您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
使用 JDK 自带的 Set 集合来进行 URL 去重,看上去效果不错,但是这种做法有一个致命了缺陷,就是随着采集的 URL 增多,你需要的内存越来越大,最终会导致你的内存崩溃。那我们在不使用数据库的情况下有没有解决办法呢?布隆过滤器!它就可以完美解决这个问题,布隆过滤器有什么特殊的地方呢?接下来就一起来学习一下布隆过滤器。
布隆过滤器是一种数据结构,比较巧妙的概率型数据结构,它是在 1970 年由一个名叫布隆提出的,它实际上是由一个很长的二进制向量和一系列随机映射函数组成,这点跟哈希表有些相同,但是相对哈希表来说布隆过滤器它更高效、占用空间更少,布隆过滤器有一个缺点那就是有一定的误识别率和删除困难。布隆过滤器只能告诉你某个元素一定不存在或者可能存在在集合中, 所以布隆过滤器经常用来处理可以忍受判断失误的业务,比如爬虫 URL 去重。
在说布隆过滤器原理之前,我们先来复习一下哈希表,利用 Set 来进行 URL 去重,我们来看看 Set 的存储模型
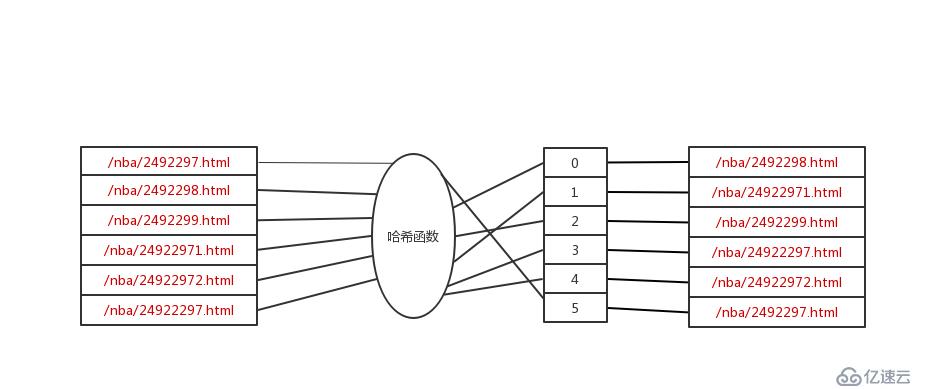
URL 经过一个哈希函数后,将 URL 存入了数组里,这样查询时也是非常高效的,但是由于数组里存入的是 URL,随着 URL 的增多,需要的数组越来越大,意味着你需要更多的内存,比如我们采集了几亿的 URL,那么可能就需要上百G 的内存,这是条件不允许的,因为内存特别的昂贵,所以这个在 url 去重中是不可取的,占内存更小的布隆过滤器就是一种不错的选择。
布隆过滤器实质上由长度为 m 的位向量或位列表(仅包含 0 或 1 位值的列表)组成,最初所有值均设置为 0,如下所示。

因为底层是 bit 数组,所以意味着数组只有 0、1 两个值,跟哈希表一样,我们将 URL 通过 K 个函数映射 bit 数组里,并且将指向的 Bit 数组对应的值改成 1 。我们以存 /nba/2492297.html 为例,如下图所示:
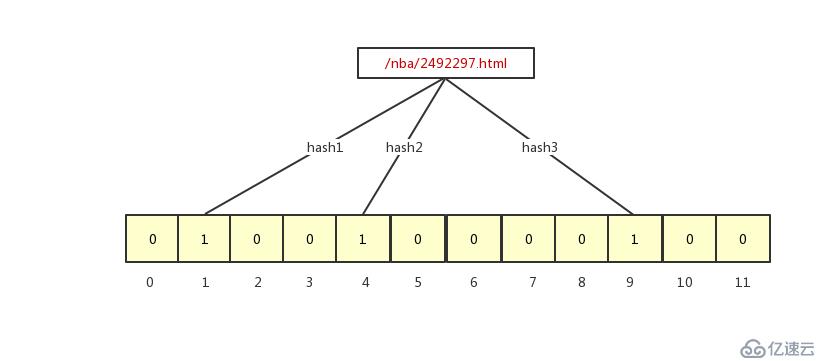
/nba/2492297.html经过三个哈希函数分别映射到了 1、4、9 的位置,这三个 bit 数组的值就变成了 1,我们再存入一个 /nba/2492298.html,此时 bit 数组就变成下面这样:
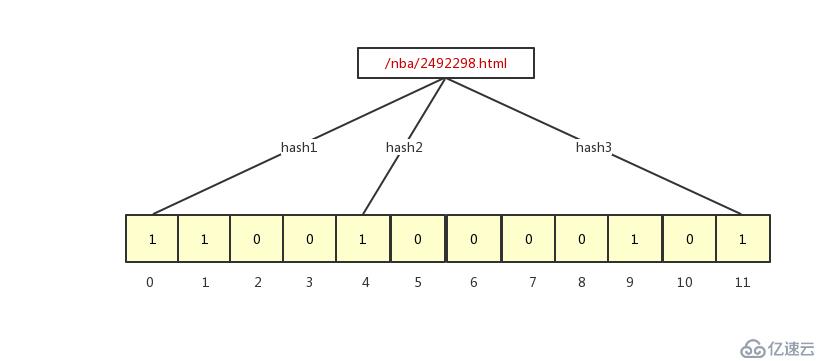
/nba/2492298.html被映射到了 0、4、11 的位置,所以此时 bit 数组上有 5 个位置的值为 1,本应该是有 6 个值为 1 的,但是因为在 4 这个位置重复了,所以会覆盖。
布隆过滤器是如何判断某个值一定不存在或者可能存在呢?通过判断哈希函数映射到对应数组的值,如果都为 1,说明可能存在,如果有一个不为 1,说明一定不存在。对于一定不存在好理解,但是都为 1 时,为什么说可能存在呢?这跟哈希表一样,哈希函数会产生哈希冲突,也就是说两个不同的值经过哈希函数都会得到同一个数组下标,布隆过滤器也是一样的。我们以判断 /nba/2492299.html 是否已经采集过为例,经过哈希函数映射的 bit 数组上的位置入下图所示:
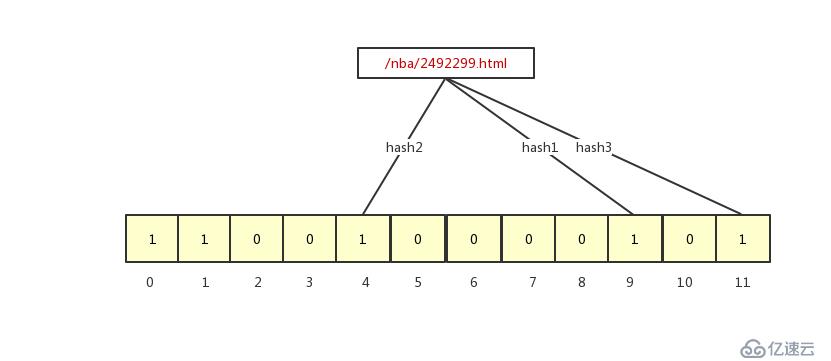
/nba/2492299.html 被哈希函数映射到了 4、9、11 的位置,而这几个位置的值都为 1 ,所以布隆过滤器就认为 /nba/2492299.html 被采集过了,实际上是没有采集过的,这就说明了布隆过滤器存在误判,这也是我们业务允许的。布隆过滤器的误判率跟 bit 数组的大小和哈希函数的个数有关系,如果 bit 数组过小,哈希函数过多,那么 bit 数组的值很快都会变成 1,这样误判率就会越来越高,bit 数组过大,就会浪费更多的内存,所以就要平衡好 bit 数组的大小和哈希函数的个数,关于如何平衡这两个的关系,不是我们这篇文章的重点。
