жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬ж–Үе°Ҷж №жҚ®еҗ„з§Қе®һз”Ёж“ҚдҪңпјҲйҒҚеҺҶгҖҒжҸ’е…ҘгҖҒеҲ йҷӨгҖҒжҺ’еәҸгҖҒжҹҘжүҫпјү并结еҗҲе®һдҫӢеҜ№еёёз”Ёж•°жҚ®з»“жһ„иҝӣиЎҢжҖ§иғҪеҲҶжһҗгҖӮ
ж•°з»„жҳҜжңҖеёёз”Ёзҡ„дёҖз§ҚзәҝжҖ§иЎЁпјҢеҜ№дәҺйқҷжҖҒзҡ„жҲ–иҖ…йў„е…ҲиғҪзЎ®е®ҡеӨ§е°Ҹзҡ„ж•°жҚ®йӣҶеҗҲпјҢйҮҮз”Ёж•°з»„иҝӣиЎҢеӯҳеӮЁжҳҜжңҖдҪійҖүжӢ©гҖӮ
ж•°з»„зҡ„дјҳзӮ№дёҖжҳҜжҹҘжүҫж–№дҫҝпјҢеҲ©з”ЁдёӢж ҮеҚіеҸҜз«ӢеҚіе®ҡдҪҚеҲ°жүҖйңҖзҡ„ж•°жҚ®иҠӮзӮ№пјӣдәҢжҳҜж·»еҠ жҲ–еҲ йҷӨе…ғзҙ ж—¶дёҚдјҡдә§з”ҹеҶ…еӯҳзўҺзүҮпјӣдёүжҳҜдёҚйңҖиҰҒиҖғиҷ‘ж•°жҚ®иҠӮзӮ№жҢҮй’Ҳзҡ„еӯҳеӮЁгҖӮ然иҖҢпјҢж•°з»„дҪңдёәдёҖз§ҚйқҷжҖҒж•°жҚ®з»“жһ„пјҢеӯҳеңЁеҶ…еӯҳдҪҝз”ЁзҺҮдҪҺгҖҒеҸҜжү©еұ•жҖ§е·®зҡ„зјәзӮ№гҖӮж— и®әж•°з»„дёӯе®һйҷ…жңүеӨҡе°‘е…ғзҙ пјҢзј–иҜ‘еҷЁжҖ»дјҡжҢүз…§йў„е…Ҳи®ҫе®ҡеҘҪзҡ„еҶ…еӯҳе®№йҮҸиҝӣиЎҢеҲҶй…ҚгҖӮеҰӮжһңи¶…еҮәиҫ№з•ҢпјҢеҲҷйңҖиҰҒе»әз«Ӣж–°зҡ„ж•°з»„гҖӮ
й“ҫиЎЁжҳҜеҸҰдёҖз§Қеёёз”Ёзҡ„зәҝжҖ§иЎЁпјҢдёҖдёӘй“ҫиЎЁе°ұжҳҜдёҖдёӘз”ұжҢҮй’ҲиҝһжҺҘзҡ„ж•°жҚ®й“ҫгҖӮжҜҸдёӘж•°жҚ®иҠӮзӮ№з”ұжҢҮй’Ҳеҹҹе’Ңж•°жҚ®еҹҹжһ„жҲҗпјҢжҢҮй’ҲдёҖиҲ¬жҢҮеҗ‘й“ҫиЎЁдёӯзҡ„дёӢдёҖдёӘиҠӮзӮ№пјҢеҰӮжһңиҠӮзӮ№жҳҜй“ҫиЎЁдёӯзҡ„жңҖеҗҺдёҖдёӘпјҢеҲҷжҢҮй’ҲдёәNULLгҖӮеңЁеҸҢеҗ‘й“ҫиЎЁпјҲDouble Linked ListпјүдёӯпјҢжҢҮй’ҲеҹҹиҝҳеҢ…жӢ¬дёҖдёӘжҢҮеҗ‘дёҠдёҖдёӘж•°жҚ®иҠӮзӮ№зҡ„жҢҮй’ҲгҖӮеңЁи·іиҪ¬й“ҫиЎЁпјҲSkip Linked ListпјүдёӯпјҢжҢҮй’ҲеҹҹеҢ…еҗ«жҢҮеҗ‘д»»ж„ҸжҹҗдёӘе…іиҒ”еҗ‘зҡ„жҢҮй’ҲгҖӮ
template <typename T>
class LinkedNode
{
public:
LinkedNode(const T& e): pNext(NULL), pPrev(NULL)
{
data = e;
}
LinkedNode<T>* Next()const
{
return pNext;
}
LinkedNode<T>* Prev()const
{
return pPrev;
}
private:
T data;
LinkedNode<T>* pNext;// жҢҮеҗ‘дёӢдёҖдёӘж•°жҚ®иҠӮзӮ№зҡ„жҢҮй’Ҳ
LinkedNode<T>* pPrev;// жҢҮеҗ‘дёҠдёҖдёӘж•°жҚ®иҠӮзӮ№зҡ„жҢҮй’Ҳ
LinkedNode<T>* pConnection;// жҢҮеҗ‘е…іиҒ”иҠӮзӮ№зҡ„жҢҮй’Ҳ
};дёҺйў„е…ҲйқҷжҖҒеҲҶй…ҚеҘҪеӯҳеӮЁз©әй—ҙзҡ„ж•°з»„дёҚеҗҢпјҢй“ҫиЎЁзҡ„й•ҝеәҰжҳҜеҸҜеҸҳзҡ„гҖӮеҸӘиҰҒеҶ…еӯҳз©әй—ҙи¶іеӨҹпјҢзЁӢеәҸе°ұиғҪжҢҒз»ӯдёәй“ҫиЎЁжҸ’е…Ҙж–°зҡ„ж•°жҚ®йЎ№гҖӮж•°з»„дёӯжүҖжңүзҡ„ж•°жҚ®йЎ№йғҪиў«еӯҳж”ҫеңЁдёҖж®өиҝһз»ӯзҡ„еӯҳеӮЁз©әй—ҙдёӯпјҢй“ҫиЎЁдёӯзҡ„ж•°жҚ®йЎ№дјҡиў«йҡҸжңәеҲҶй…ҚеҲ°еҶ…еӯҳзҡ„жҹҗдёӘдҪҚзҪ®гҖӮ
ж•°з»„е’Ңй“ҫиЎЁжңүеҗ„иҮӘзҡ„дјҳзјәзӮ№пјҢж•°з»„иғҪеӨҹж–№дҫҝе®ҡдҪҚеҲ°д»»дҪ•ж•°жҚ®йЎ№пјҢдҪҶжү©еұ•жҖ§иҫғе·®пјӣй“ҫиЎЁеҲҷж— жі•жҸҗдҫӣеҝ«жҚ·зҡ„ж•°жҚ®йЎ№е®ҡдҪҚпјҢдҪҶжҸ’е…Ҙе’ҢеҲ йҷӨд»»ж„ҸдёҖдёӘж•°жҚ®йЎ№йғҪеҫҲз®ҖеҚ•гҖӮеҪ“йңҖиҰҒеӨ„зҗҶеӨ§и§„жЁЎзҡ„ж•°жҚ®йӣҶеҗҲж—¶пјҢйҖҡеёёйңҖиҰҒе°Ҷж•°з»„е’Ңй“ҫиЎЁзҡ„дјҳзӮ№з»“еҗҲгҖӮйҖҡиҝҮз»“еҗҲж•°з»„е’Ңй“ҫиЎЁзҡ„дјҳзӮ№пјҢе“ҲеёҢиЎЁиғҪеӨҹиҫҫеҲ°иҫғеҘҪзҡ„жү©еұ•жҖ§е’Ңиҫғй«ҳзҡ„и®ҝй—®ж•ҲзҺҮгҖӮ
иҷҪ然жҜҸдёӘејҖеҸ‘иҖ…йғҪеҸҜд»Ҙжһ„е»әиҮӘе·ұзҡ„е“ҲеёҢиЎЁпјҢдҪҶе“ҲеёҢиЎЁйғҪжңүе…ұеҗҢзҡ„еҹәжң¬з»“жһ„пјҢеҰӮдёӢпјҡ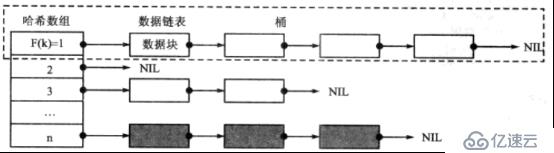
е“ҲеёҢж•°з»„дёӯжҜҸдёӘйЎ№йғҪжңүжҢҮй’ҲжҢҮеҗ‘дёҖдёӘе°Ҹзҡ„й“ҫиЎЁпјҢдёҺжҹҗйЎ№зӣёе…ізҡ„жүҖжңүж•°жҚ®иҠӮзӮ№йғҪдјҡиў«еӯҳеӮЁеңЁй“ҫиЎЁдёӯгҖӮеҪ“зЁӢеәҸйңҖиҰҒи®ҝй—®жҹҗдёӘж•°жҚ®иҠӮзӮ№ж—¶пјҢдёҚйңҖиҰҒйҒҚеҺҶж•ҙдёӘе“ҲеёҢиЎЁпјҢиҖҢжҳҜе…ҲжүҫеҲ°ж•°з»„дёӯзҡ„йЎ№пјҢ然еҗҺжҹҘиҜўеӯҗй“ҫиЎЁжүҫеҲ°зӣ®ж ҮиҠӮзӮ№гҖӮжҜҸдёӘеӯҗй“ҫиЎЁз§°дёәдёҖдёӘжЎ¶пјҲBucketпјүпјҢеҰӮдҪ•е®ҡдҪҚдёҖдёӘеӯҳеӮЁзӣ®ж ҮиҠӮзӮ№зҡ„жЎ¶пјҢз”ұж•°жҚ®иҠӮзӮ№зҡ„е…ій”®еӯ—еҹҹKeyе’Ңе“ҲеёҢеҮҪж•°е…ұеҗҢзЎ®е®ҡпјҢиҷҪ然еӯҳеңЁеӨҡз§Қжҳ е°„ж–№жі•пјҢдҪҶе®һзҺ°е“ҲеёҢеҮҪж•°жңҖеёёз”Ёзҡ„ж–№жі•иҝҳжҳҜйҷӨжі•жҳ е°„гҖӮйҷӨжі•еҮҪж•°зҡ„еҪўејҸеҰӮдёӢпјҡFпјҲkпјү = k % D
kжҳҜж•°жҚ®иҠӮзӮ№зҡ„е…ій”®еӯ—пјҢDжҳҜйў„е…Ҳи®ҫи®Ўзҡ„еёёйҮҸпјҢFпјҲkпјүжҳҜжЎ¶зҡ„еәҸеҸ·пјҲзӯүеҗҢдәҺе“ҲеёҢж•°з»„дёӯжҜҸдёӘйЎ№зҡ„дёӢж ҮпјүпјҢе“ҲеёҢиЎЁе®һзҺ°еҰӮдёӢпјҡ
// ж•°жҚ®иҠӮзӮ№е®ҡд№ү
template <class E, class Key>
class LinkNode
{
public:
LinkNode(const E& e, const Key& k): pNext(NULL), pPrev(NULL)
{
data = e;
key = k;
}
void setNextNode(LinkNode<E, Key>* next)
{
pNext = next;
}
LinkNode<E, Key>* Next()const
{
return pNext;
}
void setPrevNode(LinkNode<E, Key>* prev)
{
pPrev = prev;
}
LinkNode<E, Key>* Prev()const
{
return pPrev;
}
