жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңApache Doris Colocate JoinеҺҹзҗҶжҳҜд»Җд№ҲвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁApache Doris Colocate JoinеҺҹзҗҶжҳҜд»Җд№Ҳй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқApache Doris Colocate JoinеҺҹзҗҶжҳҜд»Җд№ҲвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
жҲ‘们йғҪзҹҘйҒ“ Join зҡ„еёёи§ҒиҝһжҺҘзұ»еһӢеҲҶдёәд»ҘдёӢеҮ з§Қпјҡ
INNER JOIN
OUTER JOIN
CROSS JOIN
SEMI JOIN
ANTI JOIN
Join зҡ„еёёи§Ғз®—жі•е®һзҺ°еҢ…еҗ«д»ҘдёӢеҮ з§Қпјҡ
Nested Loop Join
Sort Merge Join
Hash Join
еҲҶеёғејҸзі»з»ҹе®һзҺ° Join ж•°жҚ®еҲҶеёғзҡ„еёёи§Ғзӯ–з•Ҙжңүпјҡ
Shuffle Join
Broadcast Join
Colocate/Local Join
Colocate/Local Join е°ұжҳҜжҢҮеӨҡдёӘиҠӮзӮ№ Join ж—¶жІЎжңүж•°жҚ®з§»еҠЁе’ҢзҪ‘з»ңдј иҫ“пјҢжҜҸдёӘиҠӮзӮ№еҸӘеңЁжң¬ең°иҝӣиЎҢ JoinпјҢиғҪеӨҹжң¬ең°иҝӣиЎҢ Join зҡ„еүҚжҸҗжҳҜзӣёеҗҢ Join Key зҡ„ж•°жҚ®еҲҶеёғеңЁзӣёеҗҢзҡ„иҠӮзӮ№гҖӮ
зӣёжҜ” Shuffle Join е’Ң Broadcast Join,Colocate Join еңЁжҹҘиҜўж—¶жІЎжңүж•°жҚ®зҡ„зҪ‘з»ңдј иҫ“пјҢжҖ§иғҪдјҡжӣҙй«ҳгҖӮ еңЁ Doris зҡ„е…·дҪ“е®һзҺ°дёӯпјҢColocate Join зӣёжҜ” Shuffle Join еҸҜд»ҘжӢҘжңүжӣҙй«ҳзҡ„并еҸ‘зІ’еәҰпјҢд№ҹеҸҜд»Ҙжҳҫи‘—жҸҗеҚҮ Join зҡ„жҖ§иғҪпјҢиҝҷдёҖзӮ№еңЁеҗҺйқўдјҡи§ЈйҮҠгҖӮ
еҜ№дәҺ colocate tablesпјҢеңЁд»»дҪ•жғ…еҶөдёӢйғҪиҰҒдҝқиҜҒж•°жҚ®зҡ„жң¬ең°жҖ§гҖӮ е…·дҪ“еҢ…жӢ¬пјҡ
ж•°жҚ®еҜје…Ҙж—¶дҝқиҜҒж•°жҚ®жң¬ең°жҖ§
жҹҘиҜўи°ғеәҰж—¶дҝқиҜҒж•°жҚ®жң¬ең°жҖ§
ж•°жҚ® balance еҗҺдҝқиҜҒж•°жҚ®жң¬ең°жҖ§
е®һзҺ°дёӯжңҖеӨҚжқӮжҳҜ第 3 зӮ№: еӨ„зҗҶ colocate tables зҡ„ balanceгҖӮ
Colocate Group
жҲ‘们е°ҶдёҖз»„е…·дҪ“зӣёеҗҢ Colocate еұһжҖ§зҡ„ Table з§°дёә GroupпјҢдёӢеӣҫдёӯ t1 е’Ң t2 жӢҘжңүзӣёеҗҢзҡ„ Colocate GroupгҖӮ
Colocate Parent Table
жҲ‘们е°ҶеҶіе®ҡдёҖдёӘ Group ж•°жҚ®еҲҶеёғзҡ„ Table з§°дёә Parent TableпјҢдёӢеӣҫдёӯ t1 жҳҜ Colocate Parent Table.
Colocate Child Table
жҲ‘们е°ҶдёҖдёӘ Group дёӯйҷӨ Parent Table д№ӢеӨ–зҡ„ Table з§°дёә Child TableпјҢдёӢеӣҫдёӯ t2 жҳҜ Colocate Child Table.

