жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еёёз”Ёзҡ„SQLж•°жҚ®еә“зҡ„ж•°жҚ®йғҪжҳҜеӯҳеңЁзЈҒзӣҳдёӯзҡ„пјҢиҷҪ然еңЁж•°жҚ®еә“еә•еұӮд№ҹеҒҡдәҶеҜ№еә”зҡ„зј“еӯҳжқҘеҮҸе°‘ж•°жҚ®еә“зҡ„IOеҺӢеҠӣпјҢдҪҶз”ұдәҺж•°жҚ®еә“зҡ„зј“еӯҳдёҖиҲ¬жҳҜй’ҲеҜ№жҹҘиҜўзҡ„еҶ…е®№пјҢиҖҢдё”зІ’еәҰд№ҹжҜ”иҫғе°ҸпјҢдёҖиҲ¬еҸӘжңүиЎЁдёӯзҡ„ж•°жҚ®жІЎжңүеҸ‘з”ҹеҸҳеҠЁзҡ„ж—¶еҖҷпјҢж•°жҚ®еә“зҡ„зј“еӯҳжүҚдјҡдә§з”ҹдҪңз”ЁпјҢдҪҶиҝҷ并дёҚиғҪеҮҸе°‘дёҡеҠЎйҖ»иҫ‘еҜ№ж•°жҚ®еә“зҡ„еўһеҲ ж”№ж“ҚдҪңзҡ„IOеҺӢеҠӣпјҢеӣ жӯӨзј“еӯҳжҠҖжңҜеә”иҝҗиҖҢз”ҹпјҢиҜҘжҠҖжңҜе®һзҺ°дәҶеҜ№зғӯзӮ№ж•°жҚ®зҡ„й«ҳйҖҹзј“еӯҳпјҢеҸҜд»ҘеӨ§еӨ§зј“и§ЈеҗҺз«Ҝж•°жҚ®еә“зҡ„еҺӢеҠӣгҖӮ
дё»жөҒеә”з”Ёжһ¶жһ„
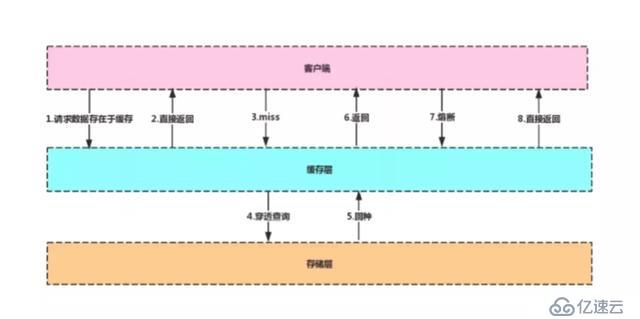
е®ўжҲ·з«ҜеңЁеҜ№ж•°жҚ®еә“еҸ‘иө·иҜ·жұӮж—¶пјҢе…ҲеҲ°зј“еӯҳеұӮжҹҘзңӢжҳҜеҗҰжңүжүҖйңҖзҡ„ж•°жҚ®пјҢеҰӮжһңзј“еӯҳеұӮеӯҳжңүе®ўжҲ·з«ҜжүҖйңҖзҡ„ж•°жҚ®пјҢеҲҷзӣҙжҺҘд»Һзј“еӯҳеұӮиҝ”еӣһпјҢеҗҰеҲҷиҝӣиЎҢз©ҝйҖҸжҹҘиҜўпјҢеҜ№ж•°жҚ®еә“иҝӣиЎҢжҹҘиҜўпјҢеҰӮжһңеңЁж•°жҚ®еә“дёӯжҹҘиҜўеҲ°иҜҘж•°жҚ®пјҢеҲҷе°ҶиҜҘж•°жҚ®еӣһеҶҷеҲ°зј“еӯҳеұӮпјҢд»ҘдҫҝдёӢж¬Ўе®ўжҲ·з«ҜеҶҚж¬ЎжҹҘиҜўиғҪеӨҹзӣҙжҺҘд»Һзј“еӯҳеұӮиҺ·еҸ–ж•°жҚ®гҖӮ
зј“еӯҳдёӯй—ҙ件 -- Memcacheе’ҢRedisзҡ„еҢәеҲ«
Memcache:д»Јз ҒеұӮзұ»дјјHash
1.ж”ҜжҢҒз®ҖеҚ•ж•°жҚ®зұ»еһӢ
2.дёҚж”ҜжҢҒж•°жҚ®жҢҒд№…еҢ–еӯҳеӮЁ
3.дёҚж”ҜжҢҒдё»д»Һ
4.дёҚж”ҜжҢҒеҲҶзүҮ
Redis
1.ж•°жҚ®зұ»еһӢдё°еҜҢ
2.ж”ҜжҢҒж•°жҚ®зЈҒзӣҳжҢҒд№…еҢ–еӯҳеӮЁ
3.ж”ҜжҢҒдё»д»Һ
4.ж”ҜжҢҒеҲҶзүҮ
дёәд»Җд№ҲRedisиғҪиҝҷд№Ҳеҝ«
Redisзҡ„ж•ҲзҺҮеҫҲй«ҳпјҢе®ҳж–№з»ҷеҮәзҡ„ж•°жҚ®жҳҜ100000+QPS(query per second),иҝҷжҳҜеӣ дёәпјҡ
1.Redisе®Ңе…ЁеҹәдәҺеҶ…еӯҳпјҢз»қеӨ§йғЁеҲҶиҜ·жұӮжҳҜзәҜзІ№зҡ„еҶ…еӯҳж“ҚдҪңпјҢжү§иЎҢж•ҲзҺҮй«ҳгҖӮ
2.RedisдҪҝз”ЁеҚ•иҝӣзЁӢеҚ•зәҝзЁӢжЁЎеһӢзҡ„(K,V)ж•°жҚ®еә“пјҢе°Ҷж•°жҚ®еӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҢеӯҳеҸ–еқҮдёҚдјҡеҸ—еҲ°зЎ¬зӣҳIOзҡ„йҷҗеҲ¶пјҢеӣ жӯӨе…¶жү§иЎҢйҖҹеәҰжһҒеҝ«пјҢеҸҰеӨ–еҚ•зәҝзЁӢд№ҹиғҪеӨ„зҗҶй«ҳ并еҸ‘иҜ·жұӮпјҢиҝҳеҸҜд»ҘйҒҝе…Қйў‘з№ҒдёҠдёӢж–ҮеҲҮжҚўе’Ңй”Ғзҡ„з«һдәүпјҢеҰӮжһңжғіиҰҒеӨҡж ёиҝҗиЎҢд№ҹеҸҜд»ҘеҗҜеҠЁеӨҡдёӘе®һдҫӢгҖӮ
3.ж•°жҚ®з»“жһ„з®ҖеҚ•пјҢеҜ№ж•°жҚ®ж“ҚдҪңд№ҹз®ҖеҚ•пјҢRedisдёҚдҪҝз”ЁиЎЁпјҢдёҚдјҡејәеҲ¶з”ЁжҲ·еҜ№еҗ„дёӘе…ізі»иҝӣиЎҢе…іиҒ”пјҢдёҚдјҡжңүеӨҚжқӮзҡ„е…ізі»йҷҗеҲ¶пјҢе…¶еӯҳеӮЁз»“жһ„е°ұжҳҜй”®еҖјеҜ№пјҢзұ»дјјдәҺHashMapпјҢHashMapжңҖеӨ§зҡ„дјҳзӮ№е°ұжҳҜеӯҳеҸ–зҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәO(1)гҖӮ
4.RedisдҪҝз”ЁеӨҡи·ҜI/OеӨҚз”ЁжЁЎеһӢпјҢдёәйқһйҳ»еЎһIOпјҲйқһйҳ»еЎһIOдјҡеҸҰеҶҷдёҖзҜҮи§ЈйҮҠпјҢеҸҜд»Ҙе…ҲиЎҢзҷҫеәҰпјүгҖӮ
жіЁпјҡRedisйҮҮз”Ёзҡ„I/OеӨҡи·ҜеӨҚз”ЁеҮҪж•°пјҡepoll/kqueue/evport/select
йҖүз”Ёзӯ–з•Ҙпјҡ
1.еӣ ең°еҲ¶е®ңпјҢдјҳе…ҲйҖүжӢ©ж—¶й—ҙеӨҚжқӮеәҰдёәO(1)зҡ„I/OеӨҡи·ҜеӨҚз”ЁеҮҪж•°дҪңдёәеә•еұӮе®һзҺ°гҖӮ