E& getData()const
{
return data;
}
Key& getKey()const
{
return key;
}
private:
// жҢҮй’Ҳеҹҹ
LinkNode<E, Key>* pNext;
LinkNode<E, Key>* pPrev;
// ж•°жҚ®еҹҹ
E data;// ж•°жҚ®
Key key;//е…ій”®еӯ—
};
// е“ҲеёҢиЎЁе®ҡд№ү
template <class E, class Key>
class HashTable
{
private:
typedef LinkNode<E, Key>* LinkNodePtr;
LinkNodePtr* hashArray;// е“ҲеёҢж•°з»„
int size;// е“ҲеёҢж•°з»„еӨ§е°Ҹ
public:
HashTable(int n = 100);
~HashTable();
bool Insert(const E& data);
bool Delete(const Key& k);
bool Search(const Key& k, E& ret)const;
private:
LinkNodePtr searchNode()const;
// е“ҲеёҢеҮҪж•°
int HashFunc(const Key& k)
{
return k % size;
}
};
// е“ҲеёҢиЎЁзҡ„жһ„йҖ еҮҪж•°
template <class E, class Key>
HashTable<E, Key>::HashTable(int n)
{
size = n;
hashArray = new LinkNodePtr[size];
memset(hashArray, 0, size * sizeof(LinkNodePtr));
}
// е“ҲеёҢиЎЁзҡ„жһҗжһ„еҮҪж•°S
template <class E, class Key>
HashTable<E, Key>::~HashTable()
{
for(int i = 0; i < size; i++)
{
if(hashArray[i] != NULL)
{
// йҮҠж”ҫжҜҸдёӘжЎ¶зҡ„еҶ…еӯҳ
LinkNodePtr p = hashArray[i];
while(p)
{
LinkNodePtr toDel = p;
p = p->Next();
delete toDel;
}
}
}
delete [] hashArray;
}еҲҶжһҗд»Јз ҒпјҢе“ҲеёҢеҮҪж•°еҶіе®ҡдәҶдёҖдёӘе“ҲеёҢиЎЁзҡ„ж•ҲзҺҮе’ҢжҖ§иғҪгҖӮ
еҪ“FпјҲkпјү=kж—¶пјҢе“ҲеёҢиЎЁдёӯзҡ„жҜҸдёӘжЎ¶д»…жңүдёҖдёӘиҠӮзӮ№пјҢе“ҲеёҢиЎЁжҳҜдёҖдёӘдёҖз»ҙж•°з»„пјҢиҷҪ然жҜҸдёӘж•°жҚ®иҠӮзӮ№зҡ„жҢҮй’ҲдјҡйҖ жҲҗдёҖе®ҡзҡ„еҶ…еӯҳз©әй—ҙжөӘиҙ№пјҢдҪҶжҹҘжүҫж•ҲзҺҮжңҖй«ҳпјҲж—¶й—ҙеӨҚжқӮеәҰOпјҲ1пјүпјүгҖӮ
еҪ“FпјҲkпјү=cж—¶пјҢе“ҲеёҢиЎЁжүҖжңүзҡ„иҠӮзӮ№еӯҳж”ҫеңЁдёҖдёӘжЎ¶дёӯпјҢе“ҲеёҢиЎЁйҖҖеҢ–дёәй“ҫиЎЁпјҢеҗҢж—¶иҝҳеҠ дёҠдёҖдёӘеӨҡдҪҷзҡ„гҖҒеҹәжң¬дёәз©әзҡ„ж•°з»„пјҢжҹҘжүҫдёҖдёӘиҠӮзӮ№зҡ„ж—¶й—ҙж•ҲзҺҮдёәOпјҲnпјүпјҢж•ҲзҺҮжңҖдҪҺгҖӮ
еӣ жӯӨпјҢжһ„е»әдёҖдёӘзҗҶжғізҡ„е“ҲеёҢиЎЁйңҖиҰҒе°ҪеҸҜиғҪзҡ„дҪҝз”Ёи®©ж•°жҚ®иҠӮзӮ№еҲҶй…ҚжӣҙеқҮеҢҖзҡ„е“ҲеёҢеҮҪж•°пјҢеҗҢж—¶е“ҲеёҢиЎЁзҡ„ж•°жҚ®з»“жһ„д№ҹжҳҜеҪұе“Қе…¶жҖ§иғҪзҡ„дёҖдёӘйҮҚиҰҒеӣ зҙ гҖӮдҫӢеҰӮпјҢжЎ¶зҡ„ж•°йҮҸеӨӘе°‘дјҡйҖ жҲҗе·ЁеӨ§зҡ„й“ҫиЎЁпјҢеҜјиҮҙжҹҘжүҫж•ҲзҺҮдҪҺдёӢпјҢеӨӘеӨҡзҡ„жЎ¶еҲҷдјҡеҜјиҮҙеҶ…еӯҳжөӘиҙ№гҖӮеӣ жӯӨпјҢеңЁи®ҫи®Ўе’Ңе®һзҺ°е“ҲеёҢиЎЁеүҚпјҢйңҖиҰҒеҲҶжһҗж•°жҚ®иҠӮзӮ№зҡ„е…ій”®еҖјпјҢж №жҚ®е…¶еҲҶеёғжқҘеҶіе®ҡйңҖиҰҒйҖ еӨҡеӨ§зҡ„е“ҲеёҢж•°з»„е’ҢдҪҝз”Ёд»Җд№Ҳж ·зҡ„е“ҲеёҢеҮҪж•°гҖӮ
е“ҲеёҢиЎЁзҡ„е®һзҺ°дёӯпјҢж•°жҚ®иҠӮзӮ№зҡ„з»„з»Үж–№ејҸеӨҡз§ҚеӨҡж ·пјҢ并дёҚеұҖйҷҗдәҺй“ҫиЎЁпјҢжЎ¶еҸҜд»ҘжҳҜдёҖжЈөж ‘пјҢд№ҹеҸҜд»ҘжҳҜдёҖдёӘе“ҲеёҢиЎЁгҖӮ
дәҢеҸүж ‘жҳҜдёҖз§Қеёёз”Ёж•°жҚ®з»“жһ„пјҢејҖеҸ‘дәәе‘ҳйҖҡеёёзҶҹзҹҘдәҢеҸүжҹҘжүҫж ‘гҖӮеңЁдёҖжЈөдәҢеҸүжҹҘжүҫж ‘дёӯпјҢжүҖжңүиҠӮзӮ№зҡ„е·ҰеӯҗиҠӮзӮ№зҡ„е…ій”®еҖјйғҪе°ҸдәҺзӯүдәҺжң¬иә«пјҢиҖҢеҸіеӯҗиҠӮзӮ№зҡ„е…ій”®еҖјеӨ§дәҺзӯүдәҺжң¬иә«гҖӮз”ұдәҺе№іиЎЎдәҢеҸүжҹҘжүҫж ‘дёҺжңүеәҸж•°з»„зҡ„жҠҳеҚҠжҹҘжүҫз®—жі•еҺҹзҗҶзӣёеҗҢпјҢжүҖд»ҘжҹҘиҜўж•ҲзҺҮиҰҒиҝңй«ҳдәҺй“ҫиЎЁпјҲOпјҲLog2nпјүпјүпјҢиҖҢй“ҫиЎЁдёәOпјҲnпјүгҖӮдҪҶз”ұдәҺж ‘дёӯжҜҸдёӘиҠӮзӮ№йғҪиҰҒдҝқеӯҳдёӨдёӘжҢҮеҗ‘еӯҗиҠӮзӮ№зҡ„жҢҮй’ҲпјҢз©әй—ҙд»Јд»·иҰҒиҝңй«ҳдәҺеҚ•еҗ‘й“ҫиЎЁе’Ңж•°з»„пјҢе№¶дё”ж ‘дёӯжҜҸдёӘиҠӮзӮ№зҡ„еҶ…еӯҳеҲҶй…ҚжҳҜдёҚиҝһз»ӯзҡ„пјҢеҜјиҮҙеҶ…еӯҳзўҺзүҮеҢ–гҖӮдҪҶдәҢеҸүж ‘еңЁжҸ’е…ҘгҖҒеҲ йҷӨд»ҘеҸҠжҹҘжүҫзӯүж“ҚдҪңдёҠзҡ„иүҜеҘҪиЎЁзҺ°дҪҝе…¶жҲҗдёәжңҖеёёз”Ёзҡ„ж•°жҚ®з»“жһ„д№ӢдёҖгҖӮдәҢеҸүж ‘зҡ„й“ҫиЎЁе®һзҺ°еҰӮдёӢпјҡ
template <class T>
class TreeNode
{
public:
TreeNode(const TreeNode& e): left(NULL), right(NULL)
{
data = e;
}
TreeNode<T>* Left()const
{
return left;
}
TreeNode<T>* Right()const
{
return right;
}
private:
T data;
TreeNode<T>* left;
TreeNode<T>* right;
};йҒҚеҺҶж•°з»„зҡ„ж“ҚдҪңеҫҲз®ҖеҚ•пјҢж— и®әжҳҜйЎәеәҸиҝҳжҳҜйҖҶеәҸйғҪеҸҜд»ҘйҒҚеҺҶж•°з»„пјҢд№ҹеҸҜд»Ҙд»»ж„ҸдҪҚзҪ®ејҖе§ӢйҒҚеҺҶж•°з»„гҖӮ
и·ҹиёӘжҢҮй’ҲдҫҝиғҪе®ҢжҲҗй“ҫиЎЁзҡ„йҒҚеҺҶпјҡ
LinkNode<E>* pNode = pFirst;
while(pNode)
{
pNode = pNode->Next();
// do something
}еҸҢеҗ‘й“ҫиЎЁеҸҜд»Ҙж”ҜжҢҒйЎәеәҸе’ҢйҖҶеәҸйҒҚеҺҶпјҢи·іиҪ¬й“ҫиЎЁйҖҡиҝҮиҝҮж»Өжҹҗдәӣж— з”ЁиҠӮзӮ№еҸҜд»Ҙе®һзҺ°еҝ«йҖҹйҒҚеҺҶгҖӮ
