您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍Apache Hudi结合Flink的示例分析,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!

实时平台上线后,主要需求是开发实时报表,即抽取各类数据源做实时etl后,吐出实时指标到oracle库中供展示查询。
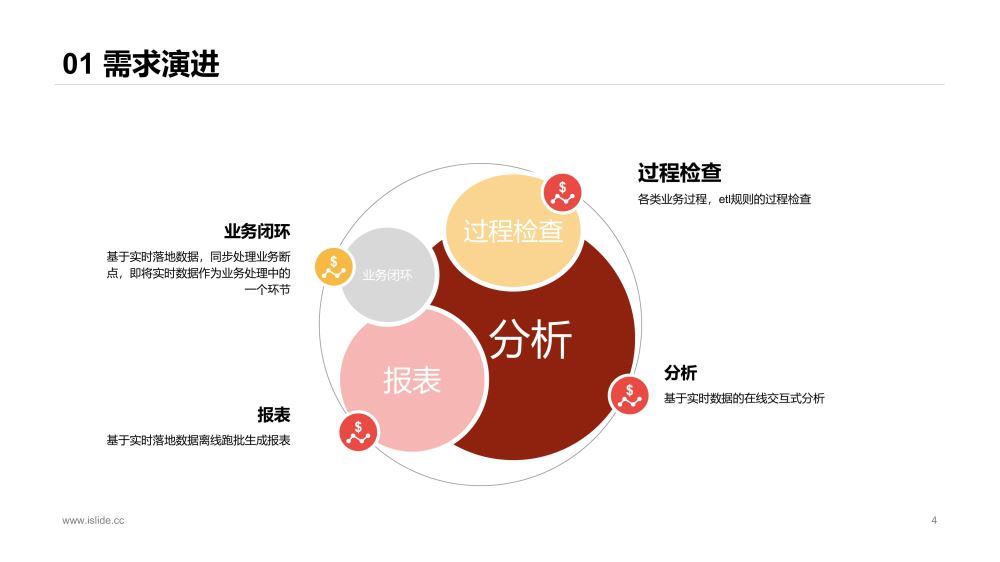
随着实时平台的稳定及推广开放,各种使用人员有了更广发的需求:
对实时开发来说,需要将实时sql数据落地做一些etl调试,数据取样等过程检查;
数据分析、业务等希望能结合数仓已有数据体系,对实时数据进行分析和洞察,比如用户行为实时埋点数据结合数仓已有一些模型进行分析,而不是仅仅看一些高度聚合化的报表;
业务希望将实时数据作为业务过程的一环进行业务驱动,实现业务闭环;
针对部分需求,需要将实时数据落地后,结合其他数仓数据,T - 1离线跑批出报表;
>
除了上述列举的主要的需求,还有一些零碎的需求。
总的来说,实时平台输出高度聚合后的数据给用户,已经满足不了需求,用户渴求更细致,更原始,更自主,更多可能的数据
而这需要平台能将实时数据落地至离线数仓体系中,因此,基于这些需求演进,实时平台开始了实时数据落地的探索实践
最早开始选型的是比较流行的Spark + Hudi体系,整体落地架构如下:
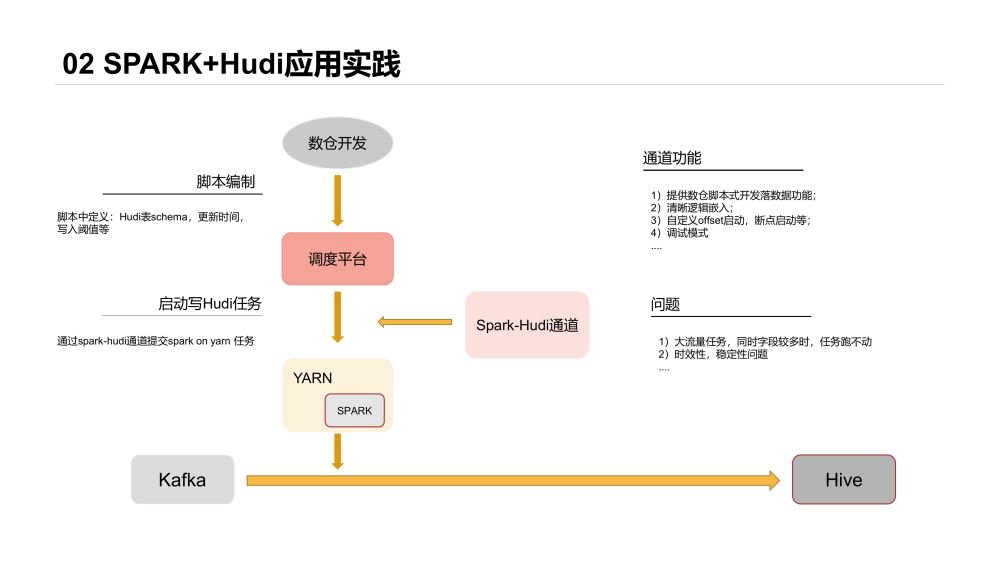
