您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了pytorch的Backward过程用时太长如何解决的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇pytorch的Backward过程用时太长如何解决文章都会有所收获,下面我们一起来看看吧。
使用pytorch对网络进行训练的时候遇到一个问题,forward阶段很快(只需要几毫秒),backward阶段却用时很长(需要十多秒)。
导致这个问题的原因在于训练数据的浅拷贝,由于backward过程中的梯度是和模型推理过程中的张量相关的,如果这些张量在被模型使用之前没有被深拷贝,意味着backward过程的会重复从这些张量的原始内存地址中取值,这个过程非常耗时。所以为了避免这个问题,需要养成一个好习惯,就是将张量数据输入模型之前进行深拷贝
pytorch的深拷贝方式如下:
tensor_a = tensor_b.clone().detach()
backward()是反向传播求梯度,具体实现过程如下
import torch x=torch.tensor([1,2,3],requires_grad=True,dtype=torch.double) y=x**2 z=y.mean() z.backward() print(x.grad)
结果
tensor([0.6667, 1.3333, 2.0000], dtype=torch.float64)
1.必须要加上requires_grad=True才能求
2. 一般来说,需要标量才能求梯度。
3.具体过程如下:
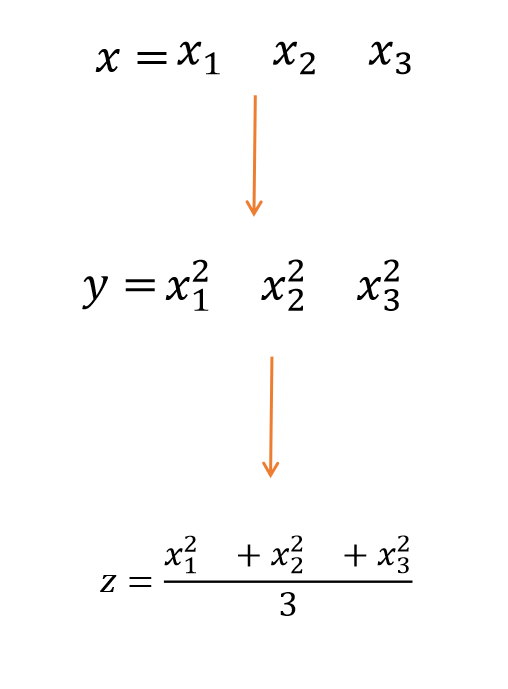
z是一个标量(1*1矩阵)分别对x1,x2,x3求偏导, 再代入x1,x2,x3的数值,就是如上程序输出的结果
关于“pytorch的Backward过程用时太长如何解决”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“pytorch的Backward过程用时太长如何解决”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。