еҰӮжһңйў„е…ҲзҹҘйҒ“жүҖжңүиҠӮзӮ№зҡ„KeyеҖјпјҢеҸҜд»ҘйҖҡиҝҮKeyеҖје’Ңе“ҲеёҢеҮҪж•°жүҫеҲ°жҜҸдёҖдёӘйқһз©әзҡ„жЎ¶пјҢ然еҗҺйҒҚеҺҶжЎ¶зҡ„й“ҫиЎЁгҖӮеҗҰеҲҷеҸӘиғҪйҖҡиҝҮйҒҚеҺҶе“ҲеёҢж•°з»„зҡ„ж–№ејҸйҒҚеҺҶжҜҸдёӘжЎ¶гҖӮ
for(int i = 0; i < size; i++)
{
LinkNodePtr pNode = hashArray[i];
while(pNode) != NULL)
{
// do something
pNode = pNode->Next();
}
}йҒҚеҺҶдәҢеҸүж ‘з”ұдёүз§Қж–№ејҸпјҡеүҚеәҸпјҢдёӯеәҸпјҢеҗҺеәҸпјҢдёүз§ҚйҒҚеҺҶж–№ејҸзҡ„йҖ’еҪ’е®һзҺ°еҰӮдёӢпјҡ
// еүҚеәҸйҒҚеҺҶ
template <class E>
void PreTraverse(TreeNode<E>* pNode)
{
if(pNode != NULL)
{
// do something
doSothing(pNode);
PreTraverse(pNode->Left());
PreTraverse(pNode->Right());
}
}
// дёӯеәҸйҒҚеҺҶ
template <class E>
void InTraverse(TreeNode<E>* pNode)
{
if(pNode != NULL)
{
InTraverse(pNode->Left());
// do something
doSothing(pNode);
InTraverse(pNode->Right());
}
}
// еҗҺеәҸйҒҚеҺҶ
template <class E>
void PostTraverse(TreeNode<E>* pNode)
{
if(pNode != NULL)
{
PostTraverse(pNode->Left());
PostTraverse(pNode->Right());
// do something
doSothing(pNode);
}
}дҪҝз”ЁйҖ’еҪ’ж–№ејҸеҜ№дәҢеҸүж ‘иҝӣиЎҢйҒҚеҺҶзҡ„зјәзӮ№дё»иҰҒжҳҜйҡҸзқҖж ‘зҡ„ж·ұеәҰеўһеҠ пјҢзЁӢеәҸеҜ№еҮҪж•°ж Ҳз©әй—ҙзҡ„дҪҝз”Ёи¶ҠжқҘи¶ҠеӨҡпјҢз”ұдәҺж Ҳз©әй—ҙзҡ„еӨ§е°ҸжңүйҷҗпјҢйҖ’еҪ’ж–№ејҸйҒҚеҺҶеҸҜиғҪдјҡеҜјиҮҙеҶ…еӯҳиҖ—е°ҪгҖӮи§ЈеҶіеҠһжі•дё»иҰҒжңүдёӨдёӘпјҡдёҖжҳҜдҪҝз”ЁйқһйҖ’еҪ’з®—жі•е®һзҺ°еүҚеәҸгҖҒдёӯеәҸгҖҒеҗҺеәҸйҒҚеҺҶпјҢеҚід»ҝз…§йҖ’еҪ’з®—жі•жү§иЎҢж—¶еҮҪж•°е·ҘдҪңж Ҳзҡ„еҸҳеҢ–зҠ¶еҶөпјҢе»әз«ӢдёҖдёӘж ҲеҜ№еҪ“еүҚйҒҚеҺҶи·Ҝеҫ„дёҠзҡ„иҠӮзӮ№иҝӣиЎҢи®°еҪ•пјҢж №жҚ®ж ҲйЎ¶е…ғзҙ жҳҜеҗҰеӯҳеңЁе·ҰеҸіиҠӮзӮ№зҡ„дёҚеҗҢжғ…еҶөпјҢеҶіе®ҡдёӢдёҖжӯҘж“ҚдҪңпјҲе°ҶеӯҗиҠӮзӮ№е…Ҙж ҲжҲ–еҪ“еүҚиҠӮзӮ№йҖҖж ҲпјүпјҢд»ҺиҖҢе®ҢжҲҗдәҢеҸүж ‘зҡ„йҒҚеҺҶпјӣдәҢжҳҜдҪҝз”ЁзәҝзҙўдәҢеҸүж ‘пјҢеҚіж №жҚ®йҒҚеҺҶ规еҲҷпјҢеңЁжҜҸдёӘеҸ¶еӯҗиҠӮзӮ№еўһеҠ жҢҮеҗ‘еҗҺз»ӯиҠӮзӮ№зҡ„жҢҮй’ҲгҖӮ
з”ұдәҺж•°з»„дёӯзҡ„жүҖжңүж•°жҚ®иҠӮзӮ№йғҪдҝқеӯҳеңЁиҝһз»ӯзҡ„еҶ…еӯҳдёӯпјҢжүҖд»ҘжҸ’е…Ҙж–°зҡ„иҠӮзӮ№йңҖиҰҒ移еҠЁжҸ’е…ҘдҪҚзҪ®д№ӢеҗҺзҡ„жүҖжңүиҠӮзӮ№д»Ҙи…ҫеҮәз©әй—ҙпјҢжүҚиғҪжӯЈзЎ®ең°е°Ҷж–°иҠӮзӮ№еӨҚеҲ¶еҲ°жҸ’е…ҘдҪҚзҪ®гҖӮеҰӮжһңжҒ°еҘҪж•°з»„е·Іж»ЎпјҢиҝҳйңҖиҰҒйҮҚж–°е»әз«ӢдёҖдёӘж–°зҡ„е®№йҮҸжӣҙеӨ§зҡ„ж•°з»„пјҢе°ҶеҺҹж•°з»„зҡ„жүҖжңүиҠӮзӮ№жӢ·иҙқеҲ°ж–°ж•°з»„пјҢеӣ жӯӨж•°з»„зҡ„жҸ’е…Ҙж“ҚдҪңдёҺе…¶е®ғж•°жҚ®з»“жһ„зӣёжҜ”пјҢж—¶й—ҙеӨҚжқӮеәҰжӣҙй«ҳгҖӮ
еҰӮжһңеҗ‘дёҖдёӘжңӘж»Ўзҡ„ж•°з»„жҸ’е…ҘиҠӮзӮ№пјҢжңҖеҘҪзҡ„жғ…еҶөжҳҜжҸ’е…ҘеҲ°ж•°з»„зҡ„жң«е°ҫпјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜOпјҲ1пјүпјҢжңҖеқҸжғ…еҶөжҳҜжҸ’е…ҘеҲ°ж•°з»„еӨҙйғЁпјҢйңҖиҰҒ移еҠЁж•°з»„зҡ„жүҖжңүиҠӮзӮ№пјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜOпјҲnпјүгҖӮ
еҰӮжһңеҗ‘дёҖдёӘж»Ўж•°з»„жҸ’е…ҘиҠӮзӮ№пјҢйҖҡеёёеҒҡжі•жҳҜе…ҲеҲӣе»әдёҖдёӘжӣҙеӨ§зҡ„ж•°з»„пјҢ然еҗҺе°ҶеҺҹж•°з»„зҡ„жүҖжңүиҠӮзӮ№жӢ·иҙқеҲ°ж–°ж•°з»„пјҢеҗҢж—¶жҸ’е…Ҙж–°иҠӮзӮ№пјҢжңҖеҗҺеҲ йҷӨе…ғж•°з»„пјҢж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲnпјүгҖӮеңЁеҲ йҷӨе…ғж•°з»„д№ӢеүҚпјҢдёӨдёӘж•°з»„еҝ…须并еӯҳдёҖж®өж—¶й—ҙпјҢз©әй—ҙејҖй”ҖиҫғеӨ§гҖӮ
еңЁй“ҫиЎЁдёӯжҸ’е…ҘдёҖдёӘж–°иҠӮзӮ№еҫҲз®ҖеҚ•пјҢеҜ№дәҺеҚ•й“ҫиЎЁеҸӘйңҖиҰҒдҝ®ж”№жҸ’е…ҘдҪҚзҪ®д№ӢеүҚиҠӮзӮ№зҡ„pNextжҢҮй’ҲдҪҝе…¶жҢҮеҗ‘жң¬иҠӮзӮ№пјҢ然еҗҺе°Ҷжң¬иҠӮзӮ№зҡ„pNextжҢҮй’ҲжҢҮеҗ‘дёӢдёҖдёӘиҠӮзӮ№еҚіеҸҜпјҲеҜ№дәҺй“ҫиЎЁеӨҙдёҚеӯҳеңЁдёҠдёҖдёӘиҠӮзӮ№пјҢеҜ№дәҺй“ҫиЎЁе°ҫдёҚеӯҳеңЁдёӢдёҖдёӘиҠӮзӮ№пјүгҖӮеҜ№дәҺеҸҢеҗ‘й“ҫиЎЁе’Ңи·іиҪ¬й“ҫиЎЁпјҢйңҖиҰҒдҝ®ж”№зӣёе…іиҠӮзӮ№зҡ„жҢҮй’ҲгҖӮй“ҫиЎЁзҡ„жҸ’е…Ҙж“ҚдҪңдёҺй•ҝеәҰж— е…іпјҢж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲ1пјүпјҢеҪ“然й“ҫиЎЁзҡ„жҸ’е…Ҙж“ҚдҪңйҖҡеёёдјҡдјҙйҡҸй“ҫиЎЁжҸ’е…ҘиҠӮзӮ№дҪҚзҪ®зҡ„е®ҡдҪҚпјҢйңҖиҰҒдёҖе®ҡж—¶й—ҙгҖӮ
еңЁе“ҲеёҢиЎЁдёӯжҸ’е…ҘдёҖдёӘиҠӮзӮ№йңҖиҰҒе®ҢжҲҗдёӨйғЁж“ҚдҪңпјҢе®ҡдҪҚ桶并еҗ‘й“ҫиЎЁжҸ’е…ҘиҠӮзӮ№гҖӮ
template <class E, class Key>
bool HashTable<E, Key>::Insert(const E& data)
{
Key k = data;// жҸҗеҸ–е…ій”®еӯ—
// еҲӣе»әдёҖдёӘж–°иҠӮзӮ№
LinkNodePtr pNew = new LinkNodePtr(data, k);
int index = HashFunc(k);//е®ҡдҪҚжЎ¶
LinkNodePtr p = hashArray[index];