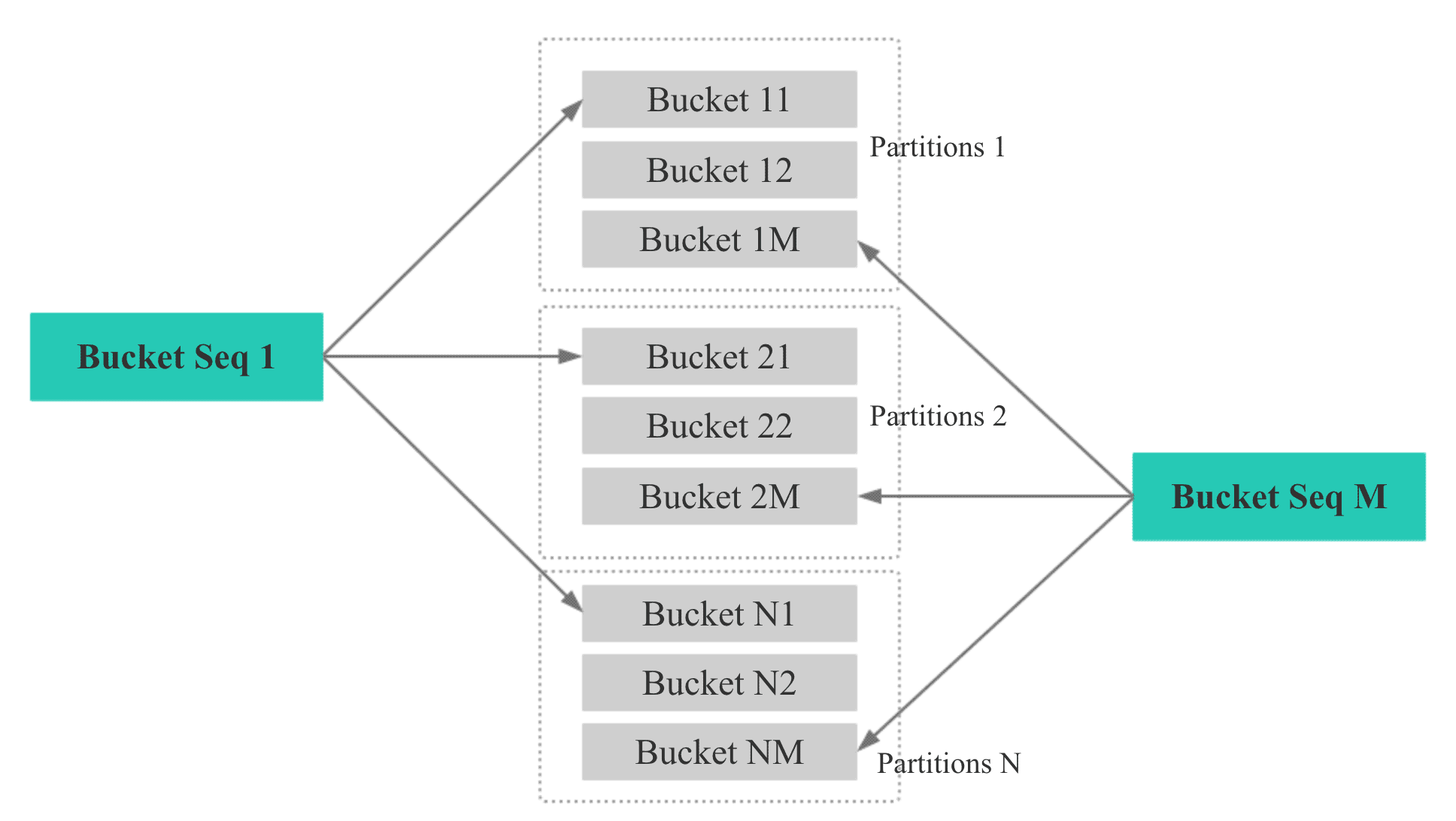
Bucket Seq
еҰӮдёӢеӣҫпјҢеҰӮжһңдёҖдёӘиЎЁжңү N дёӘ Partition, еҲҷжҜҸдёӘ Partition зҡ„第 M дёӘ bucket зҡ„ Bucket Seq жҳҜ MгҖӮ
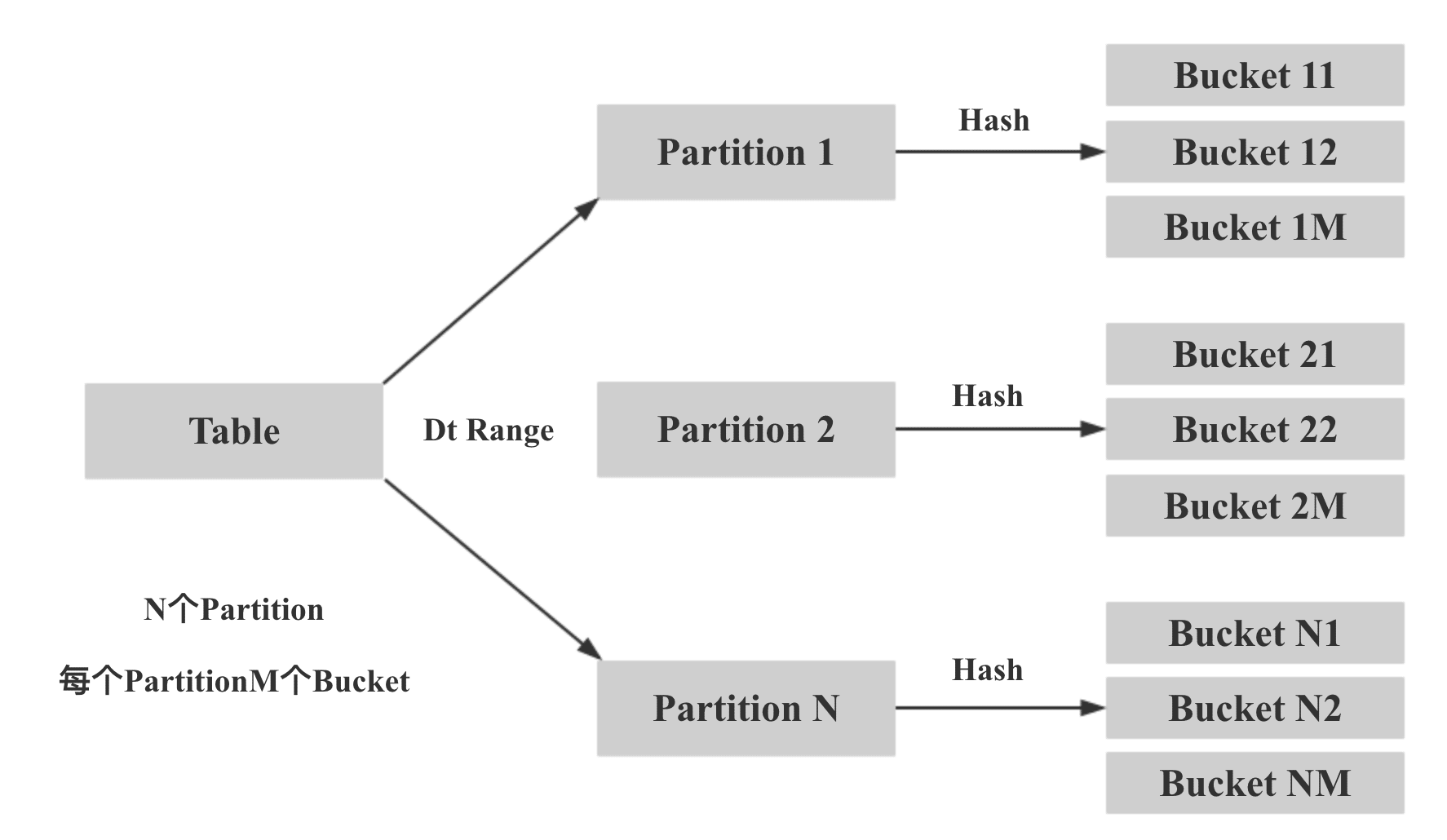
Doris зҡ„еҲҶеҢәж–№ејҸеҰӮдёӢжүҖзӨәпјҢе…Ҳж №жҚ®еҲҶеҢәеӯ—ж®ө Range еҲҶеҢәпјҢеҶҚж №жҚ®жҢҮе®ҡзҡ„ Distributed Key Hash еҲҶжЎ¶пјҡ
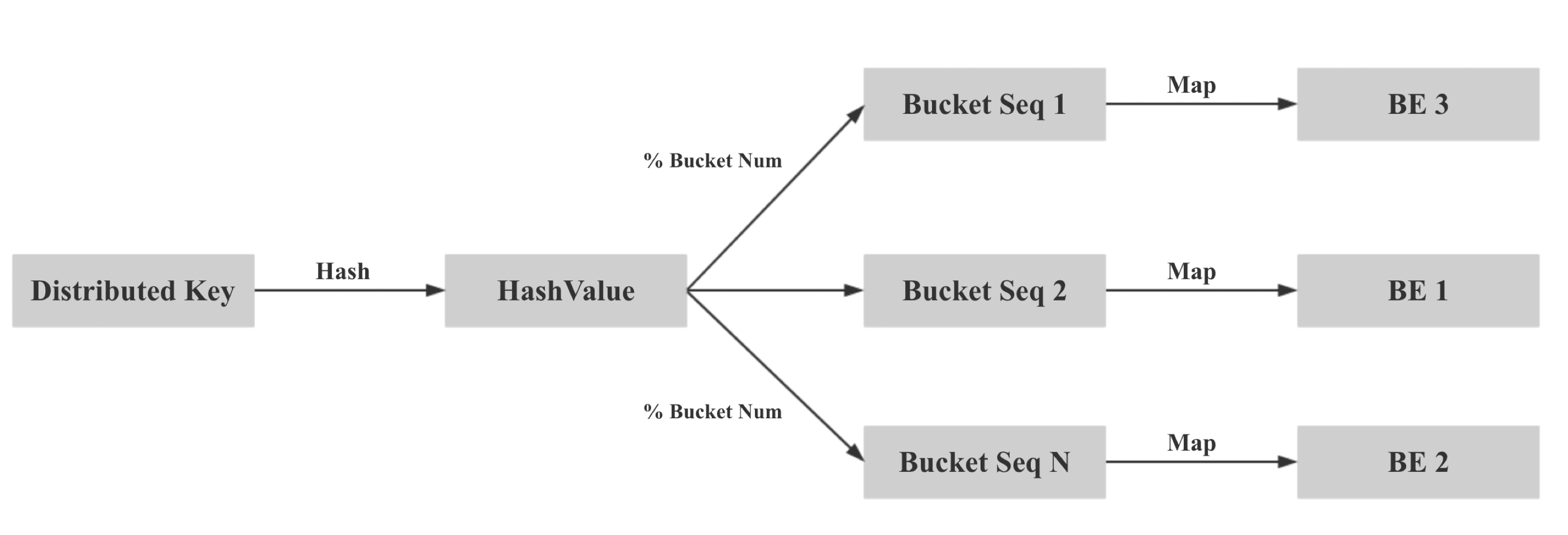
жүҖд»ҘжҲ‘们еңЁж•°жҚ®еҜје…Ҙж—¶дҝқиҜҒжң¬ең°жҖ§зҡ„ж ёеҝғжҖқжғіе°ұжҳҜдёӨж¬Ўжҳ е°„пјҢеҜ№дәҺ colocate tablesпјҢжҲ‘们дҝқиҜҒзӣёеҗҢ Distributed Key зҡ„ж•°жҚ®жҳ е°„еҲ°зӣёеҗҢзҡ„ Bucket SeqпјҢеҶҚдҝқиҜҒзӣёеҗҢ Bucket Seq зҡ„ buckets жҳ е°„еҲ°зӣёеҗҢзҡ„ BEгҖӮ

е…·дҪ“жқҘиҜҙпјҢ第дёҖжӯҘпјҡжҲ‘们计算 Distributed Key зҡ„ hash еҖјпјҢ并еҜ№ bucket num еҸ–жЁЎпјҢдҝқиҜҒзӣёеҗҢ Distributed Key зҡ„ж•°жҚ®жҳ е°„еҲ°зӣёеҗҢзҡ„ Bucket SeqгҖӮ
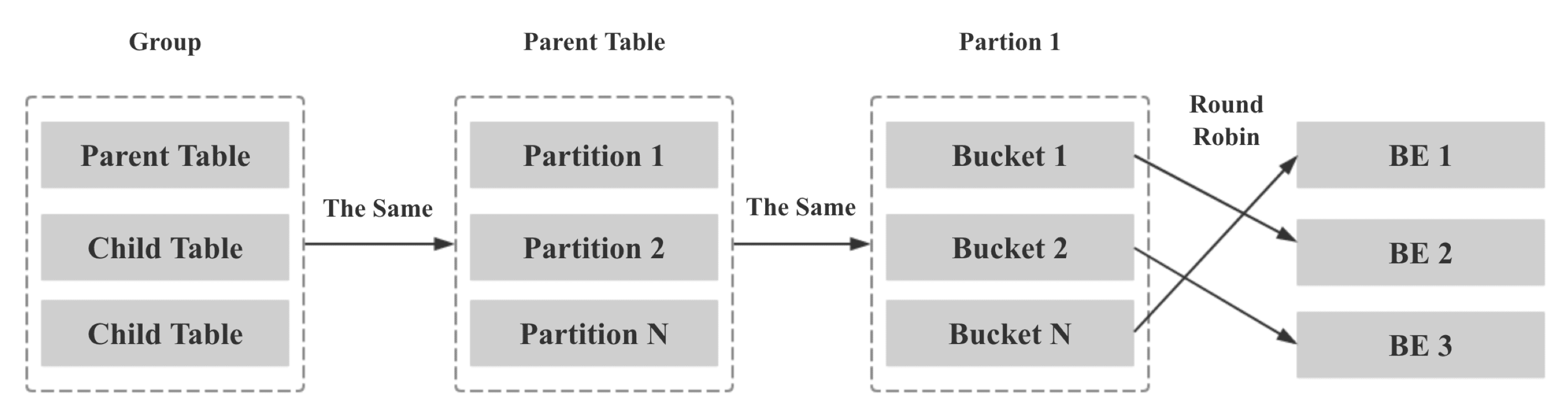