这套主要基于以下考虑:
数仓开发不需写Scala/Java打Jar包做任务开发
ETL逻辑能够嵌入落数据任务中
开发入口统一
我们当时做了通用的落数据通道,通道由Spark任务Jar包和Shell脚本组成,数仓开发入口为统一调度平台,将落数据的需求转化为对应的Shell参数,启动脚本后完成数据的落地。
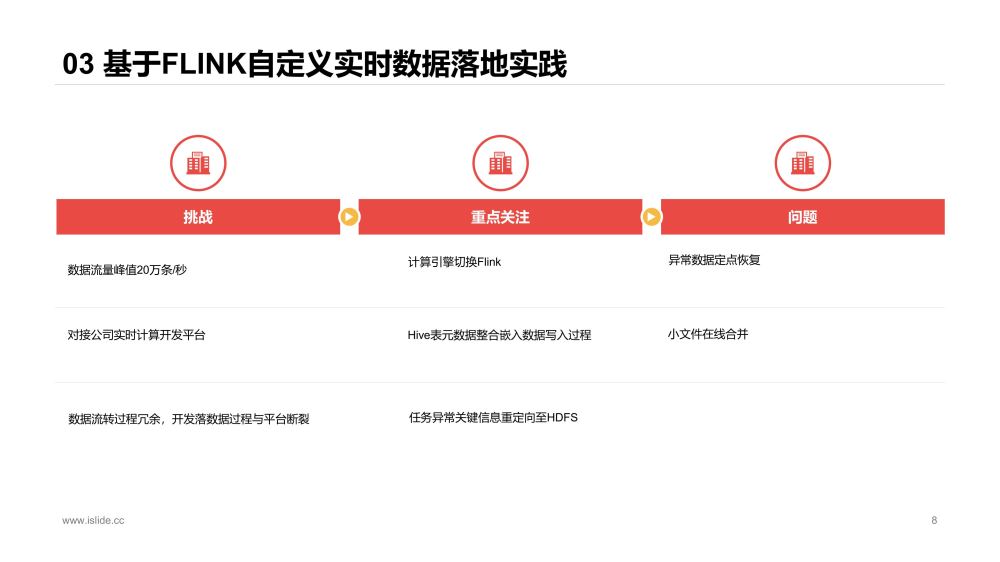
由于我们当时实时平台是基于Flink,同时Spark+Hudi对于大流量任务的支持有一些问题,比如落埋点数据时,延迟升高,任务经常OOM等,因此决定探索Flink落数据的路径。
当时Flink+Hudi社区还没有实现,我们参考Flink+ORC的落数据的过程,做了实时数据落地的实现,主要是做了落数据Schema的参数化定义,使数据开发同事能shell化实现数据落地。
Hudi整合Flink版本出来后,实时平台就着手准备做兼容,把Hudi纳入了实时平台开发内容。
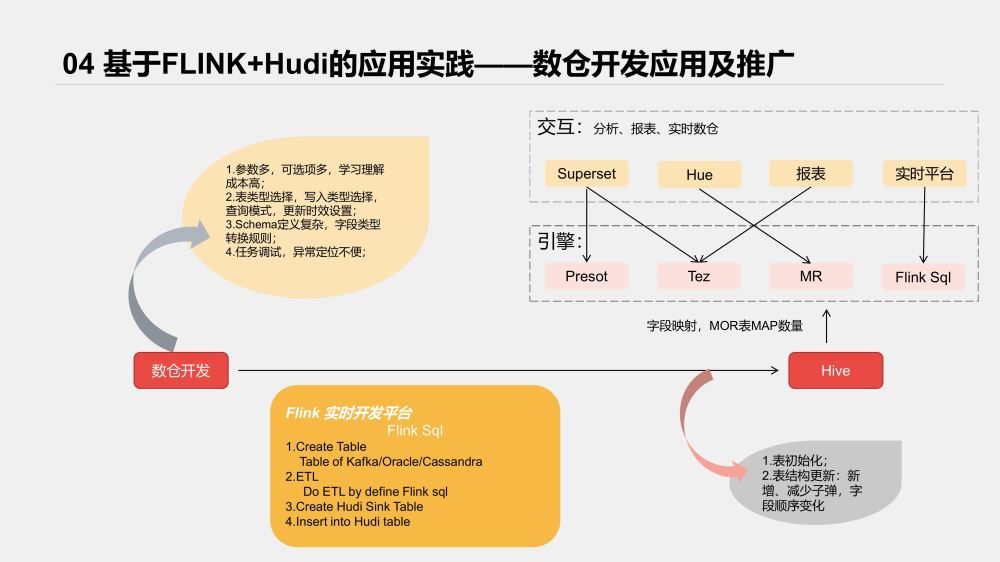
先看下接入后整体架构
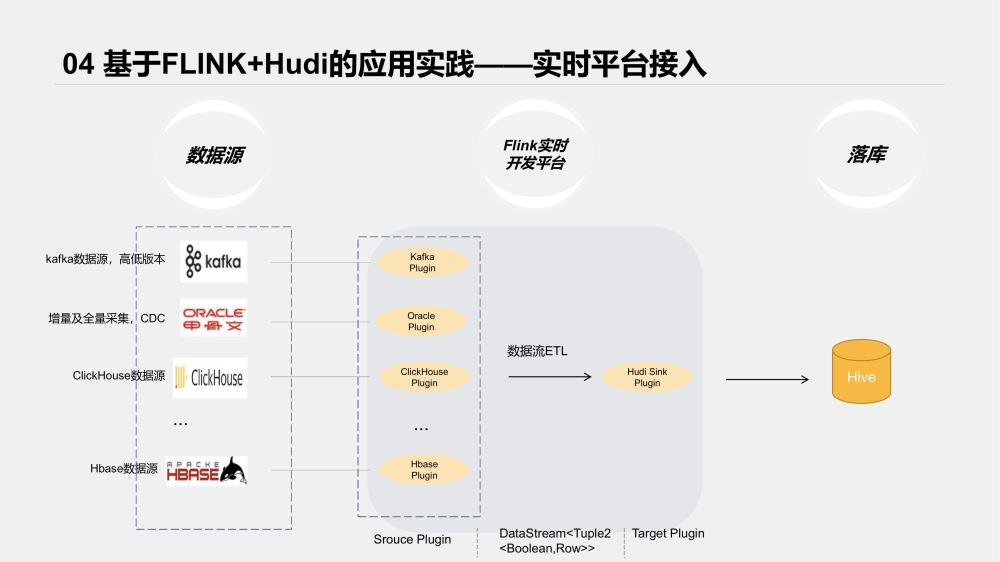
实时平台对各类数据源及Sink端都以各类插件接入,我们参考了HudiFlinkTable的Sink流程,将Hudi接入了我们的实时开发平台。
为了提高可用性,我们主要做了以下辅助功能;
Hive表元数据自动同步、更新;
Hudi schema自动拼接;
任务监控、Metrics数据接入等
实际使用过程如下
