您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“PyTorch策略梯度算法怎么使用”,在日常操作中,相信很多人在PyTorch策略梯度算法怎么使用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”PyTorch策略梯度算法怎么使用”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
策略梯度算法通过记录回合中的所有时间步并基于回合结束时与这些时间步相关联的奖励来更新权重训练智能体。使智能体遍历整个回合然后基于获得的奖励更新策略的技术称为蒙特卡洛策略梯度。
在策略梯度算法中,模型权重在每个回合结束时沿梯度方向移动。关于梯度的计算,我们将在下一节中详细解释。此外,在每一时间步中,基于当前状态和权重计算的概率得到策略,并从中采样一个动作。与随机搜索和爬山算法(通过采取确定性动作以获得更高的得分)相反,它不再确定地采取动作。因此,策略从确定性转变为随机性。例如,如果向左的动作和向右的动作的概率为 [0.8,0.2],则表示有 80% 的概率选择向左的动作,但这并不意味着一定会选择向左的动作。
在本节中,我们将学习使用 PyTorch 实现策略梯度算法了。 导入所需的库,创建 CartPole 环境实例,并计算状态空间和动作空间的尺寸:
import gym
import torch
import matplotlib.pyplot as plt
env = gym.make('CartPole-v0')
n_state = env.observation_space.shape[0]
print(n_state)
n_action = env.action_space.n
print(n_action)定义 run_episode 函数,在此函数中,根据给定输入权重的情况下模拟一回合 CartPole 游戏,并返回奖励和计算出的梯度。在每个时间步中执行以下操作:
根据当前状态和输入权重计算两个动作的概率 probs
根据结果概率采样一个动作 action
以概率作为输入计算 softmax 函数的导数 d_softmax,由于只需要计算与选定动作相关的导数,因此:
\frac {\partial p_i} {\partial z_j} = p_i(1-p_j), i=j∂zj∂pi=pi(1−pj),i=j
将所得的导数 d_softmax 除以概率 probs,以得与策略相关的对数导数 d_log
根据链式法则计算权重的梯度 grad:
\frac {dy}{dx}=\frac{dy}{du}\cdot\frac{du}{dx}dxdy=dudy⋅dxdu
记录得到的梯度 grad
执行动作,累积奖励并更新状态
def run_episode(env, weight): state = env.reset() grads = [] total_reward = 0 is_done = False while not is_done: state = torch.from_numpy(state).float() # 根据当前状态和输入权重计算两个动作的概率 probs z = torch.matmul(state, weight) probs = torch.nn.Softmax(dim=0)(z) # 根据结果概率采样一个动作 action action = int(torch.bernoulli(probs[1]).item()) # 以概率作为输入计算 softmax 函数的导数 d_softmax d_softmax = torch.diag(probs) - probs.view(-1, 1) * probs # 计算与策略相关的对数导数d_log d_log = d_softmax[action] / probs[action] # 计算权重的梯度grad grad = state.view(-1, 1) * d_log grads.append(grad) state, reward, is_done, _ = env.step(action) total_reward += reward if is_done: break return total_reward, grads
