жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңPythonж•°жҚ®з»“жһ„зҡ„ж Ҳе®һдҫӢеҲҶжһҗвҖқзҡ„зӣёе…ізҹҘиҜҶпјҢе°Ҹзј–йҖҡиҝҮе®һйҷ…жЎҲдҫӢеҗ‘еӨ§е®¶еұ•зӨәж“ҚдҪңиҝҮзЁӢпјҢж“ҚдҪңж–№жі•з®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәпјҢеёҢжңӣиҝҷзҜҮвҖңPythonж•°жҚ®з»“жһ„зҡ„ж Ҳе®һдҫӢеҲҶжһҗвҖқж–Үз« иғҪеё®еҠ©еӨ§е®¶и§ЈеҶій—®йўҳгҖӮ
ж Ҳ (Stack) жҳҜйҷҗе®ҡд»…еңЁеәҸеҲ—дёҖз«Ҝжү§иЎҢжҸ’е…Ҙе’ҢеҲ йҷӨж“ҚдҪңзҡ„зәҝжҖ§иЎЁпјҢеҜ№дәҺж ҲиҖҢиЁҖпјҢеҸҜиҝӣиЎҢж“ҚдҪңзҡ„дёҖз«Ҝз§°дёәж ҲйЎ¶ (top)пјҢиҖҢеҸҰдёҖз«Ҝз§°дёәж Ҳеә• (bottom)гҖӮеҰӮжһңж ҲдёӯдёҚеҗ«д»»дҪ•е…ғзҙ еҲҷз§°е…¶дёәз©әж ҲгҖӮ
ж ҲжҸҗдҫӣдәҶдёҖз§ҚеҹәдәҺеңЁйӣҶеҗҲдёӯзҡ„ж—¶й—ҙжқҘжҺ’еәҸзҡ„ж–№ејҸпјҢжңҖиҝ‘ж·»еҠ зҡ„е…ғзҙ йқ иҝ‘йЎ¶з«ҜпјҢж—§е…ғзҙ еҲҷйқ иҝ‘еә•з«ҜгҖӮжңҖж–°ж·»еҠ зҡ„е…ғзҙ иў«жңҖе…Ҳ移йҷӨпјҢиҝҷз§ҚжҺ’еәҸеҺҹеҲҷд№ҹз§°дёәеҗҺиҝӣе…ҲеҮә (last in first out, LIFO) жҲ–е…ҲиҝӣеҗҺеҮә (fast in last out, FILO)гҖӮ
ж ҲеңЁзҺ°е®һдёӯзҡ„дҫӢеӯҗйҡҸеӨ„еҸҜи§ҒпјҢеҰӮдёӢеӣҫжүҖзӨәпјҢзҗғжЎ¶дёӯзҡ„зҗғжһ„жҲҗдәҶдёҖдёӘж ҲпјҢжҜҸж¬ЎеҸӘиғҪд»ҺйЎ¶йғЁеҸ–еҮәдёҖдёӘпјҢж”ҫеӣһж—¶д№ҹеҸӘиғҪзҪ®дәҺйЎ¶йғЁгҖӮеҒҮи®ҫж ҲдёәS = ( a0 , a1 , … , en)дёәж ҲйЎ¶е…ғзҙ пјҢж Ҳдёӯе…ғзҙ жҢүзҡ„йЎәеәҸе…Ҙж Ҳ (push)пјҢиҖҢж ҲйЎ¶е…ғзҙ жҳҜ第дёҖдёӘйҖҖж Ҳ (pop) зҡ„е…ғзҙ гҖӮ
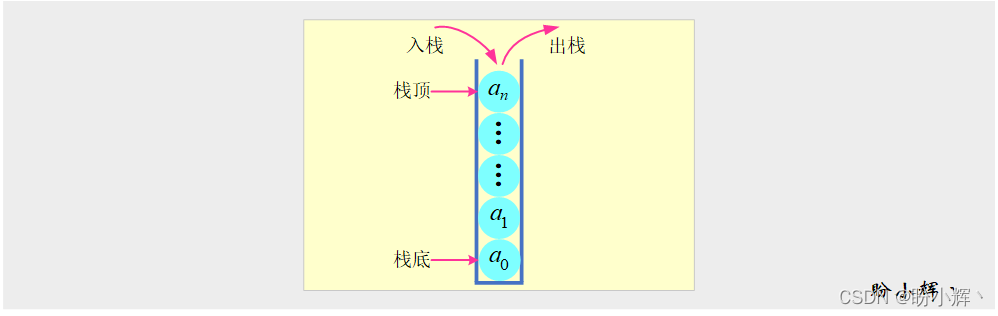
йҖҡиҝҮи§ӮеҜҹе…ғзҙ зҡ„ж·»еҠ е’Ң移йҷӨйЎәеәҸпјҢе°ұеҸҜд»Ҙеҝ«йҖҹзҗҶи§Јж ҲжүҖи•ҙеҗ«зҡ„жҖқжғігҖӮдёӢеӣҫеұ•зӨәдәҶж Ҳзҡ„е…Ҙж Ҳе’ҢеҮәж ҲиҝҮзЁӢпјҢж Ҳдёӯе…ғзҙ зҡ„жҸ’е…ҘйЎәеәҸе’Ң移йҷӨйЎәеәҸжҒ°еҘҪжҳҜзӣёеҸҚзҡ„гҖӮ

