жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңжҖҺд№ҲдҪҝз”ЁApache HudiеҠ йҖҹдј з»ҹзҡ„жү№еӨ„зҗҶжЁЎејҸвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңжҖҺд№ҲдҪҝз”ЁApache HudiеҠ йҖҹдј з»ҹзҡ„жү№еӨ„зҗҶжЁЎејҸвҖқеҗ§пјҒ
Apache Hudi(з®Җз§°пјҡHudi)дҪҝеҫ—жӮЁиғҪеңЁhadoopе…је®№зҡ„еӯҳеӮЁд№ӢдёҠеӯҳеӮЁеӨ§йҮҸж•°жҚ®пјҢеҗҢж—¶е®ғиҝҳжҸҗдҫӣдёӨз§ҚеҺҹиҜӯпјҢдҪҝеҫ—йҷӨдәҶз»Ҹе…ёзҡ„жү№еӨ„зҗҶд№ӢеӨ–пјҢиҝҳеҸҜд»ҘеңЁж•°жҚ®ж№–дёҠиҝӣиЎҢжөҒеӨ„зҗҶгҖӮ
еңЁжҲ‘们зҡ„з”ЁдҫӢдёӯ1-10% жҳҜеҜ№еҺҶеҸІи®°еҪ•зҡ„жӣҙж–°гҖӮеҪ“и®°еҪ•жӣҙж–°ж—¶пјҢжҲ‘们йңҖиҰҒд»Һд№ӢеүҚзҡ„ updated_date еҲҶеҢәдёӯеҲ йҷӨд№ӢеүҚзҡ„жқЎзӣ®пјҢ并е°ҶжқЎзӣ®ж·»еҠ еҲ°жңҖж–°зҡ„еҲҶеҢәдёӯпјҢеңЁжІЎжңүеҲ йҷӨе’Ңжӣҙж–°еҠҹиғҪзҡ„жғ…еҶөдёӢпјҢжҲ‘们еҝ…йЎ»йҮҚж–°иҜ»еҸ–ж•ҙдёӘеҺҶеҸІиЎЁеҲҶеҢә -> еҺ»йҮҚж•°жҚ® -> з”Ёж–°зҡ„еҺ»йҮҚж•°жҚ®иҰҶзӣ–ж•ҙдёӘиЎЁеҲҶеҢә
иҝҷдёӘиҝҮзЁӢжңүж•ҲпјҢдҪҶд№ҹжңүе…¶иҮӘиә«зҡ„зјәйҷ·пјҡ
ж—¶й—ҙе’ҢжҲҗжң¬——жҜҸеӨ©йғҪйңҖиҰҒиҰҶзӣ–ж•ҙдёӘеҺҶеҸІиЎЁ
ж•°жҚ®зүҲжң¬жҺ§еҲ¶——жІЎжңүејҖз®ұеҚіз”Ёзҡ„ж•°жҚ®е’Ңжё…еҚ•зүҲжң¬жҺ§еҲ¶пјҲеӣһж»ҡгҖҒ并еҸ‘иҜ»еҸ–е’ҢеҶҷе…ҘгҖҒж—¶й—ҙзӮ№жҹҘиҜўгҖҒж—¶й—ҙж—…иЎҢд»ҘеҸҠзӣёе…іеҠҹиғҪдёҚеӯҳеңЁпјү
еҶҷе…Ҙж”ҫеӨ§——ж—ҘеёёеҺҶеҸІж•°жҚ®иҰҶзӣ–еңәжҷҜдёӯзҡ„еӨ–йғЁпјҲжҲ–иҮӘжҲ‘з®ЎзҗҶпјүж•°жҚ®зүҲжң¬жҺ§еҲ¶еўһеҠ дәҶеҶҷе…Ҙж”ҫеӨ§пјҢд»ҺиҖҢеҚ з”ЁжӣҙеӨҡзҡ„ S3 еӯҳеӮЁ
