您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“ElasticSearch解决大数据量检索的方法”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“ElasticSearch解决大数据量检索的方法”文章能帮助大家解决问题。
如果你的项目里有超过千万上亿级别的数据,且数据日增量较大需要高性能检索时,如订单数据,你该怎么办?
作为面试官,你需要找一个能解决这个问题的人!为应聘者,你该如何回答面试官这个问题?
你可以了解下使用搜索引擎框架,Elasticsearch (ES)是一个不错的开源搜索引擎框架。我们可以把 ES 当做“数据库”来使用,全球很多知名社区的全文检索都采用ES,如维基百科、Stack Overflow、Github等。
ElasticSearch是开源的,它基于lucene,是伸缩性强、分布式、高可用的全⽂搜索引擎,可以简单地通过RESTful 使用JSON格式索引数据。
尝试想一下,如果你做的是一个知识库系统,系统里有大量文章,如果你想通过某一个或关键字检索文章的内容,如果用MySQL来做这件事,光靠 like 查询根本无法满足,全文检索就是对一篇文章进行索引,ES可以把内容根据词的意义进行分词,然后分别创建索引,例如”我要励志做一个有追求的程序员” ,经过ES分词后是:“我“,“我要”,”励志“,“一个“,”有追求“,“程序员”,无论你根据哪个关键词去检索,都会检索到这句话。
让你不需要了解背后复杂的逻辑,即可完成搜索,Elasticsearch致力于隐藏分布式系统的复杂性。以下这些操作都是在底层自动完成的:
将你的文档分区到不同的容器或者分片(shards)中,它们可以存在于一个或多个节点中。
将分片均匀的分配到各个节点,对索引和搜索做负载均衡。
根据ES支持全文索引这个特性,我们还可以通过它做很多所有关于模糊搜索的功能,大数据量多维度聚合也是ES的强项,如天猫商城,通过关键字搜索商品,输入iph后就会自动加载iphone相关的所有商品,这是典型的搜索引擎使用场景。
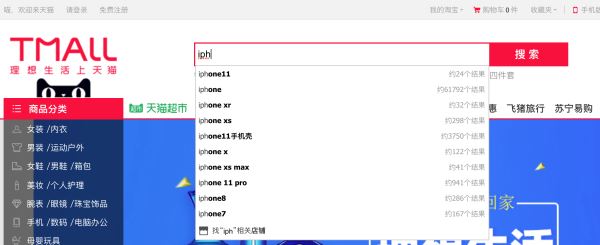
问题分析: 凡事大数据量且需要检索的,这个时候你都可以想到ES,传统关系型数据库查询速度变慢,数据库分表联合查询速度慢。
答:有这样一个需求场景,运营系统需要一个订单分析工具,当时我们的订单库总数已经远远超过亿级别数据量,每天增量在百万级。
系统初期订单查询主要采用MySQL查询,并没有使用其他数据库,随着业务的发展,系统主要面临两个挑战:
随着数据增多,MySQL 分库分表后单张表数据依然增加到了几千万数据量级,查询越来越慢。
查询中带有大量聚合运算,如过滤计算异常订单总数,完成订单总数,计算订单金额等,MySQL并不擅长使用sql做大规模运算。
针对上述两个问题,我使用了 Elasticsearch 完美地应对慢查询这个问题,我使用ES作为主查询数据源,MySQL作为降级备案,如果 ES 集群因为各种原因不可用了,系统会把订单查询数据源自动切换到 MySQL 数据源,对于运营系统,虽然查询会变慢,但是不会耽误正常使用,而且这种降级的概率也极少发生。
系统架构图这样的:(尽量给面试官展示明白这个图)
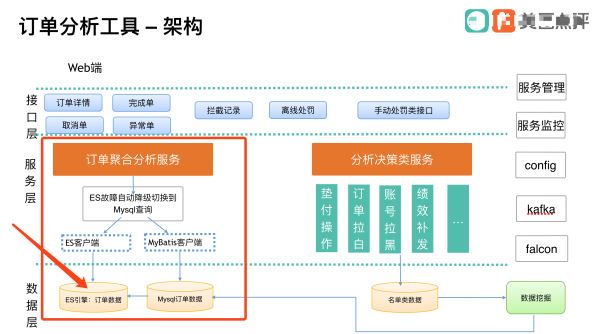
重点关注红色框,我使用了 ES 作为首选订单查询源,MySQL作为备份数据源,中间加入自动降级开关。
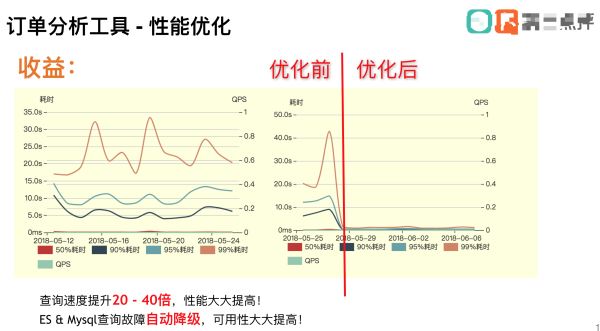