// еҰӮжһңжҳҜз©әжЎ¶пјҢзӣҙжҺҘжҸ’е…Ҙ
if(NULL == p)
{
hashArray[index] = pNew;
return true;
}
// еңЁиЎЁеӨҙжҸ’е…ҘиҠӮзӮ№
hashArray[index] = pNew;
pNew->SetNextNode(p);
p->SetPrevNode(pNew);
return true;
}е“ҲеёҢиЎЁжҸ’е…Ҙж“ҚдҪңзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲ1пјүпјҢеҰӮжһңжЎ¶зҡ„й“ҫиЎЁжҳҜжңүеәҸзҡ„пјҢйңҖиҰҒиҠұж—¶й—ҙе®ҡдҪҚй“ҫиЎЁдёӯжҸ’е…Ҙзҡ„дҪҚзҪ®пјҢеҰӮжһңй“ҫиЎЁй•ҝеәҰдёәMпјҢеҲҷж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲMпјүгҖӮ
дәҢеҸүж ‘зҡ„з»“жһ„зӣҙжҺҘеҪұе“ҚжҸ’е…Ҙж“ҚдҪңзҡ„ж•ҲзҺҮпјҢеҜ№дәҺе№іиЎЎдәҢеҸүжҹҘжүҫж ‘пјҢжҸ’е…ҘиҠӮзӮ№зҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲLog2NпјүгҖӮеҜ№дәҺйқһе№іиЎЎдәҢеҸүж ‘пјҢжҸ’е…ҘиҠӮзӮ№зҡ„ж—¶й—ҙеӨҚжқӮеәҰжҜ”иҫғй«ҳпјҢеңЁжңҖеқҸжғ…еҶөдёӢпјҢйқһе№іиЎЎдәҢеҸүж ‘жүҖжңүзҡ„leftиҠӮзӮ№йғҪдёәNULLпјҢдәҢеҸүж ‘йҖҖеҢ–дёәй“ҫиЎЁпјҢжҸ’е…ҘиҠӮзӮ№ж–°иҠӮзӮ№зҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲnпјүгҖӮ
еҪ“иҠӮзӮ№ж•°йҮҸеҫҲеӨҡж—¶пјҢеҜ№е№іиЎЎдәҢеҸүж ‘дёӯиҝӣиЎҢжҸ’е…Ҙж“ҚдҪңзҡ„ж•ҲзҺҮиҰҒиҝңй«ҳдәҺйқһе№іиЎЎдәҢеҸүж ‘гҖӮе·ҘзЁӢејҖеҸ‘дёӯпјҢйҖҡеёёйҒҝе…Қйқһе№іиЎЎдәҢеҸүж ‘зҡ„еҮәзҺ°пјҢжҲ–жҳҜе°Ҷйқһе№іиЎЎдәҢеҸүж ‘иҪ¬жҚўдёәе№іиЎЎдәҢеҸүж ‘гҖӮз®ҖеҚ•еҒҡжі•еҰӮдёӢпјҡ
пјҲ1пјүдёӯеәҸйҒҚеҺҶйқһе№іиЎЎдәҢеҸүж ‘пјҢеңЁдёҖдёӘж•°з»„дёӯдҝқеӯҳжүҖжңүзҡ„иҠӮзӮ№зҡ„жҢҮй’ҲгҖӮ
пјҲ2пјүз”ұдәҺж•°з»„дёӯжүҖжңүе…ғзҙ йғҪжҳҜжңүеәҸжҺ’еҲ—зҡ„пјҢеҸҜд»ҘдҪҝз”ЁжҠҳеҚҠжҹҘжүҫйҒҚеҺҶж•°з»„пјҢиҮӘдёҠиҖҢдёӢйҖҗеұӮжһ„е»әе№іиЎЎдәҢеҸүж ‘гҖӮ
д»Һж•°з»„дёӯеҲ йҷӨиҠӮзӮ№пјҢеҰӮжһңйңҖиҰҒж•°з»„жІЎжңүз©әжҙһпјҢйңҖиҰҒеңЁеҲ йҷӨиҠӮзӮ№еҗҺе°Ҷе…¶еҗҺжүҖжңүиҠӮзӮ№еҗ‘еүҚ移еҠЁгҖӮжңҖеқҸжғ…еҶөдёӢпјҲеҲ йҷӨйҰ–иҠӮзӮ№пјүпјҢж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲnпјүпјҢжңҖеҘҪжғ…еҶөдёӢпјҲеҲ йҷӨе°ҫиҠӮзӮ№пјүпјҢж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲ1пјүгҖӮ
еңЁжҹҗдәӣеңәеҗҲпјҲеҰӮеҠЁжҖҒж•°з»„пјүпјҢеҪ“еҲ йҷӨе®ҢжҲҗеҗҺеҰӮжһңж•°з»„дёӯеӯҳеңЁеӨ§йҮҸз©әй—ІдҪҚзҪ®пјҢеҲҷйңҖиҰҒзј©е°Ҹж•°з»„пјҢеҚіеҲӣе»әдёҖдёӘиҫғе°Ҹзҡ„ж–°ж•°з»„пјҢе°ҶеҺҹж•°з»„дёӯжүҖжңүиҠӮзӮ№жӢ·иҙқеҲ°ж–°ж•°з»„пјҢеҶҚе°ҶеҺҹж•°з»„еҲ йҷӨгҖӮеӣ жӯӨпјҢдјҡеҜјиҮҙиҫғеӨ§зҡ„з©әй—ҙдёҺж—¶й—ҙејҖй”ҖпјҢеә”и°Ёж…Һи®ҫзҪ®ж•°з»„зҡ„еӨ§е°ҸпјҢеҚіиҰҒе°ҪйҮҸйҒҝе…ҚеҶ…еӯҳз©әй—ҙзҡ„жөӘиҙ№д№ҹиҰҒеҮҸе°‘ж•°з»„зҡ„ж”ҫеӨ§жҲ–зј©е°Ҹж“ҚдҪңгҖӮйҖҡеёёпјҢжҜҸеҪ“йңҖиҰҒеҲ йҷӨж•°з»„дёӯзҡ„жҹҗдёӘиҠӮзӮ№ж—¶пјҢ并дёҚе°Ҷе…¶зңҹжӯЈеҲ йҷӨпјҢиҖҢжҳҜеңЁиҠӮзӮ№зҡ„дҪҚзҪ®и®ҫи®ЎдёҖдёӘж Үи®°дҪҚbDeleteпјҢе°Ҷе…¶и®ҫзҪ®дёәtrueпјҢеҗҢж—¶зҰҒжӯўе…¶е®ғзЁӢеәҸдҪҝз”Ёжң¬иҠӮзӮ№пјҢеҫ…ж•°з»„дёӯйңҖиҰҒеҲ йҷӨзҡ„иҠӮзӮ№иҫҫеҲ°дёҖе®ҡйҳҲеҖјж—¶пјҢеҶҚз»ҹдёҖеҲ йҷӨпјҢйҒҝе…ҚеӨҡ次移еҠЁиҠӮзӮ№ж“ҚдҪңпјҢйҷҚдҪҺж—¶й—ҙеӨҚжқӮеәҰгҖӮ
й“ҫиЎЁдёӯеҲ йҷӨиҠӮзӮ№зҡ„ж“ҚдҪңпјҢзӣҙжҺҘе°Ҷиў«еҲ йҷӨиҠӮзӮ№зҡ„дёҠдёҖиҠӮзӮ№зҡ„жҢҮй’ҲжҢҮеҗ‘иў«еҲ йҷӨиҠӮзӮ№зҡ„дёӢдёҖиҠӮзӮ№еҚіеҸҜпјҢеҲ йҷӨж“ҚдҪңзҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜOпјҲ1пјүгҖӮ
д»Һе“ҲеёҢиЎЁдёӯеҲ йҷӨдёҖдёӘиҠӮзӮ№зҡ„ж“ҚдҪңеҰӮдёӢпјҡйҰ–е…ҲйҖҡиҝҮе“ҲеёҢеҮҪж•°е’Ңй“ҫиЎЁйҒҚеҺҶпјҲжЎ¶з”ұй“ҫиЎЁе®һзҺ°пјүжүҫеҲ°еҫ…еҲ йҷӨиҠӮзӮ№пјҢ然еҗҺеҲ йҷӨиҠӮзӮ№е№¶йҮҚж–°и®ҫзҪ®еүҚеҗ‘е’ҢеҗҺеҗ‘жҢҮй’ҲгҖӮеҰӮжһңиў«еҲ йҷӨиҠӮзӮ№жҳҜжЎ¶зҡ„йҰ–иҠӮзӮ№пјҢеҲҷе°ҶжЎ¶зҡ„еӨҙжҢҮй’ҲжҢҮеҗ‘еҗҺз»ӯиҠӮзӮ№гҖӮ
template <class E, class Key>
bool HashTable<E, Key>::Delete(const Key& k)
{
// жүҫеҲ°е…ій”®еҖјеҢ№й…Қзҡ„иҠӮзӮ№
LinkNodePtr p = SearchNode(k);
if(NULL == p)
{
return false;
}
// дҝ®ж”№еүҚеҗ‘иҠӮзӮ№е’ҢеҗҺеҗ‘иҠӮзӮ№зҡ„жҢҮй’Ҳ
LinkNodePtr pPrev = p->Prev();
if(pPrev)
{
LinkNodePtr pNext = p->Next();
if(pNext)
{
pNext->SetPrevNode(pPrev);
pPrev->SetNextNode(pNext);
}
else
{
// еҰӮжһңеүҚеҗ‘иҠӮзӮ№дёәNULLпјҢеҲҷеҪ“еүҚиҠӮзӮ№pдёәйҰ–иҠӮзӮ№
// дҝ®ж”№е“ҲеёҢж•°з»„дёӯзҡ„иҠӮзӮ№зҡ„жҢҮй’ҲпјҢдҪҝе…¶жҢҮеҗ‘еҗҺеҗ‘иҠӮзӮ№гҖӮ
int index = HashFunc(k);
hashArray[index] = p->Next();
if(p->Next() != NULL)
{
p->Next()->SetPrevNode(NULL);
}
}
}
delete p;
return true;
}д»ҺдәҢеҸүж ‘еҲ йҷӨдёҖдёӘиҠӮзӮ№йңҖиҰҒж №жҚ®жғ…еҶөи®Ёи®әпјҡ
пјҲ1пјүеҰӮжһңиҠӮзӮ№жҳҜеҸ¶еӯҗиҠӮзӮ№пјҢзӣҙжҺҘеҲ йҷӨгҖӮ