еҖҹеҠ©Apache HudiпјҢжҲ‘们еёҢжңӣеңЁе°Ҷж•°жҚ®ж‘„еҸ–еҲ°ж•°жҚ®ж№–дёӯзҡ„еҗҢж—¶пјҢжүҫеҲ°жӣҙеҘҪзҡ„йҮҚеӨҚж•°жҚ®еҲ йҷӨе’Ңж•°жҚ®зүҲжң¬жҺ§еҲ¶дјҳеҢ–и§ЈеҶіж–№жЎҲгҖӮ
еҪ“жҲ‘们ејҖе§ӢеңЁжҲ‘们зҡ„ж•°жҚ®ж№–дёҠе®һзҺ° Apache Hudi зҡ„ж—…зЁӢж—¶пјҢжҲ‘д»¬ж №жҚ®иЎЁзҡ„дё»иҰҒз”ЁжҲ·зҡ„жҹҘиҜўжЁЎејҸе°ҶиЎЁеҲҶдёә 2 зұ»гҖӮ
йқўеҗ‘ETL пјҡиҝҷжҳҜжҢҮжҲ‘们д»Һеҗ„з§Қз”ҹдә§зі»з»ҹж‘„еҸ–еҲ°ж•°жҚ®ж№–дёӯзҡ„еӨ§еӨҡж•°еҺҹе§Ӣ/еҹәжң¬еҝ«з…§иЎЁгҖӮ еҰӮжһңиҝҷдәӣиЎЁиў« ETL дҪңдёҡе№ҝжіӣдҪҝз”ЁпјҢйӮЈд№ҲжҲ‘们е°ҶжҜҸж—Ҙж•°жҚ®еҲҶеҢәдҝқжҢҒеңЁ updated_dateпјҢиҝҷж ·дёӢжёёдҪңдёҡеҸҜд»Ҙз®ҖеҚ•ең°иҜ»еҸ–жңҖж–°зҡ„ updated_at еҲҶеҢә并пјҲйҮҚж–°пјүеӨ„зҗҶж•°жҚ®гҖӮ
йқўеҗ‘еҲҶжһҗеёҲпјҡйҖҡеёёеҢ…жӢ¬з»ҙеәҰиЎЁе’ҢдёҡеҠЎеҲҶжһҗеёҲжҹҘиҜўзҡ„еӨ§йғЁеҲҶи®Ўз®— OLAPпјҢеҲҶжһҗеёҲйҖҡеёёйңҖиҰҒжҹҘзңӢеҹәдәҺдәӢеҠЎпјҲжҲ–дәӢ件пјүcreated_date зҡ„ж•°жҚ®пјҢиҖҢдёҚеӨӘе…іеҝғ updated_dateгҖӮ
иҝҷжҳҜдёҖдёӘзӨәдҫӢз”өеӯҗе•ҶеҠЎи®ўеҚ•ж•°жҚ®жөҒпјҢд»Һж‘„еҸ–еҲ°ж•°жҚ®ж№–еҲ°еҲӣе»ә OLAPпјҢжңҖеҗҺеҲ°дёҡеҠЎеҲҶжһҗеёҲжҹҘиҜўе®ғ
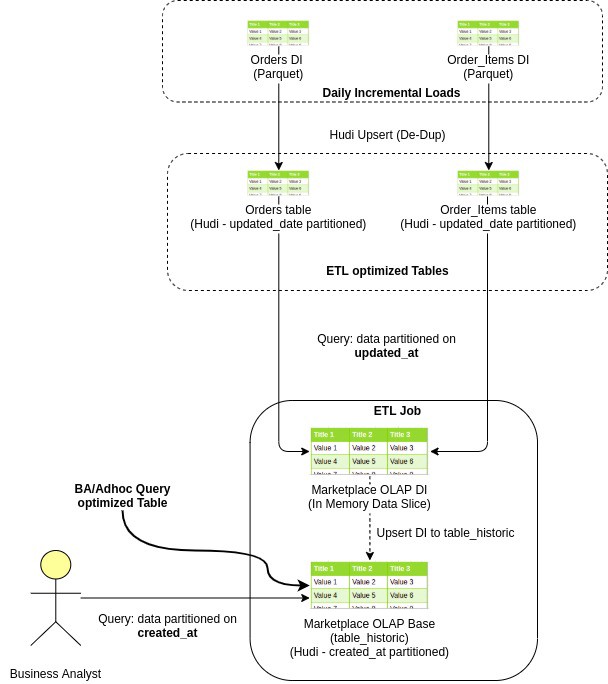
з”ұдәҺдёӨз§Қзұ»еһӢзҡ„иЎЁзҡ„ж—ҘжңҹеҲҶеҢәеҲ—дёҚеҗҢпјҢжҲ‘们йҮҮз”ЁдёҚеҗҢзҡ„зӯ–з•ҘжқҘи§ЈеҶіиҝҷдёӨдёӘз”ЁдҫӢгҖӮ
еңЁ Hudi дёӯпјҢжҲ‘们йңҖиҰҒжҢҮе®ҡеҲҶеҢәеҲ—е’Ңдё»й”®еҲ—пјҢд»Ҙдҫҝ Hudi еҸҜд»ҘдёәжҲ‘们еӨ„зҗҶжӣҙж–°е’ҢеҲ йҷӨгҖӮ
