жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңPythonжҖҺд№Ҳе®һзҺ°WordиҪ¬PDFвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңPythonжҖҺд№Ҳе®һзҺ°WordиҪ¬PDFвҖқеҗ§пјҒ
pdfkit еҢ…зҡ„е®үиЈ…пјҡ
pip install pdfkit
дҫқиө–е·Ҙе…·пјҡ
дёӢиҪҪз¬ҰеҗҲдёҺиҮӘе·ұеҪ“еүҚзі»з»ҹзҡ„е®үиЈ…еҢ…е®үиЈ…е®ҢжҲҗд№ӢеҗҺе°ұеҸҜд»ҘиҫҫеҲ°е…је®№зҡ„ж•ҲжһңдәҶгҖӮ
html иҪ¬ pdf ж–№жі•пјҡ
pdfkit.from_file(htmlж–Ү件, дҝқеӯҳи·Ҝеҫ„) еҲ©з”Ё pdfkit.from_file() еҮҪж•°дј е…Ҙ "html" ж–Ү件дёҺ pdf зҡ„дҝқеӯҳи·Ҝеҫ„
д»Јз ҒзӨәдҫӢеҰӮдёӢпјҡ
# coding:utf-8
import pdfkit # йңҖе®үиЈ… pdfkit 第дёүж–№еҢ… "pip install pdfkit" д»ҘеҸҠ第дёүж–№дҫқиө– "wkhtmltopdf"
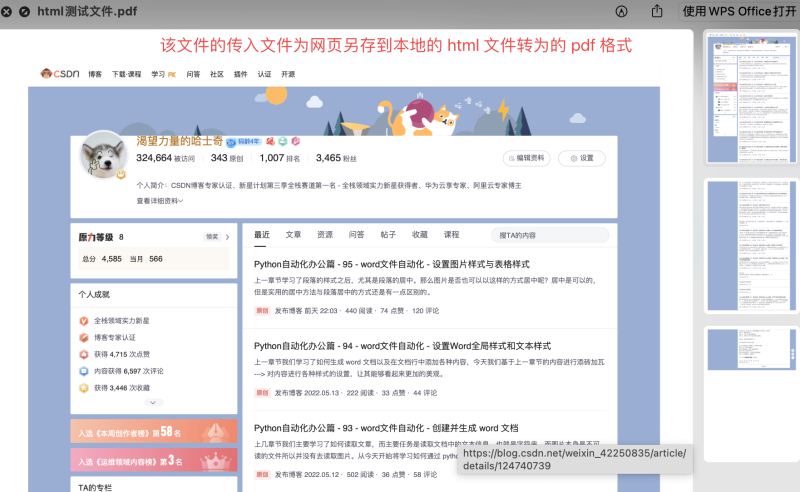
pdfkit.from_file('htmlжөӢиҜ•ж–Ү件.html', 'htmlжөӢиҜ•ж–Ү件.pdf')иҝҗиЎҢз»“жһңеҰӮдёӢпјҡ
зҪ‘еқҖ иҪ¬ pdf ж–№жі•пјҡ
pdfkit.from_url(зҪ‘еқҖ, дҝқеӯҳи·Ҝеҫ„) еҲ©з”Ё pdfkit.from_url() еҮҪж•°дј е…Ҙ "зҪ‘еқҖ" ж–Ү件дёҺ pdf зҡ„дҝқеӯҳи·Ҝеҫ„