пјҲ2пјүеҰӮжһңеҲ йҷӨиҠӮзӮ№д»…жңүдёҖдёӘеӯҗиҠӮзӮ№пјҢеҲҷе°ҶеӯҗиҠӮзӮ№жӣҝжҚўиў«еҲ йҷӨиҠӮзӮ№гҖӮ
пјҲ3пјүеҰӮжһңеҲ йҷӨиҠӮзӮ№зҡ„е·ҰеҸіеӯҗиҠӮзӮ№йғҪеӯҳеңЁпјҢз”ұдәҺжҜҸдёӘеӯҗиҠӮзӮ№йғҪеҸҜиғҪжңүиҮӘе·ұзҡ„еӯҗж ‘пјҢйңҖиҰҒжүҫеҲ°еӯҗж ‘дёӯеҗҲйҖӮзҡ„иҠӮзӮ№пјҢ并е°Ҷе…¶з«Ӣдёәж–°зҡ„ж №иҠӮзӮ№пјҢ并ж•ҙеҗҲдёӨжЈөеӯҗж ‘пјҢйҮҚж–°еҠ е…ҘеҲ°еҺҹдәҢеҸүж ‘гҖӮ
ж•°з»„зҡ„жҺ’еәҸеҢ…жӢ¬еҶ’жіЎгҖҒйҖүжӢ©гҖҒжҸ’е…ҘзӯүжҺ’еәҸж–№жі•гҖӮ
template <typename T>
void Swap(T& a, T& b)
{
T temp;
temp = a;
a = b;
b = temp;
}еҶ’жіЎжҺ’еәҸе®һзҺ°пјҡ
/**********************************************
* жҺ’еәҸж–№ејҸпјҡеҶ’жіЎжҺ’еәҸ
* array:еәҸеҲ—
* lenпјҡеәҸеҲ—дёӯе…ғзҙ дёӘж•°
* min2maxпјҡжҢүд»Һе°ҸеҲ°еӨ§иҝӣиЎҢжҺ’еәҸ
* *******************************************/
template <typename T>
static void Bubble(T array[], int len, bool min2max = true)
{
bool exchange = true;
//йҒҚеҺҶжүҖжңүе…ғзҙ
for(int i = 0; (i < len) && exchange; i++)
{
exchange = false;
//е°Ҷе°ҫйғЁе…ғзҙ дёҺеүҚйқўзҡ„жҜҸдёӘе…ғзҙ дҪңжҜ”иҫғдәӨжҚў
for(int j = len - 1; j > i; j--)
{
if(min2max?(array[j] < array[j-1]):(array[j] > array[j-1]))
{
//дәӨжҚўе…ғзҙ дҪҚзҪ®
Swap(array[j], array[j-1]);
exchange = true;
}
}
}
}еҶ’жіЎжҺ’еәҸзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲn^2пјүпјҢеҶ’жіЎжҺ’еәҸжҳҜзЁіе®ҡзҡ„жҺ’еәҸж–№жі•гҖӮ
йҖүжӢ©жҺ’еәҸе®һзҺ°пјҡ
/******************************************
* жҺ’еәҸж–№ејҸпјҡйҖүжӢ©жҺ’еәҸ
* array:еәҸеҲ—
* lenпјҡеәҸеҲ—дёӯе…ғзҙ дёӘж•°
* min2maxпјҡжҢүд»Һе°ҸеҲ°еӨ§иҝӣиЎҢжҺ’еәҸ
* ***************************************/
template <typename T>
void Select(T array[], int len, bool min2max = true)
{
for(int i = 0; i < len; i++)
{
int min = i;//д»Һ第iдёӘе…ғзҙ ејҖе§Ӣ
//еҜ№еҫ…жҺ’еәҸзҡ„е…ғзҙ иҝӣиЎҢжҜ”иҫғ
for(int j = i + 1; j < len; j++)
{
//жҢүжҺ’еәҸзҡ„ж–№ејҸйҖүжӢ©жҜ”иҫғж–№ејҸ
if(min2max?(array[min] > array[j]):(array[min] < array[j]))
{
min = j;
}
}
if(min != i)
{
//е…ғзҙ дәӨжҚў
Swap(array[i], array[min]);
}
}
}йҖүжӢ©жҺ’еәҸзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲn^2пјүпјҢйҖүжӢ©жҺ’еәҸжҳҜдёҚзЁіе®ҡзҡ„жҺ’еәҸж–№жі•гҖӮ
жҸ’е…ҘжҺ’еәҸе®һзҺ°пјҡ
/******************************************
* жҺ’еәҸж–№ејҸпјҡйҖүжӢ©жҺ’еәҸ
* array:еәҸеҲ—
* lenпјҡеәҸеҲ—дёӯе…ғзҙ дёӘж•°
* min2maxпјҡжҢүд»Һе°ҸеҲ°еӨ§иҝӣиЎҢжҺ’еәҸ
* ***************************************/
template <typename T>
void Select(T array[], int len, bool min2max = true)
{
for(int i = 0; i < len; i++)
{
int min = i;//д»Һ第iдёӘе…ғзҙ ејҖе§Ӣ
//еҜ№еҫ…жҺ’еәҸзҡ„е…ғзҙ иҝӣиЎҢжҜ”иҫғ
for(int j = i + 1; j < len; j++)
{
//жҢүжҺ’еәҸзҡ„ж–№ејҸйҖүжӢ©жҜ”иҫғж–№ејҸ
if(min2max?(array[min] > array[j]):(array[min] < array[j]))
{
min = j;
}
}
if(min != i)
{
//е…ғзҙ дәӨжҚў
Swap(array[i], array[min]);
}
}
}жҸ’е…ҘжҺ’еәҸзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲn^2пјүпјҢжҸ’е…ҘжҺ’еәҸжҳҜзЁіе®ҡзҡ„жҺ’еәҸж–№жі•гҖӮ
иҷҪ然й“ҫиЎЁеңЁжҸ’е…Ҙе’ҢеҲ йҷӨж“ҚдҪңдёҠжҖ§иғҪдјҳи¶ҠпјҢдҪҶжҺ’еәҸеӨҚжқӮеәҰеҚҙеҫҲй«ҳпјҢе°Өе…¶жҳҜеҚ•еҗ‘й“ҫиЎЁгҖӮз”ұдәҺй“ҫиЎЁдёӯи®ҝй—®жҹҗдёӘиҠӮзӮ№йңҖиҰҒдҫқиө–е…¶е®ғиҠӮзӮ№пјҢдёҚиғҪж №жҚ®дёӢж ҮзӣҙжҺҘе®ҡдҪҚеҲ°д»»ж„ҸдёҖйЎ№пјҢеӣ жӯӨиҠӮзӮ№е®ҡдҪҚзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲNпјүпјҢжҺ’еәҸж•ҲзҺҮдҪҺдёӢгҖӮ
е·ҘзЁӢејҖеҸ‘дёӯпјҢеҸҜд»ҘдҪҝз”Ёж•°з»„й“ҫиЎЁпјҢеҪ“йңҖиҰҒжҺ’еәҸж—¶жһ„йҖ дёҖдёӘж•°з»„пјҢеӯҳж”ҫй“ҫиЎЁдёӯжҜҸдёӘиҠӮзӮ№зҡ„жҢҮй’ҲгҖӮеңЁжҺ’еәҸиҝҮзЁӢдёӯйҖҡиҝҮж•°з»„е®ҡдҪҚжҜҸдёӘиҠӮзӮ№пјҢ并е®һзҺ°иҠӮзӮ№зҡ„дәӨжҚўгҖӮ
й“ҫиЎЁж•°з»„дёәзӣҙжҺҘи®ҝй—®й“ҫиЎЁзҡ„иҠӮзӮ№жҸҗдҫӣдәҶдҫҝеҲ©пјҢдҪҶжҳҜдҪҝз”Ёз©әй—ҙжҚўж—¶й—ҙзҡ„ж–№жі•пјҢеҰӮжһңеёҢжңӣеҫ—еҲ°дёҖдёӘжңүеәҸй“ҫиЎЁпјҢжңҖеҘҪжҳҜеңЁжһ„е»әй“ҫиЎЁж—¶е°ҶжҜҸдёӘиҠӮзӮ№жҸ’е…ҘеҲ°еҗҲйҖӮзҡ„дҪҚзҪ®гҖӮ
з”ұдәҺйҮҮз”Ёе“ҲеёҢеҮҪж•°и®ҝй—®жҜҸдёӘжЎ¶пјҢеӣ жӯӨе“ҲеёҢиЎЁдёӯеҜ№е“ҲеёҢж•°з»„жҺ’еәҸжҜ«ж— ж„Ҹд№үпјҢдҪҶе…·дҪ“иҠӮзӮ№зҡ„е®ҡдҪҚйңҖиҰҒйҖҡиҝҮжҹҘиҜўжҜҸдёӘжЎ¶й“ҫиЎЁе®ҢжҲҗпјҲжЎ¶з”ұй“ҫиЎЁе®һзҺ°пјүпјҢе°ҶжЎ¶зҡ„й“ҫиЎЁжҺ’еәҸеҸҜд»ҘжҸҗй«ҳиҠӮзӮ№зҡ„жҹҘиҜўж•ҲзҺҮгҖӮ
