您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家介绍数据结构中的单链表如何理解,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
单链表设计要点:
A、类模板,通过头结点访问后继结点。
B、定义内部结点类型,用于描述链表中的结点的数据域和指针域。
C、实现线性表的关键操作
struct Node:public Object
{
T value;//数据域
Node* next;//指针域
};
头结点不存储实际的数据元素,用于辅助数据元素的定位,方便插入和删除操作。
mutable Node m_header;
template <typename T>
class LinkedList:public List<T>
{
protected:
struct Node:public Object
{
T value;//数据域
Node* next;//指针域
};
Node m_header;
int m_length;
public:
LinkedList();
virtual ~LinkedList();
bool insert(int index, const T& value);
bool remove(int index);
bool set(int index, const T& value);
bool get(int index, T& value)const;
int length()const;
int find(const T& value)const;
void clear();
};在目标位置处插入数据元素流程如下:
A、从头结点开始,提供current指针定位到目标位置
B、从堆空间申请新的Node结点
C、将新结点插入目标位置,并连接相邻结点的逻辑关系。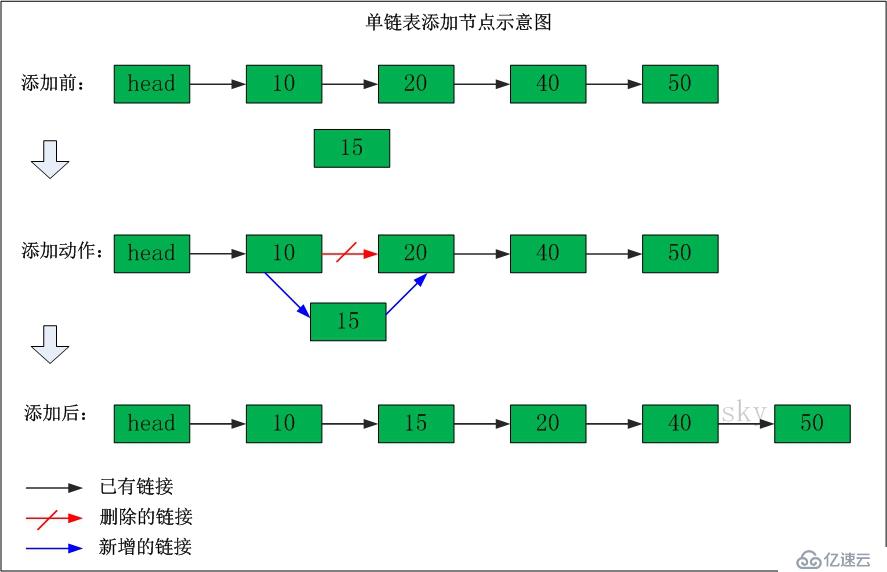
bool insert(int index, const T& value)
{
//判断目标位置是否合法
bool ret = (0 <= index) && (index <= m_length);
if(ret)
{
//创建新的结点
Node* node = new Node();
if(node != NULL)
{
//初始化当前结点为头结点
Node* current = &m_header;
//遍历到目标位置
for(int i = 0; i < index; i++)
{
current = current->next;
}
//修改插入结点的值
node->value = value;
//将当前位置的下一个结点作为插入结点的下一个结点
node->next = current->next;
//将要插入结点作为当前结点的下一个结点
current->next = node;
m_length++;//链表结点长度加1
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "No enough memmory...");
}
}
else
{
THROW_EXCEPTION(IndexOutOfBoudsException, "Parameter index is invalid...");
}
return ret;
}在目标位置删除数据元素的流程:
A、从头结点开始,通过current指针定位到目标位置
B、使用toDel指针指向要被删除的结点
C、删除结点,并连接相邻结点的逻辑关系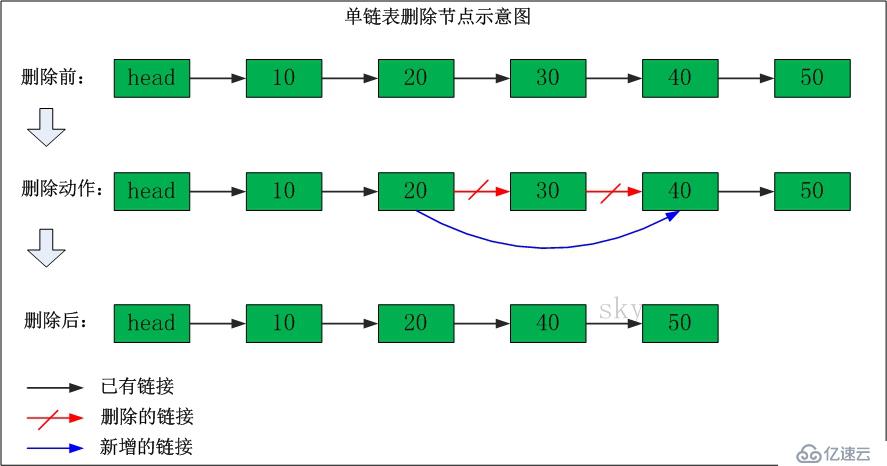
bool remove(int index)
{
//判断目标位置是否合法
bool ret = (0 <= index) && (index < m_length);
if(ret)
{
//当前结点指向头结点
Node* current = &m_header;
//遍历到目标位置
for(int i = 0; i < index; i++)
{
current = current->next;
}
//使用toDel指向要删除的结点
Node* toDel = current->next;
//将当前结点的下一个结点指向要删除结点的下一个结点
current->next = toDel->next;
m_length--;//链表结点长度减1
delete toDel;//释放要删除的结点的堆空间
}
else
{
THROW_EXCEPTION(IndexOutOfBoudsException, "Parameter inde is invalid...");
}
return ret;
}设置目标结点的值的流程如下:
A、从头结点开始,通过current指针定位到目标位置
B、修改目标结点的数据域的值
bool set(int index, const T& value)
{
//判断目标位置是否合法
bool ret = (0 <= index) && (index < m_length);
if(ret)
{
//将当前结点指向头结点
Node* current = &m_header;
//遍历到目标位置
for(int i = 0; i < index; i++)
{
current = current->next;
}
//修改目标结点的数据域的值
current->next->value = value;
}
else
{
THROW_EXCEPTION(IndexOutOfBoudsException, "Parameter inde is invalid...");
}
return ret;
} bool get(int index, T& value)const
{
//判断目标位置是否合法
bool ret = (0 <= index) && (index < m_length);
if(ret)
{
//当前结点指向头结点
Node* current = &m_header;
//遍历到目标位置