整套体系上线后,各业务线报表开发,实时在线分析等方面都有使用,比较好的赋能了业务,上线链路共26条,单日数据落入约3亿条左右
后续主要围绕如下几个方面做探索
离线报表特点是 T - 1,凌晨跑数,以及报表整体依赖链路长。两个特点导致时效性不高是一个方面,另一个方面是,数据依赖链路长的情况下,中间数据出问题容易导致后续整体依赖延时,而很多异常需要等到报表任务实际跑的时候,才能暴露出来。并且跑批问题凌晨暴露,解决的时效与资源协调都是要降低一个等级的,这对稳定性准时性要求的报表是不可接受的,特别是金融公司来说,通过把报表迁移至实时平台,不仅仅是提升了报表的时效性,由于抽数及报表etl是一直再实时跑的,报表数据给出的稳定性能有一个较大的提升。这是我们Hudi实时落数据要应用的规划之一
目前仅仅做到落数据任务的监控,即任务是否正常运行,有没有抛异常等等。但实际使用者更关心数据由上游到Hive整条链路的监控情况。比如数据是否有延迟,是否有背压,数据源消费情况,落数据是否有丢失,各个task是否有瓶颈等情况,总的来说,用户希望能更全面细致的了解到任务的运行情况,这也是后面的监控需要完善的目标
这个是和上面的监控有类似的地方,用户希望确定,一条数据从数据源接进来,经过各个算子的处理,它的一些详细情况。比如这个数据是否应该被过滤,处于哪个窗口,各个算子的处理时间等等,否则对于用户,整个数据SQL处理流程是一个黑盒。
以上是“Apache Hudi结合Flink的示例分析”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。