йҷӨдәҶдё»иҰҒзҡ„ж“ҚдҪң(е…Ҙж Ҳе’ҢеҮәж Ҳ)еӨ–пјҢж Ҳиҝҳе…·жңүеҲқе§ӢеҢ–гҖҒеҲӨз©әе’ҢеҸ–ж ҲйЎ¶е…ғзҙ зӯүиҫ…еҠ©ж“ҚдҪңгҖӮе…·дҪ“иҖҢиЁҖпјҢж Ҳзҡ„жҠҪиұЎж•°жҚ®зұ»еһӢе®ҡд№үеҰӮдёӢпјҡ

еҹәжң¬ж“ҚдҪңпјҡ
1. __itit__(): еҲқе§ӢеҢ–ж Ҳ
еҲӣе»әдёҖдёӘз©әж Ҳ
2. size(): жұӮеҸ–并иҝ”еӣһж ҲдёӯжүҖеҗ«е…ғзҙ зҡ„дёӘж•° n
иӢҘж Ҳдёәз©әпјҢеҲҷиҝ”еӣһж•ҙж•°0
3. isempty(): еҲӨж–ӯжҳҜеҗҰдёәз©әж Ҳ
еҲӨж–ӯж ҲдёӯжҳҜеҗҰеӯҳеӮЁе…ғзҙ
4. push(data): е…Ҙж Ҳ
е°Ҷе…ғзҙ data жҸ’е…Ҙж ҲйЎ¶
5. pop(): еҮәж Ҳ
еҲ йҷӨ并иҝ”еӣһж ҲйЎ¶е…ғзҙ
4. peek(): еҸ–ж ҲйЎ¶е…ғзҙ
иҝ”еӣһж ҲйЎ¶е…ғзҙ еҖјпјҢдҪҶ并дёҚеҲ йҷӨе…ғзҙ
ж Ҳе…·жңүе№ҝжіӣзҡ„еә”з”ЁеңәжҷҜпјҢдҫӢеҰӮпјҡ
з¬ҰеҸ·зҡ„еҢ№й…ҚпјҢе…·дҪ“жҸҸиҝ°еҸӮиҖғ第3.3е°ҸиҠӮпјӣ
еҮҪж•°и°ғз”ЁпјҢжҜҸдёӘжңӘз»“жқҹи°ғз”Ёзҡ„еҮҪж•°йғҪдјҡеңЁеҮҪж•°ж ҲдёӯжӢҘжңүдёҖеқ—ж•°жҚ®еҢәпјҢдҝқеӯҳдәҶеҮҪж•°зҡ„йҮҚиҰҒдҝЎжҒҜпјҢеҢ…жӢ¬еҮҪж•°зҡ„еұҖйғЁеҸҳйҮҸгҖҒеҸӮж•°зӯүпјӣ
еҗҺзјҖиЎЁиҫҫејҸжұӮеҖјпјҢи®Ўз®—еҗҺзјҖиЎЁиҫҫејҸеҸӘйңҖдёҖдёӘз”ЁдәҺеӯҳж”ҫж•°еҖјзҡ„ж ҲпјҢйҒҚеҺҶиЎЁиҫҫејҸйҒҮеҲ°ж•°еҖјеҲҷе…Ҙж ҲпјҢйҒҮеҲ°иҝҗз®—з¬ҰеҲҷеҮәж ҲдёӨдёӘж•°еҖјиҝӣиЎҢи®Ўз®—пјҢ并е°Ҷи®Ўз®—з»“жһңе…Ҙж ҲпјҢжңҖеҗҺж Ҳдёӯдҝқз•ҷзҡ„е”ҜдёҖеҖјеҚідёәиЎЁиҫҫејҸз»“жһңпјӣ
зҪ‘йЎөжөҸи§Ҳдёӯзҡ„иҝ”еӣһжҢүй’®пјҢеҪ“жҲ‘们еңЁзҪ‘йЎөй—ҙиҝӣиЎҢи·іиҪ¬ж—¶пјҢиҝҷдәӣзҪ‘еқҖйғҪиў«еӯҳж”ҫеңЁдёҖдёӘж Ҳдёӯпјӣ
зј–иҫ‘еҷЁдёӯзҡ„ж’Өй”ҖеәҸеҲ—пјҢдёҺзҪ‘йЎөжөҸи§Ҳдёӯзҡ„иҝ”еӣһжҢүй’®зұ»дјјпјҢж ҲдҝқеӯҳжҜҸжӯҘзҡ„зј–иҫ‘ж“ҚдҪңгҖӮ