2.з”ұдәҺselectиҰҒйҒҚеҺҶжҜҸдёҖдёӘIOпјҢжүҖд»Ҙе…¶ж—¶й—ҙеӨҚжқӮеәҰдёәO(n)пјҢйҖҡеёёиў«дҪңдёәдҝқеә•ж–№жЎҲгҖӮ
3.еҹәдәҺreactи®ҫи®ЎжЁЎејҸзӣ‘еҗ¬I/OдәӢ件гҖӮ
String
жңҖеҹәжң¬зҡ„ж•°жҚ®зұ»еһӢпјҢе…¶еҖјжңҖеӨ§еҸҜеӯҳеӮЁ512MпјҢдәҢиҝӣеҲ¶е®үе…ЁпјҲRedisзҡ„StringеҸҜд»ҘеҢ…еҗ«д»»дҪ•дәҢиҝӣеҲ¶ж•°жҚ®пјҢеҢ…еҗ«jpgеҜ№иұЎзӯүпјүгҖӮ
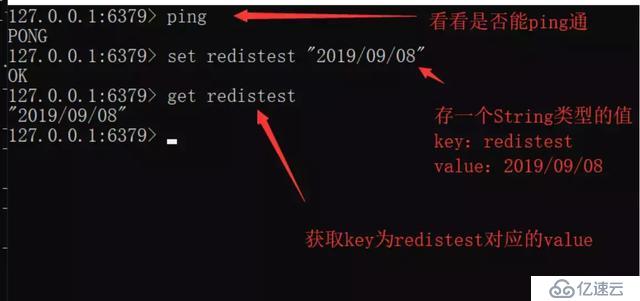
жіЁпјҡеҰӮжһңйҮҚеӨҚеҶҷе…ҘkeyзӣёеҗҢзҡ„й”®еҖјеҜ№пјҢеҗҺеҶҷе…Ҙзҡ„дјҡе°Ҷд№ӢеүҚеҶҷе…Ҙзҡ„иҰҶзӣ–гҖӮ
Hash
Stringе…ғзҙ з»„жҲҗзҡ„еӯ—е…ёпјҢйҖӮз”ЁдәҺеӯҳеӮЁеҜ№иұЎгҖӮ

List
еҲ—иЎЁпјҢжҢүз…§Stringе…ғзҙ жҸ’е…ҘйЎәеәҸжҺ’еәҸгҖӮе…¶йЎәеәҸдёәеҗҺиҝӣе…ҲеҮәгҖӮз”ұдәҺе…¶е…·жңүж Ҳзҡ„зү№жҖ§пјҢжүҖд»ҘеҸҜд»Ҙе®һзҺ°еҰӮвҖңжңҖж–°ж¶ҲжҒҜжҺ’иЎҢжҰңвҖқиҝҷзұ»зҡ„еҠҹиғҪгҖӮ

Set
Stringе…ғзҙ з»„жҲҗзҡ„ж— еәҸйӣҶеҗҲпјҢйҖҡиҝҮе“ҲеёҢиЎЁе®һзҺ°пјҲеўһеҲ ж”№жҹҘж—¶й—ҙеӨҚжқӮеәҰдёәO(1)пјүпјҢдёҚе…Ғи®ёйҮҚеӨҚгҖӮ
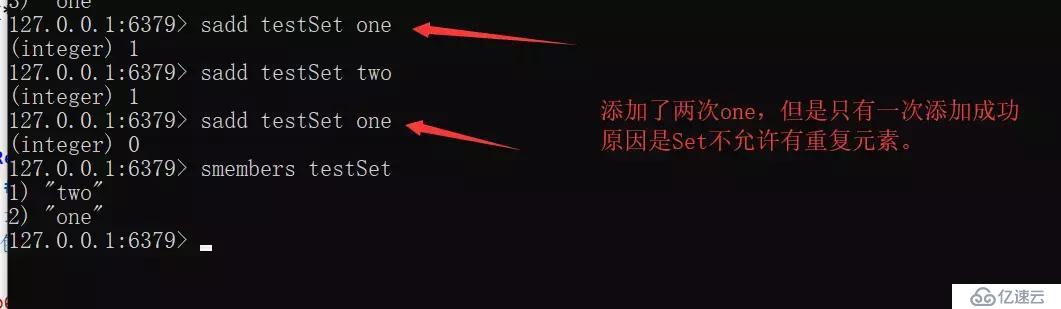
еҸҰеӨ–пјҢеҪ“жҲ‘们дҪҝз”ЁsmembersйҒҚеҺҶsetдёӯзҡ„е…ғзҙ ж—¶пјҢе…¶йЎәеәҸд№ҹжҳҜдёҚзЎ®е®ҡзҡ„пјҢжҳҜйҖҡиҝҮhashиҝҗз®—иҝҮеҗҺзҡ„з»“жһңгҖӮRedisиҝҳеҜ№йӣҶеҗҲжҸҗдҫӣдәҶжұӮдәӨйӣҶгҖҒ并йӣҶгҖҒе·®йӣҶзӯүж“ҚдҪңпјҢеҸҜд»Ҙе®һзҺ°еҰӮеҗҢе…ұеҗҢе…іжіЁпјҢе…ұеҗҢеҘҪеҸӢзӯүеҠҹиғҪгҖӮ
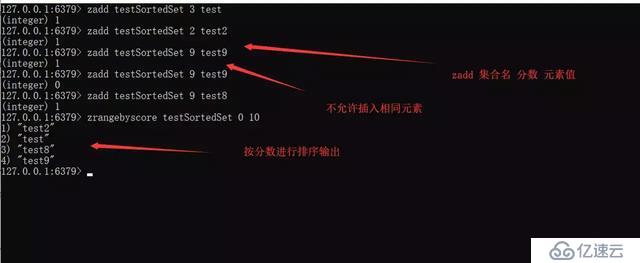
Sorted Set
йҖҡиҝҮеҲҶж•°жқҘдёәйӣҶеҗҲдёӯзҡ„жҲҗе‘ҳиҝӣиЎҢд»Һе°ҸеҲ°еӨ§зҡ„жҺ’еәҸгҖӮ
жӣҙй«ҳзә§зҡ„Redisзұ»еһӢ
з”ЁдәҺи®Ўж•°зҡ„HyperLogLogгҖҒз”ЁдәҺж”ҜжҢҒеӯҳеӮЁең°зҗҶдҪҚзҪ®дҝЎжҒҜзҡ„GeoгҖӮ
д»Һжө·йҮҸKeyйҮҢжҹҘиҜўеҮәжҹҗдёҖдёӘеӣәе®ҡеүҚзјҖзҡ„Key
еҒҮи®ҫredisдёӯжңүеҚҒдәҝжқЎkeyпјҢеҰӮдҪ•д»Һиҝҷд№ҲеӨҡkeyдёӯжүҫеҲ°еӣәе®ҡеүҚзјҖзҡ„keyпјҹ
ж–№жі•1пјҡдҪҝз”ЁKEYS [pattern]пјҡжҹҘжүҫжүҖжңүз¬ҰеҗҲз»ҷе®ҡжЁЎејҸpatternзҡ„key
дҪҝз”Ёkeys [pattern]жҢҮд»ӨеҸҜд»ҘжүҫеҲ°жүҖжңүз¬ҰеҗҲpatternжқЎд»¶зҡ„keyпјҢдҪҶжҳҜkeysдјҡдёҖж¬ЎжҖ§иҝ”еӣһжүҖжңүз¬ҰеҗҲжқЎд»¶зҡ„keyпјҢжүҖд»ҘдјҡйҖ жҲҗredisзҡ„еҚЎйЎҝпјҢеҒҮи®ҫredisжӯӨж—¶жӯЈеңЁз”ҹдә§зҺҜеўғдёӢпјҢдҪҝз”ЁиҜҘе‘Ҫд»Өе°ұдјҡйҖ жҲҗйҡҗжӮЈпјҢеҸҰеӨ–еҰӮжһңдёҖж¬ЎжҖ§иҝ”еӣһжүҖжңүkeyпјҢеҜ№еҶ…еӯҳзҡ„ж¶ҲиҖ—еңЁжҹҗдәӣжқЎд»¶дёӢд№ҹжҳҜе·ЁеӨ§зҡ„гҖӮ дҫӢпјҡ
keys test* //иҝ”еӣһжүҖжңүд»ҘtestдёәеүҚзјҖзҡ„key
ж–№жі•2пјҡдҪҝз”ЁSCAN cursor [MATCH pattern] [COUNT count]
cursorпјҡжёёж Ү MATCH patternпјҡжҹҘиҜўkeyзҡ„жқЎд»¶ countпјҡиҝ”еӣһзҡ„жқЎж•° SCANжҳҜдёҖдёӘеҹәдәҺжёёж Үзҡ„иҝӯд»ЈеҷЁпјҢйңҖиҰҒеҹәдәҺдёҠдёҖж¬Ўзҡ„жёёж Ү延з»ӯд№ӢеүҚзҡ„иҝӯд»ЈиҝҮзЁӢгҖӮSCANд»Ҙ0дҪңдёәжёёж ҮпјҢејҖе§ӢдёҖж¬Ўж–°зҡ„иҝӯд»ЈпјҢзӣҙеҲ°е‘Ҫд»Өиҝ”еӣһжёёж Ү0е®ҢжҲҗдёҖж¬ЎйҒҚеҺҶгҖӮжӯӨе‘Ҫд»Ө并дёҚдҝқиҜҒжҜҸж¬Ўжү§иЎҢйғҪиҝ”еӣһжҹҗдёӘз»ҷе®ҡж•°йҮҸзҡ„е…ғзҙ пјҢз”ҡиҮідјҡиҝ”еӣһ0дёӘе…ғзҙ пјҢдҪҶеҸӘиҰҒжёёж ҮдёҚжҳҜ0пјҢзЁӢеәҸйғҪдёҚдјҡи®ӨдёәSCANе‘Ҫд»Өз»“жқҹпјҢдҪҶжҳҜиҝ”еӣһзҡ„е…ғзҙ ж•°йҮҸеӨ§жҰӮзҺҮз¬ҰеҗҲcountеҸӮж•°гҖӮеҸҰеӨ–пјҢSCANж”ҜжҢҒжЁЎзіҠжҹҘиҜўгҖӮ дҫӢпјҡ