еҜ№дәҺдәҢеҸүжҹҘжүҫж ‘пјҢе…¶жң¬иә«жҳҜжңүеәҸзҡ„пјҢдёӯеәҸйҒҚеҺҶеҸҜд»Ҙеҫ—еҲ°дәҢеҸүжҹҘжүҫж ‘жңүеәҸзҡ„иҠӮзӮ№иҫ“еҮәгҖӮеҜ№дәҺжңӘжҺ’еәҸзҡ„дәҢеҸүж ‘пјҢжүҖжңүиҠӮзӮ№иў«йҡҸжңәз»„з»ҮпјҢе®ҡдҪҚиҠӮзӮ№зҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲNпјүгҖӮ
ж•°з»„зҡ„жңҖеӨ§дјҳзӮ№жҳҜеҸҜд»ҘйҖҡиҝҮдёӢж Үд»»ж„Ҹзҡ„и®ҝй—®иҠӮзӮ№пјҢиҖҢдёҚйңҖиҰҒеҖҹеҠ©жҢҮй’ҲгҖҒзҙўеј•жҲ–йҒҚеҺҶпјҢж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲ1пјүгҖӮеҜ№дәҺдёӢж ҮжңӘзҹҘзҡ„жғ…еҶөжҹҘжүҫиҠӮзӮ№пјҢеҲҷеҸӘиғҪйҒҚеҺҶж•°з»„пјҢж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲNпјүгҖӮеҜ№дәҺжңүеәҸж•°з»„пјҢжңҖеҘҪзҡ„жҹҘжүҫз®—жі•жҳҜдәҢеҲҶжҹҘжүҫжі•гҖӮ
template <class E>
int BinSearch(E array[], const E& value, int start, int end)
{
if(end - start < 0)
{
return INVALID_INPUT;
}
if(value == array[start])
{
return start;
}
if(value == array[end])
{
return end;
}
while(end > start + 1)
{
int temp = (end + start) / 2;
if(value == array[temp])
{
return temp;
}
if(array[temp] < value)
{
start = temp;
}
else
{
end = temp;
}
}
return -1;
}жҠҳеҚҠжҹҘжүҫзҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜOпјҲLog2NпјүпјҢдёҺдәҢеҸүж ‘жҹҘиҜўж•ҲзҺҮзӣёеҗҢгҖӮ
еҜ№дәҺд№ұеәҸж•°з»„пјҢеҸӘиғҪйҖҡиҝҮйҒҚеҺҶж–№жі•жҹҘжүҫиҠӮзӮ№пјҢе·ҘзЁӢејҖеҸ‘дёӯйҖҡеёёи®ҫзҪ®дёҖдёӘж ҮиҜҶеҸҳйҮҸдҝқеӯҳжӣҙж–°иҠӮзӮ№зҡ„дёӢж ҮпјҢжү§иЎҢжҹҘиҜўж—¶д»Һж ҮиҜҶеҸҳйҮҸж Үи®°зҡ„дёӢж ҮејҖе§ӢйҒҚеҺҶж•°з»„пјҢжү§иЎҢж•ҲзҺҮжҜ”д»ҺеӨҙејҖе§ӢиҰҒй«ҳгҖӮ
еҜ№дәҺеҚ•еҗ‘й“ҫиЎЁпјҢжңҖе·®жғ…еҶөдёӢйңҖиҰҒйҒҚеҺҶж•ҙдёӘй“ҫиЎЁжүҚиғҪжүҫеҲ°йңҖиҰҒзҡ„иҠӮзӮ№пјҢж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲNпјүгҖӮ
еҜ№дәҺжңүеәҸй“ҫиЎЁпјҢеҸҜд»Ҙйў„е…ҲиҺ·еҸ–жҹҗдәӣиҠӮзӮ№зҡ„ж•°жҚ®пјҢеҸҜд»ҘйҖүжӢ©дёҺзӣ®ж Үж•°жҚ®жңҖжҺҘиҝ‘зҡ„дёҖдёӘиҠӮзӮ№жҹҘжүҫпјҢж•ҲзҺҮеҸ–еҶідәҺе·ІзҹҘиҠӮзӮ№еңЁй“ҫиЎЁдёӯзҡ„еҲҶеёғпјҢеҜ№дәҺеҸҢеҗ‘жңүеәҸй“ҫиЎЁж•ҲзҺҮдјҡжӣҙй«ҳпјҢеҰӮжһңжӯЈдёӯиҠӮзӮ№е·ІзҹҘпјҢеҲҷжҹҘиҜўзҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲN/2пјүгҖӮ
еҜ№дәҺи·іиҪ¬й“ҫиЎЁпјҢеҰӮжһңйў„е…ҲиғҪеӨҹж №жҚ®й“ҫиЎЁдёӯиҠӮзӮ№д№Ӣй—ҙзҡ„е…ізі»е»әз«ӢжҢҮй’Ҳе…іиҒ”пјҢжҹҘиҜўж•ҲзҺҮе°ҶеӨ§еӨ§жҸҗй«ҳгҖӮ
е“ҲеёҢиЎЁдёӯжҹҘиҜўзҡ„ж•ҲзҺҮдёҺжЎ¶зҡ„ж•°жҚ®з»“жһ„жңүе…ігҖӮжЎ¶з”ұй“ҫиЎЁе®һзҺ°пјҢеҲҷжҹҘиҜўж•ҲзҺҮе’Ңй“ҫиЎЁй•ҝеәҰжңүе…іпјҢж—¶й—ҙеӨҚжқӮеәҰдёәOпјҲMпјүгҖӮжҹҘжүҫз®—жі•е®һзҺ°еҰӮдёӢпјҡ
template <class E, class Key>
bool HashTable<E, Key>::SearchNode(const Key& k)const
{
int index = HashFunc(k);
// з©әжЎ¶пјҢзӣҙжҺҘиҝ”еӣһ
if(NULL == hashArray[index])
return NULL;
// йҒҚеҺҶжЎ¶зҡ„й“ҫиЎЁпјҢеҰӮжһңз”ұеҢ№й…ҚиҠӮзӮ№пјҢзӣҙжҺҘиҝ”еӣһгҖӮ
LinkNodePtr p = hashArray[index];
while(p)
{
if(k == p->GetKey())
return p;
p = p->Next();
}
}еңЁдәҢеҸүж ‘дёӯжҹҘжүҫиҠӮзӮ№дёҺж ‘зҡ„еҪўзҠ¶жңүе…ігҖӮеҜ№дәҺе№іиЎЎдәҢеҸүж ‘пјҢжҹҘжүҫж•ҲзҺҮдёәOпјҲLog2NпјүпјӣеҜ№дәҺе®Ңе…ЁдёҚе№іиЎЎзҡ„дәҢеҸүж ‘пјҢжҹҘжүҫж•ҲзҺҮдёәOпјҲNпјүпјӣ
е·ҘзЁӢејҖеҸ‘дёӯпјҢйҖҡеёёйңҖиҰҒжһ„е»әе°ҪйҮҸе№іиЎЎзҡ„дәҢеҸүж ‘д»ҘжҸҗй«ҳжҹҘиҜўж•ҲзҺҮпјҢдҪҶе№іиЎЎдәҢеҸүж ‘еҸ—жҸ’е…ҘгҖҒеҲ йҷӨж“ҚдҪңеҪұе“ҚеҫҲеӨ§пјҢжҸ’е…ҘжҲ–еҲ йҷӨиҠӮзӮ№еҗҺйңҖиҰҒи°ғж•ҙдәҢеҸүж ‘зҡ„з»“жһ„пјҢйҖҡеёёпјҢеҪ“дәҢеҸүж ‘зҡ„жҸ’е…ҘгҖҒеҲ йҷӨж“ҚдҪңеҫҲеӨҡж—¶пјҢдёҚйңҖиҰҒеңЁжҜҸж¬ЎжҸ’е…ҘгҖҒеҲ йҷӨж“ҚдҪңеҗҺйғҪи°ғж•ҙе№іиЎЎеәҰпјҢиҖҢжҳҜеңЁеҜҶйӣҶзҡ„жҹҘиҜўж“ҚдҪңеүҚз»ҹдёҖи°ғж•ҙдёҖж¬ЎгҖӮ
е·ҘзЁӢејҖеҸ‘дёӯпјҢж•°з»„жҳҜеёёз”Ёж•°жҚ®з»“жһ„пјҢеҰӮжһңеңЁзј–иҜ‘ж—¶е°ұзҹҘйҒ“ж•°з»„жүҖжңүзҡ„з»ҙж•°пјҢеҲҷеҸҜд»ҘйқҷжҖҒе®ҡд№үж•°з»„гҖӮйқҷжҖҒе®ҡд№үж•°з»„еҗҺпјҢж•°з»„еңЁеҶ…еӯҳдёӯеҚ жҚ®зҡ„з©әй—ҙеӨ§е°Ҹе’ҢдҪҚзҪ®жҳҜеӣәе®ҡзҡ„пјҢеҰӮжһңе®ҡд№үзҡ„жҳҜе…ЁеұҖж•°з»„пјҢзј–иҜ‘еҷЁе°ҶеңЁйқҷжҖҒж•°жҚ®еҢәдёәж•°з»„еҲҶй…Қз©әй—ҙпјҢеҰӮжһңжҳҜеұҖйғЁж•°з»„пјҢзј–иҜ‘еҷЁе°ҶеңЁж ҲдёҠдёәж•°з»„еҲҶй…Қз©әй—ҙгҖӮдҪҶеҰӮжһңйў„е…Ҳж— жі•зҹҘйҒ“ж•°з»„зҡ„з»ҙж•°пјҢзЁӢеәҸеҸӘжңүеңЁиҝҗиЎҢж—¶жүҚзҹҘйҒ“йңҖиҰҒеҲҶй…ҚеӨҡеӨ§зҡ„ж•°з»„пјҢжӯӨж—¶C++зј–иҜ‘еҷЁеҸҜд»ҘеңЁе ҶдёҠдёәж•°з»„еҠЁжҖҒеҲҶй…Қз©әй—ҙгҖӮ