д»ҘдёӢжҳҜжҲ‘们еҰӮдҪ•еӨ„зҗҶйқўеҗ‘еҲҶжһҗеёҲзҡ„иЎЁдёӯзҡ„жӣҙж–°е’ҢеҲ йҷӨзҡ„йҖ»иҫ‘пјҡ
иҜ»еҸ–дёҠжёёж•°жҚ®зҡ„ D-n дёӘ updated_date еҲҶеҢәгҖӮ
еә”з”Ёж•°жҚ®иҪ¬жҚўгҖӮ зҺ°еңЁиҝҷдёӘж•°жҚ®е°ҶеҸӘжңүж–°зҡ„жҸ’е…Ҙе’ҢеҫҲе°‘зҡ„жӣҙж–°и®°еҪ•гҖӮ
еҸ‘еҮә hudi upsert ж“ҚдҪңпјҢе°ҶеӨ„зҗҶеҗҺзҡ„ж•°жҚ® upsert еҲ°зӣ®ж Ү Hudi иЎЁгҖӮ
з”ұдәҺдё»й”®е’Ң created_date еҜ№дәҺйҖҖеҮәе’Ңдј е…Ҙи®°еҪ•дҝқжҢҒзӣёеҗҢпјҢHudi йҖҡиҝҮдҪҝз”ЁжқҘиҮӘдј е…Ҙи®°еҪ• created_date е’Ң primary_key еҲ—зҡ„жӯӨдҝЎжҒҜиҺ·еҸ–зҺ°жңүи®°еҪ•зҡ„еҲҶеҢәе’ҢеҲҶеҢәж–Ү件и·Ҝеҫ„гҖӮ
еҪ“жҲ‘们ејҖе§ӢдҪҝз”Ё Hudi ж—¶пјҢеңЁйҳ…иҜ»дәҶи®ёеӨҡеҚҡе®ўе’Ңж–ҮжЎЈд№ӢеҗҺпјҢеңЁ created_date дёҠеҜ№йқўеҗ‘ ETL зҡ„иЎЁиҝӣиЎҢеҲҶеҢәдјјд№ҺжҳҜеҗҲд№ҺйҖ»иҫ‘зҡ„гҖӮ
жӯӨеӨ– Hudi жҸҗдҫӣеўһйҮҸж¶Ҳиҙ№еҠҹиғҪпјҢе…Ғи®ёжҲ‘们еңЁ created_date дёҠеҜ№иЎЁиҝӣиЎҢеҲҶеҢәпјҢ并仅иҺ·еҸ–еңЁ D-1 жҲ– D-n дёҠжҸ’е…ҘпјҲжҸ’е…ҘжҲ–жӣҙж–°пјүзҡ„йӮЈдәӣи®°еҪ•гҖӮ
иҝҷз§Қж–№жі•еңЁзҗҶи®әдёҠж•ҲжһңеҫҲеҘҪпјҢдҪҶеңЁж”№йҖ дј з»ҹзҡ„ж—Ҙеёёжү№еӨ„зҗҶиҝҮзЁӢдёӯзҡ„еўһйҮҸж¶Ҳиҙ№ж—¶пјҢе®ғеёҰжқҘдәҶе…¶д»–дёҖзі»еҲ—жҢ‘жҲҳпјҡ
Hudi з»ҙжҠӨдәҶеңЁдёҚеҗҢж—¶еҲ»еңЁиЎЁдёҠжү§иЎҢзҡ„жүҖжңүж“ҚдҪңзҡ„ж—¶й—ҙиЎЁпјҢиҝҷдәӣжҸҗдәӨеҢ…еҗ«жңүе…ідҪңдёә upsert зҡ„дёҖйғЁеҲҶжҸ’е…ҘжҲ–йҮҚеҶҷзҡ„йғЁеҲҶж–Ү件зҡ„дҝЎжҒҜпјҢжҲ‘们е°ҶжӯӨ Hudi иЎЁз§°дёә Commit TimelineгҖӮ
