жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶGoиҜӯиЁҖеҰӮдҪ•е®һзҺ°LRUз®—жі•зҡ„ж ёеҝғжҖқжғіе’Ңе®һзҺ°иҝҮзЁӢпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢйңҖиҰҒзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢгҖӮдёӢйқўе°ұе’ҢжҲ‘дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
еёёи§Ғзҡ„дёүз§Қзј“еӯҳж·ҳжұ°з®—жі•жңүдёүз§Қ:FIFO,LRUе’ҢLFU
е®һзҺ°LRUзј“еӯҳж·ҳжұ°з®—жі•
зј“еӯҳе…ЁйғЁеӯҳеңЁеҶ…еӯҳдёӯпјҢеҶ…еӯҳжҳҜжңүйҷҗзҡ„пјҢеӣ жӯӨдёҚеҸҜиғҪж— йҷҗеҲ¶зҡ„ж·»еҠ ж•°жҚ®пјҢеҒҮе®ҡжҲ‘们иғҪеӨҹжңҖеӨ§дҪҝз”Ёзҡ„еҶ…еӯҳдёәMax,йӮЈд№ҲеңЁдёҖдёӘж—¶й—ҙзӮ№д№ӢеҗҺпјҢж·»еҠ дәҶжҹҗдёҖжқЎзј“еӯҳи®°еҪ•д№ӢеҗҺпјҢеҚ з”ЁеҶ…еӯҳи¶…иҝҮдәҶN,иҝҷдёӘж—¶еҖҷе°ұйңҖиҰҒд»Һзј“еӯҳдёӯ移йҷӨдёҖдәӣж•°жҚ®пјҢйӮЈд№ҲиҜҘ移йҷӨжҲ–иҖ…ж·ҳжұ°и°Ғе‘ўпјҹжҲ‘们иӮҜе®ҡеёҢжңӣеҺ»з§»йҷӨжІЎз”Ёзҡ„ж•°жҚ®пјҢе°ҶзғӯзӮ№ж•°жҚ®з•ҷеңЁзј“еӯҳдёӯ,дёӢйқўеҮ з§Қе°ұжҳҜеҜ№еә”зҡ„еҮ з§Қзӯ–з•ҘпјҒ
FIFO пјҲFirst in First Outпјү
е…Ҳиҝӣе…ҲеҮәпјҢеҶ…еӯҳж»ЎдәҶж—¶ж·ҳжұ°жңҖиҖҒеӯҳеңЁжңҖд№…зҡ„keyзј“еӯҳпјҢиҝҷз§Қз®—жі•и®Өдёәи¶Ҡж—©иў«ж·»еҠ зҡ„ж•°жҚ®дҪҝз”ЁеҸҜиғҪжҖ§дјҡжҜ”ж–°еҠ е…ҘиҝӣжқҘзҡ„е°ҸпјҢдҪҶжҳҜиҝҷз§Қд№ҹжңүејҠз«ҜпјҢеңЁжҹҗдәӣеңәжҷҜдёӢжҜ”еҰӮжҹҘеҺҶеҸІж”Ҝд»ҳи®°еҪ•зҡ„иҙҰеҚ•пјҢе°ұйңҖиҰҒжҹҘиҜўд№ӢеүҚзҡ„зј“еӯҳи®°еҪ•пјҢиҝҷзұ»и®°еҪ•е°ұдёҚеҫ—дёҚеӣ дёәжҜҸеӨ©ж–°зҡ„ж”Ҝд»ҳд»ҺиҖҢж·ҳжұ°жҺүд»ҘеүҚзҡ„ж”Ҝд»ҳи®°еҪ•пјҲеҪ“然иҝҷзұ»и®°еҪ•еӯҳеә“жҳҜжңҖеҘҪж–№ејҸпјү
