жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢPython+FuzzyWuzzyжҖҺд№Ҳе®һзҺ°жЁЎзіҠеҢ№й…Қзҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
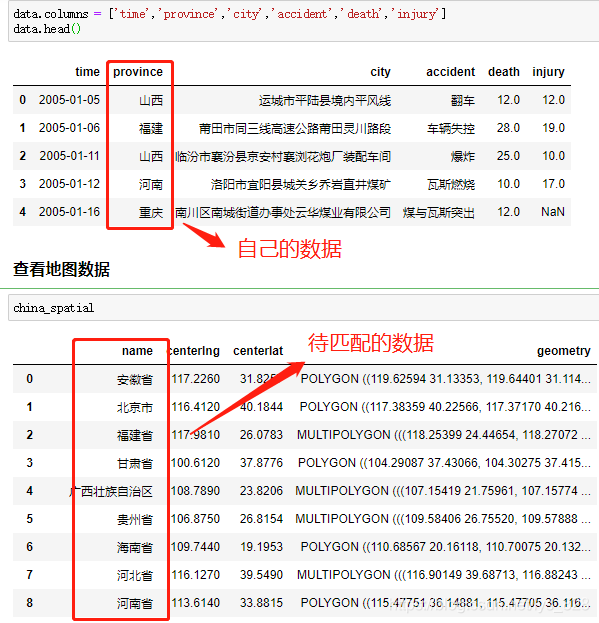
еңЁеӨ„зҗҶж•°жҚ®зҡ„иҝҮзЁӢдёӯпјҢйҡҫе…ҚдјҡйҒҮеҲ°дёӢйқўзұ»дјјзҡ„еңәжҷҜпјҢиҮӘе·ұжүӢйҮҢеӨҙиҺ·еҫ—зҡ„жҳҜз®ҖеҢ–зүҲзҡ„ж•°жҚ®еӯ—ж®өпјҢдҪҶжҳҜиҰҒжҜ”еҜ№зҡ„жҲ–иҖ…иҰҒеҗҲ并зҡ„еҚҙжҳҜе®Ңж•ҙзүҲзҡ„ж•°жҚ®пјҲжңүж—¶еҖҷд№ҹдјҡеҸҚиҝҮжқҘпјү
жңҖеёёи§Ғзҡ„дёҖдёӘдҫӢеӯҗе°ұжҳҜпјҡеңЁиҝӣиЎҢең°зҗҶеҸҜи§ҶеҢ–дёӯпјҢиҮӘе·ұ收йӣҶзҡ„ж•°жҚ®еҸӘдҝқз•ҷзҡ„зј©еҶҷпјҢжҜ”еҰӮеҢ—дә¬пјҢе№ҝиҘҝпјҢж–°з–ҶпјҢиҘҝи—ҸзӯүпјҢдҪҶжҳҜеҫ…еҢ№й…Қзҡ„еӯ—ж®өж•°жҚ®еҚҙжҳҜеҢ—дә¬еёӮпјҢе№ҝиҘҝеЈ®ж—ҸиҮӘжІ»еҢәпјҢж–°з–Ҷз»ҙеҗҫе°”иҮӘжІ»еҢәпјҢиҘҝи—ҸиҮӘжІ»еҢәзӯүпјҢеҰӮдёӢгҖӮеӣ жӯӨе°ұйңҖиҰҒжңүжІЎжңүдёҖз§Қж–№ејҸеҸҜд»ҘеҫҲеҝ«йҖҹдҫҝжҚ·зҡ„зӣҙжҺҘиҝӣиЎҢеҜ№еә”еӯ—ж®өзҡ„еҢ№й…Қ并е°Ҷз»“жһңеҚ•зӢ¬з”ҹжҲҗдёҖеҲ—пјҢе°ұеҸҜд»Ҙз”ЁеҲ°FuzzyWuzzyеә“гҖӮ
FuzzyWuzzy жҳҜдёҖдёӘз®ҖеҚ•жҳ“з”Ёзҡ„жЁЎзіҠеӯ—з¬ҰдёІеҢ№й…Қе·Ҙе…·еҢ…гҖӮе®ғдҫқжҚ® Levenshtein Distance з®—жі•пјҢи®Ўз®—дёӨдёӘеәҸеҲ—д№Ӣй—ҙзҡ„е·®ејӮгҖӮ