SCAN 0 MATCH test* COUNT 10 //жҜҸж¬Ўиҝ”еӣһ10жқЎд»ҘtestдёәеүҚзјҖзҡ„key
еҰӮдҪ•йҖҡиҝҮRedisе®һзҺ°еҲҶеёғејҸй”Ғ
еҲҶеёғејҸй”Ғ
еҲҶеёғејҸй”ҒжҳҜжҺ§еҲ¶еҲҶеёғејҸзі»з»ҹд№Ӣй—ҙе…ұеҗҢи®ҝй—®е…ұдә«иө„жәҗзҡ„дёҖз§Қй”Ғзҡ„е®һзҺ°гҖӮеҰӮжһңдёҖдёӘзі»з»ҹпјҢжҲ–иҖ…дёҚеҗҢзі»з»ҹзҡ„дёҚеҗҢдё»жңәд№Ӣй—ҙе…ұдә«жҹҗдёӘиө„жәҗж—¶пјҢеҫҖеҫҖйңҖиҰҒдә’ж–ҘпјҢжқҘжҺ’йҷӨе№Іжү°пјҢж»Ўи¶іж•°жҚ®дёҖиҮҙжҖ§гҖӮ
еҲҶеёғејҸй”ҒйңҖиҰҒи§ЈеҶізҡ„й—®йўҳеҰӮдёӢпјҡ
1.дә’ж–ҘжҖ§пјҡд»»ж„Ҹж—¶еҲ»еҸӘжңүдёҖдёӘе®ўжҲ·з«ҜиҺ·еҸ–еҲ°й”ҒпјҢдёҚиғҪжңүдёӨдёӘе®ўжҲ·з«ҜеҗҢж—¶иҺ·еҸ–еҲ°й”ҒгҖӮ
2.е®үе…ЁжҖ§пјҡй”ҒеҸӘиғҪиў«жҢҒжңүиҜҘй”Ғзҡ„е®ўжҲ·з«ҜеҲ йҷӨпјҢдёҚиғҪз”ұе…¶е®ғе®ўжҲ·з«ҜеҲ йҷӨгҖӮ
3.жӯ»й”ҒпјҡиҺ·еҸ–й”Ғзҡ„е®ўжҲ·з«Ҝеӣ дёәжҹҗдәӣеҺҹеӣ иҖҢе®•жңә继иҖҢж— жі•йҮҠж”ҫй”ҒпјҢе…¶е®ғе®ўжҲ·з«ҜеҶҚд№ҹж— жі•иҺ·еҸ–й”ҒиҖҢеҜјиҮҙжӯ»й”ҒпјҢжӯӨж—¶йңҖиҰҒжңүзү№ж®ҠжңәеҲ¶жқҘйҒҝе…Қжӯ»й”ҒгҖӮ
4.е®№й”ҷпјҡеҪ“еҗ„дёӘиҠӮзӮ№пјҢеҰӮжҹҗдёӘredisиҠӮзӮ№е®•жңәзҡ„ж—¶еҖҷпјҢе®ўжҲ·з«Ҝд»Қ然иғҪеӨҹиҺ·еҸ–й”ҒжҲ–йҮҠж”ҫй”ҒгҖӮ
еҰӮдҪ•дҪҝз”Ёredisе®һзҺ°еҲҶеёғејҸй”Ғ
дҪҝз”ЁSETNXе®һзҺ°
SETNX key value:еҰӮжһңkeyдёҚеӯҳеңЁпјҢеҲҷеҲӣе»ә并иөӢеҖјгҖӮиҜҘе‘Ҫд»Өж—¶й—ҙеӨҚжқӮеәҰдёәO(1)пјҢеҰӮжһңи®ҫзҪ®жҲҗеҠҹпјҢеҲҷиҝ”еӣһ1пјҢеҗҰеҲҷиҝ”еӣһ0гҖӮ

з”ұдәҺSETNXжҢҮд»Өж“ҚдҪңз®ҖеҚ•пјҢдё”жҳҜеҺҹеӯҗжҖ§зҡ„пјҢжүҖд»ҘеҲқжңҹзҡ„ж—¶еҖҷз»Ҹеёёиў«дәә们дҪңдёәеҲҶеёғејҸй”ҒпјҢжҲ‘们еңЁеә”з”Ёзҡ„ж—¶еҖҷпјҢеҸҜд»ҘеңЁжҹҗдёӘе…ұдә«иө„жәҗеҢәд№ӢеүҚе…ҲдҪҝз”ЁSETNXжҢҮд»ӨпјҢжҹҘзңӢжҳҜеҗҰи®ҫзҪ®жҲҗеҠҹпјҢеҰӮжһңи®ҫзҪ®жҲҗеҠҹеҲҷиҜҙжҳҺеүҚж–№жІЎжңүе®ўжҲ·з«ҜжӯЈеңЁи®ҝй—®иҜҘиө„жәҗпјҢеҰӮжһңи®ҫзҪ®еӨұиҙҘеҲҷиҜҙжҳҺжңүе®ўжҲ·з«ҜжӯЈеңЁи®ҝй—®иҜҘиө„жәҗпјҢйӮЈд№ҲеҪ“еүҚе®ўжҲ·з«Ҝе°ұйңҖиҰҒзӯүеҫ…гҖӮдҪҶжҳҜеҰӮжһңзңҹзҡ„иҝҷд№ҲеҒҡпјҢе°ұдјҡеӯҳеңЁдёҖдёӘй—®йўҳпјҢеӣ дёәSETNXжҳҜй•ҝд№…еӯҳеңЁзҡ„пјҢжүҖд»ҘеҒҮи®ҫдёҖдёӘе®ўжҲ·з«ҜжӯЈеңЁи®ҝй—®иө„жәҗпјҢ并且дёҠй”ҒпјҢйӮЈд№ҲеҪ“иҝҷдёӘе®ўжҲ·з«Ҝз»“жқҹи®ҝй—®ж—¶пјҢиҜҘй”Ғдҫқж—§еӯҳеңЁпјҢеҗҺжқҘиҖ…д№ҹж— жі•жҲҗеҠҹиҺ·еҸ–й”ҒпјҢиҝҷдёӘиҜҘеҰӮдҪ•и§ЈеҶіе‘ўпјҹ
з”ұдәҺSETNX并дёҚж”ҜжҢҒдј е…ҘEXPIREеҸӮж•°пјҢжүҖд»ҘжҲ‘们еҸҜд»ҘзӣҙжҺҘдҪҝз”ЁEXPIREжҢҮд»ӨжқҘеҜ№зү№е®ҡзҡ„keyжқҘи®ҫзҪ®иҝҮжңҹж—¶й—ҙгҖӮ
з”Ёжі•пјҡEXPIRE key seconds

зЁӢеәҸпјҡ
RedisServiceВ redisServiceВ =В SpringUtils.getBean(RedisService.class);
longВ statusВ =В redisService.setnx(key,"1");
if(statusВ ==В 1){
В redisService.expire(key,expire);
В doOcuppiedWork();