йҷӨдәҶд»ҘдёҠеә”з”ЁеӨ–пјҢжҲ‘们еңЁд№ӢеҗҺзҡ„еӯҰд№ дёӯиҝҳе°ҶзңӢеҲ°ж Ҳз”ЁдҪңи®ёеӨҡз®—жі•зҡ„иҫ…еҠ©ж•°жҚ®з»“жһ„гҖӮ
е’ҢзәҝжҖ§иЎЁдёҖж ·пјҢж ҲеҗҢж ·жңүдёӨз§ҚеӯҳеӮЁиЎЁзӨәж–№ејҸгҖӮ
йЎәеәҸж ҲжҳҜж Ҳзҡ„йЎәеәҸеӯҳеӮЁз»“жһ„пјҢе…¶еҲ©з”ЁдёҖз»„ең°еқҖиҝһз»ӯзҡ„еӯҳеӮЁеҚ•е…ғд»Һж Ҳеә•еҲ°ж ҲйЎ¶дҫқж¬Ўеӯҳж”ҫгҖӮеҗҢж—¶дҪҝз”ЁжҢҮй’ҲtopжқҘжҢҮзӨәж ҲйЎ¶е…ғзҙ еңЁйЎәеәҸж Ҳдёӯзҡ„зҙўеј•пјҢеҗҢж ·йЎәеәҸж ҲеҸҜд»ҘжҳҜеӣәе®ҡй•ҝеәҰе’ҢеҠЁжҖҒй•ҝеәҰпјҢеҪ“ж Ҳж»Ўж—¶пјҢе®ҡй•ҝйЎәеәҸж ҲдјҡжҠӣеҮәж Ҳж»ЎејӮеёёпјҢеҠЁжҖҒйЎәеәҸж ҲеҲҷдјҡеҠЁжҖҒз”іиҜ·з©әй—Із©әй—ҙгҖӮ
йЎәеәҸж Ҳзҡ„еҲқе§ӢеҢ–йңҖиҰҒдёүйғЁеҲҶдҝЎжҒҜпјҡstack еҲ—иЎЁз”ЁдәҺеӯҳеӮЁж•°жҚ®е…ғзҙ пјҢmax_size з”ЁдәҺеӯҳеӮЁ stack еҲ—иЎЁзҡ„жңҖеӨ§й•ҝеәҰпјҢд»ҘеҸҠ top з”ЁдәҺи®°еҪ•ж ҲйЎ¶е…ғзҙ зҡ„зҙўеј•пјҡ
class Stack: def __init__(self, max_size=10): self.max_size = max_size self.stack = self.max_size * [None] self.top = -1
2.1.2 жұӮж Ҳй•ҝ
з”ұдәҺ top иЎЁзӨәж ҲйЎ¶е…ғзҙ зҡ„зҙўеј•пјҢжҲ‘们еҸҜд»ҘжҚ®жӯӨж–№дҫҝзҡ„и®Ўз®—йЎәеәҸж Ҳдёӯзҡ„ж•°жҚ®е…ғзҙ ж•°йҮҸпјҢеҚіж Ҳй•ҝпјҡ
def size(self): return self.top + 1
2.1.3 еҲӨж Ҳз©ә
ж №жҚ®ж Ҳзҡ„й•ҝеәҰеҸҜд»ҘеҫҲе®№жҳ“зҡ„еҲӨж–ӯж ҲжҳҜеҗҰдёәз©әж Ҳпјҡ
def isempty(self): if self.size() == 0: return True else: return False
2.1.4 еҲӨж Ҳж»Ў
з”ұдәҺйңҖиҰҒжҸҗеүҚз”іиҜ·ж Ҳз©әй—ҙпјҢеӣ жӯӨжҲ‘们йңҖиҰҒиғҪеӨҹеҲӨж–ӯж ҲжҳҜеҗҰиҝҳжңүз©әй—Із©әй—ҙпјҡ
def isfully(self): if self.size() == self.max_size: return True else: return False
