您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文小编为大家详细介绍“Python Numpy中ndarray的常见操作实例分析”,内容详细,步骤清晰,细节处理妥当,希望这篇“Python Numpy中ndarray的常见操作实例分析”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
NumPy(Numerical Python)是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
Numpy中主要使用ndarray来处理N维数组,Numpy中的大部分属性和方法都是为ndarray服务的,所以掌握Numpy中ndarray的常见操作非常有必要!
NumPy的主要对象是同构多维数组。它是一个元素表(通常是数字),所有类型都相同,由非负整数元组索引。在NumPy维度中称为轴 。
下面所示的例子中,数组有2个轴。第一轴的长度为2,第二轴的长度为3。
[[ 1., 0., 0.], [ 0., 1., 2.]]
ndarray.ndim : 数组的轴(维度)的个数。在Python世界中,维度的数量被称为rank。
ndarray.shape :数组的维度。这是一个整数的元组,表示每个维度中数组的大小。对于有 n 行和 m 列的矩阵,shape 将是 (n,m)。因此,shape 元组的长度就是rank或维度的个数 ndim。
ndarray.size :数组元素的总数。这等于 shape 的元素的乘积。
ndarray.dtype :一个描述数组中元素类型的对象。可以使用标准的Python类型创建或指定dtype。另外NumPy提供它自己的类型。例如numpy.int32、numpy.int16和numpy.float64。
ndarray.itemsize :数组中每个元素的字节大小。例如,元素为 float64 类型的数组的 itemsize 为8(=64/8),而 complex32 类型的数组的 itemsize 为4(=32/8)。它等于 ndarray.dtype.itemsize 。
>>> import numpy as np >>> a = np.arange(15).reshape(3, 5) >>> a array([[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14]]) >>> a.shape (3, 5) >>> a.ndim 2 >>> a.dtype.name 'int64' >>> a.itemsize 8 >>> a.size 15 >>> type(a) <type 'numpy.ndarray'> >>> b = np.array([6, 7, 8]) >>> b array([6, 7, 8]) >>> type(b) <type 'numpy.ndarray'>
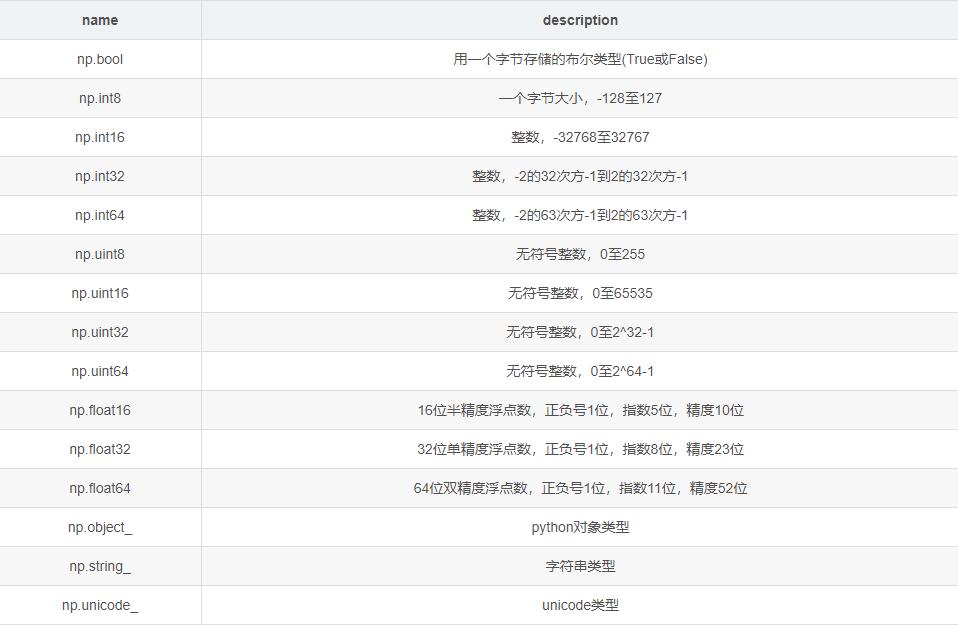
在同一个ndarray中,存储的是同一类型的数据,ndarray常见的数据类型包括:
## ndarray reshape操作 array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.shape) array_a_1 = array_a.reshape((3, 2)) print(array_a_1, array_a_1.shape) # note: reshape不能改变ndarray中元素的个数,例如reshape之前为(2,3),reshape之后为(3,2)/(1,6)... ## ndarray转置 array_a_2 = array_a.T print(array_a_2, array_a_2.shape) ## ndarray ravel操作:将ndarray展平 a.ravel() # returns the array, flattened array([ 1, 2, 3, 4, 5, 6 ]) 输出: [[1 2 3] [4 5 6]] (2, 3) [[1 2] [3 4] [5 6]] (3, 2) [[1 4] [2 5] [3 6]] (3, 2)
astype(dtype[, order, casting, subok, copy]):修改ndarray中的数据类型。传入需要修改的数据类型,其他关键字参数可以不关注。
array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.dtype) array_a_1 = array_a.astype(np.int64) print(array_a_1, array_a_1.dtype) 输出: [[1 2 3] [4 5 6]] int32 [[1 2 3] [4 5 6]] int64