Levenshtein Distanceз®—жі•пјҢеҸҲеҸ« Edit Distanceз®—жі•пјҢжҳҜжҢҮдёӨдёӘеӯ—з¬ҰдёІд№Ӣй—ҙпјҢз”ұдёҖдёӘиҪ¬жҲҗеҸҰдёҖдёӘжүҖйңҖзҡ„жңҖе°‘зј–иҫ‘ж“ҚдҪңж¬Ўж•°гҖӮи®ёеҸҜзҡ„зј–иҫ‘ж“ҚдҪңеҢ…жӢ¬е°ҶдёҖдёӘеӯ—з¬ҰжӣҝжҚўжҲҗеҸҰдёҖдёӘеӯ—з¬ҰпјҢжҸ’е…ҘдёҖдёӘеӯ—з¬ҰпјҢеҲ йҷӨдёҖдёӘеӯ—з¬ҰгҖӮдёҖиҲ¬жқҘиҜҙпјҢзј–иҫ‘и·қзҰ»и¶Ҡе°ҸпјҢдёӨдёӘдёІзҡ„зӣёдјјеәҰи¶ҠеӨ§гҖӮ
иҝҷйҮҢдҪҝз”Ёзҡ„жҳҜAnacondaдёӢзҡ„jupyter notebookзј–зЁӢзҺҜеўғпјҢеӣ жӯӨеңЁAnacondaзҡ„е‘Ҫд»ӨиЎҢдёӯиҫ“е…ҘдёҖдёӢжҢҮд»ӨиҝӣиЎҢ第дёүж–№еә“е®үиЈ…гҖӮ
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple FuzzyWuzzy
иҜҘжЁЎеқ—дёӢдё»иҰҒд»Ӣз»ҚеӣӣдёӘеҮҪж•°пјҲж–№жі•пјүпјҢеҲҶеҲ«дёәпјҡз®ҖеҚ•еҢ№й…ҚпјҲRatioпјүгҖҒйқһе®Ңе…ЁеҢ№й…ҚпјҲPartial RatioпјүгҖҒеҝҪз•ҘйЎәеәҸеҢ№й…ҚпјҲToken Sort Ratioпјүе’ҢеҺ»йҮҚеӯҗйӣҶеҢ№й…ҚпјҲToken Set Ratioпјү
жіЁж„Ҹпјҡ еҰӮжһңзӣҙжҺҘеҜје…ҘиҝҷдёӘжЁЎеқ—зҡ„иҜқпјҢзі»з»ҹдјҡжҸҗзӨәwarningпјҢеҪ“然иҝҷдёҚд»ЈиЎЁжҠҘй”ҷпјҢзЁӢеәҸдҫқж—§еҸҜд»ҘиҝҗиЎҢпјҲдҪҝз”Ёзҡ„й»ҳи®Өз®—жі•пјҢжү§иЎҢйҖҹеәҰиҫғж…ўпјүпјҢеҸҜд»ҘжҢүз…§зі»з»ҹзҡ„жҸҗзӨәе®үиЈ…python-Levenshteinеә“иҝӣиЎҢиҫ…еҠ©пјҢиҝҷжңүеҲ©дәҺжҸҗй«ҳи®Ўз®—зҡ„йҖҹеәҰгҖӮ

2.1.1 з®ҖеҚ•еҢ№й…ҚпјҲRatioпјү
з®ҖеҚ•зҡ„дәҶи§ЈдёҖдёӢе°ұиЎҢпјҢиҝҷдёӘдёҚжҖҺд№ҲзІҫзЎ®пјҢд№ҹдёҚеёёз”Ё
fuzz.ratio("жІіеҚ—зңҒ", "жІіеҚ—зңҒ")