布隆过滤器的原理我们已经了解了,为了加深对布隆过滤器的理解,我们用 Java 来实现一个简易办的布隆过滤器,代码如下:
public class SimpleBloomFilterTest {
// bit 数组的大小
private static final int DEFAULT_SIZE = 1000;
// 用来生产三个不同的哈希函数的
private static final int[] seeds = new int[]{7, 31, 61,};
// bit 数组
private BitSet bits = new BitSet(DEFAULT_SIZE);
// 存放哈希函数的数组
private SimpleHash[] func = new SimpleHash[seeds.length];
public static void main(String[] args) {
SimpleBloomFilterTest filter = new SimpleBloomFilterTest();
filter.add("https://voice.hupu.com/nba/2492440.html");
filter.add("https://voice.hupu.com/nba/2492437.html");
filter.add("https://voice.hupu.com/nba/2492439.html");
System.out.println(filter.contains("https://voice.hupu.com/nba/2492440.html"));
System.out.println(filter.contains("https://voice.hupu.com/nba/249244.html"));
}
public SimpleBloomFilterTest() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
/**
* 向布隆过滤器添加元素
* @param value
*/
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
/**
* 判断某元素是否存在布隆过滤器
* @param value
* @return
*/
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
/**
* 哈希函数
*/
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}把上面这段代码理解好对我们理解布隆过滤器非常有帮助,实际上在工作中并不需要我们自己实现布隆过滤器,谷歌已经帮我们实现了布隆过滤器,在 Guava 包中提供了 BloomFilter,这个布隆过滤器实现的非常棒,下面就看看谷歌办的布隆过滤器。
要使用 Guava 包下提供的 BloomFilter ,就需要引入 Guava 包,我们在 pom.xml 中引入下面依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.1-jre</version>
</dependency>Guava 中的布隆过滤器实现的非常复杂,关于细节我们就不去探究了,我们就来看看 Guava 中布隆过滤器的构造函数吧,Guava 中并没有提供构造函数,而且提供了 create 方法来构造布隆过滤器:
public static <T> BloomFilter<T> create(
Funnel<? super T> funnel, int expectedInsertions, double fpp) {