2.1.5 е…Ҙж Ҳ
е…Ҙж Ҳж—¶пјҢйңҖиҰҒйҰ–е…ҲеҲӨж–ӯж ҲдёӯжҳҜеҗҰиҝҳжңүз©әй—Із©әй—ҙпјҢ然еҗҺж №жҚ®ж Ҳдёәе®ҡй•ҝйЎәеәҸж ҲжҲ–еҠЁжҖҒйЎәеәҸж ҲпјҢе…Ҙж Ҳж“ҚдҪңзЁҚжңүдёҚеҗҢпјҡ
[е®ҡй•ҝйЎәеәҸж Ҳзҡ„е…Ҙж Ҳж“ҚдҪң] еҰӮжһңж Ҳж»ЎпјҢеҲҷеј•еҸ‘ејӮеёёпјҡ
def push(self, data):
if self.isfully():
raise IndexError('Stack Overflow!')
else:
self.top += 1
self.stack[self.top_1] = data[еҠЁжҖҒйЎәеәҸж Ҳзҡ„е…Ҙж Ҳж“ҚдҪң] еҰӮжһңж Ҳж»ЎпјҢеҲҷйҰ–е…Ҳз”іиҜ·ж–°з©әй—ҙпјҡ
def resize(self): new_size = 2 * self.max_size new_stack = [None] * new_size for i in range(self.num_items): new_stack[i] = self.items[i] self.stack = new_stack self.max_size = new_size def push(self, data): if self.isfully(): self.resize() else: self.top += 1 self.stack[self.top_1] = data
е…Ҙж Ҳзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәO(1)гҖӮиҝҷйҮҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢиҷҪ然еҪ“еҠЁжҖҒйЎәеәҸж Ҳж»Ўж—¶пјҢеҺҹж Ҳдёӯзҡ„е…ғзҙ йңҖиҰҒйҰ–е…ҲеӨҚеҲ¶еҲ°ж–°ж ҲдёӯпјҢ然еҗҺж·»еҠ ж–°е…ғзҙ пјҢдҪҶж №жҚ®гҖҠйЎәеәҸиЎЁеҸҠе…¶ж“ҚдҪңе®һзҺ°гҖӢдёӯйЎәеәҸиЎЁиҝҪеҠ ж“ҚдҪңзҡ„д»Ӣз»ҚпјҢз”ұдәҺnж¬Ўе…Ҙж Ҳж“ҚдҪңзҡ„жҖ»ж—¶й—ҙT(n) дёҺO(n) жҲҗжӯЈжҜ”пјҢеӣ жӯӨе…Ҙж Ҳзҡ„ж‘Ҡй”Җж—¶й—ҙеӨҚжқӮеәҰд»ҚеҸҜд»Ҙи®ӨдёәжҳҜO(1)гҖӮ
2.1.6 еҮәж Ҳ
иӢҘж ҲдёҚз©әпјҢеҲҷеҲ йҷӨ并иҝ”еӣһж ҲйЎ¶е…ғзҙ пјҡ
def pop(self):
if self.isempty():
raise IndexError('Stack Underflow!')