иҝҷйҮҢиҰҒжіЁж„Ҹзҡ„йҮҚиҰҒдҝЎжҒҜжҳҜеўһйҮҸжҹҘиҜўеҹәдәҺжҸҗдәӨж—¶й—ҙзәҝпјҢиҖҢдёҚдҫқиө–дәҺж•°жҚ®и®°еҪ•дёӯеӯҳеңЁзҡ„е®һйҷ…жӣҙж–°/еҲӣе»әж—ҘжңҹдҝЎжҒҜгҖӮ
еҶ·еҗҜеҠЁпјҡеҪ“жҲ‘们е°ҶзҺ°жңүзҡ„дёҠжёёиЎЁиҝҒ移еҲ° Hudi ж—¶пјҢD-1 Hudi еўһйҮҸжҹҘиҜўе°ҶиҺ·еҸ–е®Ңж•ҙзҡ„иЎЁпјҢиҖҢдёҚд»…д»…жҳҜ D-1 жӣҙж–°гҖӮеҸ‘з”ҹиҝҷз§Қжғ…еҶөжҳҜеӣ дёәеңЁејҖе§Ӣж—¶пјҢж•ҙдёӘиЎЁжҳҜйҖҡиҝҮеңЁ D-1 жҸҗдәӨж—¶й—ҙзәҝеҶ…еҸ‘з”ҹзҡ„еҚ•дёӘеҲқе§ӢжҸҗдәӨжҲ–еӨҡдёӘжҸҗдәӨеҲӣе»әзҡ„пјҢ并且зјәе°‘зңҹжӯЈзҡ„еўһйҮҸжҸҗдәӨдҝЎжҒҜгҖӮ
еҺҶеҸІж•°жҚ®йҮҚж–°ж‘„еҸ–пјҡеңЁжҜҸдёӘ常规еўһйҮҸ D-1 жӢүеҸ–дёӯпјҢжҲ‘们жңҹжңӣд»…еңЁ D-1 дёҠжӣҙж–°зҡ„и®°еҪ•дҪңдёәиҫ“еҮәгҖӮдҪҶжҳҜеңЁйҮҚж–°ж‘„еҸ–еҺҶеҸІж•°жҚ®зҡ„жғ…еҶөдёӢпјҢдјҡеҶҚж¬ЎеҮәзҺ°зұ»дјјдәҺеүҚйқўжҸҸиҝ°зҡ„еҶ·еҗҜеҠЁй—®йўҳзҡ„й—®йўҳпјҢ并且дёӢжёёдҪңдёҡд№ҹдјҡеҮәзҺ° OOMгҖӮ
еҺҶеҸІж•°жҚ®йҮҚж–°ж‘„еҸ–пјҡеңЁжҜҸдёӘ常规еўһйҮҸ D-1 жӢүеҸ–дёӯпјҢжҲ‘们жңҹжңӣд»…еңЁ D-1 дёҠжӣҙж–°зҡ„и®°еҪ•дҪңдёәиҫ“еҮәгҖӮдҪҶжҳҜеңЁйҮҚж–°ж‘„еҸ–еҺҶеҸІж•°жҚ®зҡ„жғ…еҶөдёӢпјҢдјҡеҶҚж¬ЎеҮәзҺ°зұ»дјјдәҺеүҚйқўжҸҸиҝ°зҡ„еҶ·еҗҜеҠЁй—®йўҳзҡ„й—®йўҳпјҢ并且дёӢжёёдҪңдёҡд№ҹдјҡеҮәзҺ° OOMгҖӮ
дҪңдёәйқўеҗ‘ ETL зҡ„дҪңдёҡзҡ„и§ЈеҶіж–№жі•пјҢжҲ‘们е°қиҜ•е°Ҷж•°жҚ®еҲҶеҢәдҝқжҢҒеңЁ updated_date жң¬иә«пјҢ然иҖҢиҝҷз§Қж–№жі•д№ҹжңүе…¶иҮӘиә«зҡ„жҢ‘жҲҳгҖӮ