NumPy主要通过np.array()函数来创建ndarray数组。
>>> import numpy as np
>>> a = np.array([2,3,4])
>>> a
array([2, 3, 4])
>>> a.dtype
dtype('int64')
>>> b = np.array([1.2, 3.5, 5.1])
>>> b.dtype
dtype('float64')也可以在创建时显式指定数组的类型:
>>> c = np.array( [ [1,2], [3,4] ], dtype=complex ) >>> c array([[ 1.+0.j, 2.+0.j], [ 3.+0.j, 4.+0.j]])
也可以通过使用np.random.random函数来创建随机的ndarray数组。
>>> a = np.random.random((2,3)) >>> a array([[ 0.18626021, 0.34556073, 0.39676747], [ 0.53881673, 0.41919451, 0.6852195 ]])
通常,数组的元素最初是未知的,但它的大小是已知的。因此,NumPy提供了几个函数来创建具有初始占位符内容的数组。这就减少了数组增长的必要,因为数组增长的操作花费很大。
函数zeros创建一个由0组成的数组,函数 ones创建一个完整的数组,函数empty 创建一个数组,其初始内容是随机的,取决于内存的状态。默认情况下,创建的数组的dtype是 float64 类型的。
>>> np.zeros( (3,4) ) array([[ 0., 0., 0., 0.], [ 0., 0., 0., 0.], [ 0., 0., 0., 0.]]) >>> np.ones( (2,3,4), dtype=np.int16 ) # dtype can also be specified array([[[ 1, 1, 1, 1], [ 1, 1, 1, 1], [ 1, 1, 1, 1]], [[ 1, 1, 1, 1], [ 1, 1, 1, 1], [ 1, 1, 1, 1]]], dtype=int16) >>> np.empty( (2,3) ) # uninitialized, output may vary array([[ 3.73603959e-262, 6.02658058e-154, 6.55490914e-260], [ 5.30498948e-313, 3.14673309e-307, 1.00000000e+000]])
为了创建数字组成的数组,NumPy提供了一个类似于range的函数,该函数返回数组而不是列表。
>>> np.arange( 10, 30, 5 ) array([10, 15, 20, 25]) >>> np.arange( 0, 2, 0.3 ) # it accepts float arguments array([ 0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])
与许多矩阵语言不同,乘积运算符*在NumPy数组中按元素进行运算。矩阵乘积可以使用@运算符(在python> = 3.5中)或dot函数或方法执行:
>>> A = np.array( [[1,1], ... [0,1]] ) >>> B = np.array( [[2,0], ... [3,4]] ) >>> A * B # elementwise product array([[2, 0], [0, 4]]) >>> A @ B # matrix product array([[5, 4], [3, 4]]) >>> A.dot(B) # another matrix product array([[5, 4], [3, 4]])
某些操作(例如+=和 *=)会更直接更改被操作的矩阵数组而不会创建新矩阵数组。
>>> a = np.ones((2,3), dtype=int)
>>> b = np.random.random((2,3))
>>> a *= 3
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> b += a
>>> b
array([[ 3.417022 , 3.72032449, 3.00011437],
[ 3.30233257, 3.14675589, 3.09233859]])
>>> a += b # b is not automatically converted to integer type
Traceback (most recent call last):
...