for(int i = 0; i < index; i++)
{
current = current->next;
}
//获取目标结点的数据域的值
value = current->next->value;
}
else
{
THROW_EXCEPTION(IndexOutOfBoudsException, "Parameter inde is invalid...");
}
return ret;
}
//重载版本
T get(int index)const
{
T ret;
get(index, ret);
return ret;
}int length()const
{
return m_length;
}void clear()
{
//遍历删除结点
while(m_header.next)
{
//要删除的结点为头结点的下一个结点
Node* toDel = m_header.next;
//将头结点的下一个结点指向删除结点的下一个结点
m_header.next = toDel->next;
delete toDel;//释放要删除结点
}
m_length = 0;
}struct Node:public Object
{
T value;//数据域
Node* next;//指针域
};
mutable Node m_header;由于单链表在构建时必须先创建头结点,头结点在创建时必须调用具体类型的构造函数,如果具体类型的构造函数抛出异常,则单链表对象将构建失败,并会传递具体类型构造函数的异常。
class Test
{
public:
Test()
{
throw 0;
}
};
int main()
{
LinkedList<Test> l;
return 0;
}因此,为了确保模板类的健壮性,需要对头结点的创建进行优化,即在创建单链表对象时不调用具体类型的构造函数。
mutable struct:public Object
{
char reserved[sizeof(T)];//占位空间
Node* next;
}m_header;创建的匿名的头结点m_header的内存布局与Node对象的内存布局完全一样,并且不会调用具体类型T的构造函数。
单链表的操作中经常会定位到目标位置,因此可以将此部分代码独立构建一个函数。
Node* position(int index)const
{
//指针指向头结点
Node* ret = reinterpret_cast<Node*>(&m_header);
//遍历到目标位置
for(int i = 0; i < index; i++)
{
ret = ret->next;
}
return ret;
}为List模板类增加一个find操作:
virtual int find(const T& value)const = 0;
顺序存储结构的线性表SeqList模板类的find实现如下:
int find(const T& value)const
{
int ret = -1;
//遍历线性表
for(int i = 0; i < m_length; i++)
{
//如果找到元素,退出循环
if(m_array[i] = value)
{
ret = i;
break;
}
}
return ret;
}链式存储结构的线性表的find操作如下:
int find(const T& value)const
{
int ret = -1;
//指向头结点
Node* node = m_header.next;
int i = 0;
while(node)
{
//找到元素,退出循环
if(node->value == value)
{
ret = i;
break;
}
else
{
node = node->next;
i++;
}
}
return ret;
}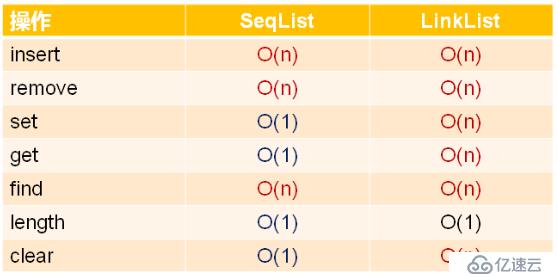
在实际工程开发中,时间复杂度只是效率的一个参考指标。对于内置基础类型,顺序存储结构实现的线性表与链式存储结构实现的线性表的效率基本相同。对于自定义类类型,顺序存储结构实现的线性表比链式存储结构实现的线性表效率要低,原因在于顺序存储结构实现的线性表要设计大量的数据元素的复制,如果自定义类型的拷贝耗时严重,则效率会很低。
顺序存储结构实现的线性表的插入和删除操作涉及大量对象的复制操作,链式存储结构实现的线性表的插入和删除操作只涉及指针的操作,不会涉及数据对象的复制。
顺序存储结构实现的线性表的数据访问支持随机访问,可直接定位数据对象。链式存储结构实现的线性表的数据访问必须顺序访问,必须从头开始访问数据对象,无法直接定位。
因此,顺序存储结构实现的线性表适合数据类型的类型相对简单,不涉及深拷贝,数据元素相对固定,访问操作远多于插入和删除的场合。链式存储结构实现的线性表适合数据元素的类型复杂,复制操作耗时,数据元素不稳定,需要经常插入和删除操作,访问操作较少的场合。
通常遍历链表的方法时间复杂度为O(n^2)
for(int i = 0; i < ll.length(); i++)
{
ll.get(i);
}通过使用游标的方法将遍历链表的时间复杂度优化为O(n):
A、在单链表的内部定义一个游标(Node* m_current)
B、遍历开始前将游标指向位置为0的数据元素
C、获取游标指向的数据元素
D、通过结点中的next指针移动游标
提供一组遍历相关成员函数,以线性时间复杂度遍历链表:
bool move(int pos, int step = 1)
{
bool ret = (0 <= pos) && (pos < m_length) && (0 < step);
if(ret)
{
m_current = position(pos);
m_step = step;
}
return ret;
}
bool end()
{
return m_current == NULL;
}
T current()
{
if(!end())
{
return m_current->value;
}
else
{