第дәҢжӯҘпјҡе°ҶеҗҢдёҖдёӘ Colocate Group дёӢжүҖжңүзӣёеҗҢ Bucket Seq зҡ„ Bucket жҳ е°„еҲ°зӣёеҗҢзҡ„ BEпјҢж–№жі•еҰӮдёӢпјҡ
Group дёӯжүҖжңү Table зҡ„ Bucket Seq е’Ң BE иҠӮзӮ№зҡ„жҳ е°„е…ізі»е’Ң Parent Table дёҖиҮҙ
Parent Table дёӯжүҖжңү Partition зҡ„ Bucket Seq е’Ң BE иҠӮзӮ№зҡ„жҳ е°„е…ізі»е’Ң第дёҖдёӘ Partition дёҖиҮҙ
Parent Table 第дёҖдёӘ Partition зҡ„ Bucket Seq е’Ң BE иҠӮзӮ№зҡ„жҳ е°„е…ізі»еҲ©з”ЁеҺҹз”ҹзҡ„ Round Robin з®—жі•еҶіе®ҡ
еҜ№ HashJoinFragmentпјҢз”ұдәҺ Join зҡ„еӨҡеј иЎЁжңүдәҶж•°жҚ®жң¬ең°жҖ§дҝқиҜҒпјҢжүҖд»ҘеҸҜд»ҘеҺ»жҺү Exchange NodeпјҢйҒҝе…ҚзҪ‘з»ңдј иҫ“пјҢе°Ҷ ScanNode зӣҙжҺҘи®ҫзҪ®дёә Hash Join Node зҡ„ ChildгҖӮ

жҹҘиҜўи°ғеәҰзҡ„зӣ®ж Үпјҡ дёҖдёӘ Colocate join дёӯжүҖжңү ScanNode дёӯжүҖжңү Bucket Seq зӣёеҗҢзҡ„ Buckets иў«и°ғеәҰеҲ°еҗҢдёҖдёӘ BEгҖӮ
жҹҘиҜўи°ғеәҰзҡ„зӯ–з•Ҙпјҡ第дёҖдёӘ ScanNode зҡ„ Buckets йҡҸжңәйҖүжӢ© BEпјҢе…¶дҪҷзҡ„ ScanNode е’Ң第дёҖдёӘ ScanNode дҝқжҢҒдёҖиҮҙгҖӮ