>>> 100
>
fuzz.ratio("жІіеҚ—", "жІіеҚ—зңҒ")
>>> 802.1.2 йқһе®Ңе…ЁеҢ№й…ҚпјҲPartial Ratioпјү
е°ҪйҮҸдҪҝз”Ёйқһе®Ңе…ЁеҢ№й…ҚпјҢзІҫеәҰиҫғй«ҳ
fuzz.partial_ratio("жІіеҚ—зңҒ", "жІіеҚ—зңҒ")
>>> 100
fuzz.partial_ratio("жІіеҚ—", "жІіеҚ—зңҒ")
>>> 1002.1.3 еҝҪз•ҘйЎәеәҸеҢ№й…ҚпјҲToken Sort Ratioпјү
еҺҹзҗҶеңЁдәҺпјҡд»Ҙ з©әж ј дёәеҲҶйҡ”з¬ҰпјҢе°ҸеҶҷ еҢ–жүҖжңүеӯ—жҜҚпјҢж— и§Ҷз©әж јеӨ–зҡ„е…¶е®ғж ҮзӮ№з¬ҰеҸ·
fuzz.ratio("иҘҝи—Ҹ иҮӘжІ»еҢә", "иҮӘжІ»еҢә иҘҝи—Ҹ")
>>> 50
fuzz.ratio('I love YOU','YOU LOVE I')
>>> 30
fuzz.token_sort_ratio("иҘҝи—Ҹ иҮӘжІ»еҢә", "иҮӘжІ»еҢә иҘҝи—Ҹ")
>>> 100
fuzz.token_sort_ratio('I love YOU','YOU LOVE I')
>>> 1002.1.4 еҺ»йҮҚеӯҗйӣҶеҢ№й…ҚпјҲToken Set Ratioпјү
зӣёеҪ“дәҺжҜ”еҜ№д№ӢеүҚжңүдёҖдёӘйӣҶеҗҲеҺ»йҮҚзҡ„иҝҮзЁӢпјҢжіЁж„ҸжңҖеҗҺдёӨдёӘпјҢеҸҜзҗҶи§ЈдёәиҜҘж–№жі•жҳҜеңЁtoken_sort_ratioж–№жі•зҡ„еҹәзЎҖдёҠж·»еҠ дәҶйӣҶеҗҲеҺ»йҮҚзҡ„еҠҹиғҪпјҢдёӢйқўдёүдёӘеҢ№й…Қзҡ„йғҪжҳҜеҖ’еәҸ
fuzz.ratio("иҘҝи—Ҹ иҘҝи—Ҹ иҮӘжІ»еҢә", "иҮӘжІ»еҢә иҘҝи—Ҹ")
>>> 40
fuzz.token_sort_ratio("иҘҝи—Ҹ иҘҝи—Ҹ иҮӘжІ»еҢә", "иҮӘжІ»еҢә иҘҝи—Ҹ")
>>> 80
fuzz.token_set_ratio("иҘҝи—Ҹ иҘҝи—Ҹ иҮӘжІ»еҢә", "иҮӘжІ»еҢә иҘҝи—Ҹ")