THROW_EXCEPTION(InvalidOperationException, "Invalid Operation...");
}
}
bool next()
{
int i = 0;
while((i < m_step) && (!end()))
{
m_current = m_current->next;
i++;
}
return (i == m_step);
}使用游标遍历链表的方法:
for(ll.move(0); !ll.end(); ll.next())
{
cout << ll.current() << endl;
}单链表反转有递归和非递归两种算法。
单链表翻转的递归实现:
Node* reverse(Node* list)
{
Node* ret = NULL;
//如果单链表为空
if(list == NULL || list->next == NULL)
{
ret = list;
}
else
{
Node* guard = list->next;
ret = reverse(list->next);
guard->next = list;
list->next = NULL;
}
return ret;
}单链表翻转的非递归实现:
Node* reverse(Node *header)
{
Node* guard = NULL;//链表翻转后的头结点
Node* current = reinterpret_cast<Node*>(header);//当前结点
Node* prev = NULL;//前一结点
while(current != NULL)
{
Node* pNext = current->next;//下一结点
if(NULL == pNext)//如果是单结点链表
{
guard = current;
}
current->next = prev;//当前结点的下一个结点指向前一结点,实现翻转
prev = current;//将前一结点移到当前结点位置
current = pNext;//将当前结点后移
}
return guard;
} template <typename T>
class LinkedList:public List<T>
{
protected:
struct Node:public Object
{
T value;//数据域
Node* next;//指针域
};
mutable struct:public Object
{
char reserved[sizeof(T)];//占位空间
Node* next;
}m_header;
int m_length;
int m_step;
Node* m_current;
protected:
Node* position(int index)const
{
//指针指向头结点
Node* ret = reinterpret_cast<Node*>(&m_header);
//遍历到目标位置
for(int i = 0; i < index; i++)
{
ret = ret->next;
}
return ret;
}
public:
LinkedList()
{
m_header.next = NULL;
m_length = 0;
m_step = 1;
m_current = NULL;
}
virtual ~LinkedList()
{
clear();
}
bool insert(int index, const T& value)
{
//判断目标位置是否合法
bool ret = (0 <= index) && (index <= m_length);
if(ret)
{
//创建新的结点
Node* node = createNode();
if(node != NULL)
{
//当前结点定位到目标位置
Node* current = position(index);
//修改插入结点的值
node->value = value;
//将当前位置的下一个结点作为插入结点的下一个结点
node->next = current->next;
//将要插入结点作为当前结点的下一个结点
current->next = node;
m_length++;//链表结点长度加1
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "No enough memmory...");
}
}
else
{
THROW_EXCEPTION(IndexOutOfBoudsException, "Parameter index is invalid...");
}
return ret;
}
bool insert(const T& value)
{
return insert(m_length, value);
}
bool remove(int index)
{
//判断目标位置是否合法
bool ret = (0 <= index) && (index < m_length);
if(ret)
{
//当前结点指向头结点
Node* current = position(index);
//使用toDel指向要删除的结点
Node* toDel = current->next;
//将当前结点的下一个结点指向要删除结点的下一个结点
current->next = toDel->next;
m_length--;//链表结点长度减1
destroy(toDel);//释放要删除的结点的堆空间
}
else
{
THROW_EXCEPTION(IndexOutOfBoudsException, "Parameter inde is invalid...");
}
return ret;
}
bool set(int index, const T& value)
{
//判断目标位置是否合法
bool ret = (0 <= index) && (index < m_length);
if(ret)
{
//将当前结点指向头结点
Node* current = position(index);
//修改目标结点的数据域的值