зӣ®еүҚпјҢDoris зҡ„ Hash Join жҳҜ Server зІ’еәҰзҡ„пјҡ
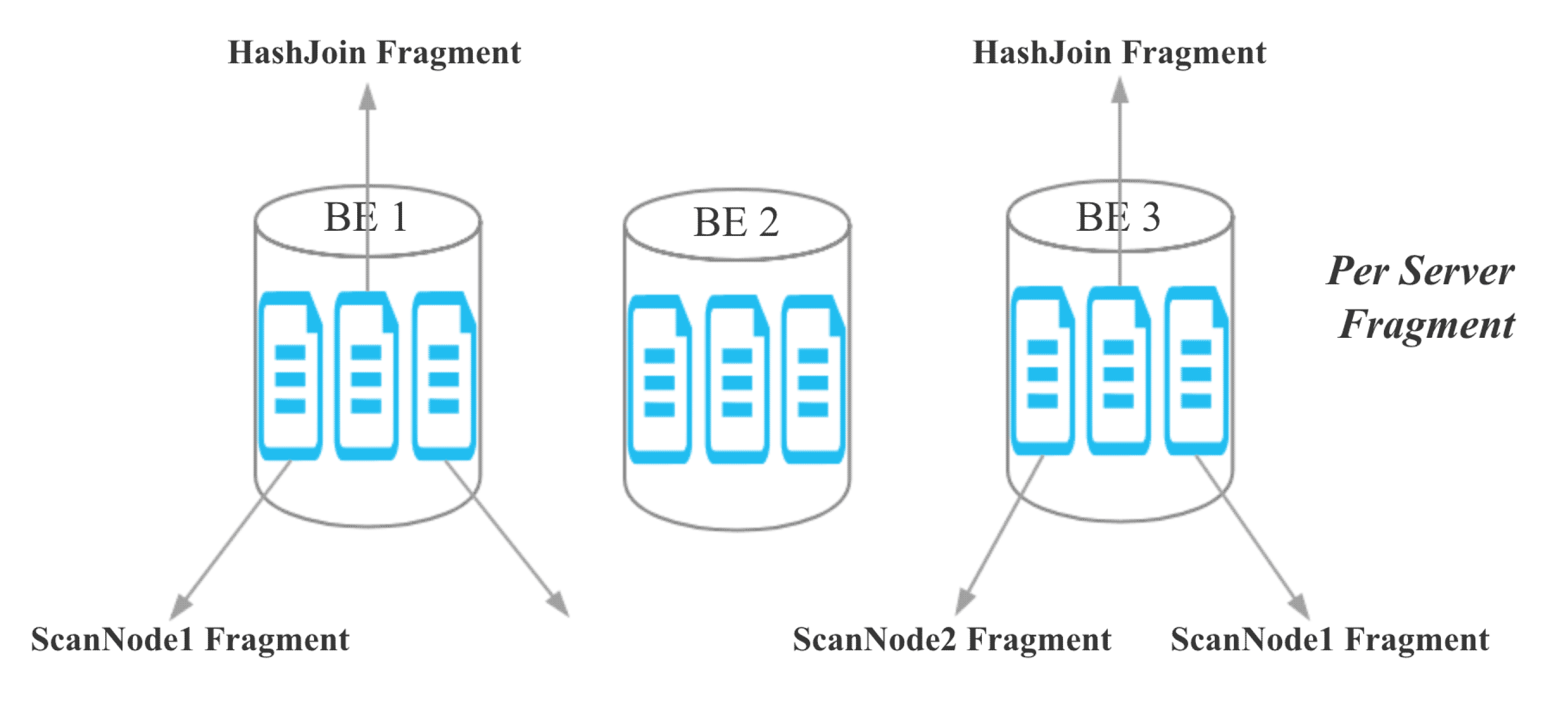
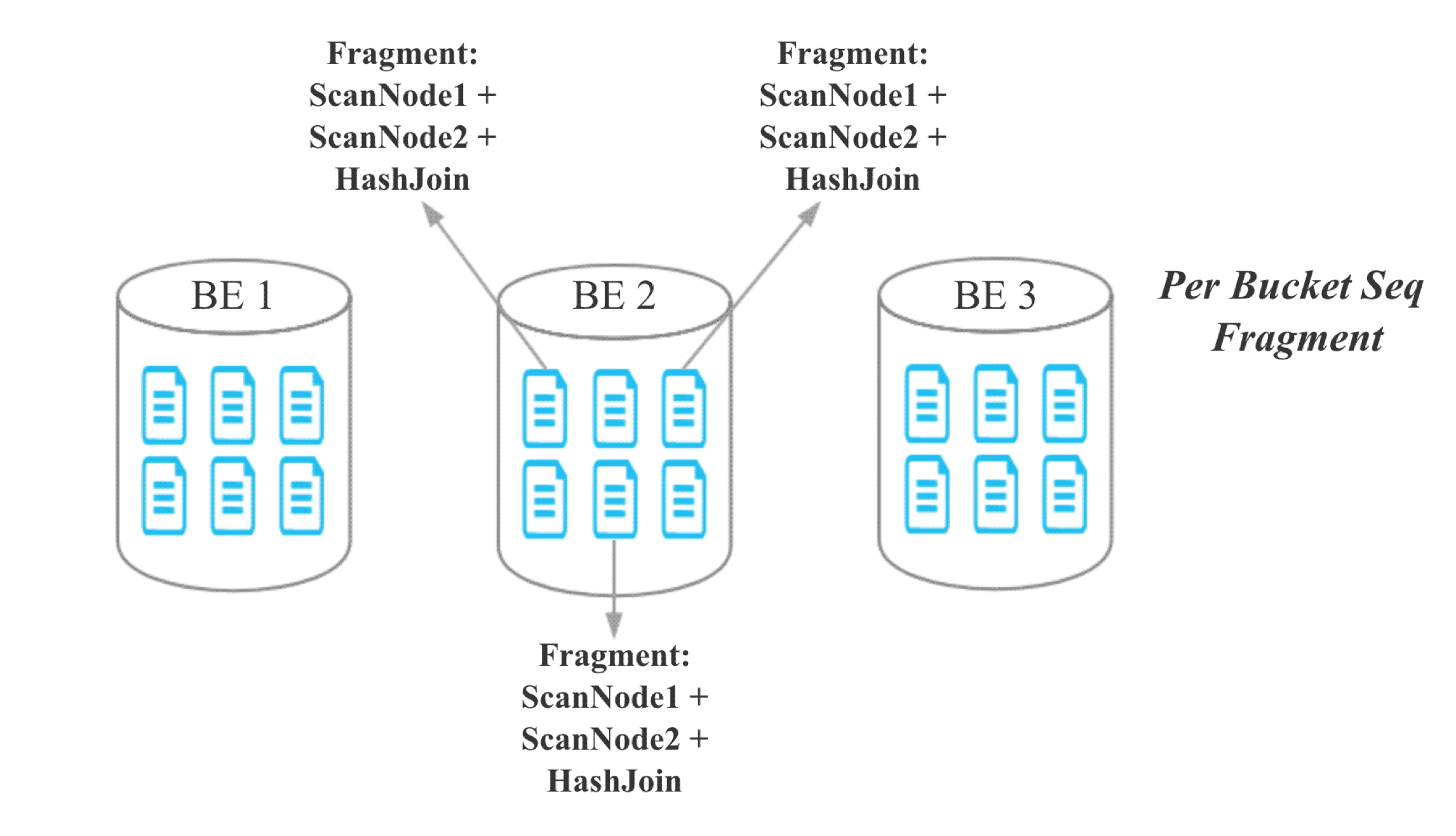
еҜ№дәҺ colocate joinпјҢз”ұдәҺеҗҢдёҖдёӘ Colocate Group дёӢзӣёеҗҢ Bucket Seq зҡ„ Bucket еҲҶеёғеңЁзӣёеҗҢзҡ„ BEпјҢжүҖд»ҘжҲ‘们е°Ҷ Join зҡ„зІ’еәҰд»Һ Server зІ’еәҰйҷҚиҮі Bucket Seq зІ’еәҰпјҡ
еҜ№дәҺ colocate joinпјҢжҲ‘们йңҖиҰҒз»ҙжҠӨд»ҘдёӢеҮ дёӘж ёеҝғе…ғж•°жҚ®пјҡ

д»Јз ҒдёӯпјҢcolocate group id е°ұжҳҜ colocate parent table id
group2BackendsPerBucketSeq д»ЈиЎЁжҜҸдёӘ colocate group дёӯжҜҸдёӘ bucket seq жҳ е°„еҲ°е“Әдәӣ BE
дёәдәҶж”ҜжҢҒ balanceпјҢд»ҘеҸҠдҝқиҜҒе…ғж•°жҚ®зҡ„дёҖиҮҙжҖ§пјҢиҝҷдәӣе…ғж•°жҚ®йғҪйңҖиҰҒжҢҒд№…еҢ–
Join зҡ„ tables жҳҜ colocate able
The colocate group жҳҜ stable зҠ¶жҖҒпјҢжІЎжңү balancing
Join зҡ„ Key еҢ…еҗ«еҲҶжЎ¶зҡ„ Distributed Key