>>> 100fuzzиҝҷеҮ дёӘratio()еҮҪж•°пјҲж–№жі•пјүжңҖеҗҺеҫ—еҲ°зҡ„з»“жһңйғҪжҳҜж•°еӯ—пјҢеҰӮжһңйңҖиҰҒиҺ·еҫ—еҢ№й…ҚеәҰжңҖй«ҳзҡ„еӯ—з¬ҰдёІз»“жһңпјҢиҝҳйңҖиҰҒдҫқж—§иҮӘе·ұзҡ„ж•°жҚ®зұ»еһӢйҖүжӢ©дёҚеҗҢзҡ„еҮҪж•°пјҢ然еҗҺеҶҚиҝӣиЎҢз»“жһңжҸҗеҸ–пјҢеҰӮжһңдҪҶзңӢж–Үжң¬ж•°жҚ®зҡ„еҢ№й…ҚзЁӢеәҰдҪҝз”Ёиҝҷз§Қж–№ејҸжҳҜеҸҜд»ҘйҮҸеҢ–зҡ„пјҢдҪҶжҳҜеҜ№дәҺжҲ‘们иҰҒжҸҗеҸ–еҢ№й…Қзҡ„з»“жһңжқҘиҜҙе°ұдёҚжҳҜеҫҲж–№дҫҝдәҶпјҢеӣ жӯӨе°ұжңүдәҶprocessжЁЎеқ—гҖӮ
з”ЁдәҺеӨ„зҗҶеӨҮйҖүзӯ”жЎҲжңүйҷҗзҡ„жғ…еҶөпјҢиҝ”еӣһжЁЎзіҠеҢ№й…Қзҡ„еӯ—з¬ҰдёІе’ҢзӣёдјјеәҰгҖӮ
2.2.1 extractжҸҗеҸ–еӨҡжқЎж•°жҚ®
зұ»дјјдәҺзҲ¬иҷ«дёӯselectпјҢиҝ”еӣһзҡ„жҳҜеҲ—иЎЁпјҢе…¶дёӯдјҡеҢ…еҗ«еҫҲеӨҡеҢ№й…Қзҡ„ж•°жҚ®
choices = ["жІіеҚ—зңҒ", "йғ‘е·һеёӮ", "ж№–еҢ—зңҒ", "жӯҰжұүеёӮ"]
process.extract("йғ‘е·һ", choices, limit=2)
>>> [('йғ‘е·һеёӮ', 90), ('жІіеҚ—зңҒ', 0)]
# extractд№ӢеҗҺзҡ„ж•°жҚ®зұ»еһӢжҳҜеҲ—иЎЁпјҢеҚідҪҝlimit=1пјҢжңҖеҗҺиҝҳжҳҜеҲ—иЎЁпјҢжіЁж„Ҹе’ҢдёӢйқўextractOneзҡ„еҢәеҲ«2.2.2 extractOneжҸҗеҸ–дёҖжқЎж•°жҚ®
еҰӮжһңиҰҒжҸҗеҸ–еҢ№й…ҚеәҰжңҖеӨ§зҡ„з»“жһңпјҢеҸҜд»ҘдҪҝз”ЁextractOneпјҢжіЁж„ҸиҝҷйҮҢиҝ”еӣһзҡ„жҳҜ е…ғз»„ зұ»еһӢпјҢ иҝҳжңүе°ұжҳҜеҢ№й…ҚеәҰжңҖеӨ§зҡ„з»“жһңдёҚдёҖе®ҡжҳҜжҲ‘们жғіиҰҒзҡ„ж•°жҚ®пјҢеҸҜд»ҘйҖҡиҝҮдёӢйқўзҡ„зӨәдҫӢе’ҢдёӨдёӘе®һжҲҳеә”з”ЁдҪ“дјҡдёҖдёӢ