гҖҗе®һзҺ°ж–№ејҸгҖ‘з»ҙжҠӨдёҖдёӘйҳҹеҲ—е…Ҳиҝӣе…ҲеҮәе°ұиЎҢдәҶ,ж–°жқҘзҡ„ж•°жҚ®еҠ еҲ°йҳҹе°ҫ
LFU (Least Frequently Used)
жңҖе°‘дҪҝз”ЁпјҢд№ҹе°ұжҳҜж·ҳжұ°зј“еӯҳдёӯи®ҝй—®йў‘зҺҮжңҖдҪҺзҡ„и®°еҪ•гҖӮиҝҷдёӘз®—жі•и®ӨдёәиҝҮеҺ»и®ҝй—®ж¬Ўж•°жңҖй«ҳзҡ„дҪҝз”ЁжҰӮзҺҮд№ҹжңҖеӨ§пјҢдҪҶжҳҜиҝҷж ·е°ұйўқеӨ–з»ҙжҠӨдәҶдёҖдёӘи®ҝй—®ж¬Ўж•°пјҢеҜ№еҶ…еӯҳе…¶е®һеҚ з”Ёд№ҹжҢәеӨҡзҡ„пјҢеҶҚиҖ…и®ҝй—®ж¬Ўж•°жңҖеӨҡзҡ„ж•°жҚ®пјҢзӘҒ然дёҚдҪҝз”ЁдәҶпјҢйӮЈд№ҲиҰҒж·ҳжұ°е®ғд№ӢеүҚпјҢйңҖиҰҒеҶ…еӯҳе…¶д»–еҢәеҹҹзҡ„ж•°жҚ®и®ҝй—®ж¬Ўж•°е…ЁйғЁи¶…иҝҮе®ғжүҚжңүеҸҜиғҪпјҢжүҖд»Ҙж·ҳжұ°зҡ„зјәзӮ№д№ҹйқһеёёжҳҺжҳҫгҖӮ
гҖҗе®һзҺ°ж–№ејҸгҖ‘LFU зҡ„е®һзҺ°йңҖиҰҒз»ҙжҠӨдёҖдёӘжҢүз…§и®ҝй—®ж¬Ўж•°жҺ’еәҸзҡ„йҳҹеҲ—пјҢжҜҸж¬Ўи®ҝй—®пјҢи®ҝй—®ж¬Ўж•°еҠ 1пјҢйҳҹеҲ—йҮҚж–°жҺ’еәҸпјҢж·ҳжұ°ж—¶йҖүжӢ©и®ҝй—®ж¬Ўж•°жңҖе°‘зҡ„еҚіеҸҜ
LRU пјҲLeast Recently Usedпјү
жңҖиҝ‘жңҖе°‘дҪҝз”Ё,зӣёеҜ№дәҺеҸӘиҖғиҷ‘дҪҝз”Ёж—¶й—ҙе’ҢдҪҝз”Ёж¬Ўж•°жқҘзңӢпјҢLRUдјҡзӣёеҜ№жҜ”иҫғе№іеқҮеҺ»ж·ҳжұ°ж•°жҚ®пјҢеҰӮжһңж•°жҚ®жңҖиҝ‘иў«дҪҝз”ЁиҝҮпјҢйӮЈд№Ҳе°ҶжқҘиў«и®ҝй—®зҡ„жҰӮзҺҮе°ҶжҸҗй«ҳ