}иҝҷж®өзЁӢеәҸеӯҳеңЁзҡ„й—®йўҳ:еҒҮи®ҫзЁӢеәҸиҝҗиЎҢеҲ°з¬¬дәҢиЎҢеҮәзҺ°ејӮеёёпјҢйӮЈд№ҲзЁӢеәҸжқҘдёҚеҸҠи®ҫзҪ®иҝҮжңҹж—¶й—ҙе°ұз»“жқҹдәҶпјҢеҲҷkeyдјҡдёҖзӣҙеӯҳеңЁпјҢзӯүеҗҢдәҺй”ҒдёҖзӣҙиў«жҢҒжңүж— жі•йҮҠж”ҫгҖӮеҮәзҺ°жӯӨй—®йўҳзҡ„ж №жң¬еҺҹеӣ дёәпјҡеҺҹеӯҗжҖ§еҫ—дёҚеҲ°ж»Ўи¶ігҖӮ
и§ЈеҶіпјҡд»ҺRedis2.6.12зүҲжң¬ејҖе§ӢпјҢжҲ‘们е°ұеҸҜд»ҘдҪҝз”ЁSetж“ҚдҪңпјҢе°ҶSetnxе’ҢexpireиһҚеҗҲеңЁдёҖиө·жү§иЎҢпјҢе…·дҪ“еҒҡжі•еҰӮдёӢгҖӮ
SETВ KEYВ valueВ [EXВ seconds]В [PXВ milliseconds]В [NX|XX]
EX second:и®ҫзҪ®й”®зҡ„иҝҮжңҹж—¶й—ҙдёәsecondз§’гҖӮ
PX millisecond:и®ҫзҪ®й”®зҡ„иҝҮжңҹж—¶й—ҙдёәmillisecondжҜ«з§’гҖӮ
NXпјҡеҸӘеңЁй”®дёҚеӯҳеңЁж—¶пјҢжүҚеҜ№й”®иҝӣиЎҢи®ҫзҪ®ж“ҚдҪңгҖӮ
XX:еҸӘеңЁй”®е·Із»ҸеӯҳеңЁж—¶пјҢжүҚеҜ№й”®иҝӣиЎҢи®ҫзҪ®ж“ҚдҪңгҖӮ
жіЁпјҡSETж“ҚдҪңжҲҗеҠҹе®ҢжҲҗж—¶жүҚдјҡиҝ”еӣһOKпјҢеҗҰеҲҷиҝ”еӣһnilгҖӮ
жңүдәҶSETжҲ‘们е°ұеҸҜд»ҘеңЁзЁӢеәҸдёӯдҪҝз”Ёзұ»дјјдёӢйқўзҡ„д»Јз Ғе®һзҺ°еҲҶеёғејҸй”ҒдәҶпјҡ
RedisServiceВ redisServiceВ =В SpringUtils.getBean(RedisService.class);
StringВ resultВ =В redisService.set(lockKey,requestId,SET_IF_NOT_EXIST,SET_WITH_EXPIRE_TIME,expireTime);
if("OK.equals(result)"){
В doOcuppiredWork();
}еҰӮдҪ•е®һзҺ°ејӮжӯҘйҳҹеҲ—
дҪҝз”ЁRedisдёӯзҡ„ListдҪңдёәйҳҹеҲ—
дҪҝз”ЁдёҠж–ҮжүҖиҜҙзҡ„Redisзҡ„ж•°жҚ®з»“жһ„дёӯзҡ„ListдҪңдёәйҳҹеҲ— Rpushз”ҹдә§ж¶ҲжҒҜпјҢLPOPж¶Ҳиҙ№ж¶ҲжҒҜгҖӮ
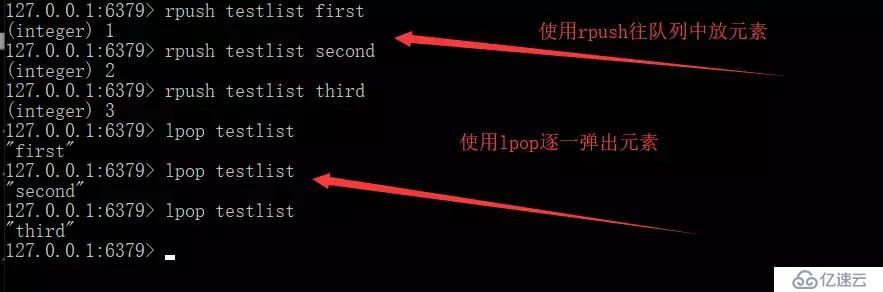
жӯӨж—¶жҲ‘们еҸҜд»ҘзңӢеҲ°пјҢиҜҘйҳҹеҲ—жҳҜдҪҝз”Ёrpushз”ҹдә§йҳҹеҲ—пјҢдҪҝз”Ёlpopж¶Ҳиҙ№йҳҹеҲ—гҖӮеңЁиҝҷдёӘз”ҹдә§иҖ…-ж¶Ҳиҙ№иҖ…йҳҹеҲ—йҮҢпјҢеҪ“lpopжІЎжңүж¶ҲжҒҜж—¶пјҢиҜҒжҳҺиҜҘйҳҹеҲ—дёӯжІЎжңүе…ғзҙ пјҢ并且з”ҹдә§иҖ…иҝҳжІЎжңүжқҘеҫ—еҸҠз”ҹдә§ж–°зҡ„ж•°жҚ®гҖӮ
зјәзӮ№пјҡlpopдёҚдјҡзӯүеҫ…йҳҹеҲ—дёӯжңүеҖјд№ӢеҗҺеҶҚж¶Ҳиҙ№пјҢиҖҢжҳҜзӣҙжҺҘиҝӣиЎҢж¶Ҳиҙ№гҖӮ
ејҘиЎҘпјҡеҸҜд»ҘйҖҡиҝҮеңЁеә”з”ЁеұӮеј•е…ҘSleepжңәеҲ¶еҺ»и°ғз”ЁLPOPйҮҚиҜ•гҖӮ
дҪҝз”ЁBLPOP key [key...] timeout
BLPOP key [key ...] timeout:йҳ»еЎһзӣҙеҲ°йҳҹеҲ—жңүж¶ҲжҒҜжҲ–иҖ…и¶…ж—¶гҖӮ
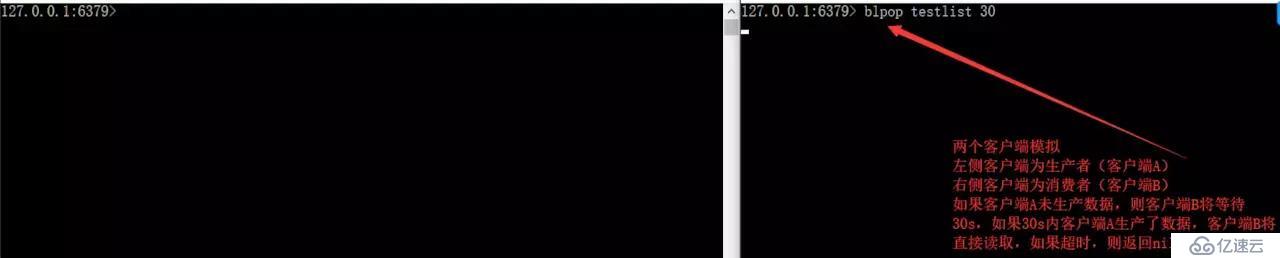
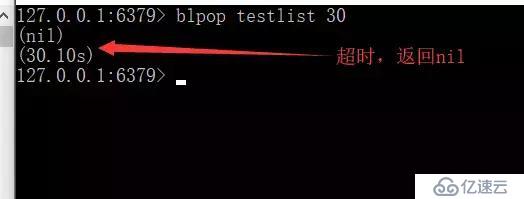

зјәзӮ№пјҡжҢүз…§жӯӨз§Қж–№жі•пјҢжҲ‘们з”ҹдә§еҗҺзҡ„ж•°жҚ®еҸӘиғҪжҸҗдҫӣз»ҷеҗ„дёӘеҚ•дёҖж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№иғҪеҗҰе®һзҺ°з”ҹдә§дёҖж¬Ўе°ұиғҪи®©еӨҡдёӘж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№е‘ўпјҹ
pub/subпјҡдё»йўҳи®ўйҳ…иҖ…жЁЎејҸ
еҸ‘йҖҒиҖ…пјҲpubпјүеҸ‘йҖҒж¶ҲжҒҜпјҢи®ўйҳ…иҖ…пјҲsubпјүжҺҘ收ж¶ҲжҒҜгҖӮ и®ўйҳ…иҖ…еҸҜд»Ҙи®ўйҳ…д»»ж„Ҹж•°йҮҸзҡ„йў‘йҒ“
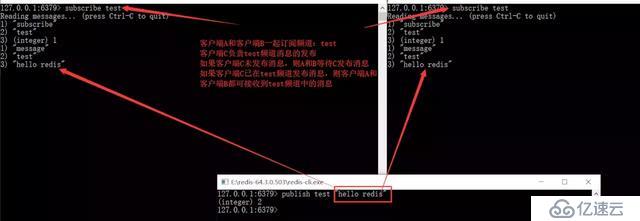
pub/subжЁЎејҸзҡ„зјәзӮ№пјҡ
ж¶ҲжҒҜзҡ„еҸ‘еёғжҳҜж— зҠ¶жҖҒзҡ„пјҢж— жі•дҝқиҜҒеҸҜиҫҫгҖӮеҜ№дәҺеҸ‘еёғиҖ…жқҘиҜҙпјҢж¶ҲжҒҜжҳҜвҖңеҚіеҸ‘еҚіеӨұвҖқзҡ„пјҢжӯӨж—¶еҰӮжһңжҹҗдёӘж¶Ҳиҙ№иҖ…еңЁз”ҹдә§иҖ…еҸ‘еёғж¶ҲжҒҜж—¶дёӢзәҝпјҢйҮҚж–°дёҠзәҝд№ӢеҗҺпјҢжҳҜж— жі•жҺҘ收иҜҘж¶ҲжҒҜзҡ„пјҢиҰҒи§ЈеҶіиҜҘй—®йўҳйңҖиҰҒдҪҝз”Ёдё“дёҡзҡ„ж¶ҲжҒҜйҳҹеҲ—пјҢеҰӮkafka...жӯӨеӨ„дёҚеҶҚиөҳиҝ°гҖӮ
