жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮвҖңMySQLжҹҘиҜўжҖ§иғҪдјҳеҢ–зҡ„зҙўеј•жҪңж°ҙе®һдҫӢеҲҶжһҗвҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңMySQLжҹҘиҜўжҖ§иғҪдјҳеҢ–зҡ„зҙўеј•жҪңж°ҙе®һдҫӢеҲҶжһҗвҖқж–Үз« еҗ§гҖӮ
е…ҲиҰҒд»ҺдёҖ件жҖӘдәӢиҜҙиө·пјҡ
жҲ‘е…ҲйҖ зӮ№ж•°жҚ®еӨҚзҺ°дёҖдёӢй—®йўҳпјҢеҲӣе»әдёҖеј з”ЁжҲ·иЎЁпјҡ
CREATE TABLE `user` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'дё»й”®ID', `name` varchar(100) NOT NULL DEFAULT '' COMMENT '姓еҗҚ', `age` int(11) NOT NULL DEFAULT 0 COMMENT 'е№ҙйҫ„', PRIMARY KEY (`id`), KEY `idx_age` (`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
йҖҡиҝҮдёҖжү№з”ЁжҲ·е№ҙйҫ„пјҢжҹҘиҜўиҜҘе№ҙйҫ„зҡ„з”ЁжҲ·дҝЎжҒҜпјҢ并жҹҘзңӢдёҖдёӢSQLжү§иЎҢи®ЎеҲ’пјҡ
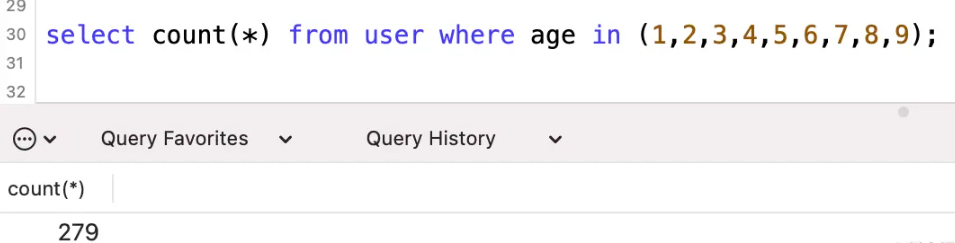
explain select * from user where age in (1,2,3,4,5,6,7,8,9);

whereжқЎд»¶дёӯжңү9дёӘеҸӮж•°пјҢйҮҚзӮ№е…іжіЁдёҖдёӢжү§иЎҢи®ЎеҲ’дёӯзҡ„йў„дј°жү«жҸҸиЎҢж•°дёә279иЎҢгҖӮ
еҲ°иҝҷйҮҢжІЎд»Җд№Ҳй—®йўҳпјҢйў„дј°зҡ„йқһеёёеҮҶпјҢе®һйҷ…е°ұжҳҜ279иЎҢгҖӮ
дҪҶжҳҜпјҢй—®йўҳжқҘдәҶпјҢеҪ“жҲ‘们еңЁwhereжқЎд»¶дёӯпјҢеҶҚеҠ дёҖдёӘеҸӮж•°пјҢеҸҳжҲҗдәҶ10дёӘеҸӮж•°пјҢйў„дј°жү«жҸҸиЎҢж•°жң¬еә”иҜҘеўһеҠ пјҢз»“жһңеҚҙеӨ§еӨ§еҮҸе°‘дәҶгҖӮ
explain select * from user where age in (1,2,3,4,5,6,7,8,9,10);

