF转化为图片
pdfPath pdf文件的路径
imgPath 图像要保存的路径
zoom_x x方向的缩放系数
zoom_y y方向的缩放系数
rotation_angle 旋转角度
zoom_x和zoom_y一般取相同值,值越大,图像分辨率越高
返回目标pdf的名称和页数,便于下一步操作
'''
def pdf_image(pdfPath, imgPath, zoom_x=10, zoom_y=10, rotation_angle=0):
# 获取pdf文件名称
name = pdfPath.split("\\")[-1].split('.pdf')[0]
# 打开PDF文件
pdf = fitz.open(pdfPath)
# 获取pdf页数
num = pdf.pageCount
# 逐页读取PDF
for pg in range(0, num):
page = pdf[pg]
# 设置缩放和旋转系数
trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotation_angle)
pm = page.getPixmap(matrix=trans, alpha=False)
# 开始写图像
pm.writePNG(imgPath + name + "_" + str(pg) + ".png")
pdf.close()
return name, num
'''
将图片读取为docx文件
imgPath 图像所在路径
生成的docx也保存在图像所在路径中
name为pdf名称(不含后缀)
num为pdf页数
name和num均可由上一个函数返回
'''
def ReadDetail_docx(imgPath, name, num):
# 建立一个空doc文档
doc = docx.Document()
# 设置全局字体
doc.styles["Normal"].font.name=u"宋体"
doc.styles["Normal"]._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
# 读取图片
for n in range(0,num):
i = open(imgPath+name+"_"+str(n)+".png",'rb')
time.sleep(0.1)
img = i.read()
message = client.basicAccurate(img)
content = message.get('words_result')
# 将内容写入doc文档
for i in range(len(content)):
doc.add_paragraph(content[i].get('words'))
# 保存doc文档
doc.save(imgPath + name + '.docx')
def pdf_to_docx(pdfPath, imgPath, zoom_x=10, zoom_y=10, rotation_angle=0):
print("正在将pdf文件转换为图片...")
# 调用函数一将pdf转换为图片,并获得文件名和页数
name_, num_ = pdf_image(pdfPath, imgPath, zoom_x, zoom_y, rotation_angle)
print("转换成功!")
#print("正在读取图片内容...")
# 调用函数二逐页读取图片并逐行保存在docx文件中
# ReadDetail_docx(imgPath, name_, num_)
#print("名为 {}.pdf 的pdf文件共有{}页,已成功转换为docx文件!".format(name_, num_))
# pdf储存路径
pdf_path = "JRT 0197-2020金融数据安全 数据安全分级指南.pdf"
# 图片和生成的docx文件的储存路径
img_path = r"G:\imges\\"
# 调用函数
pdf_to_docx(pdf_path, img_path)import pandas as pd
import numpy as np
import re
# 图片识别
from aip import AipOcr
# 时间模块
import time
# 网页获取
import requests
# 操作系统接口模块
import os
image_path = ''
# 获取文件夹中所有图片
def get_image():
images = [] # 存储文件夹内所有文件的路径(包括子目录内的文件)
for root, dirs, files in os.walk(image_path):
path = [os.path.join(root, name) for name in files]
images.extend(path)
return images
def Image_Excel(APP_ID, API_KEY, SECRET_KEY):
# 调用百度AI接口
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 循环遍历文件家中图片
images = get_image()
for image in images:
# 以二进制方式打开图片
img_open = open(image, 'rb')
# 读取图片
img_read = img_open.read()
# 调用表格识别模块识别图片
table = client.tableRecognitionAsync(img_read)
# 获取请求ID
request_id = table['result'][0]['request_id']
# 获取表格处理结果
result = client.getTableRecognitionResult(request_id)
# 处理状态是“已完成”,获取下载地址
while result['result']['ret_msg'] != '已完成':
time.sleep(2) # 暂停2秒再刷新
result = client.getTableRecognitionResult(request_id)
download_url = result['result']['result_data']
print(download_url)
# 获取表格数据
excel_data = requests.get(download_url)
# 根据图片名字命名表格名称
xlsx_name = image.split(".")[0] + ".xlsx"
# 新建excel文件
xlsx = open(xlsx_name, 'wb')
# 将数据写入excel文件并保存
xlsx.write(excel_data.content)
if __name__ == '__main__':
image_path = r"G:\imgs\\"
APP_ID = 'xxxxxxxx'
API_KEY = 'xxxxxxx'
SECRET_KEY = 'xxxxxxxxxxxxxxxxxxxxxx'
Image_Excel(APP_ID, API_KEY, SECRET_KEY)我这里是获取JRT 0197-2020金融数据安全 数据安全分级指南.pdf扫描文件,将内部表格数据写入到excel文件。

关于“Python如何实现PDF扫描件生成DOCX或EXCEL功能”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。