еҠЁжҖҒж•°з»„зҡ„дјҳзӮ№еҰӮдёӢпјҡ
пјҲ1пјүеҸҜеҲҶй…Қз©әй—ҙиҫғеӨ§гҖӮж Ҳзҡ„еӨ§е°ҸйғҪжңүйҷҗеҲ¶пјҢLinuxзі»з»ҹеҸҜд»ҘдҪҝз”Ёulimit -sжҹҘзңӢпјҢйҖҡеёёдёә8KгҖӮејҖеҸ‘иҖ…иҷҪ然еҸҜд»Ҙи®ҫзҪ®пјҢдҪҶз”ұдәҺйңҖиҰҒдҝқиҜҒзЁӢеәҸиҝҗиЎҢж•ҲзҺҮпјҢйҖҡеёёдёҚе®ңеӨӘеӨ§гҖӮе Ҷз©әй—ҙзҡ„йҖҡеёёеҸҜдҫӣеҲҶй…ҚеҶ…еӯҳжҜ”иҫғеӨ§пјҢиҫҫеҲ°GBзә§еҲ«гҖӮ
пјҲ2пјүдҪҝз”ЁзҒөжҙ»гҖӮејҖеҸ‘дәәе‘ҳеҸҜд»Ҙж №жҚ®е®һйҷ…йңҖиҰҒеҶіе®ҡж•°з»„зҡ„еӨ§е°Ҹе’Ңз»ҙж•°гҖӮ
еҠЁжҖҒж•°з»„зҡ„зјәзӮ№еҰӮдёӢпјҡ
пјҲ1пјүз©әй—ҙеҲҶй…Қж•ҲзҺҮжҜ”йқҷжҖҒж•°з»„дҪҺгҖӮйқҷжҖҒж•°з»„дёҖиҲ¬з”ұж ҲеҲҶй…Қз©әй—ҙпјҢеҠЁжҖҒж•°з»„дёҖиҲ¬з”ұе ҶеҲҶй…Қз©әй—ҙгҖӮж ҲжҳҜжңәеҷЁзі»з»ҹжҸҗдҫӣзҡ„ж•°жҚ®з»“жһ„пјҢи®Ўз®—жңәдјҡеңЁеә•еұӮдёәж ҲжҸҗдҫӣж”ҜжҢҒпјҢеҚіеҲҶй…Қдё“й—Ёзҡ„еҜ„еӯҳеҷЁеӯҳж”ҫж Ҳзҡ„ең°еқҖпјҢеҺӢж Ҳе’ҢеҮәж ҲйғҪжңүдё“й—Ёзҡ„жңәеҷЁжҢҮд»Өжү§иЎҢпјҢеӣ иҖҢж Ҳзҡ„ж•ҲзҺҮжҜ”иҫғй«ҳгҖӮе Ҷз”ұC++еҮҪж•°еә“жҸҗдҫӣпјҢе…¶еҶ…еӯҳеҲҶй…ҚжңәеҲ¶жҜ”ж ҲиҰҒеӨҚжқӮеҫ—еӨҡпјҢдёәдәҶеҲҶй…ҚдёҖеқ—еҶ…еӯҳпјҢеә“еҮҪж•°дјҡжҢүз…§дёҖе®ҡзҡ„з®—жі•еңЁе ҶеҶ…еӯҳеҶ…жҗңзҙўеҸҜз”Ёзҡ„и¶іеӨҹеӨ§е°Ҹзҡ„з©әй—ҙпјҢеҰӮжһңеҸ‘зҺ°з©әй—ҙдёҚеӨҹпјҢе°Ҷи°ғз”ЁеҶ…ж ёж–№жі•еҺ»еўһеҠ зЁӢеәҸж•°жҚ®ж®өзҡ„еӯҳеӮЁз©әй—ҙпјҢд»ҺиҖҢзЁӢеәҸе°ұжңүжңәдјҡеҲҶй…Қи¶іеӨҹеӨ§зҡ„еҶ…еӯҳгҖӮеӣ жӯӨе Ҷзҡ„ж•ҲзҺҮиҰҒжҜ”ж ҲдҪҺгҖӮ
пјҲ2пјүе®№жҳ“йҖ жҲҗеҶ…еӯҳжі„йңІгҖӮеҠЁжҖҒеҶ…еӯҳйңҖиҰҒејҖеҸ‘дәәе‘ҳжүӢе·ҘеҲҶй…Қе’ҢйҮҠж”ҫеҶ…еӯҳпјҢе®№жҳ“з”ұдәҺејҖеҸ‘дәәе‘ҳзҡ„з–ҸеҝҪйҖ жҲҗеҶ…еӯҳжі„йңІгҖӮ
еңЁе®һж—¶и§Ҷйў‘зі»з»ҹдёӯпјҢи§Ҷйў‘жңҚеҠЎеҷЁжүҝжӢ…и§Ҷйў‘ж•°жҚ®зҡ„зј“еӯҳе’ҢиҪ¬еҸ‘е·ҘдҪңгҖӮдёҖиҲ¬пјҢжңҚеҠЎеҷЁдёәжҜҸеҸ°ж‘„еғҸжңәејҖиҫҹдёҖе®ҡеӨ§е°Ҹдё”зӢ¬з«Ӣзҡ„зј“еӯҳеҢәгҖӮи§Ҷйў‘её§иў«еҶҷе…ҘжӯӨзј“еӯҳеҢәеҗҺпјҢжңҚеҠЎеҷЁеңЁжҹҗдёҖж—¶еҲ»еҶҚе°Ҷе…¶иҜ»еҮәпјҢ并еҗ‘е®ўжҲ·з«ҜиҪ¬еҸ‘гҖӮи§Ҷйў‘её§зҡ„иҪ¬еҸ‘жҳҜдёҙж—¶зҡ„пјҢз”ұдәҺзј“еӯҳеҢәеӨ§е°ҸжңүйҷҗиҖҢи§Ҷйў‘ж•°жҚ®жәҗжәҗдёҚж–ӯпјҢжүҖд»ҘдёҖеё§ж•°жҚ®еңЁиў«еҶҷе…ҘиҝҮеҗҺпјҢиҝҮдёҖж®өж—¶й—ҙ并дјҡиў«ж–°жқҘзҡ„и§Ҷйў‘её§жүҖиҰҶзӣ–гҖӮи§Ҷйў‘её§зҡ„зј“еӯҳж—¶й—ҙз”ұзј“еӯҳеҢәе’Ңи§Ҷйў‘её§зҡ„й•ҝеәҰеҶіе®ҡгҖӮ
з”ұдәҺи§Ҷйў‘её§ж•°жҚ®йҮҸе·ЁеӨ§пјҢиҖҢдёҖеҸ°жңҚеҠЎеҷЁйҖҡеёёйңҖиҰҒж”ҜжҢҒеҮ еҚҒеҸ°з”ҡиҮіж•°зҷҫеҸ°ж‘„еғҸжңәпјҢзј“еӯҳз»“жһ„зҡ„и®ҫи®ЎжҳҜзі»з»ҹзҡ„йҮҚиҰҒйғЁеҲҶгҖӮдёҖж–№йқўпјҢеҰӮжһңйў„е…ҲеҲҶй…Қеӣәе®ҡж•°йҮҸзҡ„еҶ…еӯҳпјҢиҝҗиЎҢж—¶дёҚеҶҚеўһеҠ гҖҒеҲ йҷӨпјҢеҲҷжңҚеҠЎеҷЁеҸӘиғҪж”ҜжҢҒдёҖе®ҡж•°йҮҸзҡ„ж‘„еғҸжңәпјҢзҒөжҙ»жҖ§е°ҸпјӣеҸҰдёҖж–№йқўпјҢз”ұдәҺи§Ҷйў‘жңҚеҠЎеҷЁзЁӢеәҸеңЁеҗҜеҠЁж—¶е°ҶеҚ жҚ®дёҖеӨ§еқ—еҶ…еӯҳпјҢе°ҶеҜјиҮҙзі»з»ҹж•ҙдҪ“жҖ§иғҪдёӢйҷҚпјҢеӣ жӯӨиҖғиҷ‘дҪҝз”ЁеҠЁжҖҒж•°з»„е®һзҺ°и§Ҷйў‘зј“еӯҳгҖӮ
йҰ–е…ҲпјҢжңҚеҠЎеҷЁдёӯдёәжҜҸеҸ°ж‘„еғҸжңәеҲҶй…ҚдёҖдёӘдёҖе®ҡеӨ§е°Ҹзҡ„зј“еӯҳеқ—пјҢз”ұзұ»CamBlockе®һзҺ°гҖӮжҜҸдёӘCamBlockеҜ№иұЎдёӯжңүдёӨдёӘеҠЁжҖҒж•°з»„пјҢеҲҶеҲ«еӯҳж”ҫи§Ҷйў‘ж•°жҚ®зҡ„_dataе’Ңеӯҳж”ҫи§Ҷйў‘её§зҙўеј•дҝЎжҒҜзҡ„_frameIndexгҖӮжҜҸеҪ“зЁӢеәҸеңЁеҶ…еӯҳдёӯзј“еӯҳпјҲиҜ»еҸ–пјүдёҖдёӘи§Ҷйў‘её§ж—¶пјҢеҜ№еә”зҡ„CamBlockеҜ№иұЎе°Ҷж №жҚ®и§Ҷйў‘её§зҙўеј•иЎЁ_frameIndexжүҫеҲ°и§Ҷйў‘её§еңЁ_dataдёӯзҡ„еӯҳж”ҫдҪҚзҪ®пјҢ然еҗҺе°Ҷж•°жҚ®еҶҷе…ҘжҲ–иҜ»еҮәгҖӮ_dataжҳҜдёҖдёӘеҫӘзҺҜйҳҹеҲ—пјҢдёҖиҲ¬ж №жҚ®FIFOиҝӣиЎҢиҜ»еҸ–пјҢеҚіеҰӮжһңжңүж–°её§иҝӣе…ҘйҳҹеҲ—пјҢзЁӢеәҸдјҡеңЁ_dataдёӯжңҖиҝ‘еҶҷе…Ҙеё§зҡ„жң«е°ҫејҖе§ӢеӨҚеҲ¶пјҢеҰӮжһңи¶…еҮәж•°з»„й•ҝеәҰпјҢеҲҷд»ҺеӨҙиҰҶзӣ–гҖӮ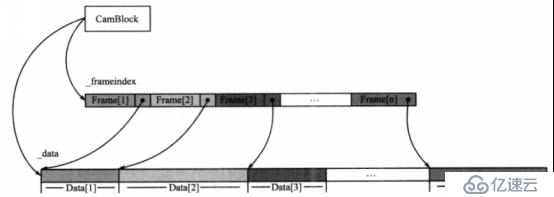
// и§Ҷйў‘её§зҡ„ж•°жҚ®з»“жһ„
typedef struct
{
unsigned short idCamera;// ж‘„еғҸжңәID
unsigned long length;// ж•°жҚ®й•ҝеәҰ
unsigned short width;// еӣҫеғҸе®ҪеәҰ
unsigned short height;// еӣҫеғҸй«ҳеәҰ
unsigned char* data; // еӣҫеғҸж•°жҚ®ең°еқҖ
} Frame;
// еҚ•еҸ°ж‘„еғҸжңәзҡ„зј“еӯҳеқ—ж•°жҚ®з»“жһ„
class CamBlock
{
public:
CamBlock(int id, unsigned long len, unsigned short numFrames):
_data(NULL), _length(0), _idCamera(-1), _numFrames(0)
{
// зЎ®дҝқзј“еӯҳеҢәеӨ§е°ҸдёҚи¶…иҝҮйҳҲеҖј
if(len > MAX_LENGTH || numFrames > MAX_FRAMES)
{
throw;
}
try
{
// дёәеё§зҙўеј•иЎЁеҲҶй…Қз©әй—ҙ
_frameIndex = new Frame[numFrames];
// дёәж‘„еғҸжңәеҲҶй…ҚжҢҮе®ҡеӨ§е°Ҹзҡ„еҶ…еӯҳ
_data = new unsigned char[len];
}
catch(...)