ж ёеҝғжҖқи·Ҝпјҡ
ж–°еўһдёҖдёӘ daemon зәҝзЁӢдё“й—ЁеӨ„зҗҶ colocate table зҡ„ balanceпјҢ并让жӯЈеёёзҡ„ balance зәҝзЁӢдёҚеӨ„зҗҶ colocate table зҡ„ balanceгҖӮ
дҪ•ж—¶ balanceпјҡ
жңү BE иҠӮзӮ№ж–°еўһпјҢеҲ йҷӨпјҢdown жҺүж—¶гҖӮ
balance зҡ„зІ’еәҰпјҡ
жӯЈеёё balance зҡ„зІ’еәҰжҳҜ bucketпјҢдҪҶжҳҜеҜ№дәҺ colocate tableпјҢжҲ‘们еҝ…йЎ»дҝқиҜҒеҗҢдёҖдёӘ colocate group дёӢжүҖжңү bucket зҡ„ж•°жҚ®жң¬ең°жҖ§пјҢжүҖд»ҘжҲ‘们 balance зҡ„еҚ•дҪҚжҳҜ colocate groupгҖӮ
balance еҜ№жҹҘиҜўзҡ„еҪұе“Қпјҡ
еҪ“дёҖдёӘ colocate group жӯЈеңЁ balance ж—¶пјҢcolocate join дјҡйҖҖеҢ–дёәеҺҹе§Ӣзҡ„ shuffle join жҲ– broadcast joinгҖӮ
balance жөҒзЁӢпјҡ
дёәйңҖиҰҒеӨҚеҲ¶жҲ–иҝҒ移зҡ„ Bucket йҖүжӢ©зӣ®ж Ү BE
ж Үи®° colocate group зҡ„иҪ¬жҖҒдёә balancing
еҜ№дәҺйңҖиҰҒеӨҚеҲ¶жҲ–иҝҒ移зҡ„ BucketпјҢеҸ‘иө· Clone JobпјҢClone Job дјҡд»Һ Bucket зҡ„зҺ°жңүеүҜжң¬еӨҚеҲ¶дёҖдёӘж–°еүҜжң¬зӣ®ж Ү BE