回合完成后,返回在此回合中获得的总奖励以及在各个时间步中计算的梯度信息,用于之后更新权重。
接下来,定义要运行的回合数,在每个回合中调用 run_episode 函数,并初始化权重以及用于记录每个回合总奖励的变量:
n_episode = 1000 weight = torch.rand(n_state, n_action) total_rewards = []
在每个回合结束后,使用计算出的梯度来更新权重。对于回合中的每个时间步,权重都根据学习率、计算出的梯度和智能体在剩余时间步中的获得的总奖励进行更新。
我们知道在回合终止之前,每一时间步的奖励都是 1。因此,我们用于计算每个时间步策略梯度的未来奖励是剩余的时间步数。在每个回合之后,我们使用随机梯度上升方法将梯度乘以未来奖励来更新权重。这样,一个回合中经历的时间步越长,权重的更新幅度就越大,这将增加获得更大总奖励的机会。我们设定学习率为 0.001:
learning_rate = 0.001
for e in range(n_episode):
total_reward, gradients = run_episode(env, weight)
print('Episode {}: {}'.format(e + 1, total_reward))
for i, gradient in enumerate(gradients):
weight += learning_rate * gradient * (total_reward - i)
total_rewards.append(total_reward)然后,我们计算通过策略梯度算法获得的平均总奖励:
print('Average total reward over {} episode: {}'.format(n_episode, sum(total_rewards)/n_episode))我们可以绘制每个回合的总奖励变化情况,如下所示:
plt.plot(total_rewards)
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.show()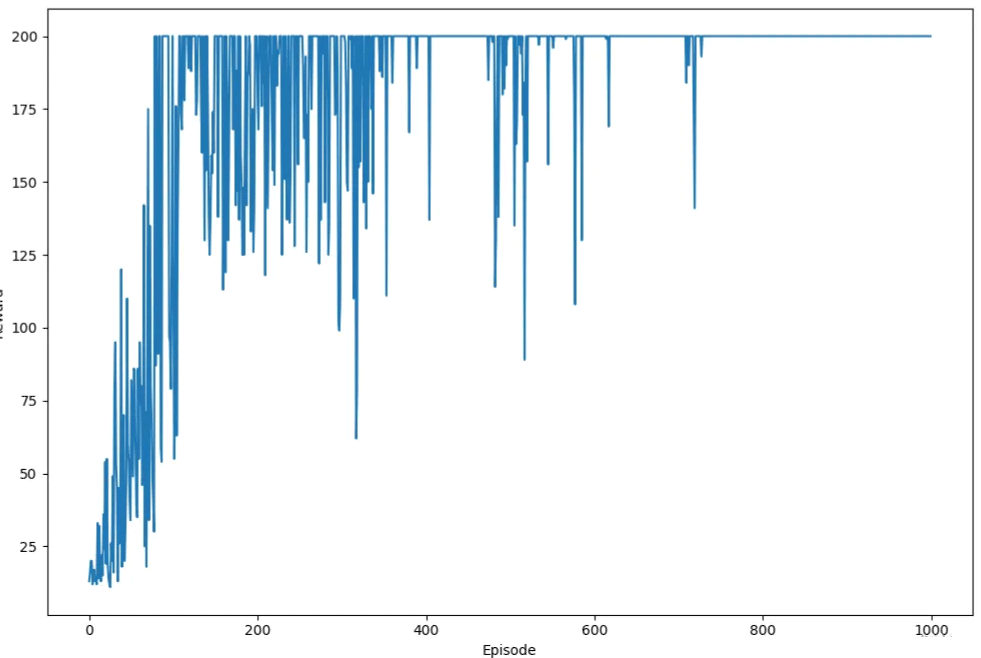
在上图中,我们可以看到奖励会随着训练回合的增加呈现出上升趋势,然后能够在最大值处稳定。我们还可以看到,即使在收敛之后,奖励也会振荡,这是由于策略梯度算法是一种随机策略算法。
最后,我们查看学习到策略在 1000 个新回合中的性能表现,并计算平均奖励:
n_episode_eval = 1000
total_rewards_eval = []
for e in range(n_episode_eval):
total_reward, _ = run_episode(env, weight)
print('Episode {}: {}'.format(e+1, total_reward))
total_rewards_eval.append(total_reward)
print('Average total reward over {} episode: {}'.format(n_episode_eval, sum(total_rewards_eval)/n_episode_eval))
# Average total reward over 1000 episode: 200进行测试后,可以看到回合的平均奖励接近最大值 200。可以多次测试训练后的模型,得到的平均奖励较为稳定。正如我们一开始所说的那样,对于诸如 CartPole 之类的简单环境,策略梯度算法可能大材小用,但它为我们解决更加复杂的问题奠定了基础。
到此,关于“PyTorch策略梯度算法怎么使用”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。