гҖҗе®һзҺ°ж–№ејҸгҖ‘з»ҙжҠӨдёҖдёӘйҳҹеҲ—пјҢеҰӮжһңжҹҗжқЎи®°еҪ•иў«и®ҝй—®дәҶпјҢеҲҷ移еҠЁеҲ°йҳҹе°ҫпјҢйӮЈд№ҲйҳҹйҰ–еҲҷжҳҜжңҖиҝ‘жңҖе°‘и®ҝй—®зҡ„ж•°жҚ®пјҢж·ҳжұ°иҜҘжқЎи®°еҪ•еҚіеҸҜгҖӮ
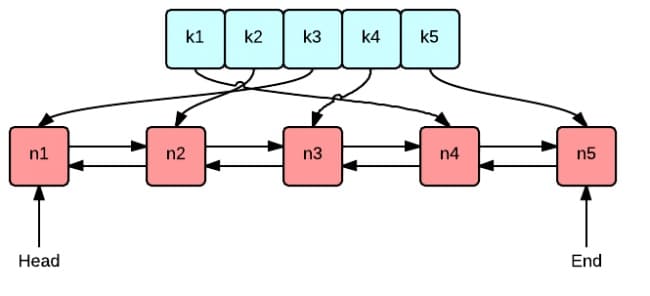
иҝҷеј еӣҫеҫҲеҘҪең°иЎЁзӨәдәҶ LRU з®—жі•жңҖж ёеҝғзҡ„ 2 дёӘж•°жҚ®з»“жһ„
з»ҝиүІзҡ„жҳҜеӯ—е…ё(map)пјҢеӯҳеӮЁй”®е’ҢеҖјзҡ„жҳ е°„е…ізі»гҖӮиҝҷж ·ж №жҚ®жҹҗдёӘй”®(key)жҹҘжүҫеҜ№еә”зҡ„еҖј(value)зҡ„еӨҚжқӮжҳҜO(1)пјҢеңЁеӯ—е…ёдёӯжҸ’е…ҘдёҖжқЎи®°еҪ•зҡ„еӨҚжқӮеәҰд№ҹжҳҜO(1)гҖӮ
зәўиүІзҡ„жҳҜеҸҢеҗ‘й“ҫиЎЁ(double linked list)е®һзҺ°зҡ„йҳҹеҲ—гҖӮе°ҶжүҖжңүзҡ„еҖјж”ҫеҲ°еҸҢеҗ‘й“ҫиЎЁдёӯпјҢиҝҷж ·пјҢеҪ“и®ҝй—®еҲ°жҹҗдёӘеҖјж—¶пјҢе°Ҷ其移еҠЁеҲ°йҳҹе°ҫзҡ„еӨҚжқӮеәҰжҳҜO(1)пјҢеңЁйҳҹе°ҫж–°еўһдёҖжқЎи®°еҪ•д»ҘеҸҠеҲ йҷӨдёҖжқЎи®°еҪ•зҡ„еӨҚжқӮеәҰеқҮдёәO(1)гҖӮ
жҺҘдёӢжқҘжҲ‘们еҲӣе»әдёҖдёӘеҢ…еҗ«еӯ—е…ёе’ҢеҸҢеҗ‘й“ҫиЎЁзҡ„з»“жһ„дҪ“зұ»еһӢ CacheпјҢж–№дҫҝе®һзҺ°еҗҺз»ӯзҡ„еўһеҲ жҹҘж”№ж“ҚдҪңгҖӮ
package lru
import (
"container/list"
"log"
)
// Cache is a LRU cache. It is not safe for concurrent access.
type Cache struct {
maxBytes int64 // е…Ғи®ёдҪҝз”Ёзҡ„жңҖеӨ§еҶ…еӯҳ
nbytes int64 // еҪ“еүҚе·ІдҪҝз”Ёзҡ„еҶ…еӯҳ
ll *list.List
cache map[string]*list.Element
// optional and executed when an entry is purged.