жӣҙж–° backendsPerBucketSeqпјҲз»ҙжҠӨ Bucket Seq еҲ° BE жҳ е°„е…ізі»зҡ„е…ғж•°жҚ®пјү
еҪ“дёҖдёӘ colocate group дёӢзҡ„жүҖжңү Clone Job йғҪе®ҢжҲҗж—¶пјҢж Үи®° colocate group зҡ„иҪ¬жҖҒдёә stable
еҲ йҷӨеҶ—дҪҷзҡ„еүҜжң¬
еҪ“жңү BE иҠӮзӮ№еҲ йҷӨжҲ–й•ҝж—¶й—ҙжҢӮжҺүж—¶пјҢйҖүжӢ©зӣ®ж Ү BE зҡ„зӯ–з•Ҙпјҡ
е’ҢжӯЈеёё balance ж—¶зҡ„йҖүжӢ©зӯ–з•ҘзӣёеҗҢпјҢиҖғиҷ‘йӣҶзҫӨзҡ„ж•ҙдҪ“иҙҹиҪҪпјҢе°ҪйҮҸйҖүжӢ©иҙҹиҪҪиҫғдҪҺзҡ„ BEгҖӮ
еҪ“жңү BE иҠӮзӮ№ж–°еўһж—¶пјҢйҖүжӢ©зӣ®ж Ү BE зҡ„зӯ–з•Ҙпјҡ
еҜ№дәҺеҪ“еүҚ colocate groupпјҢи®Ўз®—жҜҸдёӘж–°еўһ BE йңҖиҰҒеўһеҠ зҡ„ bucket seqs дёӘж•°пјҡеҒҮеҰӮжҲ‘们жңү 3 дёӘ BEпјҢ8 дёӘ bucketпјҢжҜҸдёӘ bucket жҳҜ 3 еүҜжң¬пјҢеҲҷжҜҸдёӘ BE иҙҹиҙЈ 8 дёӘ bucket еүҜжң¬пјҢжҲ‘们新еўһ 1 дёӘ BE еҗҺпјҢеҸҜд»Ҙи®Ўз®—еҮәжҜҸдёӘ BE иҙҹиҙЈзҡ„е№іеқҮ bucket еүҜжң¬ж•°еә”иҜҘжҳҜ 3 * 8 / 4 = 6пјҢжҜҸдёӘж–°еўһ BE йңҖиҰҒеўһеҠ зҡ„ bucket seqs дёӘж•°дёә 6 / 1 = 6.