RedisжҢҒд№…еҢ–
д»Җд№ҲжҳҜжҢҒд№…еҢ–
жҢҒд№…еҢ–пјҢеҚіе°Ҷж•°жҚ®жҢҒд№…еӯҳеӮЁпјҢиҖҢдёҚеӣ ж–ӯз”өжҲ–е…¶е®ғеҗ„з§ҚеӨҚжқӮеӨ–йғЁзҺҜеўғеҪұе“Қж•°жҚ®зҡ„е®Ңж•ҙжҖ§гҖӮз”ұдәҺRedisе°Ҷж•°жҚ®еӯҳеӮЁеңЁеҶ…еӯҳиҖҢдёҚжҳҜзЈҒзӣҳдёӯпјҢжүҖд»ҘеҶ…еӯҳдёҖж—Ұж–ӯз”өпјҢRedisдёӯеӯҳеӮЁзҡ„ж•°жҚ®д№ҹйҡҸеҚіж¶ҲеӨұпјҢиҝҷеҫҖеҫҖжҳҜз”ЁжҲ·дёҚжңҹжңӣзҡ„пјҢжүҖд»ҘRedisжңүжҢҒд№…еҢ–жңәеҲ¶жқҘдҝқиҜҒж•°жҚ®зҡ„е®үе…ЁжҖ§гҖӮ
RedisеҰӮдҪ•еҒҡжҢҒд№…еҢ–
Redisзӣ®еүҚжңүдёӨз§ҚжҢҒд№…еҢ–ж–№ејҸпјҢеҚіRDBе’ҢAOFпјҢRDBжҳҜйҖҡиҝҮдҝқеӯҳжҹҗдёӘж—¶й—ҙзӮ№зҡ„е…ЁйҮҸж•°жҚ®еҝ«з…§е®һзҺ°ж•°жҚ®зҡ„жҢҒд№…еҢ–пјҢеҪ“жҒўеӨҚж•°жҚ®ж—¶пјҢзӣҙжҺҘйҖҡиҝҮrdbж–Ү件дёӯзҡ„еҝ«з…§пјҢе°Ҷж•°жҚ®жҒўеӨҚгҖӮ
RDB(еҝ«з…§)жҢҒд№…еҢ–:дҝқеӯҳжҹҗдёӘж—¶й—ҙзӮ№зҡ„е…ЁйҮҸж•°жҚ®еҝ«з…§
RDBжҢҒд№…еҢ–дјҡеңЁжҹҗдёӘзү№е®ҡзҡ„й—ҙйҡ”дҝқеӯҳйӮЈдёӘж—¶й—ҙзӮ№зҡ„е…ЁйҮҸж•°жҚ®зҡ„еҝ«з…§гҖӮ RDBй…ҚзҪ®ж–Ү件: redis.conf:
В saveВ 900В 1В #еңЁ900sеҶ…еҰӮжһңжңү1жқЎж•°жҚ®иў«еҶҷе…ҘпјҢеҲҷдә§з”ҹдёҖж¬Ўеҝ«з…§гҖӮ В saveВ 300В 10В #еңЁ300sеҶ…еҰӮжһңжңү10жқЎж•°жҚ®иў«еҶҷе…ҘпјҢеҲҷдә§з”ҹдёҖж¬Ўеҝ«з…§ В saveВ 60В 10000В #еңЁ60sеҶ…еҰӮжһңжңү10000жқЎж•°жҚ®иў«еҶҷе…ҘпјҢеҲҷдә§з”ҹдёҖж¬Ўеҝ«з…§ В stop-writes-on-bgsave-errorВ yesВ В #stop-writes-on-bgsave-errorВ пјҡ В еҰӮжһңдёәyesеҲҷиЎЁзӨәпјҢеҪ“еӨҮд»ҪиҝӣзЁӢеҮәй”ҷзҡ„ж—¶еҖҷпјҢ В дё»иҝӣзЁӢе°ұеҒңжӯўиҝӣиЎҢжҺҘеҸ—ж–°зҡ„еҶҷе…Ҙж“ҚдҪңпјҢиҝҷж ·жҳҜдёәдәҶдҝқжҠӨжҢҒд№…еҢ–зҡ„ж•°жҚ®дёҖиҮҙжҖ§зҡ„й—®йўҳгҖӮ
RDBзҡ„еҲӣе»әдёҺиҪҪе…Ҙ
SAVE:йҳ»еЎһRedisзҡ„жңҚеҠЎеҷЁиҝӣзЁӢпјҢзӣҙеҲ°RDBж–Ү件被еҲӣе»әе®ҢжҜ•гҖӮSAVEе‘Ҫд»ӨеҫҲе°‘иў«дҪҝз”ЁпјҢеӣ дёәе…¶дјҡйҳ»еЎһдё»зәҝзЁӢжқҘдҝқиҜҒеҝ«з…§зҡ„еҶҷе…ҘпјҢз”ұдәҺRedisжҳҜдҪҝз”ЁдёҖдёӘдё»зәҝзЁӢжқҘжҺҘ收жүҖжңүе®ўжҲ·з«ҜиҜ·жұӮпјҢиҝҷж ·дјҡйҳ»еЎһжүҖжңүе®ўжҲ·з«ҜиҜ·жұӮгҖӮ
BGSAVE:иҜҘжҢҮд»ӨдјҡForkеҮәдёҖдёӘеӯҗиҝӣзЁӢжқҘеҲӣе»әRDBж–Ү件пјҢдёҚйҳ»еЎһжңҚеҠЎеҷЁиҝӣзЁӢпјҢеӯҗиҝӣзЁӢжҺҘ收иҜ·жұӮ并еҲӣе»әRDBеҝ«з…§пјҢзҲ¶иҝӣзЁӢ继з»ӯжҺҘ收客жҲ·з«Ҝзҡ„иҜ·жұӮгҖӮеӯҗиҝӣзЁӢеңЁе®ҢжҲҗж–Ү件зҡ„еҲӣе»әж—¶дјҡеҗ‘зҲ¶иҝӣзЁӢеҸ‘йҖҒдҝЎеҸ·пјҢзҲ¶иҝӣзЁӢеңЁжҺҘ收客жҲ·з«ҜиҜ·жұӮзҡ„иҝҮзЁӢдёӯпјҢеңЁдёҖе®ҡзҡ„ж—¶й—ҙй—ҙйҡ”йҖҡиҝҮиҪ®иҜўжқҘжҺҘ收еӯҗиҝӣзЁӢзҡ„дҝЎеҸ·гҖӮжҲ‘们д№ҹеҸҜд»ҘйҖҡиҝҮдҪҝз”ЁlastsaveжҢҮд»ӨжқҘжҹҘзңӢbgsaveжҳҜеҗҰжү§иЎҢжҲҗеҠҹпјҢlastsaveеҸҜд»Ҙиҝ”еӣһжңҖеҗҺдёҖж¬Ўжү§иЎҢжҲҗеҠҹbgsaveзҡ„ж—¶й—ҙгҖӮ
иҮӘеҠЁеҢ–и§ҰеҸ‘RDBжҢҒд№…еҢ–зҡ„ж–№ејҸ
1.ж №жҚ®redis.confй…ҚзҪ®йҮҢзҡ„SAVE m n е®ҡж—¶и§ҰеҸ‘пјҲе®һйҷ…дёҠдҪҝз”Ёзҡ„жҳҜBGSAVEпјү
2.дё»д»ҺеӨҚеҲ¶ж—¶пјҢдё»иҠӮзӮ№иҮӘеҠЁи§ҰеҸ‘гҖӮ
3.жү§иЎҢDebug Reload
4.жү§иЎҢShutdownдё”жІЎжңүејҖеҗҜAOFжҢҒд№…еҢ–гҖӮ
BGSAVEзҡ„еҺҹзҗҶ