答:使用 ES 后,查询速度当然是大大的提高。
使用MySQL的时候99%的查询时间在10s+,架构引入ES后上线后,查询时间迅速降低到毫秒级别。
我还保留了性能监控的图放在我述职报告里,为升级加薪打下扎实的基础。
面试官一直点头,对我这一波操作非常认可。
问题分析:有些人刚刚接触 Elasticsearch 的时候,只顾用,只知道ES快,能装很多数据,但是面试官稍微问了一个倒排索引就懵逼了,还好意思说你会用搜索引擎?
答:先说说ES中的 Index,Document,Type,以及对应MySQL数据库
索引(Index):
索引的概念相当于MySQL里数据库的概念,用ES创建一个索引就是创建一个库,比如电商系统里给订单创建一个订单的索引,那客服系统就可以通过订单索引快速查询订单所有信息快速处理客诉。
文档(Document):
ES属于文档型数据库,文档的概念就相当于MySQL里一条数据的概念,很多个文档(很多条数据)构成了一个索引。
类型(Type)
上面说文档的概念就相当于MySQL里一条数据的概念,MySQL里一条数据有很多个字段,比如订单号,用户手机号,订单金额等,Type 的概念相当于根据每个字段聚合所一张表,如根据订单号分组,按照手机号分组,这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤文档,无论根据哪个字段搜索都有对应的Type(表)。
如果还不明白,直接给你整理成表:ES VS Mysql
| ElasticSearch | 关系型数据库:MySQL | |
|---|---|---|
| 对应关系: | 索引 | 库 |
| 对应关系: | 类型type | 数据表 |
| 对应关系: | 文档 | 行 |
| 对应关系: | 字段Field | 列 |
Tip: 如果你使用过 Elasticsearch 不知道倒排索引的概念那恐怕有点说不过去,倒排索引也叫反向索引(Inverted Index)
(开始给面试官举例分析倒排索引,我可是货真价实做过功课的)
有这样三段话:
hello everyone
this article is based on inverted index
which is hashmap like data structure
使用ES保存后结构如下:
hello (1, 1)
everyone (1, 2)
this (2, 1)
article (2, 2)
is (2, 3); (3, 2)
based (2, 4)
on (2, 5)
inverted (2, 6)
index (2, 7)
which (3, 1)
hashmap (3, 3)
like (3, 4)
data (3, 5)
structure (3, 6)
hello 出现在第1句话第1个单词,所以是(1, 1) ,is (2, 3); (3, 2) 表示is出现在第2句第3个单词和第3句第2个单词,这样经过拆分后,每个关键词出现在哪句话哪个位置都一目了然,非常方便检索,这便是倒排索引的概念。试想一下,我们使用的百度或是谷歌检索,是不是这种数据结构更容易让我们找到你想要的所有内容,这便是倒排索引带给我们的便利之处,倒排索引允许快速全文搜索,但是在将文档添加到数据库时会增加处理成本
面试官: 行了行了,我知道你理解了,时间有限咱先不聊这个了。
这才是面试理想效果,让面试官无话可说。
关于“ElasticSearch解决大数据量检索的方法”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。