return create(funnel, (long) expectedInsertions, fpp);
}funnel:你要过滤数据的类型
expectedInsertions:你要存放的数据量
fpp:误判率
你只需要传入这三个参数你就可以使用 Guava 包中的布隆过滤器了,下面这我写的一段 Guava 布隆过滤器测试程序,可以改动 fpp 多运行几次,体验 Guava 的布隆过滤器。
public class GuavaBloomFilterTest {
// bit 数组大小
private static int size = 10000;
// 布隆过滤器
private static BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), size, 0.03);
public static void main(String[] args) {
// 先向布隆过滤器中添加 10000 个url
for (int i = 0; i < size; i++) {
String url = "https://voice.hupu.com/nba/" + i;
bloomFilter.put(url);
}
// 前10000个url不会出现误判
for (int i = 0; i < size; i++) {
String url = "https://voice.hupu.com/nba/" + i;
if (!bloomFilter.mightContain(url)) {
System.out.println("该 url 被采集过了");
}
}
List<String> list = new ArrayList<String>(1000);
// 再向布隆过滤器中添加 2000 个 url ,在这2000 个中就会出现误判了
// 误判的个数为 2000 * fpp
for (int i = size; i < size + 2000; i++) {
String url = "https://voice.hupu.com/nba/" + i;
if (bloomFilter.mightContain(url)) {
list.add(url);
}
}
System.out.println("误判数量:" + list.size());
}
}缓存击穿是查询数据库中不存在的数据,如果有用户恶意模拟请求很多缓存中不存在的数据,由于缓存中都没有,导致这些请求短时间内直接落在了DB上,对DB产生压力,导致数据库异常。
最常见的解决办法就是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。下面是一段伪代码:
public String getByKey(String key) {
// 通过key获取value
String value = redis.get(key);
if (StringUtil.isEmpty(value)) {
if (bloomFilter.mightContain(key)) {
value = xxxService.get(key);
redis.set(key, value);
return value;
} else {
return null;
}
}
return value;
}爬虫是对 url 的去重,防止 url 重复采集,这也是我们这篇文章重点讲解的内容
从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱,将垃圾邮箱添加到布隆过滤器中,然后判断某个邮件是否是存在在布隆过滤器中,存在说明就是垃圾邮箱。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。