TypeError: Cannot cast ufunc add output from dtype('float64') to dtype('int64') with casting rule 'same_kind'当使用不同类型的数组进行操作时,结果数组的类型对应于更一般或更精确的数组(称为向上转换的行为)。
>>> a = np.ones(3, dtype=np.int32) >>> b = np.linspace(0,pi,3) >>> b.dtype.name 'float64' >>> c = a+b >>> c array([ 1. , 2.57079633, 4.14159265]) >>> c.dtype.name 'float64' >>> d = np.exp(c*1j) >>> d array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j, -0.54030231-0.84147098j]) >>> d.dtype.name 'complex128'
许多一元操作,例如计算数组中所有元素的总和,都是作为ndarray类的方法实现的。
>>> a = np.random.random((2,3)) >>> a array([[ 0.18626021, 0.34556073, 0.39676747], [ 0.53881673, 0.41919451, 0.6852195 ]]) >>> a.sum() 2.5718191614547998 >>> a.min() 0.1862602113776709 >>> a.max() 0.6852195003967595
默认情况下,这些操作适用于数组,就像它是一个数字列表一样,无论其形状如何。但是,通过指定axis 参数,您可以沿数组的指定轴应用操作:
>>> b = np.arange(12).reshape(3,4) >>> b array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) >>> >>> b.sum(axis=0) # 计算每一列的和 array([12, 15, 18, 21]) >>> >>> b.min(axis=1) # 计算每一行的和 array([0, 4, 8]) >>> >>> b.cumsum(axis=1) # cumulative sum along each row array([[ 0, 1, 3, 6], [ 4, 9, 15, 22], [ 8, 17, 27, 38]]) 解释:以第一行为例,0=0,1=1+0,3=2+1+0,6=3+2+1+0
一维的数组可以进行索引、切片和迭代操作的,就像列表和其他Python序列类型一样。
>>> a = np.arange(10)**3 >>> a array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729]) >>> a[2] 8 >>> a[2:5] array([ 8, 27, 64]) >>> a[:6:2] = -1000 # 等价于 a[0:6:2] = -1000; 从0到6的位置, 每隔一个设置为-1000 >>> a array([-1000, 1, -1000, 27, -1000, 125, fan 216, 343, 512, 729]) >>> a[ : :-1] # 将a反转 array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000])
多维的数组每个轴可以有一个索引。这些索引以逗号分隔的元组给出:
>>> b array([[ 0, 1, 2, 3], [10, 11, 12, 13], [20, 21, 22, 23], [30, 31, 32, 33], [40, 41, 42, 43]]) >>> b[2,3] 23 >>> b[0:5, 1] # each row in the second column of b array([ 1, 11, 21, 31, 41]) >>> b[ : ,1] # equivalent to the previous example array([ 1, 11, 21, 31, 41]) >>> b[1:3, : ] # each column in the second and third row of b array([[10, 11, 12, 13], [20, 21, 22, 23]]) >>> b[-1] # the last row. Equivalent to b[-1,:] array([40, 41, 42, 43])
几个数组可以沿不同的轴堆叠在一起,例如:np.vstack()函数和np.hstack()函数
>>> a = np.floor(10*np.random.random((2,2))) >>> a array([[ 8., 8.], [ 0., 0.]]) >>> b = np.floor(10*np.random.random((2,2))) >>> b array([[ 1., 8.], [ 0., 4.]]) >>> np.vstack((a,b)) array([[ 8., 8.], [ 0., 0.], [ 1., 8.], [ 0., 4.]]) >>> np.hstack((a,b)) array([[ 8., 8., 1., 8.], [ 0., 0., 0., 4.]])
column_stack()函数将1D数组作为列堆叠到2D数组中。
>>> from numpy import newaxis >>> a = np.array([4.,2.]) >>> b = np.array([3.,8.]) >>> np.column_stack((a,b)) # returns a 2D array array([[ 4., 3.], [ 2., 8.]]) >>> np.hstack((a,b)) # the result is different array([ 4., 2., 3., 8.]) >>> a[:,newaxis] # this allows to have a 2D columns vector array([[ 4.], [ 2.]]) >>> np.column_stack((a[:,newaxis],b[:,newaxis])) array([[ 4., 3.], [ 2., 8.]]) >>> np.hstack((a[:,newaxis],b[:,newaxis])) # the result is the same array([[ 4., 3.], [ 2., 8.]])
使用hsplit(),可以沿数组的水平轴拆分数组,方法是指定要返回的形状相等的数组的数量,或者指定应该在其之后进行分割的列:
同理,使用vsplit(),可以沿数组的垂直轴拆分数组,方法同上。
################### np.hsplit ################### >>> a = np.floor(10*np.random.random((2,12))) >>> a array([[ 9., 5., 6., 3., 6., 8., 0., 7., 9., 7., 2., 7.], [ 1., 4., 9., 2., 2., 1., 0., 6., 2., 2., 4., 0.]]) >>> np.hsplit(a,3) # Split a into 3 [array([[ 9., 5., 6., 3.], [ 1., 4., 9., 2.]]), array([[ 6., 8., 0., 7.], [ 2., 1., 0., 6.]]), array([[ 9., 7., 2., 7.], [ 2., 2., 4., 0.]])] >>> np.hsplit(a,(3,4)) # Split a after the third and the fourth column [array([[ 9., 5., 6.], [ 1., 4., 9.]]), array([[ 3.], [ 2.]]), array([[ 6., 8., 0., 7., 9., 7., 2., 7.], [ 2., 1., 0., 6., 2., 2., 4., 0.]])] >>> x = np.arange(8.0).reshape(2, 2, 2) >>> x array([[[0., 1.], [2., 3.]], [[4., 5.], [6., 7.]]]) ################### np.vsplit ################### >>> np.vsplit(x, 2) [array([[[0., 1.], [2., 3.]]]), array([[[4., 5.], [6., 7.]]])]
读到这里,这篇“Python Numpy中ndarray的常见操作实例分析”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。