еҗҜеҠЁпјҡ
1.жЈҖжҹҘжҳҜеҗҰеӯҳеңЁеӯҗиҝӣзЁӢжӯЈеңЁжү§иЎҢAOFжҲ–иҖ…RDBзҡ„жҢҒд№…еҢ–д»»еҠЎгҖӮеҰӮжһңжңүеҲҷиҝ”еӣһfalseгҖӮ
2.и°ғз”ЁRedisжәҗз Ғдёӯзҡ„rdbSaveBackgroundж–№жі•пјҢж–№жі•дёӯжү§иЎҢfork()дә§з”ҹеӯҗиҝӣзЁӢжү§иЎҢrdbж“ҚдҪңгҖӮ
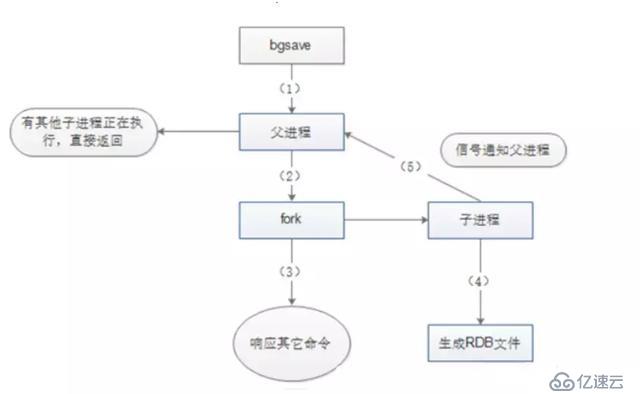
3.е…ідәҺfork()дёӯзҡ„Copy-On-Write
fork()еңЁlinuxдёӯеҲӣе»әеӯҗиҝӣзЁӢйҮҮз”ЁCopy-On-WriteпјҲеҶҷж—¶жӢ·иҙқжҠҖжңҜпјүпјҢеҚіеҰӮжһңжңүеӨҡдёӘи°ғз”ЁиҖ…еҗҢж—¶иҰҒжұӮзӣёеҗҢиө„жәҗпјҲеҰӮеҶ…еӯҳжҲ–зЈҒзӣҳдёҠзҡ„ж•°жҚ®еӯҳеӮЁпјүпјҢ他们дјҡе…ұеҗҢиҺ·еҸ–зӣёеҗҢзҡ„жҢҮй’ҲжҢҮеҗ‘зӣёеҗҢзҡ„иө„жәҗпјҢзӣҙеҲ°жҹҗдёӘи°ғз”ЁиҖ…иҜ•еӣҫдҝ®ж”№иө„жәҗзҡ„еҶ…е®№ж—¶пјҢзі»з»ҹжүҚдјҡзңҹжӯЈеӨҚеҲ¶дёҖд»Ҫдё“з”ЁеүҜжң¬з»ҷи°ғз”ЁиҖ…пјҢиҖҢе…¶е®ғи°ғз”ЁиҖ…жүҖи§ҒеҲ°зҡ„жңҖеҲқзҡ„иө„жәҗд»Қ然дҝқжҢҒдёҚеҸҳгҖӮ
RDBжҢҒд№…еҢ–ж–№ејҸзҡ„зјәзӮ№
1.еҶ…еӯҳж•°жҚ®е…ЁйҮҸеҗҢжӯҘпјҢж•°жҚ®йҮҸеӨ§зҡ„зҠ¶еҶөдёӢпјҢдјҡз”ұдәҺI/OиҖҢдёҘйҮҚеҪұе“ҚжҖ§иғҪгҖӮ
2.еҸҜиғҪдјҡеӣ дёәRedisе®•жңәиҖҢдёўеӨұд»ҺеҪ“еүҚиҮіжңҖиҝ‘дёҖж¬Ўеҝ«з…§жңҹй—ҙзҡ„ж•°жҚ®гҖӮ
AOF(Append-Only-File)жҢҒд№…еҢ–:дҝқеӯҳеҶҷзҠ¶жҖҒ
AOFжҢҒд№…еҢ–жҳҜйҖҡиҝҮдҝқеӯҳRedisзҡ„еҶҷзҠ¶жҖҒжқҘи®°еҪ•ж•°жҚ®еә“зҡ„гҖӮзӣёеҜ№RDBжқҘиҜҙпјҢRDBжҢҒд№…еҢ–жҳҜйҖҡиҝҮеӨҮд»Ҫж•°жҚ®еә“зҡ„зҠ¶жҖҒжқҘи®°еҪ•ж•°жҚ®еә“пјҢиҖҢAOFжҢҒд№…еҢ–жҳҜеӨҮд»Ҫж•°жҚ®еә“жҺҘ收еҲ°зҡ„жҢҮд»ӨгҖӮ
1.AOFи®°еҪ•йҷӨдәҶжҹҘиҜўд»ҘеӨ–зҡ„жүҖжңүеҸҳжӣҙж•°жҚ®еә“зҠ¶жҖҒзҡ„жҢҮд»ӨгҖӮ
2.д»ҘеўһйҮҸзҡ„еҪўејҸиҝҪеҠ дҝқеӯҳеҲ°AOFж–Ү件дёӯгҖӮ
ејҖеҗҜAOFжҢҒд№…еҢ–
1.жү“ејҖredis.confй…ҚзҪ®ж–Ү件,е°ҶappendonlyеұһжҖ§ж”№дёәyesгҖӮ
2.дҝ®ж”№appendfsyncеұһжҖ§пјҢиҜҘеұһжҖ§еҸҜд»ҘжҺҘ收дёүз§ҚеҸӮж•°пјҢеҲҶеҲ«жҳҜalways,everysec,no,alwaysиЎЁзӨәжҖ»жҳҜеҚіж—¶е°Ҷзј“еҶІеҢәеҶ…е®№еҶҷе…ҘAOFж–Ү件еҪ“дёӯпјҢeverysecиЎЁзӨәжҜҸйҡ”дёҖз§’е°Ҷзј“еҶІеҢәеҶ…е®№еҶҷе…ҘAOFж–Ү件пјҢnoиЎЁзӨәе°ҶеҶҷе…Ҙж–Ү件ж“ҚдҪңдәӨз”ұж“ҚдҪңзі»з»ҹеҶіе®ҡпјҢдёҖиҲ¬жқҘиҜҙпјҢж“ҚдҪңзі»з»ҹиҖғиҷ‘ж•ҲзҺҮй—®йўҳпјҢдјҡзӯүеҫ…зј“еҶІеҢәиў«еЎ«ж»ЎеҶҚе°Ҷзј“еҶІеҢәж•°жҚ®еҶҷе…ҘAOFж–Ү件дёӯгҖӮ
В appendonlyВ yes В #appendsyncВ always В appendfsyncВ everysec В #В appendfsyncВ no
ж—Ҙеҝ—йҮҚеҶҷи§ЈеҶіAOFж–Ү件дёҚж–ӯеўһеӨ§зҡ„й—®йўҳ
йҡҸзқҖеҶҷж“ҚдҪңзҡ„дёҚж–ӯеўһеҠ пјҢAOFж–Ү件дјҡи¶ҠжқҘи¶ҠеӨ§гҖӮеҒҮи®ҫйҖ’еўһдёҖдёӘи®Ўж•°еҷЁ100ж¬ЎпјҢеҰӮжһңдҪҝз”ЁRDBжҢҒд№…еҢ–ж–№ејҸпјҢжҲ‘们еҸӘиҰҒдҝқеӯҳжңҖз»Ҳз»“жһң100еҚіеҸҜпјҢиҖҢAOFжҢҒд№…еҢ–ж–№ејҸйңҖиҰҒи®°еҪ•дёӢиҝҷ100ж¬ЎйҖ’еўһж“ҚдҪңзҡ„жҢҮд»ӨпјҢиҖҢдәӢе®һдёҠиҰҒжҒўеӨҚиҝҷжқЎи®°еҪ•пјҢеҸӘйңҖиҰҒжү§иЎҢдёҖжқЎе‘Ҫд»Өе°ұиЎҢпјҢжүҖд»ҘйӮЈдёҖзҷҫжқЎе‘Ҫд»Өе®һйҷ…еҸҜд»ҘзІҫз®ҖдёәдёҖжқЎгҖӮRedisж”ҜжҢҒиҝҷж ·зҡ„еҠҹиғҪпјҢеңЁдёҚдёӯж–ӯеүҚеҸ°жңҚеҠЎзҡ„жғ…еҶөдёӢпјҢеҸҜд»ҘйҮҚеҶҷAOFж–Ү件пјҢеҗҢж ·дҪҝз”ЁеҲ°дәҶCOWпјҲеҶҷж—¶жӢ·иҙқпјүгҖӮйҮҚеҶҷиҝҮзЁӢеҰӮдёӢпјҡ