else:
result = self.stack[self.top]
self.top -= 1
return result2.1.7 жұӮж ҲйЎ¶е…ғзҙ
иӢҘж ҲдёҚз©әпјҢеҲҷеҸӘйңҖиҝ”еӣһж ҲйЎ¶е…ғзҙ пјҡ
def peek(self):
if self.isempty():
raise IndexError('Stack Underflow!')
else:
return self.stack[self.top]ж Ҳзҡ„еҸҰдёҖз§ҚеӯҳеӮЁиЎЁзӨәж–№ејҸжҳҜдҪҝз”Ёй“ҫејҸеӯҳеӮЁз»“жһ„пјҢеӣ жӯӨд№ҹеёёз§°дёәй“ҫж ҲпјҢе…¶дёӯ push ж“ҚдҪңжҳҜйҖҡиҝҮеңЁй“ҫиЎЁеӨҙйғЁжҸ’е…Ҙе…ғзҙ жқҘе®һзҺ°зҡ„пјҢpop ж“ҚдҪңжҳҜйҖҡиҝҮд»ҺеӨҙйғЁеҲ йҷӨиҠӮзӮ№жқҘе®һзҺ°зҡ„гҖӮ
2.2.1 ж Ҳз»“зӮ№
ж Ҳзҡ„з»“зӮ№е®һзҺ°дёҺй“ҫиЎЁе№¶ж— е·®еҲ«пјҡ
class Node: def __init__(self, data): self.data = data self.next = None def __str__(self): return str(self.data)
2.2.2 ж Ҳзҡ„еҲқе§ӢеҢ–
ж Ҳзҡ„еҲқе§ӢеҢ–еҮҪж•°дёӯпјҢдҪҝж ҲйЎ¶жҢҮй’ҲжҢҮеҗ‘ NoneпјҢ并еҲқе§ӢеҢ–ж Ҳй•ҝпјҡ
class Stack: def __init__(self): self.top = None # ж Ҳдёӯе…ғзҙ ж•° self.length = 0
2.2.3 жұӮж Ҳй•ҝ
иҝ”еӣһ length зҡ„еҖјз”ЁдәҺжұӮеҸ–ж Ҳзҡ„й•ҝеәҰпјҢеҰӮжһңжІЎжңү length еұһжҖ§пјҢеҲҷйңҖиҰҒйҒҚеҺҶж•ҙдёӘй“ҫиЎЁжүҚиғҪеҫ—еҲ°ж Ҳй•ҝпјҡ
def size(self): return self.length
2.2.4 еҲӨж Ҳз©ә
ж №жҚ®ж Ҳзҡ„й•ҝеәҰеҸҜд»ҘеҫҲе®№жҳ“зҡ„еҲӨж–ӯж ҲжҳҜеҗҰдёәз©әж Ҳпјҡ
def isempty(self): if self.length == 0: return True else: return False
2.2.5 е…Ҙж Ҳ
е…Ҙж Ҳж—¶пјҢеңЁж ҲйЎ¶жҸ’е…Ҙж–°е…ғзҙ еҚіеҸҜпјҡ
def push(self, data): p = Node(data) p.next = self.top self.top = p self.length += 1
з”ұдәҺжҸ’е…Ҙе…ғзҙ жҳҜеңЁй“ҫиЎЁеӨҙйғЁиҝӣиЎҢзҡ„пјҢеӣ жӯӨе…Ҙж Ҳзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәO(1)пјҢеңЁиҝҷз§Қжғ…еҶөдёӢй“ҫе°ҫдҪңдёәж Ҳеә• гҖӮ
2.2.5 еҮәж Ҳ
иӢҘж ҲдёҚз©әпјҢеҲҷеҲ йҷӨ并иҝ”еӣһж ҲйЎ¶е…ғзҙ пјҡ
def pop(self):
if self.isempty():
raise IndexError("Stack Underflow!")