OnEvicted func(key string, value Value) // жҹҗжқЎи®°еҪ•иў«з§»йҷӨж—¶зҡ„еӣһи°ғеҮҪж•°
}
type entry struct {
key string
value Value
}
// Value use Len to count how many bytes it takes
type Value interface {
Len() int
}еңЁиҝҷйҮҢжҲ‘们зӣҙжҺҘдҪҝз”Ё Go иҜӯиЁҖж ҮеҮҶеә“е®һзҺ°зҡ„еҸҢеҗ‘й“ҫиЎЁlist.ListгҖӮ
еӯ—е…ёзҡ„е®ҡд№үжҳҜ map[string]*list.ElementпјҢй”®жҳҜеӯ—з¬ҰдёІпјҢеҖјжҳҜеҸҢеҗ‘й“ҫиЎЁдёӯеҜ№еә”иҠӮзӮ№зҡ„жҢҮй’ҲгҖӮ
maxBytes жҳҜе…Ғи®ёдҪҝз”Ёзҡ„жңҖеӨ§еҶ…еӯҳпјҢnbytes жҳҜеҪ“еүҚе·ІдҪҝз”Ёзҡ„еҶ…еӯҳпјҢOnEvicted жҳҜжҹҗжқЎи®°еҪ•иў«з§»йҷӨж—¶зҡ„еӣһи°ғеҮҪж•°пјҢеҸҜд»Ҙдёә nilгҖӮ
й”®еҖјеҜ№ entry жҳҜеҸҢеҗ‘й“ҫиЎЁиҠӮзӮ№зҡ„ж•°жҚ®зұ»еһӢпјҢеңЁй“ҫиЎЁдёӯд»ҚдҝқеӯҳжҜҸдёӘеҖјеҜ№еә”зҡ„ key зҡ„еҘҪеӨ„еңЁдәҺпјҢж·ҳжұ°йҳҹйҰ–иҠӮзӮ№ж—¶пјҢйңҖиҰҒз”Ё key д»Һеӯ—е…ёдёӯеҲ йҷӨеҜ№еә”зҡ„жҳ е°„гҖӮ
дёәдәҶйҖҡз”ЁжҖ§пјҢжҲ‘们е…Ғи®ёеҖјжҳҜе®һзҺ°дәҶ Value жҺҘеҸЈзҡ„д»»ж„Ҹзұ»еһӢпјҢиҜҘжҺҘеҸЈеҸӘеҢ…еҗ«дәҶдёҖдёӘж–№жі• Len() intпјҢз”ЁдәҺиҝ”еӣһеҖјжүҖеҚ з”Ёзҡ„еҶ…еӯҳеӨ§е°ҸгҖӮ
ж–№дҫҝе®һдҫӢеҢ– CacheпјҢе®һзҺ° New() еҮҪж•°пјҡ
// New is the Constructor of Cache
func New(maxBytes int64, onEvicted func(string, Value)) *Cache {
return &Cache{
maxBytes: maxBytes,
ll: list.New(),
cache: make(map[string]*list.Element),
OnEvicted: onEvicted,
}
}жҹҘжүҫдё»иҰҒжңү 2 дёӘжӯҘйӘӨпјҢ第дёҖжӯҘжҳҜд»Һеӯ—е…ёдёӯжүҫеҲ°еҜ№еә”зҡ„еҸҢеҗ‘й“ҫиЎЁзҡ„иҠӮзӮ№пјҢ第дәҢжӯҘпјҢе°ҶиҜҘиҠӮзӮ№з§»еҠЁеҲ°йҳҹе°ҫгҖӮ
func (c *Cache)Get(key string)(val Value,ok bool){
// еҰӮжһңжүҫеҲ°дәҶиҠӮзӮ№пјҢе°ұе°Ҷзј“еӯҳ移еҠЁеҲ°йҳҹе°ҫ
if ele,ok:=c.cache[key];ok{
c.ll.MoveToBack(ele)
kv:=ele.Value.(*entry)
return kv.value,true
}
return
}еҰӮжһңй”®еҜ№еә”зҡ„й“ҫиЎЁиҠӮзӮ№еӯҳеңЁпјҢеҲҷе°ҶеҜ№еә”иҠӮзӮ№з§»еҠЁеҲ°йҳҹе°ҫпјҢ并иҝ”еӣһжҹҘжүҫеҲ°зҡ„еҖјгҖӮ
c.ll.MoveToBack(ele)пјҢеҚіе°Ҷй“ҫиЎЁдёӯзҡ„иҠӮзӮ№ ele 移еҠЁеҲ°йҳҹе°ҫ
иҝҷйҮҢзҡ„еҲ йҷӨпјҢе®һйҷ…дёҠжҳҜзј“еӯҳж·ҳжұ°гҖӮеҚіз§»йҷӨжңҖиҝ‘жңҖе°‘и®ҝй—®зҡ„иҠӮзӮ№пјҲйҳҹйҰ–пјү