process.extractOne("йғ‘е·һ", choices)
>>> ('йғ‘е·һеёӮ', 90)
process.extractOne("еҢ—дә¬", choices)
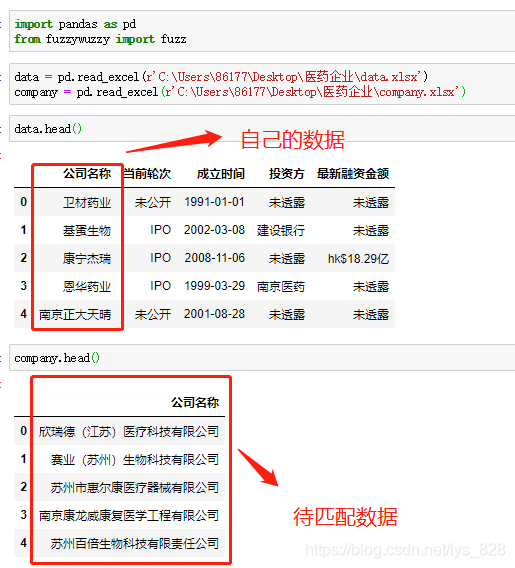
>>> ('ж№–еҢ—зңҒ', 45)иҝҷйҮҢдёҫдёӨдёӘе®һжҲҳеә”з”Ёзҡ„е°ҸдҫӢеӯҗпјҢ第дёҖдёӘжҳҜе…¬еҸёеҗҚз§°еӯ—ж®өзҡ„жЁЎзіҠеҢ№й…ҚпјҢ第дәҢдёӘжҳҜзңҒеёӮеӯ—ж®өзҡ„жЁЎзіҠеҢ№й…Қ
ж•°жҚ®еҸҠеҫ…еҢ№й…Қзҡ„ж•°жҚ®ж ·ејҸеҰӮдёӢпјҡиҮӘе·ұиҺ·еҸ–еҲ°зҡ„ж•°жҚ®еӯ—ж®өзҡ„еҗҚз§°еҫҲз®ҖжҙҒпјҢ并дёҚжҳҜе…¬еҸёзҡ„е…Ёз§°пјҢеӣ жӯӨйңҖиҰҒиҝӣиЎҢдёӨдёӘеӯ—ж®өзҡ„еҗҲ并
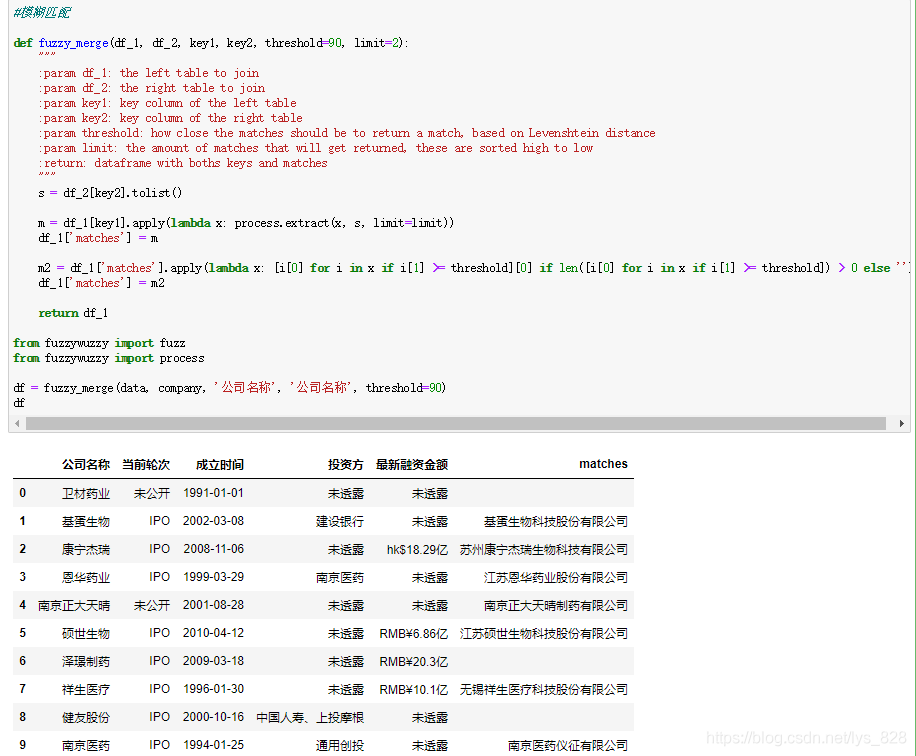
зӣҙжҺҘе°Ҷд»Јз Ғе°ҒиЈ…дёәеҮҪж•°пјҢдё»иҰҒжҳҜдёәдәҶж–№дҫҝж—ҘеҗҺзҡ„и°ғз”ЁпјҢиҝҷйҮҢеҸӮж•°и®ҫзҪ®зҡ„жҜ”иҫғиҜҰз»ҶпјҢжү§иЎҢз»“жһңеҰӮдёӢпјҡ
3.1.1 еҸӮж•°и®Іи§Јпјҡ
①第дёҖдёӘеҸӮж•°df_1жҳҜиҮӘе·ұиҺ·еҸ–зҡ„ж¬ІеҗҲ并зҡ„е·Ұдҫ§ж•°жҚ®пјҲиҝҷйҮҢжҳҜdataеҸҳйҮҸпјүпјӣ
в‘Ў 第дәҢдёӘеҸӮж•°df_2жҳҜеҫ…еҢ№й…Қзҡ„ж¬ІеҗҲ并зҡ„еҸідҫ§ж•°жҚ®пјҲиҝҷйҮҢжҳҜcompanyеҸҳйҮҸпјүпјӣ
в‘ў 第дёүдёӘеҸӮж•°key1жҳҜdf_1дёӯиҰҒеӨ„зҗҶзҡ„еӯ—ж®өеҗҚз§°пјҲиҝҷйҮҢжҳҜdataеҸҳйҮҸйҮҢзҡ„‘е…¬еҸёеҗҚз§°’еӯ—ж®өпјү
в‘Ј 第еӣӣдёӘеҸӮж•°key2жҳҜdf_2дёӯиҰҒеҢ№й…Қзҡ„еӯ—ж®өеҗҚз§°пјҲиҝҷйҮҢжҳҜcompanyеҸҳйҮҸйҮҢзҡ„‘е…¬еҸёеҗҚз§°’еӯ—ж®өпјү