жҲ‘们зҹҘйҒ“ Hudi иЎЁзҡ„жң¬ең°зҙўеј•пјҢHudi дҫқйқ зҙўеј•жқҘиҺ·еҸ–еӯҳеӮЁеңЁж•°жҚ®еҲҶеҢәжң¬ең°зӣ®еҪ•дёӯзҡ„ Row-to-Part_file жҳ е°„гҖӮеӣ жӯӨпјҢеҰӮжһңжҲ‘们зҡ„иЎЁеңЁ updated_date иҝӣиЎҢеҲҶеҢәпјҢHudi ж— жі•и·ЁеҲҶеҢәиҮӘеҠЁеҲ йҷӨйҮҚеӨҚи®°еҪ•гҖӮ
Hudi зҡ„е…ЁеұҖзҙўеј•зӯ–з•ҘиҰҒжұӮжҲ‘们дҝқз•ҷдёҖдёӘеҶ…йғЁжҲ–еӨ–йғЁзҙўеј•жқҘз»ҙжҠӨи·ЁеҲҶеҢәзҡ„ж•°жҚ®еҺ»йҮҚгҖӮеҜ№дәҺеӨ§ж•°жҚ®йҮҸпјҢжҜҸеӨ©еӨ§зәҰ 2 дәҝжқЎи®°еҪ•пјҢиҝҷз§Қж–№жі•иҰҒд№ҲиҝҗиЎҢзј“ж…ўпјҢиҰҒд№Ҳеӣ OOM иҖҢеӨұиҙҘгҖӮ
еӣ жӯӨпјҢдёәдәҶи§ЈеҶіжӣҙж–°ж—ҘжңҹеҲҶеҢәзҡ„ж•°жҚ®йҮҚеӨҚжҢ‘жҲҳпјҢжҲ‘们жҸҗеҮәдәҶдёҖз§Қе…Ёж–°зҡ„йҮҚеӨҚж•°жҚ®еҲ йҷӨзӯ–з•ҘпјҢиҜҘзӯ–з•Ҙд№ҹе…·жңүеҫҲй«ҳзҡ„жҖ§иғҪгҖӮ
жҹҘжүҫжӣҙж–° - д»ҺжҜҸж—ҘеўһйҮҸиҙҹиҪҪдёӯпјҢд»…иҝҮж»ӨжҺүжӣҙж–°пјҲ1-10% зҡ„ DI ж•°жҚ®пјүпјҲе…¶дёӯ updated_date> created_dateпјүпјҲеҝ«йҖҹпјҢд»…жҳ е°„ж“ҚдҪңпјү
жүҫеҲ°иҝҮж—¶жӣҙж–° - е°ҶиҝҷдәӣвҖңжӣҙж–°вҖқдёҺдёӢжёё Hudi еҹәиЎЁе№ҝж’ӯиҝһжҺҘгҖӮ з”ұдәҺжҲ‘们еҸӘиҺ·еҸ–жӣҙж–°зҡ„и®°еҪ•пјҲд»…еҚ жҜҸж—ҘеўһйҮҸзҡ„ 1-10%пјүпјҢеӣ жӯӨеҸҜд»Ҙе®һзҺ°й«ҳжҖ§иғҪзҡ„е№ҝж’ӯиҝһжҺҘгҖӮ иҝҷдёәжҲ‘们жҸҗдҫӣдәҶдёҺжӣҙж–°и®°еҪ•зӣёеҜ№еә”зҡ„еҹәзЎҖ Hudi иЎЁдёӯзҡ„жүҖжңүзҺ°жңүи®°еҪ•
еҲ йҷӨиҝҮж—¶жӣҙж–°——еңЁеҹәжң¬ Hudi иЎЁи·Ҝеҫ„дёҠзҡ„иҝҷдәӣвҖңиҝҮж—¶жӣҙж–°вҖқдёҠеҸ‘еҮә Hudi еҲ йҷӨе‘Ҫд»Ө
жҸ’е…Ҙ - еңЁеҹәжң¬ hudi иЎЁи·Ҝеҫ„дёҠзҡ„е®Ңж•ҙжҜҸж—ҘеўһйҮҸиҙҹиҪҪдёҠеҸ‘еҮә hudi insert е‘Ҫд»Ө