дёҖдёӢеӯҗеҮҸе°‘еҲ°дәҶ30иЎҢпјҢеҸҜжҳҜе®һйҷ…иЎҢж•°жҳҜеӨҡе°‘е‘ўпјҹ

е®һйҷ…жҳҜ310иЎҢпјҢйў„дј°жү«жҸҸиЎҢж•°жҳҜ30иЎҢпјҢзңҹжҳҜй”ҷеҲ°е§Ҙе§Ҙ家дәҶгҖӮ
MySQLе’ӢеӣһдәӢе•ҠпјҢеҲ°еә•иҝҳиғҪдёҚиғҪйў„дј°пјҹ
дёҚиғҪйў„дј°зҡ„иҜқпјҢжҚўе…¶д»–дәәпјҒ
еӨ§е®¶иӮҜе®ҡд№ҹжҳҜж»Ўи„ёз–‘жғ‘пјҢзӣҙеҲ°жҲ‘еҺ»е®ҳзҪ‘дёҠзңӢеҲ°дәҶдёҖдёӘиҜҚиҜӯпјҢзҙўеј•жҪңж°ҙпјҲIndex diveпјү гҖӮ
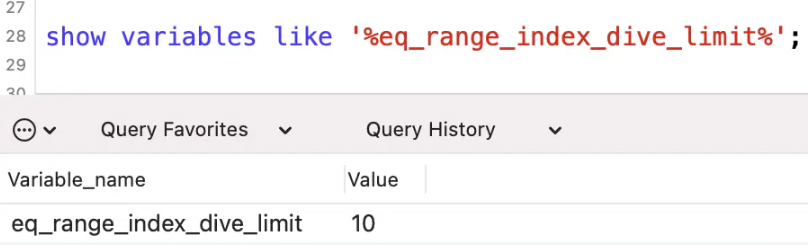
и·ҹиҝҷдёӘиҜҚиҜӯзӣёе…ізҡ„пјҢиҝҳжңүдёҖдёӘй…ҚзҪ®еҸӮж•° eq_range_index_dive_limitгҖӮ
MySQL5.7.3д№ӢеүҚзҡ„зүҲжң¬пјҢиҝҷдёӘеҖјй»ҳи®ӨжҳҜ10пјҢд№ӢеҗҺзҡ„зүҲжң¬пјҢиҝҷдёӘеҖјй»ҳи®ӨжҳҜ200гҖӮ
еҸҜд»ҘдҪҝз”Ёе‘Ҫд»ӨжҹҘзңӢдёҖдёӢиҝҷдёӘеҖјзҡ„еӨ§е°Ҹпјҡ
show variables like '%eq_range_index_dive_limit%';
еҪ“然пјҢжҲ‘们д№ҹеҸҜд»ҘжүӢеҠЁдҝ®ж”№иҝҷдёӘеҖјзҡ„еӨ§е°Ҹпјҡ
set eq_range_index_dive_limit=200;
иҝҷдёӘ eq_range_index_dive_limit й…ҚзҪ®зҡ„дҪңз”Ёе°ұжҳҜпјҡ
еҪ“whereиҜӯеҸҘinжқЎд»¶дёӯеҸӮж•°дёӘж•°е°ҸдәҺиҝҷдёӘеҖјзҡ„ж—¶еҖҷпјҢMySQLе°ұйҮҮз”Ёзҙўеј•жҪңж°ҙпјҲIndex diveпјү зҡ„ж–№ејҸйў„дј°жү«жҸҸиЎҢж•°пјҢйқһеёёеҮҶзЎ®гҖӮ
еҪ“whereиҜӯеҸҘinжқЎд»¶дёӯеҸӮж•°дёӘж•°еӨ§дәҺзӯүдәҺиҝҷдёӘеҖјзҡ„ж—¶еҖҷпјҢMySQLе°ұйҮҮз”ЁеҸҰдёҖз§Қж–№ејҸзҙўеј•з»ҹи®ЎпјҲIndex statisticsпјү йў„дј°жү«жҸҸиЎҢж•°пјҢиҜҜе·®иҫғеӨ§гҖӮ
MySQLдёәд»Җд№ҲиҰҒиҝҷд№ҲеҒҡе‘ўпјҹ
йғҪз”Ёзҙўеј•жҪңж°ҙпјҲIndex diveпјү зҡ„ж–№ејҸйў„дј°жү«жҸҸиЎҢж•°пјҢдёҚеҘҪеҗ—пјҹ
е…¶е®һиҝҷжҳҜеҹәдәҺжҲҗжң¬зҡ„иҖғиҷ‘пјҢзҙўеј•жҪңж°ҙдј°з®—жҲҗжң¬иҫғй«ҳпјҢйҖӮеҗҲе°Ҹж•°жҚ®йҮҸгҖӮзҙўеј•з»ҹи®Ўдј°з®—жҲҗжң¬иҫғдҪҺпјҢйҖӮеҗҲеӨ§ж•°жҚ®йҮҸгҖӮ
дёҖиҲ¬жғ…еҶөдёӢпјҢжҲ‘们зҡ„whereиҜӯеҸҘзҡ„inжқЎд»¶зҡ„еҸӮж•°дёҚдјҡеӨӘеӨҡпјҢйҖӮеҗҲдҪҝз”Ёзҙўеј•жҪңж°ҙйў„дј°жү«жҸҸиЎҢж•°гҖӮ
е»әи®®иҝҳеңЁдҪҝз”ЁMySQL5.7.3д№ӢеүҚзүҲжң¬зҡ„еҗҢеӯҰ们пјҢжүӢеҠЁдҝ®ж”№дёҖдёӢзҙўеј•жҪңж°ҙзҡ„й…ҚзҪ®еҸӮж•°пјҢж”№жҲҗеҗҲйҖӮзҡ„ж•°еҖјгҖӮ
еҰӮжһңдҪ 们项зӣ®дёӯinжқЎд»¶жңҖеӨҡжңү500дёӘеҸӮж•°пјҢе°ұжҠҠй…ҚзҪ®еҸӮж•°ж”№жҲҗ501гҖӮ
иҝҷж ·MySQLйў„дј°жү«жҸҸиЎҢж•°жӣҙеҮҶзЎ®пјҢеҸҜд»ҘйҖүжӢ©жӣҙеҗҲйҖӮзҡ„зҙўеј•гҖӮ
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңMySQLжҹҘиҜўжҖ§иғҪдјҳеҢ–зҡ„зҙўеј•жҪңж°ҙе®һдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