в‘Ө 第дә”дёӘеҸӮж•°thresholdжҳҜи®ҫе®ҡжҸҗеҸ–з»“жһңеҢ№й…ҚеәҰзҡ„ж ҮеҮҶгҖӮжіЁж„ҸиҝҷйҮҢе°ұжҳҜеҜ№extractOneж–№жі•зҡ„е®Ңе–„пјҢжҸҗеҸ–еҲ°зҡ„жңҖеӨ§еҢ№й…ҚеәҰзҡ„з»“жһң并дёҚдёҖе®ҡжҳҜжҲ‘们йңҖиҰҒзҡ„пјҢжүҖд»ҘйңҖиҰҒи®ҫе®ҡдёҖдёӘйҳҲеҖјжқҘиҜ„еҲӨпјҢиҝҷдёӘеҖје°ұдёә90пјҢеҸӘжңүжҳҜеӨ§дәҺзӯүдәҺ90пјҢиҝҷдёӘеҢ№й…Қз»“жһңжҲ‘们жүҚеҸҜд»ҘжҺҘеҸ—
в‘Ҙ 第е…ӯдёӘеҸӮж•°пјҢй»ҳи®ӨеҸӮж•°е°ұжҳҜеҸӘиҝ”еӣһдёӨдёӘеҢ№й…ҚжҲҗеҠҹзҡ„з»“жһң
в‘Ұ иҝ”еӣһеҖјпјҡдёәdf_1ж·»еҠ ‘matches’еӯ—ж®өеҗҺзҡ„ж–°зҡ„DataFrameж•°жҚ®
3.1.2 ж ёеҝғд»Јз Ғи®Іи§Ј
第дёҖйғЁеҲҶд»Јз ҒеҰӮдёӢпјҢеҸҜд»ҘеҸӮиҖғдёҠйқўи®Іи§Јprocess.extractж–№жі•пјҢиҝҷйҮҢе°ұжҳҜзӣҙжҺҘдҪҝз”ЁпјҢжүҖд»Ҙиҝ”еӣһзҡ„з»“жһңmе°ұжҳҜеҲ—иЎЁдёӯеөҢеҘ—е…ғзҘ–зҡ„ж•°жҚ®ж јејҸпјҢж ·ејҸдёә: [(‘йғ‘е·һеёӮ’, 90), (‘жІіеҚ—зңҒ’, 0)]пјҢеӣ жӯӨ第дёҖж¬ЎеҶҷе…ҘеҲ°’matches’еӯ—ж®өдёӯзҡ„ж•°жҚ®д№ҹе°ұжҳҜиҝҷз§Қж јејҸ
жіЁж„ҸпјҢжіЁж„Ҹпјҡ е…ғзҘ–дёӯзҡ„第дёҖдёӘжҳҜеҢ№й…ҚжҲҗеҠҹзҡ„еӯ—з¬ҰдёІпјҢ第дәҢдёӘе°ұжҳҜи®ҫзҪ®зҡ„thresholdеҸӮж•°жҜ”еҜ№зҡ„ж•°еӯ—еҜ№иұЎ
s = df_2[key2].tolist() m = df_1[key1].apply(lambda x: process.extract(x, s, limit=limit)) df_1['matches'] = m