иҝӣдёҖжӯҘдјҳеҢ–з”Ё true еЎ«е……йҷҲж—§жӣҙж–°дёӯзҡ„ _hoodie_is_deleted еҲ—пјҢ并е°Ҷе…¶дёҺжҜҸж—ҘеўһйҮҸиҙҹиҪҪз»“еҗҲгҖӮ йҖҡиҝҮеҹәжң¬ hudi иЎЁи·Ҝеҫ„еҸ‘еҮәжӯӨж•°жҚ®зҡ„ upsert е‘Ҫд»ӨгҖӮ е®ғе°ҶеңЁеҚ•дёӘж“ҚдҪңпјҲе’ҢеҚ•дёӘжҸҗдәӨпјүдёӯжү§иЎҢжҸ’е…Ҙе’ҢеҲ йҷӨгҖӮ
ж—¶й—ҙе’ҢжҲҗжң¬——Hudi еңЁйҮҚеӨҚж•°жҚ®еҲ йҷӨж—¶дёҚдјҡиҰҶзӣ–ж•ҙдёӘиЎЁгҖӮ е®ғеҸӘжҳҜйҮҚеҶҷжҺҘ收жӣҙж–°зҡ„йғЁеҲҶж–Ү件гҖӮ еӣ жӯӨиҫғе°Ҹзҡ„ upsert е·ҘдҪң
ж•°жҚ®зүҲжң¬жҺ§еҲ¶——Hudi дҝқз•ҷиЎЁзүҲжң¬пјҲжҸҗдәӨеҺҶеҸІпјүпјҢеӣ жӯӨжҸҗдҫӣе®һж—¶жҹҘиҜўпјҲж—¶й—ҙж—…иЎҢпјүе’ҢиЎЁзүҲжң¬еӣһж»ҡеҠҹиғҪгҖӮ
еҶҷе…Ҙж”ҫеӨ§——з”ұдәҺеҸӘжңүйғЁеҲҶж–Ү件被жӣҙ改并дҝқз•ҷз”ЁдәҺж•°жҚ®жё…еҚ•зүҲжң¬жҺ§еҲ¶пјҢжҲ‘们дёҚйңҖиҰҒдҝқз•ҷе®Ңж•ҙж•°жҚ®зҡ„зүҲжң¬гҖӮ еӣ жӯӨж•ҙдҪ“еҶҷе…Ҙж”ҫеӨ§жҳҜжңҖе°Ҹзҡ„гҖӮ
дҪңдёәж•°жҚ®зүҲжң¬жҺ§еҲ¶зҡ„еҸҰдёҖдёӘеҘҪеӨ„пјҢе®ғи§ЈеҶідәҶ并еҸ‘иҜ»еҸ–е’ҢеҶҷе…Ҙй—®йўҳпјҢеӣ дёәж•°жҚ®зүҲжң¬жҺ§еҲ¶дҪҝ并еҸ‘иҜ»еҸ–еҷЁеҸҜд»ҘиҜ»еҸ–ж•°жҚ®ж–Ү件зҡ„зүҲжң¬жҺ§еҲ¶еүҜжң¬пјҢ并且еҪ“并еҸ‘еҶҷе…ҘеҷЁз”Ёж–°ж•°жҚ®иҰҶзӣ–еҗҢдёҖеҲҶеҢәж—¶дёҚдјҡжҠӣеҮә FileNotFoundException ж–Ү件гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңжҖҺд№ҲдҪҝз”ЁApache HudiеҠ йҖҹдј з»ҹзҡ„жү№еӨ„зҗҶжЁЎејҸвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№жҖҺд№ҲдҪҝз”ЁApache HudiеҠ йҖҹдј з»ҹзҡ„жү№еӨ„зҗҶжЁЎејҸиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