еҜ№дәҺжҜҸдёӘ bucket seqs, йҡҸжңәйҖүжӢ©д»Һе“ӘдёӘж—§зҡ„ BE иҝҒ移еүҜжң¬еҲ°ж–°еўһзҡ„ BEгҖӮ
жөӢиҜ•ж•°жҚ®пјҡ
Table A,B,C йғҪжңү 10 еӨ©ж•°жҚ®пјҢ1 еӨ©дёҖдёӘ partitionsпјҢжҜҸдёӘ partition жңү 570 дёҮж•°жҚ®гҖӮ
жөӢиҜ•йӣҶзҫӨпјҡ
4 еҸ°дҪҺй…Қзү©зҗҶжңәпјҢжҜҸдёӘ BE 24CPUпјҢ96MEM
жөӢиҜ• SQL:
SQL1:
select count(*) FROM A t1 INNER JOIN [shuffle] B t5 ON ((t1.dt = t5.dt) AND (t1.id = t5.id)) INNER JOIN [shuffle] C t6 ON ((t1.dt = t6.dt) AND (t1.id = t6.id)) where t1.dt in (xxx days);
SQL2:
select t1.dt, t1.id, t1.name, t1.second_id,t1.second_name, t5.id, t5.weight_time,t5.list, t6.ord_id, t6._id FROM A t1 INNER JOIN B t5 ON ((t1.dt = t5.dt) AND (t1.id = t5.id)) INNER JOIN C t6 ON ((t1.dt = t6.dt) AND (t1.id = t6.id)) where t1.dt in (xxx days) limit 10000;
Test Result for SQL1:
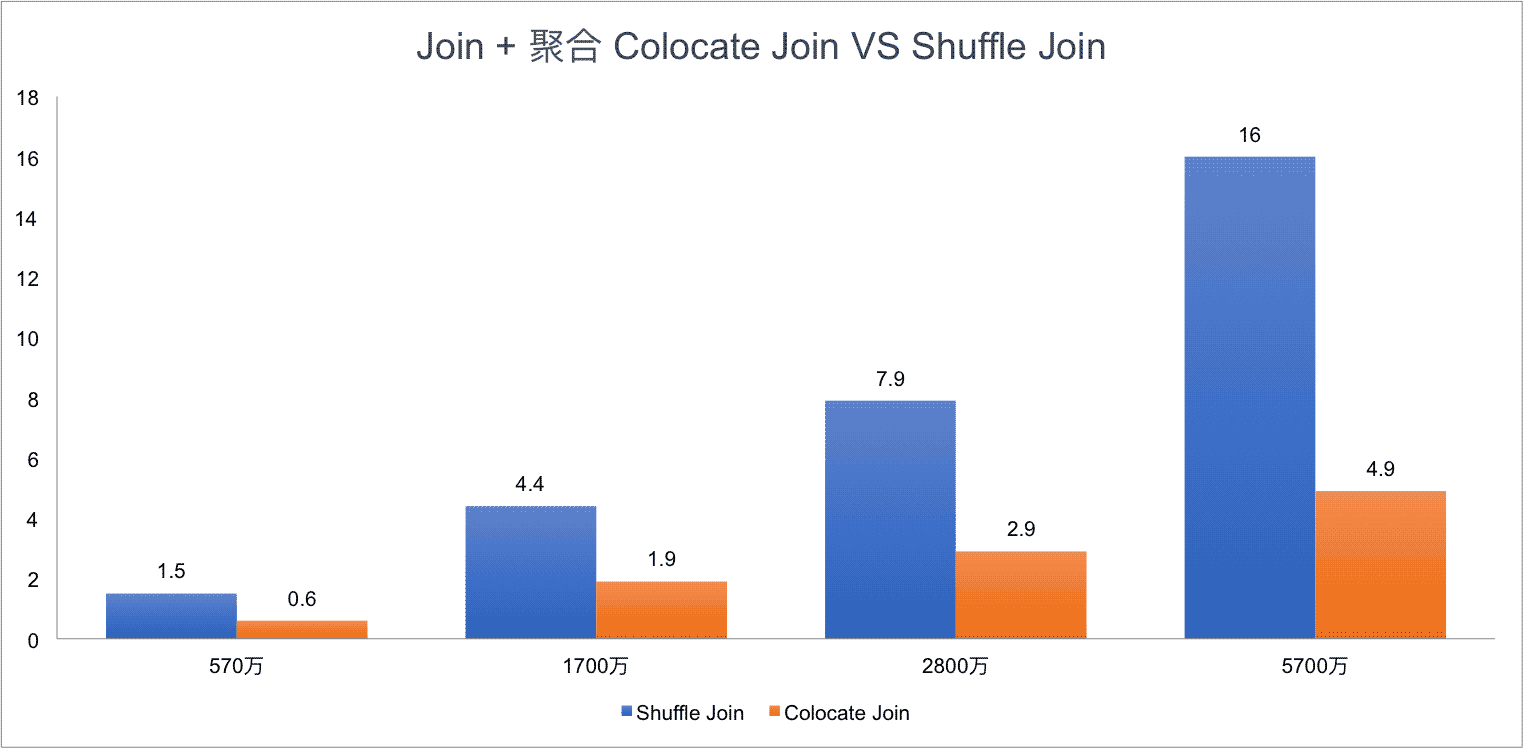
Test Result for SQL2:

еҸҜд»ҘзңӢеҲ°пјҢColocate Join зӣёжҜ” Shuffle Join жңүжҳҺжҳҫзҡ„жҖ§иғҪжҸҗеҚҮпјҢиҖҢдё”йҡҸзқҖйӣҶзҫӨ规模и¶ҠеӨ§пјҢJoin зҡ„ж•°жҚ®йҮҸи¶ҠеӨҡпјҢColocate Join зҡ„дјҳеҠҝдјҡжӣҙжҳҺжҳҫгҖӮ
зӨҫеҢәжңҖж–°д»Јз Ғе·Із»Ҹж”ҜжҢҒ Colocate JoinпјҢеҸӘдёҚиҝҮй»ҳи®ӨжҳҜе…ій—ӯзҡ„пјҢеҸӘйңҖиҰҒеңЁ FE й…ҚзҪ®дёӯи®ҫзҪ® disable_colocate_join дёә falseпјҢеҚіеҸҜејҖеҗҜ Colocate Join еҠҹиғҪгҖӮ
е…·дҪ“дҪҝз”Ёж—¶еҸӘйңҖиҰҒеңЁе»әиЎЁж—¶еўһеҠ colocate_with иҝҷдёӘеұһжҖ§еҚіеҸҜпјҢcolocate_with зҡ„еҖјеҸҜд»Ҙи®ҫзҪ®жҲҗеҗҢдёҖз»„ colocate иЎЁдёӯзҡ„д»»ж„ҸдёҖдёӘпјҢдёҚиҝҮйңҖиҰҒдҝқиҜҒ colocate_with еұһжҖ§дёӯзҡ„иЎЁиҰҒе…Ҳе»әз«ӢгҖӮ
еҒҮеҰӮйңҖиҰҒеҜ№ table t1 е’Ң t2 иҝӣиЎҢ Colocate JoinпјҢеҸҜд»ҘжҢүд»ҘдёӢиҜӯеҸҘе»әиЎЁпјҡ