вҖңhtmlвҖқ ж–Ү件дёҺзҪ‘еқҖзҡ„еҢәеҲ«еңЁдәҺе®һйҷ…дёҠhtmlж–Ү件жңүеҸҜиғҪжҳҜжҲ‘们жң¬ең°ејҖеҸ‘з”ҹжҲҗзҡ„пјҢд№ҹжңүеҸҜиғҪжҳҜйҖҡиҝҮ вҖңзҪ‘йЎөеҸҰеӯҳдёәвҖқ зҡ„ж–№ејҸеӯҳеӮЁеңЁжң¬ең°зҡ„гҖӮжүҖд»Ҙ зҪ‘еқҖ дёҺ htmlж–Ү件 иҝҳжҳҜжңүдёҖзӮ№зӮ№еҢәеҲ«зҡ„пјҢдҪҶжҳҜе®ғ们зҡ„жң¬иҙЁе…¶е®һжҳҜдёҖж ·зҡ„гҖӮ
д»Јз ҒзӨәдҫӢеҰӮдёӢпјҡ
# coding:utf-8
import pdfkit # йңҖе®үиЈ… pdfkit 第дёүж–№еҢ… "pip install pdfkit" д»ҘеҸҠ第дёүж–№дҫқиө– "wkhtmltopdf"
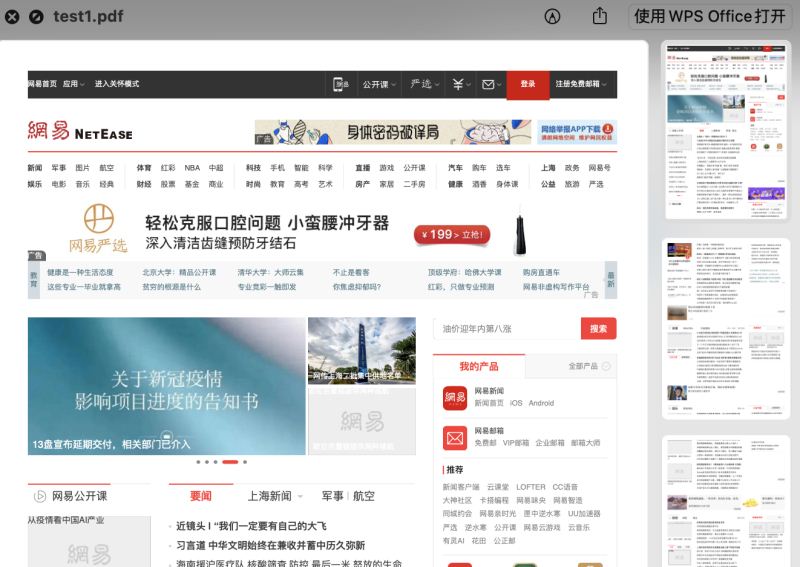
pdfkit.from_url('https://www.163.com', 'test1.pdf')иҝҗиЎҢз»“жһңеҰӮдёӢпјҡ
зҪ‘еқҖ иҪ¬ pdf ж–№жі•пјҡ
pdfkit.from_string(еҹәдәҺhtmlзҡ„еӯ—з¬ҰдёІ, дҝқеӯҳи·Ҝеҫ„) еҲ©з”Ё pdfkit.from_string() еҮҪж•°дј е…Ҙ "зҪ‘еқҖ" ж–Ү件дёҺ pdf зҡ„дҝқеӯҳи·Ҝеҫ„
еҹәдәҺhtmlзҡ„еӯ—з¬ҰдёІ е…¶е®һе°ұжҳҜеүҚз«Ҝзҡ„дёҖз§Қи¶…ж–Үжң¬ж–Үд»¶ж јејҸпјҢд»Ҙиҝҷз§ҚеүҚз«Ҝ规иҢғз”ҹжҲҗзҡ„еӯ—з¬ҰдёІе…¶е®һе°ұжҳҜ html зҡ„еӯ—з¬ҰдёІдәҶ
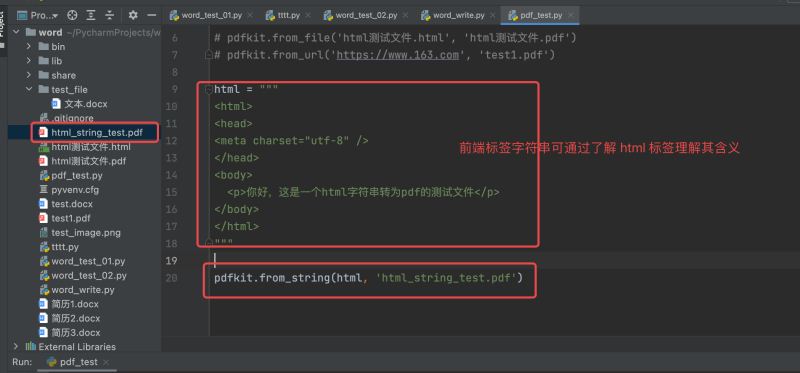
# coding:utf-8 import pdfkit # йңҖе®үиЈ… pdfkit 第дёүж–№еҢ… "pip install pdfkit" д»ҘеҸҠ第дёүж–№дҫқиө– "wkhtmltopdf" html = """ <html> <head> <meta charset="utf-8" /> </head> <body> <p>дҪ еҘҪпјҢиҝҷжҳҜдёҖдёӘhtmlеӯ—з¬ҰдёІиҪ¬дёәpdfзҡ„жөӢиҜ•ж–Ү件</p> </body> </html> """ pdfkit.from_string(html, 'html_string_test.pdf')
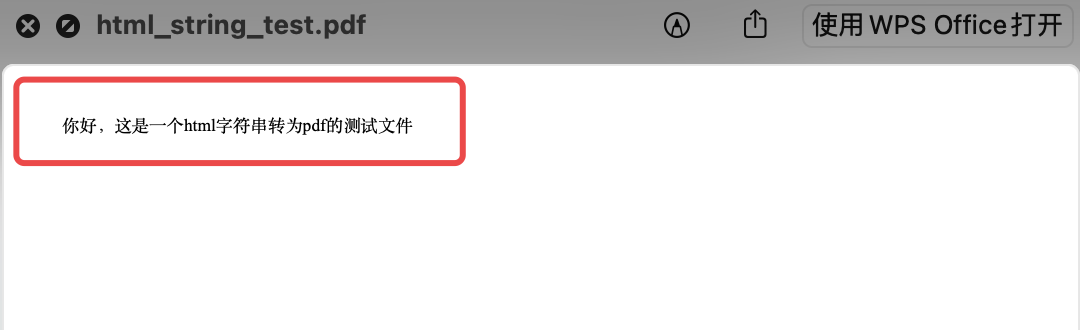