current->next->value = value;
}
else
{
THROW_EXCEPTION(IndexOutOfBoudsException, "Parameter inde is invalid...");
}
return ret;
}
bool get(int index, T& value)const
{
//判断目标位置是否合法
bool ret = (0 <= index) && (index < m_length);
if(ret)
{
//当前结点指向头结点
Node* current = position(index);
//遍历到目标位置
//获取目标结点的数据域的值
value = current->next->value;
}
else
{
THROW_EXCEPTION(IndexOutOfBoudsException, "Parameter inde is invalid...");
}
return ret;
}
//重载版本
T get(int index)const
{
T ret;
if(get(index, ret))
return ret;
}
int length()const
{
return m_length;
}
int find(const T& value)const
{
int ret = -1;
//指向头结点
Node* node = m_header.next;
int i = 0;
while(node)
{
//找到元素,退出循环
if(node->value == value)
{
ret = i;
break;
}
else
{
node = node->next;
i++;
}
}
return ret;
}
void clear()
{
//遍历删除结点
while(m_header.next)
{
//要删除的结点为头结点的下一个结点
Node* toDel = m_header.next;
//将头结点的下一个结点指向删除结点的下一个结点
m_header.next = toDel->next;
m_length--;
destroy(toDel);//释放要删除结点
}
}
bool move(int pos, int step = 1)
{
bool ret = (0 <= pos) && (pos < m_length) && (0 < step);
if(ret)
{
m_current = position(pos)->next;
m_step = step;
}
return ret;
}
bool end()
{
return m_current == NULL;
}
T current()
{
if(!end())
{
return m_current->value;
}
else
{
THROW_EXCEPTION(InvalidOperationException, "Invalid Operation...");
}
}
bool next()
{
int i = 0;
while((i < m_step) && (!end()))
{
m_current = m_current->next;
i++;
}
return (i == m_step);
}
virtual Node* createNode()
{
return new Node();
}
virtual void destroy(Node* node)
{
delete node;
}
};长时间使用单链表频繁增加和删除数据元素时,堆空间会产生大量内存碎片,导致系统运行缓慢。
静态单链表的实现要点:
A、通过类模板实现静态单链表
B、在类中定义固定大小的空间
C、重写create、destroy函数,改变内存的分配和释放方式
D、在Node类中重载operator new操作符,用于在指定内存上创建对象。
template <typename T, int N>
class StaticLinkedList:public LinkedList<T>
{
protected:
typedef typename LinkedList<T>::Node Node;
struct SNode:public Node
{
//重载new操作符
void* operator new(unsigned int size, void* loc)
{
return loc;
}
};
unsigned char m_space[N*sizeof(Node)];//顺序存储空间
bool m_used[N];//空间可用标识
public:
StaticLinkedList()
{
for(int i = 0; i < N; i++)
{
m_used[i] = false;
}
}
Node* createNode()
{
SNode* ret = NULL;
for(int i = 0; i < N; i++)
{
if(!m_used[i])
{
ret = reinterpret_cast<SNode*>(m_space) + i;
ret = new(ret) SNode();
m_used[i] = true;
break;
}
}
return ret;
}
void destroy(Node* node)
{
SNode* space = reinterpret_cast<SNode*>(m_space);
SNode* pn = dynamic_cast<SNode*>(node);
for(int i = 0; i < N; i++)
{
if(pn == space + i)
{
m_used[i] = false;
pn->~SNode();
}
}
}
int capacty()
{
return N;
}
};静态单链表拥有单链表的所有操作,在预留的顺序存储空间中创建结点对象,适合于最大数据元素个数固定需要频繁增加和删除数据元素的场合。
关于数据结构中的单链表如何理解就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。