第дәҢйғЁеҲҶзҡ„ж ёеҝғд»Јз ҒеҰӮдёӢпјҢжңүдәҶдёҠйқўзҡ„жўізҗҶпјҢжҳҺзЎ®дәҶ‘matches’еӯ—ж®өдёӯзҡ„ж•°жҚ®зұ»еһӢпјҢ然еҗҺе°ұжҳҜиҝӣиЎҢж•°жҚ®зҡ„жҸҗеҸ–дәҶпјҢйңҖиҰҒеӨ„зҗҶзҡ„йғЁеҲҶжңүдёӨзӮ№йңҖиҰҒжіЁж„Ҹзҡ„пјҡ
в‘ жҸҗеҸ–еҢ№й…ҚжҲҗеҠҹзҡ„еӯ—з¬ҰдёІпјҢ并еҜ№йҳҲеҖје°ҸдәҺ90зҡ„ж•°жҚ®еЎ«е……з©әеҖј
в‘Ў жңҖеҗҺжҠҠж•°жҚ®ж·»еҠ еҲ°‘matches’еӯ—ж®ө
m2 = df_1['matches'].apply(lambda x: [i[0] for i in x if i[1] >= threshold][0] if len([i[0] for i in x if i[1] >= threshold]) > 0 else '')
#иҰҒзҗҶ解第дёҖдёӘвҖҳmatches'еӯ—ж®өиҝ”еӣһзҡ„ж•°жҚ®зұ»еһӢжҳҜд»Җд№Ҳж ·еӯҗзҡ„пјҢе°ұдёҚйҡҫзҗҶи§ЈиҝҷиЎҢд»Јз ҒдәҶ
#еҸӮиҖғдёҖдёӢиҝҷдёӘж јејҸпјҡ[('йғ‘е·һеёӮ', 90), ('жІіеҚ—зңҒ', 0)]
df_1['matches'] = m2
return df_1иҮӘе·ұзҡ„ж•°жҚ®е’Ңеҫ…еҢ№й…Қзҡ„ж•°жҚ®иғҢжҷҜд»Ӣз»Қдёӯе·Із»ҸжңүеӣҫзүҮжҳҫзӨәдәҶпјҢдёҠйқўд№ҹе·Із»Ҹе°ҒиЈ…дәҶжЁЎзіҠеҢ№й…Қзҡ„еҮҪж•°пјҢиҝҷйҮҢзӣҙжҺҘи°ғз”ЁдёҠйқўзҡ„еҮҪж•°пјҢиҫ“е…Ҙзӣёеә”зҡ„еҸӮж•°еҚіеҸҜпјҢд»Јз Ғд»ҘеҸҠжү§иЎҢз»“жһңеҰӮдёӢпјҡ
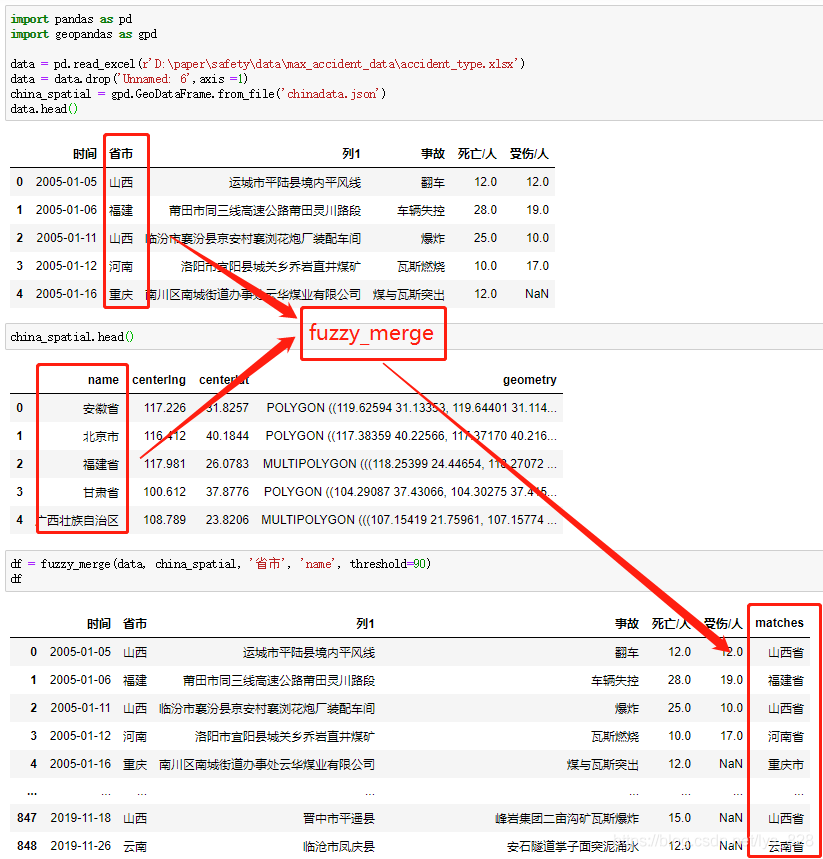
ж•°жҚ®еӨ„зҗҶе®ҢжҲҗпјҢз»ҸиҝҮе°ҒиЈ…еҗҺзҡ„еҮҪж•°еҸҜд»ҘзӣҙжҺҘж”ҫеңЁиҮӘе·ұиҮӘе®ҡд№үзҡ„жЁЎеқ—еҗҚж–Ү件дёӢйқўпјҢд»ҘеҗҺеҸҜд»Ҙж–№дҫҝзӣҙжҺҘеҜје…ҘеҮҪж•°еҗҚеҚіеҸҜпјҢеҸҜд»ҘеҸӮиҖғе°ҶиҮӘе®ҡд№үеёёз”Ёзҡ„дёҖдәӣеҮҪж•°е°ҒиЈ…жҲҗеҸҜд»ҘзӣҙжҺҘи°ғз”Ёзҡ„жЁЎеқ—ж–№жі•гҖӮ
#жЁЎзіҠеҢ№й…Қ def fuzzy_merge(df_1, df_2, key1, key2, threshold=90, limit=2): """ :param df_1: the left table to join :param df_2: the right table to join :param key1: key column of the left table :param key2: key column of the right table :param threshold: how close the matches should be to return a match, based on Levenshtein distance :param limit: the amount of matches that will get returned, these are sorted high to low :return: dataframe with boths keys and matches """ s = df_2[key2].tolist() m = df_1[key1].apply(lambda x: process.extract(x, s, limit=limit)) df_1['matches'] = m m2 = df_1['matches'].apply(lambda x: [i[0] for i in x if i[1] >= threshold][0] if len([i[0] for i in x if i[1] >= threshold]) > 0 else '') df_1['matches'] = m2 return df_1 from fuzzywuzzy import fuzz from fuzzywuzzy import process df = fuzzy_merge(data, company, 'е…¬еҸёеҗҚз§°', 'е…¬еҸёеҗҚз§°', threshold=90) df
д»ҘдёҠе°ұжҳҜвҖңPython+FuzzyWuzzyжҖҺд№Ҳе®һзҺ°жЁЎзіҠеҢ№й…ҚвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