жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢsparkзј–зЁӢpythonд»Јз ҒеҲҶжһҗзҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[])
1.1.еҗҜеҠЁ
IPYTHON_OPTS="notebook" /opt/spark/bin/pyspark

дёӢиҪҪеә”з”ЁпјҢе°Ҷеә”з”ЁдёӢиҪҪдёә.pyж–Ү件пјҲй»ҳи®ӨnotebookеҗҺзјҖжҳҜ.ipynbпјү
wxl@wxl-pc:/opt/spark/bin$ spark-submit /bin/spark-submit /home/wxl/Downloads/pysparkdemo.py

ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[*])
d*
3.1.й”ҷиҜҜ
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[*])
d*
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[*]) created by <module> at /usr/local/lib/python2.7/dist-packages/IPython/utils/py3compat.py:288
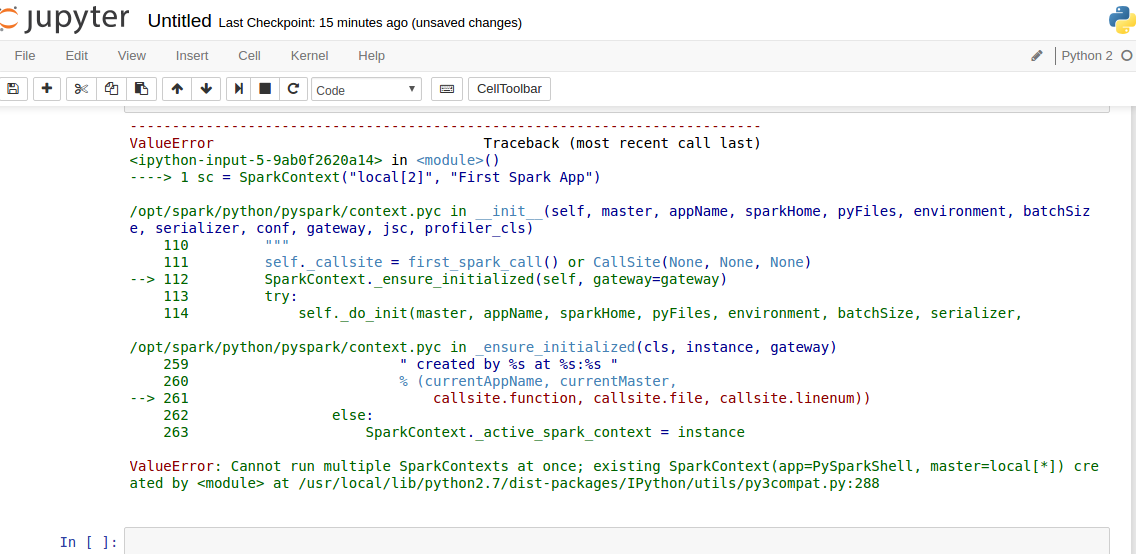
3.2.и§ЈеҶіпјҢжҲҗеҠҹиҝҗиЎҢ
еңЁfromд№ӢеҗҺж·»еҠ
try:
sc.stop()
except:
pass
sc=SparkContext('local[2]','First Spark App')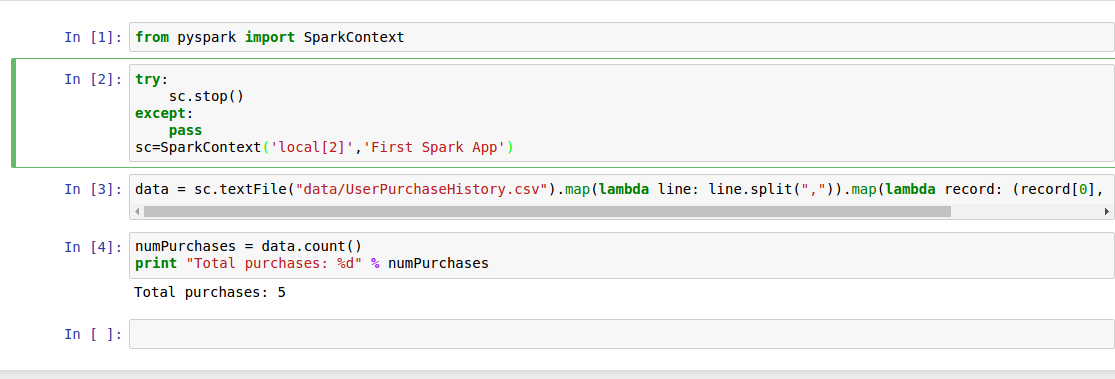
иҙҙдёҠй”ҷиҜҜи§ЈеҶіж–№жі•жқҘжәҗStackOverFlow
pysparkdemo.ipynb
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"from pyspark import SparkContext"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"try:\n",
" sc.stop()\n",
"except:\n",
" pass\n",
"sc=SparkContext('local[2]','First Spark App')"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"data = sc.textFile(\"data/UserPurchaseHistory.csv\").map(lambda line: line.split(\",\")).map(lambda record: (record[0], record[1], record[2]))"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"collapsed": false,
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Total purchases: 5\n"
]
}
],
"source": [
"numPurchases = data.count()\n",
"print \"Total purchases: %d\" % numPurchases"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.12"
}
},
"nbformat": 4,
"nbformat_minor": 0
}pysparkdemo.py
# coding: utf-8
# In[1]:
from pyspark import SparkContext
# In[2]:
try:
sc.stop()
except:
pass
sc=SparkContext('local[2]','First Spark App')
# In[3]:
data = sc.textFile("data/UserPurchaseHistory.csv").map(lambda line: line.split(",")).map(lambda record: (record[0], record[1], record[2]))
# In[4]:
numPurchases = data.count()
print "Total purchases: %d" % numPurchases
# In[ ]:д»ҘдёҠе°ұжҳҜвҖңsparkзј–зЁӢpythonд»Јз ҒеҲҶжһҗвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