1.и°ғз”Ёfork()пјҢеҲӣе»әдёҖдёӘеӯҗиҝӣзЁӢгҖӮ
2.еӯҗиҝӣзЁӢжҠҠж–°зҡ„AOFеҶҷеҲ°дёҖдёӘдёҙж—¶ж–Ү件йҮҢпјҢдёҚдҫқиө–еҺҹжқҘзҡ„AOFж–Ү件гҖӮ
3.дё»иҝӣзЁӢжҢҒз»ӯе°Ҷж–°зҡ„еҸҳеҠЁеҗҢж—¶еҶҷеҲ°еҶ…еӯҳе’ҢеҺҹжқҘзҡ„AOFйҮҢгҖӮ
4.дё»иҝӣзЁӢиҺ·еҸ–еӯҗиҝӣзЁӢйҮҚеҶҷAOFзҡ„е®ҢжҲҗдҝЎеҸ·пјҢеҫҖж–°AOFеҗҢжӯҘеўһйҮҸеҸҳеҠЁгҖӮ
5.дҪҝз”Ёж–°зҡ„AOFж–Ү件жӣҝжҚўжҺүж—§зҡ„AOFж–Ү件гҖӮ
AOFе’ҢRDBзҡ„дјҳзјәзӮ№
RDBдјҳзӮ№пјҡе…ЁйҮҸж•°жҚ®еҝ«з…§пјҢж–Ү件е°ҸпјҢжҒўеӨҚеҝ«гҖӮ
RDBзјәзӮ№пјҡж— жі•дҝқеӯҳжңҖиҝ‘дёҖж¬Ўеҝ«з…§д№ӢеҗҺзҡ„ж•°жҚ®гҖӮ
AOFдјҳзӮ№пјҡеҸҜиҜ»жҖ§й«ҳпјҢйҖӮеҗҲдҝқеӯҳеўһйҮҸж•°жҚ®пјҢж•°жҚ®дёҚжҳ“дёўеӨұгҖӮ
AOFзјәзӮ№пјҡж–Ү件дҪ“з§ҜеӨ§пјҢжҒўеӨҚж—¶й—ҙй•ҝгҖӮ
RDB-AOFж··еҗҲжҢҒд№…еҢ–ж–№ејҸ
redis4.0д№ӢеҗҺжҺЁеҮәдәҶжӯӨз§ҚжҢҒд№…еҢ–ж–№ејҸпјҢRDBдҪңдёәе…ЁйҮҸеӨҮд»ҪпјҢAOFдҪңдёәеўһйҮҸеӨҮд»ҪпјҢ并且е°ҶжӯӨз§Қж–№ејҸдҪңдёәй»ҳи®Өж–№ејҸдҪҝз”ЁгҖӮ
еңЁдёҠиҝ°дёӨз§Қж–№ејҸдёӯпјҢRDBж–№ејҸжҳҜе°Ҷе…ЁйҮҸж•°жҚ®еҶҷе…ҘRDBж–Ү件пјҢиҝҷж ·еҶҷе…Ҙзҡ„зү№зӮ№жҳҜж–Ү件е°ҸпјҢжҒўеӨҚеҝ«пјҢдҪҶж— жі•дҝқеӯҳжңҖиҝ‘дёҖж¬Ўеҝ«з…§д№ӢеҗҺзҡ„ж•°жҚ®пјҢAOFеҲҷе°ҶredisжҢҮд»Өеӯҳе…Ҙж–Ү件дёӯпјҢиҝҷж ·еҸҲдјҡйҖ жҲҗж–Ү件дҪ“з§ҜеӨ§пјҢжҒўеӨҚж—¶й—ҙй•ҝзӯүејұзӮ№гҖӮ
еңЁRDB-AOFж–№ејҸдёӢпјҢжҢҒд№…еҢ–зӯ–з•ҘйҰ–е…Ҳе°Ҷзј“еӯҳдёӯж•°жҚ®д»ҘRDBж–№ејҸе…ЁйҮҸеҶҷе…Ҙж–Ү件пјҢеҶҚе°ҶеҶҷе…ҘеҗҺж–°еўһзҡ„ж•°жҚ®д»ҘAOFзҡ„ж–№ејҸиҝҪеҠ еңЁRDBж•°жҚ®зҡ„еҗҺйқўпјҢеңЁдёӢдёҖж¬ЎеҒҡRDBжҢҒд№…еҢ–зҡ„ж—¶еҖҷе°ҶAOFзҡ„ж•°жҚ®йҮҚж–°д»ҘRDBзҡ„еҪўејҸеҶҷе…Ҙж–Ү件гҖӮиҝҷз§Қж–№ејҸж—ўеҸҜд»ҘжҸҗй«ҳиҜ»еҶҷе’ҢжҒўеӨҚж•ҲзҺҮпјҢд№ҹеҸҜд»ҘеҮҸе°‘ж–Ү件еӨ§е°ҸпјҢеҗҢж—¶еҸҜд»ҘдҝқиҜҒж•°жҚ®зҡ„е®Ңж•ҙжҖ§гҖӮеңЁжӯӨз§Қзӯ–з•Ҙзҡ„жҢҒд№…еҢ–иҝҮзЁӢдёӯпјҢеӯҗиҝӣзЁӢдјҡйҖҡиҝҮз®ЎйҒ“д»ҺзҲ¶иҝӣзЁӢиҜ»еҸ–еўһйҮҸж•°жҚ®пјҢеңЁд»ҘRDBж јејҸдҝқеӯҳе…ЁйҮҸж•°жҚ®ж—¶пјҢд№ҹдјҡйҖҡиҝҮз®ЎйҒ“иҜ»еҸ–ж•°жҚ®пјҢеҗҢж—¶дёҚдјҡйҖ жҲҗз®ЎйҒ“йҳ»еЎһгҖӮеҸҜд»ҘиҜҙпјҢеңЁжӯӨз§Қж–№ејҸдёӢзҡ„жҢҒд№…еҢ–ж–Ү件пјҢеүҚеҚҠж®өжҳҜRDBж јејҸзҡ„е…ЁйҮҸж•°жҚ®пјҢеҗҺеҚҠж®өжҳҜAOFж јејҸзҡ„еўһйҮҸж•°жҚ®гҖӮжӯӨз§Қж–№ејҸжҳҜзӣ®еүҚиҫғдёәжҺЁиҚҗзҡ„дёҖз§ҚжҢҒд№…еҢ–ж–№ејҸгҖӮ
Redisж•°жҚ®зҡ„жҒўеӨҚ
RDBе’ҢAOFж–Ү件е…ұеӯҳжғ…еҶөдёӢзҡ„жҒўеӨҚжөҒзЁӢ
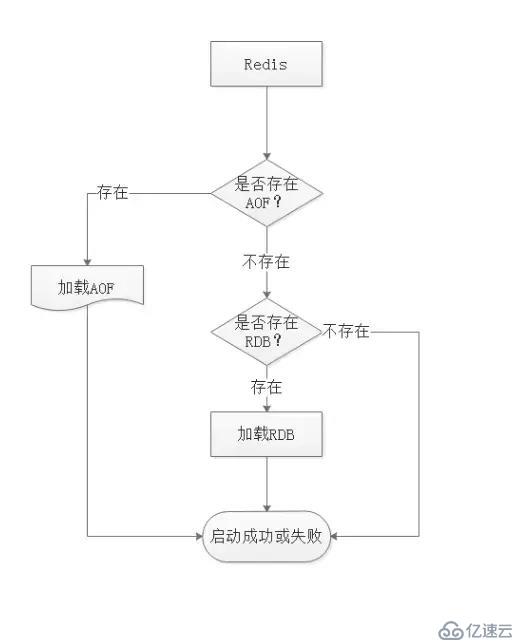
д»ҺеӣҫеҸҜзҹҘпјҢRedisеҗҜеҠЁж—¶дјҡе…ҲжЈҖжҹҘAOFжҳҜеҗҰеӯҳеңЁпјҢеҰӮжһңAOFеӯҳеңЁеҲҷзӣҙжҺҘеҠ иҪҪAOFпјҢеҰӮжһңдёҚеӯҳеңЁAOFпјҢеҲҷзӣҙжҺҘеҠ иҪҪRDBж–Ү件гҖӮ
Pineline
Pipelineе’ҢLinuxзҡ„з®ЎйҒ“зұ»дјјпјҢе®ғеҸҜд»Ҙи®©Redisжү№йҮҸжү§иЎҢжҢҮд»ӨгҖӮ
RedisеҹәдәҺиҜ·жұӮ/е“Қеә”жЁЎеһӢпјҢеҚ•дёӘиҜ·жұӮеӨ„зҗҶйңҖиҰҒдёҖдёҖеә”зӯ”гҖӮеҰӮжһңйңҖиҰҒеҗҢж—¶жү§иЎҢеӨ§йҮҸе‘Ҫд»ӨпјҢеҲҷжҜҸжқЎе‘Ҫд»ӨйғҪйңҖиҰҒзӯүеҫ…дёҠдёҖжқЎе‘Ҫд»Өжү§иЎҢе®ҢжҜ•еҗҺжүҚиғҪ继з»ӯжү§иЎҢпјҢиҝҷдёӯй—ҙдёҚд»…д»…еӨҡдәҶRTT,иҝҳеӨҡж¬ЎдҪҝз”ЁдәҶзі»з»ҹIOгҖӮPipelineз”ұдәҺеҸҜд»Ҙжү№йҮҸжү§иЎҢжҢҮд»ӨпјҢжүҖд»ҘеҸҜд»ҘиҠӮзңҒеӨҡж¬ЎIOе’ҢиҜ·жұӮе“Қеә”еҫҖиҝ”зҡ„ж—¶й—ҙгҖӮдҪҶжҳҜеҰӮжһңжҢҮд»Өд№Ӣй—ҙеӯҳеңЁдҫқиө–е…ізі»пјҢеҲҷе»әи®®еҲҶжү№еҸ‘йҖҒжҢҮд»ӨгҖӮ