иҝҗиЎҢз»“жһңеҰӮдёӢпјҡ
йҰ–е…ҲйңҖиҰҒе®үиЈ… pydocx дҫқиө–еҢ… —> pip install pydocx
еҜје…Ҙ PyDocX еҮҪж•° —> from pydocx import PyDocX
еҲ©з”Ё PyDocX е°Ҷ word ж–Ү件иҪ¬жҚўдёә html ж јејҸпјҲдјҡз”ҹжҲҗдёҖдёӘ html зҡ„еӯ—з¬ҰдёІеҜ№иұЎпјү
е°Ҷ з”ҹжҲҗзҡ„ html еӯ—з¬ҰдёІ еҶҷе…ҘеҲ°дёҖдёӘ html ж–Ү件дёӯ
然еҗҺеҲ©з”Ё pdfkit еҢ…зҡ„ pdfkit.from_file() еҮҪж•°е°Ҷе…¶иҪ¬дёә pdf ж–Ү件
д»Јз ҒзӨәдҫӢеҰӮдёӢпјҡ
# coding:utf-8
import pdfkit # pip install pdfkit
from pydocx import PyDocX # pip install pydocx
html = PyDocX.to_html('з®ҖеҺҶ1.docx')
f = open('з®ҖеҺҶ1.html', 'w')
f.write(html)
f.close()
#pdfkit.from_file('html1.html', 'test3.pdf')
pdfkit.from_string(html, 'з®ҖеҺҶ1.pdf')иҝҗиЎҢз»“жһңеҰӮдёӢпјҡ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңPythonжҖҺд№Ҳе®һзҺ°WordиҪ¬PDFвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№PythonжҖҺд№Ҳе®һзҺ°WordиҪ¬PDFиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