ele = self.top.data
self.top = self.top.next
self.length -= 1
return eleз”ұдәҺеҲ йҷӨе…ғзҙ д»…йңҖдҝ®ж”№еӨҙжҢҮй’ҲжҢҮеҗ‘е…¶ next еҹҹпјҢеӣ жӯӨеҮәж Ҳзҡ„ж—¶й—ҙеӨҚжқӮеәҰеҗҢж ·дёәO(1)гҖӮ
2.2.6 жұӮж ҲйЎ¶е…ғзҙ
иӢҘж ҲдёҚз©әпјҢиҝ”еӣһж ҲйЎ¶е…ғзҙ еҚіеҸҜпјҢдҪҶж ҲйЎ¶е…ғзҙ 并дёҚдјҡиў«еҲ йҷӨпјҡ
def peek(self):
if self.isempty():
raise IndexError("Stack Underflow!")
return self.top.dataжң¬иҠӮжҲ‘们е°ҶеҜ№жҜ”ж Ҳзҡ„дёҚеҗҢе®һзҺ°д№Ӣй—ҙзҡ„ејӮеҗҢпјҡ
йЎәеәҸж Ҳ
ж“ҚдҪңзҡ„ж—¶й—ҙеӨҚжқӮеәҰеқҮдёәO(1)пјҢеҲ—иЎЁзҡ„е°ҫйғЁдҪңдёәж ҲйЎ¶
ж Ҳж»Ўж—¶йңҖиҰҒиҝӣиЎҢеҠЁжҖҒзҡ„жү©еұ•пјҢеӨҚеҲ¶еҺҹж Ҳе…ғзҙ еҲ°ж–°ж Ҳдёӯ
й“ҫж Ҳ
ж“ҚдҪңзҡ„ж—¶й—ҙеӨҚжқӮеәҰеқҮдёәO(1)пјҢй“ҫиЎЁзҡ„еӨҙйғЁдҪңдёәж ҲйЎ¶
дјҳйӣ…зҡ„жү©еұ•пјҢж— йңҖиҖғиҷ‘ж Ҳж»ЎпјҢйңҖиҰҒйўқеӨ–зҡ„з©әй—ҙеӯҳеӮЁжҢҮй’Ҳ
жҺҘдёӢжқҘпјҢжҲ‘们йҰ–е…ҲжөӢиҜ•дёҠиҝ°е®һзҺ°зҡ„й“ҫиЎЁпјҢд»ҘйӘҢиҜҒж“ҚдҪңзҡ„жңүж•ҲжҖ§пјҢ然еҗҺеҲ©з”Ёе®һзҺ°зҡ„еҹәжң¬ж“ҚдҪңжқҘи§ЈеҶіе®һйҷ…з®—жі•й—®йўҳгҖӮ
йҰ–е…ҲеҲқе§ӢеҢ–дёҖдёӘйЎәеәҸж Ҳ stackпјҢ然еҗҺжөӢиҜ•зӣёе…іж“ҚдҪңпјҡ
# еҲқе§ӢеҢ–дёҖдёӘжңҖеӨ§й•ҝеәҰдёә4зҡ„ж Ҳ
s = Stack(4)
print('ж Ҳз©ә?', s.isempty())
for i in range(4):
print('е…Ҙж Ҳе…ғзҙ пјҡ', i)
s.push(i)
print('ж Ҳж»Ў?', s.isfully())
print('ж ҲйЎ¶е…ғзҙ пјҡ', s.peek())
print('ж Ҳй•ҝеәҰдёәпјҡ', s.size())
while not s.isempty():
print('еҮәж Ҳе…ғзҙ пјҡ', s.pop())жөӢиҜ•зЁӢеәҸиҫ“еҮәз»“жһңеҰӮдёӢпјҡ
ж Ҳз©ә? True
е…Ҙж Ҳе…ғзҙ пјҡ 0
е…Ҙж Ҳе…ғзҙ пјҡ 1
е…Ҙж Ҳе…ғзҙ пјҡ 2
е…Ҙж Ҳе…ғзҙ пјҡ 3
ж Ҳж»Ў? True
ж ҲйЎ¶е…ғзҙ пјҡ 3
ж Ҳй•ҝеәҰдёәпјҡ 4
еҮәж Ҳе…ғзҙ пјҡ 3
еҮәж Ҳе…ғзҙ пјҡ 2