{
throw;
}
memset(this, 0, len);
_length = len;
_idCamera = id;
_numFrames = numFrames;
}
~CamBlcok()
{
delete [] _frameIndex;
delete [] _data;
}
// ж №жҚ®зҙўеј•иЎЁе°Ҷи§Ҷйў‘её§еӯҳе…Ҙзј“еӯҳ
bool SaveFrame(const Frame* frame);
// ж №жҚ®зҙўеј•иЎЁе®ҡдҪҚеҲ°жҹҗдёҖеё§пјҢиҜ»еҸ–
bool ReadFrame(Frame* frame);
private:
Frame* _frameIndex;// её§зҙўеј•иЎЁ
unsigned char* _data;//еӯҳж”ҫеӣҫеғҸж•°жҚ®зҡ„зј“еӯҳеҢә
unsigned long _length;// зј“еӯҳеҢәеӨ§е°Ҹ
unsigned short _idCamera;// ж‘„еғҸжңәID
unsigned short _numFrames;//еҸҜеӯҳж”ҫеё§зҡ„ж•°йҮҸ
unsigned long _lastFrameIndex;//жңҖеҗҺдёҖеё§зҡ„дҪҚзҪ®
};дёәдәҶз®ЎзҗҶжҜҸеҸ°ж‘„еғҸжңәзӢ¬з«Ӣзҡ„еҶ…еӯҳеқ—пјҢеҝ«йҖҹе®ҡдҪҚеҲ°д»»ж„ҸдёҖеҸ°ж‘„еғҸжңәзҡ„зј“еӯҳпјҢз”ҡиҮід»»ж„ҸдёҖеё§пјҢйңҖиҰҒе»әз«Ӣзҙўеј•иЎЁCameraArrayжқҘз®ЎзҗҶжүҖжңүзҡ„CamBlockеҜ№иұЎгҖӮ
class CameraArray
{
typedef CamBlock BlockPtr;
BlockPtr* cameraBufs;// ж‘„еғҸжңәи§Ҷйў‘зј“еӯҳ
unsigned short cameraNum;// еҪ“еүҚе·Із»ҸиҝһжҺҘзҡ„ж‘„еғҸжңәеҸ°ж•°
unsigned short maxNum;//cameraBufsе®№йҮҸ
unsigned short increaseNum;//cameraBufsзҡ„еўһйҮҸ
public:
CameraArray(unsigned short max, unsigned short inc);
~CameraArray();
// жҸ’е…ҘдёҖеҸ°ж‘„еғҸжңә
CamBlock* InsertBlock(unsigned short idCam, unsigned long size, unsigned short numFrames);
// еҲ йҷӨдёҖеҸ°ж‘„еғҸжңә
bool RemoveBlock(unsigned short idCam);
private:
// ж №жҚ®ж‘„еғҸжңәIDиҝ”еӣһе…¶еңЁж•°з»„зҡ„зҙўеј•
unsigned short GetPosition(unsigned short idCam);
};
CameraArray::CameraArray(unsigned short max, unsigned short inc):
cameraBufs(NULL), cameraNum(0), maxNum(0), increaseNum(0)
{
// еҰӮжһңеҸӮж•°и¶Ҡз•ҢпјҢжҠӣеҮәејӮеёё
if(max > MAX_CAMERAS || inc > MAX_INCREMENTS)
throw;
try
{
cameraBufs = new BlockPtr[max];
}
catch(...)
{
throw;
}
maxNum = max;
increaseNum = inc;
}
CameraArray::~CameraArray()
{
for(int i = 0; i < cameraNum; i++)
{
delete cameraBufs[i];
}
delete [] cameraBufs;
}йҖҡеёёпјҢдјҡдёәжҜҸдёӘж‘„еғҸжңәе®үжҺ’дёҖдёӘж•ҙеһӢзҡ„IDпјҢеңЁCameraArrayдёӯпјҢзЁӢеәҸжҢүз…§IDйҖ’еўһзҡ„йЎәеәҸжҺ’еҲ—жҜҸдёӘж‘„еғҸжңәзҡ„CamBlockеҜ№иұЎд»Ҙж–№дҫҝжҹҘиҜўгҖӮеҪ“дёҖдёӘж–°зҡ„ж‘„еғҸжңәжҺҘе…Ҙзі»з»ҹж—¶пјҢзЁӢеәҸдјҡж №жҚ®е®ғзҡ„IDеңЁCameraArrayдёӯжүҫеҲ°дёҖдёӘеҗҲйҖӮзҡ„дҪҚзҪ®пјҢ然еҗҺеҲ©з”Ёзӣёеә”дҪҚзҪ®зҡ„жҢҮй’ҲеҲӣе»әдёҖдёӘж–°зҡ„CamBlockеҜ№иұЎпјӣеҪ“жҹҗдёӘж‘„еғҸжңәж–ӯејҖиҝһжҺҘпјҢзЁӢеәҸд№ҹдјҡж №жҚ®е®ғзҡ„IDпјҢжүҫеҲ°еҜ№еә”зҡ„CamBlockзј“еӯҳеқ—пјҢ并е°Ҷе…¶еҲ йҷӨгҖӮ
CamBlock* CameraArray::InsertBlock(unsigned short idCam, unsigned long size,
unsigned short numFrames)
{
// еңЁж•°з»„дёӯжүҫеҲ°еҗҲйҖӮзҡ„жҸ’е…ҘдҪҚзҪ®
int pos = GetPosition(idCam);
// еҰӮжһңе·Із»ҸиҫҫеҲ°ж•°з»„иҫ№з•ҢпјҢйңҖиҰҒжү©еӨ§ж•°з»„
if(cameraNum == maxNum)
{
// е®ҡд№үж–°зҡ„ж•°з»„жҢҮй’ҲпјҢжҢҮе®ҡе…¶з»ҙж•°
BlockPtr* newBufs = NULL;
try
{
BlockPtr* newBufs = new BlockPtr[maxNum + increaseNum];
}
catch(...)
{
throw;
}
// е°ҶеҺҹж•°з»„еҶ…е®№жӢ·иҙқеҲ°ж–°ж•°з»„
memcpy(newBufs, cameraBufs, maxNum * sizeof(BlockPtr));
// йҮҠж”ҫеҺҹж•°з»„зҡ„еҶ…еӯҳ
delete [] cameraBufs;
maxNum += increaseNum;
// жӣҙж–°ж•°з»„жҢҮй’Ҳ
cameraBufs = newBufs;
}
if(pos != cameraNum)
{
// еңЁж•°з»„дёӯжҸ’е…ҘдёҖдёӘеқ—пјҢйңҖиҰҒе°Ҷе…¶еҗҺжүҖжңүжҢҮй’ҲдҪҚзҪ®еҗҺ移
memmov(cameraBufs + pos + 1, cameraBufs + pos, (cameraNum - pos) * sizeof(BlockPtr));
}
++cameraNum;
CamBlock* newBlock = new CamBlock(idCam, size, numFrames);
cameraBufs[pos] = newBlock;
return cameraBufs[pos];
}еҰӮжһңжҺҘе…Ҙзі»з»ҹзҡ„ж‘„еғҸжңәж•°йҮҸи¶…еҮәдәҶжңҖеҲқеҲӣе»әCameraArrayзҡ„и®ҫи®Ўе®№йҮҸпјҢеҲҷиҖғиҷ‘еҲ°зі»з»ҹзҡ„еҸҜжү©еұ•жҖ§пјҢеҸӘиҰҒ硬件жқЎд»¶е…Ғи®ёпјҢйңҖиҰҒеўһеҠ cameraBufsзҡ„й•ҝеәҰгҖӮ
bool CameraArray::RemoveBlock(unsigned short idCam)
{
if(cameraNum < 1)
return false;
// еңЁж•°з»„дёӯжүҫеҲ°иҰҒеҲ йҷӨзҡ„ж‘„еғҸжңәзҡ„зј“еӯҳеҢәзҡ„дҪҚзҪ®
int pos = GetPosition(idCam);
cameraNum--;
BlockPtr deleteBlock = cameraBufs[pos];
delete deleteBlock;
if(pos != cameraNum)
{
// е°ҶposеҗҺжүҖжңүжҢҮй’ҲдҪҚзҪ®еүҚ移
memmov(cameraBufs + pos, cameraBufs + pos + 1, (cameraNum - pos) * sizeof(BlockPtr));
}
// еҰӮжһңж•°з»„дёӯжңүиҝҮеӨҡз©әй—Ізҡ„дҪҚзҪ®пјҢиҝӣиЎҢйҮҠж”ҫ
if(maxNum - cameraNum > increaseNum)
{
// йҮҚж–°и®Ўз®—ж•°з»„зҡ„й•ҝеәҰ
unsigned short len = (cameraNum / increaseNum + 1) * increaseNum;
// е®ҡд№үж–°зҡ„ж•°з»„жҢҮй’Ҳ
BlockPtr* newBufs = NULL;
try
{
newBufs = new BlockPtr[len];
}
catch(...)
{
throw;
}
// е°ҶеҺҹж•°з»„зҡ„ж•°жҚ®жӢ·иҙқеҲ°ж–°зҡ„ж•°з»„
memcpy(newBufs, cameraBufs, cameraNum * sizeof(BlockPtr));
delete cameraBufs;
cameraBufs = newBufs;
maxNum = len;
}
return true;
}еҰӮжһңеҲ йҷӨдёҖеҸ°ж‘„еғҸжңәж—¶пјҢеҸ‘зҺ°ж•°з»„з©әй—ҙжңүиҝҮеӨҡз©әй—Із©әй—ҙпјҢеҲҷйңҖиҰҒйҮҠж”ҫзӣёеә”з©әй—Із©әй—ҙгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