CREATE TABLE `t1` ( `id` int(11) COMMENT "", `value` varchar(8) COMMENT "" ) ENGINE=OLAP DUPLICATE KEY(`id`) DISTRIBUTED BY HASH(`id`) BUCKETS 10 PROPERTIES ( "colocate_with" = "t1" ); CREATE TABLE `t2` ( `id` int(11) COMMENT "", `value` varchar(8) COMMENT "" ) ENGINE=OLAP DUPLICATE KEY(`id`) DISTRIBUTED BY HASH(`id`) BUCKETS 10 PROPERTIES ( "colocate_with" = "t1" );
Colocate Table еҝ…йЎ»жҳҜ OLAP зұ»еһӢзҡ„иЎЁ
colocate_with еұһжҖ§зӣёеҗҢиЎЁзҡ„ BUCKET ж•°еҝ…йЎ»дёҖж ·
colocate_with еұһжҖ§зӣёеҗҢиЎЁзҡ„ еүҜжң¬ж•°еҝ…йЎ»дёҖж · пјҲиҝҷдёӘйҷҗеҲ¶д№ӢеҗҺеҸҜиғҪдјҡеҺ»жҺүпјҢдҪҶеҜ№з”ЁжҲ·еә”иҜҘжІЎжңүе®һйҷ…еҪұе“Қпјү
colocate_with еұһжҖ§зӣёеҗҢиЎЁзҡ„ DISTRIBUTED Columns зҡ„ж•°жҚ®зұ»еһӢеҝ…йЎ»дёҖж ·
Colocate Join еҚҒеҲҶйҖӮеҗҲеҮ еј иЎЁжҢүз…§зӣёеҗҢеӯ—ж®өеҲҶжЎ¶пјҢ并й«ҳйў‘ж №жҚ®зӣёеҗҢеӯ—ж®ө Join зҡ„еңәжҷҜпјҢжҜ”еҰӮз”өе•Ҷзҡ„дёҚе°‘еә”з”ЁйғҪжҢүз…§е•Ҷ家 Id еҲҶжЎ¶пјҢ并й«ҳйў‘жҢүз…§е•Ҷ家 Id иҝӣиЎҢ JoinгҖӮ
дёҖеҸҘиҜқжҖ»з»“пјҢеҮЎжҳҜдёҚиғҪиҝӣиЎҢ Colocate Join зҡ„еңәжҷҜйғҪдјҡиҮӘеҠЁйҖҖеҢ–дёәеҺҹе§Ӣзҡ„ Shuffle Join жҲ–иҖ… Broadcast JoinгҖӮ
Q1: ж”ҜжҢҒеӨҡеј иЎЁиҝӣиЎҢ Colocate Join еҗ—?
A: ж”ҜжҢҒ
Q2: ж”ҜжҢҒ Colocate иЎЁе’ҢжӯЈеёёиЎЁ Join еҗ—пјҹ
A: ж”ҜжҢҒ
Q3: Colocate иЎЁж”ҜжҢҒз”ЁйқһеҲҶжЎ¶зҡ„ Key иҝӣиЎҢ Join еҗ—пјҹ
A: ж”ҜжҢҒпјҡдёҚз¬ҰеҗҲ Colocate Join жқЎд»¶зҡ„ Join дјҡдҪҝз”Ё Shuffle Join жҲ– Broadcast Join
Q4: еҰӮдҪ•зЎ®е®ҡ Join жҳҜжҢүз…§ Colocate Join жү§иЎҢзҡ„пјҹ
A: explain зҡ„з»“жһңдёӯ Hash Join зҡ„еӯ©еӯҗиҠӮзӮ№еҰӮжһңзӣҙжҺҘжҳҜ OlapScanNodeпјҢ жІЎжңү Exchange NodeпјҢе°ұиҜҙжҳҺжҳҜ Colocate Join
Q5: еҰӮдҪ•дҝ®ж”№ colocate_with еұһжҖ§пјҹ
A: ALTER TABLE example_db.my_table set ("colocate_with"="target_table");
Q6: еҰӮдҪ•зҰҒз”Ё colocate join?
A: set disable_colocate_join = true; е°ұеҸҜд»ҘзҰҒз”Ё Colocate JoinпјҢжҹҘиҜўж—¶е°ұдјҡдҪҝз”Ё Shuffle Join жҲ– Broadcast Join
еҲ°жӯӨпјҢе…ідәҺвҖңApache Doris Colocate JoinеҺҹзҗҶжҳҜд»Җд№ҲвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