// 移йҷӨжңҖиҝ‘жңҖиҝ‘пјҢжңҖе°‘и®ҝй—®зҡ„зҡ„иҠӮзӮ№
func (c *Cache)RemoveOldest(){
ele:=c.ll.Front() // еҸ–еҲ°йҳҹйҰ–иҠӮзӮ№пјҢд»Һй“ҫиЎЁдёӯеҲ йҷӨ
if ele!=nil{
c.ll.Remove(ele)
kv:=ele.Value.(*entry)
delete(c.cache,kv.key)
c.nbytes-=int64(len(kv.key))+int64(kv.value.Len())
if c.OnEvicted != nil {
c.OnEvicted(kv.key, kv.value)
}
}
}c.ll.Front() еҸ–еҲ°йҳҹйҰ–иҠӮзӮ№пјҢд»Һй“ҫиЎЁдёӯеҲ йҷӨгҖӮ
delete(c.cache, kv.key)пјҢд»Һеӯ—е…ёдёӯ c.cache еҲ йҷӨиҜҘиҠӮзӮ№зҡ„жҳ е°„е…ізі»гҖӮ
жӣҙж–°еҪ“еүҚжүҖз”Ёзҡ„еҶ…еӯҳ c.nbytesгҖӮ
еҰӮжһңеӣһи°ғеҮҪж•° OnEvicted дёҚдёә nilпјҢеҲҷи°ғз”Ёеӣһи°ғеҮҪж•°
// ж–°еўһжҲ–дҝ®ж”№
func (c *Cache)Add(key string ,value Value){
if int64(value.Len())>c.maxBytes{
log.Printf("и¶…иҝҮжңҖеӨ§е®№йҮҸ%d,жҸ’е…Ҙзј“еӯҳе®№йҮҸдёә%d",c.maxBytes,int64(value.Len()))
return
}
if ele,ok:=c.cache[key];ok{
c.ll.MoveToBack(ele)
kv:=ele.Value.(*entry)
c.nbytes += int64(value.Len()) - int64(kv.value.Len())
}else{
ele:=c.ll.PushFront(&entry{key: key,value: value})
c.cache[key]=ele
c.nbytes=int64(len(key))+int64(value.Len())
}
// еҰӮжһңеҪ“еүҚдҪҝз”Ёзҡ„еҶ…еӯҳ>е…Ғи®ёдҪҝз”Ёзҡ„жңҖеӨ§еҶ…еӯҳ дҪҝз”Ёж·ҳжұ°зӯ–з•Ҙ
for c.maxBytes !=0 && c.maxBytes < c.nbytes{
c.RemoveOldest()
}
}еҰӮжһңй”®еӯҳеңЁпјҢеҲҷжӣҙж–°еҜ№еә”иҠӮзӮ№зҡ„еҖјпјҢ并е°ҶиҜҘиҠӮзӮ№з§»еҲ°йҳҹе°ҫгҖӮ
дёҚеӯҳеңЁеҲҷжҳҜж–°еўһеңәжҷҜпјҢйҰ–е…Ҳйҳҹе°ҫж·»еҠ ж–°иҠӮзӮ№ &entry{key, value}, 并еӯ—е…ёдёӯж·»еҠ key е’ҢиҠӮзӮ№зҡ„жҳ е°„е…ізі»гҖӮ
жӣҙж–° c.nbytesпјҢеҰӮжһңи¶…иҝҮдәҶи®ҫе®ҡзҡ„жңҖеӨ§еҖј c.maxBytesпјҢеҲҷ移йҷӨжңҖе°‘и®ҝй—®зҡ„иҠӮзӮ№гҖӮ
д»ҘдёҠе°ұжҳҜGoиҜӯиЁҖеҰӮдҪ•е®һзҺ°LRUз®—жі•зҡ„ж ёеҝғжҖқжғіе’Ңе®һзҺ°иҝҮзЁӢзҡ„иҜҰз»ҶеҶ…е®№дәҶпјҢзңӢе®Ңд№ӢеҗҺжҳҜеҗҰжңүжүҖ收иҺ·е‘ўпјҹеҰӮжһңжғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺжқҘдәҝйҖҹдә‘иЎҢдёҡиө„и®ҜпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