еҮәж Ҳе…ғзҙ пјҡ 1
еҮәж Ҳе…ғзҙ пјҡ 0
йҰ–е…ҲеҲқе§ӢеҢ–дёҖдёӘй“ҫж Ҳ stackпјҢ然еҗҺжөӢиҜ•зӣёе…іж“ҚдҪңпјҡ
# еҲқе§ӢеҢ–ж–°ж Ҳ
s = Stack()
print('ж Ҳз©ә?', s.isempty())
for i in range(4):
print('е…Ҙж Ҳе…ғзҙ пјҡ', i)
s.push(i)
print('ж ҲйЎ¶е…ғзҙ пјҡ', s.peek())
print('ж Ҳй•ҝеәҰдёәпјҡ', s.size())
while not s.isempty():
print('еҮәж Ҳе…ғзҙ пјҡ', s.pop())жөӢиҜ•зЁӢеәҸиҫ“еҮәз»“жһңеҰӮдёӢпјҡ
ж Ҳз©ә? True
е…Ҙж Ҳе…ғзҙ пјҡ 0
е…Ҙж Ҳе…ғзҙ пјҡ 1
е…Ҙж Ҳе…ғзҙ пјҡ 2
е…Ҙж Ҳе…ғзҙ пјҡ 3
ж ҲйЎ¶е…ғзҙ пјҡ 3
ж Ҳй•ҝеәҰдёәпјҡ 4
еҮәж Ҳе…ғзҙ пјҡ 3
еҮәж Ҳе…ғзҙ пјҡ 2
еҮәж Ҳе…ғзҙ пјҡ 1
еҮәж Ҳе…ғзҙ пјҡ 0
еҢ№й…Қз¬ҰеҸ·жҳҜжҢҮжӯЈзЎ®ең°еҢ№й…Қе·ҰеҸіеҜ№еә”зҡ„з¬ҰеҸ·(з¬ҰеҸ·е…Ғи®ёиҝӣиЎҢеөҢеҘ—)пјҢдёҚд»…жҜҸдёҖдёӘе·Ұз¬ҰеҸ·йғҪжңүдёҖдёӘеҸіз¬ҰеҸ·дёҺд№ӢеҜ№еә”пјҢиҖҢдё”дёӨдёӘз¬ҰеҸ·зҡ„зұ»еһӢд№ҹжҳҜдёҖиҮҙзҡ„пјҢдёӢж Үеұ•зӨәдәҶдёҖдәӣз¬ҰеҸ·дёІзҡ„еҢ№й…Қжғ…еҶөпјҡ
| з¬ҰеҸ·дёІ | жҳҜеҗҰеҢ№й…Қ |
|---|---|
| []()() | еҢ№й…Қ |
| [(())() | дёҚеҢ№й…Қ |
| {([]())} | еҢ№й…Қ |
| (())[]} | дёҚеҢ№й…Қ |
дёәдәҶжЈҖжҹҘз¬ҰеҸ·дёІзҡ„еҢ№й…Қжғ…еҶөпјҢйңҖиҰҒйҒҚеҺҶз¬ҰеҸ·дёІпјҢеҰӮжһңеӯ—з¬ҰжҳҜ (гҖҒ[ жҲ– { д№Ӣзұ»зҡ„ејҖе§ӢеҲҶйҡ”з¬ҰпјҢеҲҷе°Ҷе…¶еҶҷе…Ҙж ҲдёӯпјӣеҪ“йҒҮеҲ°иҜёеҰӮ )гҖҒ] жҲ– } зӯүз»“жқҹеҲҶйҡ”з¬Ұж—¶пјҢеҲҷж ҲйЎ¶е…ғзҙ еҮәж ҲпјҢ并е°Ҷе…¶дёҺеҪ“еүҚйҒҚеҺҶе…ғзҙ иҝӣиЎҢжҜ”иҫғпјҢеҰӮжһңе®ғ们еҢ№й…ҚпјҢеҲҷ继з»ӯи§Јжһҗз¬ҰеҸ·дёІпјҢеҗҰеҲҷиЎЁзӨәдёҚеҢ№й…ҚгҖӮеҪ“йҒҚеҺҶе®ҢжҲҗеҗҺпјҢеҰӮжһңж ҲдёҚдёәз©әпјҢеҲҷеҗҢж ·иЎЁзӨәдёҚеҢ№й…Қпјҡ
def isvalid_expression(expression):
stack = Stack()
symbols = {')':'(', ']':'[', '}':'{'}
for s in expression:
if s in symbols:
if stack:
top_element = stack.pop()
else:
top_element = '#'
if symbols[s] != top_element:
return False
else:
stack.push(s)
return not stackз”ұдәҺжҲ‘们еҸӘйңҖиҰҒйҒҚеҺҶз¬ҰеҸ·дёІдёҖиҫ№пјҢеӣ жӯӨз®—жі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәO(n)пјҢз®—жі•зҡ„з©әй—ҙеӨҚжқӮеәҰеҗҢж ·дёәO(n)гҖӮ
з»ҷе®ҡдёҖй“ҫиЎЁ(еёҰжңүеӨҙз»“зӮ№) L : L0→L1→…→Ln пјҢе°Ҷе…¶йҮҚжҺ’дёәпјҡL0→Ln→L1→Ln−1 … гҖӮ
дҫӢеҰӮй“ҫиЎЁдёӯеҢ…еҗ« 9 дёӘе…ғзҙ пјҢеҲҷдёӢеӣҫзҺ°е®һдәҶйҮҚжҺ’еүҚеҗҺзҡ„й“ҫиЎЁе…ғзҙ жғ…еҶөпјҡ
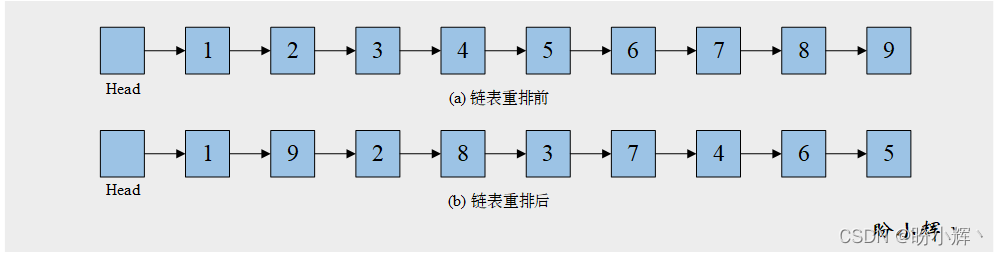
з”ұдәҺж Ҳзҡ„е…ҲиҝӣеҗҺеҮәеҺҹеҲҷпјҢеҸҜд»ҘеҲ©з”Ёж ҲдёҺеҺҹй“ҫиЎЁзҡ„й…ҚеҗҲиҝӣиЎҢйҮҚжҺ’пјҢйҰ–ж¬ЎжҢүйҒҚеҺҶй“ҫиЎЁпјҢе°ҶжҜҸдёӘз»“зӮ№е…Ҙж Ҳпјӣж Ҳдёӯе…ғзҙ зҡ„еҮәж ҲйЎәеәҸдёәеҺҹй“ҫиЎЁз»“зӮ№зҡ„йҖҶеәҸпјҢ然еҗҺдәӨжӣҝйҒҚеҺҶй“ҫиЎЁе’Ңж ҲпјҢжһ„е»әж–°й“ҫиЎЁгҖӮ
def reorder_list(L): p = L.head.next if p == None: return L stack = Stack() while p!= None: stack.push(p) p = p.next l = L.head.next from_head = L.head.next from_stack = True while (from_stack and l != stack.peek() or (not from_stack and l != from_head)): if from_stack: from_head = from_head.next l.next = stack.pop() from_stack = False else: l.next = from_head from_stack = True l = l.next l.next = None
иҜҘз®—жі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰе’Ңз©әй—ҙеӨҚжқӮеәҰеқҮдёәO(n)гҖӮ
е…ідәҺвҖңPythonж•°жҚ®з»“жһ„зҡ„ж Ҳе®һдҫӢеҲҶжһҗвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶзӮ№гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