Redisзҡ„еҗҢжӯҘжңәеҲ¶
дё»д»ҺеҗҢжӯҘеҺҹзҗҶ
RedisдёҖиҲ¬жҳҜдҪҝз”ЁдёҖдёӘMasterиҠӮзӮ№жқҘиҝӣиЎҢеҶҷж“ҚдҪңпјҢиҖҢиӢҘе№ІдёӘSlaveиҠӮзӮ№иҝӣиЎҢиҜ»ж“ҚдҪңпјҢMasterе’ҢSlaveеҲҶеҲ«д»ЈиЎЁдәҶдёҖдёӘдёӘдёҚеҗҢзҡ„RedisServerе®һдҫӢпјҢеҸҰеӨ–е®ҡжңҹзҡ„ж•°жҚ®еӨҮд»Ҫж“ҚдҪңд№ҹжҳҜеҚ•зӢ¬йҖүжӢ©дёҖдёӘSlaveеҺ»е®ҢжҲҗпјҢиҝҷж ·еҸҜд»ҘжңҖеӨ§зЁӢеәҰеҸ‘жҢҘRedisзҡ„жҖ§иғҪпјҢдёәзҡ„жҳҜдҝқиҜҒж•°жҚ®зҡ„ејұдёҖиҮҙжҖ§е’ҢжңҖз»ҲдёҖиҮҙжҖ§гҖӮеҸҰеӨ–пјҢMasterе’ҢSlaveзҡ„ж•°жҚ®дёҚжҳҜдёҖе®ҡиҰҒеҚіж—¶еҗҢжӯҘзҡ„пјҢдҪҶжҳҜеңЁдёҖж®өж—¶й—ҙеҗҺMasterе’ҢSlaveзҡ„ж•°жҚ®жҳҜи¶ӢдәҺеҗҢжӯҘзҡ„пјҢиҝҷе°ұжҳҜжңҖз»ҲдёҖиҮҙжҖ§гҖӮ
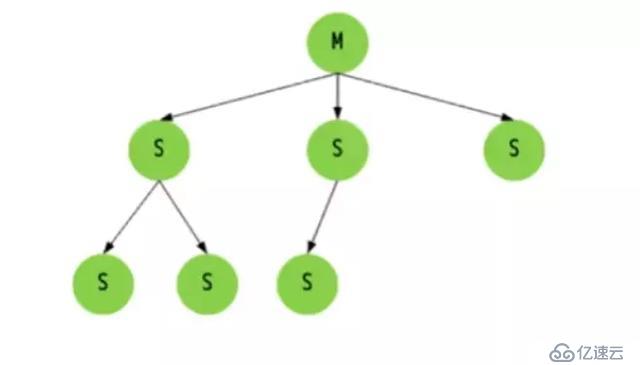
е…ЁеҗҢжӯҘиҝҮзЁӢ
1.SlaveеҸ‘йҖҒsyncе‘Ҫд»ӨеҲ°MasterгҖӮ
2.MasterеҗҜеҠЁдёҖдёӘеҗҺеҸ°иҝӣзЁӢпјҢе°ҶRedisдёӯзҡ„ж•°жҚ®еҝ«з…§дҝқеӯҳеҲ°ж–Ү件дёӯгҖӮ
3.Masterе°Ҷдҝқеӯҳж•°жҚ®еҝ«з…§жңҹй—ҙжҺҘ收еҲ°зҡ„еҶҷе‘Ҫд»Өзј“еӯҳиө·жқҘгҖӮ
4.Masterе®ҢжҲҗеҶҷж–Ү件ж“ҚдҪңеҗҺпјҢе°ҶиҜҘж–Ү件еҸ‘йҖҒз»ҷSlaveгҖӮ
5.дҪҝз”Ёж–°зҡ„AOFж–Ү件жӣҝжҚўжҺүж—§зҡ„AOFж–Ү件гҖӮ
6.Masterе°Ҷиҝҷжңҹй—ҙ收йӣҶзҡ„еўһйҮҸеҶҷе‘Ҫд»ӨеҸ‘йҖҒз»ҷSlaveз«ҜгҖӮ
еўһйҮҸеҗҢжӯҘиҝҮзЁӢ
1.MasterжҺҘ收еҲ°з”ЁжҲ·зҡ„ж“ҚдҪңжҢҮд»ӨпјҢеҲӨж–ӯжҳҜеҗҰйңҖиҰҒдј ж’ӯеҲ°SlaveгҖӮ
2.е°Ҷж“ҚдҪңи®°еҪ•иҝҪеҠ еҲ°AOFж–Ү件гҖӮ
3.е°Ҷж“ҚдҪңдј ж’ӯеҲ°е…¶е®ғSlaveпјҡ1.еҜ№йҪҗдё»д»Һеә“пјӣ2.еҫҖе“Қеә”зј“еӯҳеҶҷе…ҘжҢҮд»ӨгҖӮ
4.е°Ҷзј“еӯҳдёӯзҡ„ж•°жҚ®еҸ‘йҖҒз»ҷSlaveгҖӮ
Redis SentinelпјҲе“Ёе…өпјү
дё»д»ҺжЁЎејҸејҠз«ҜпјҡеҪ“Masterе®•жңәеҗҺпјҢRedisйӣҶзҫӨе°ҶдёҚиғҪеҜ№еӨ–жҸҗдҫӣеҶҷе…Ҙж“ҚдҪңгҖӮRedis SentinelеҸҜи§ЈеҶіиҝҷдёҖй—®йўҳгҖӮ
и§ЈеҶідё»д»ҺеҗҢжӯҘMasterе®•жңәеҗҺзҡ„дё»д»ҺеҲҮжҚўй—®йўҳпјҡ
1.зӣ‘жҺ§пјҡжЈҖжҹҘдё»д»ҺжңҚеҠЎеҷЁжҳҜеҗҰиҝҗиЎҢжӯЈеёёгҖӮ
2.жҸҗйҶ’пјҡйҖҡиҝҮAPIеҗ‘з®ЎзҗҶе‘ҳжҲ–иҖ…е…¶е®ғеә”з”ЁзЁӢеәҸеҸ‘йҖҒж•…йҡңйҖҡзҹҘгҖӮ
3.иҮӘеҠЁж•…йҡңиҝҒ移пјҡдё»д»ҺеҲҮжҚўпјҲеңЁMasterе®•жңәеҗҺпјҢе°Ҷе…¶дёӯдёҖдёӘSlaveиҪ¬дёәMasterпјҢе…¶д»–зҡ„
Slaveд»ҺиҜҘиҠӮзӮ№еҗҢжӯҘж•°жҚ®пјүгҖӮ
RedisйӣҶзҫӨ
еҺҹзҗҶпјҡеҰӮдҪ•д»Һжө·йҮҸж•°жҚ®йҮҢеҝ«йҖҹжүҫеҲ°жүҖйңҖпјҹ
еҲҶзүҮ
жҢүз…§жҹҗз§Қ规еҲҷеҺ»еҲ’еҲҶж•°жҚ®пјҢеҲҶж•ЈеӯҳеӮЁеңЁеӨҡдёӘиҠӮзӮ№дёҠгҖӮйҖҡиҝҮе°Ҷж•°жҚ®еҲҶеҲ°еӨҡдёӘRedisжңҚеҠЎеҷЁдёҠпјҢжқҘеҮҸиҪ»еҚ•дёӘRedisжңҚеҠЎеҷЁзҡ„еҺӢеҠӣгҖӮ
дёҖиҮҙжҖ§Hashз®—жі•
既然иҰҒе°Ҷж•°жҚ®иҝӣиЎҢеҲҶзүҮпјҢйӮЈд№ҲйҖҡеёёзҡ„еҒҡжі•е°ұжҳҜиҺ·еҸ–иҠӮзӮ№зҡ„HashеҖјпјҢ然еҗҺж №жҚ®иҠӮзӮ№ж•°жұӮжЁЎпјҢдҪҶиҝҷж ·зҡ„ж–№жі•жңүжҳҺжҳҫзҡ„ејҠз«ҜпјҢеҪ“RedisиҠӮзӮ№ж•°йңҖиҰҒеҠЁжҖҒеўһеҠ жҲ–еҮҸе°‘зҡ„ж—¶еҖҷпјҢдјҡйҖ жҲҗеӨ§йҮҸзҡ„Keyж— жі•иў«е‘ҪдёӯгҖӮжүҖд»ҘRedisдёӯеј•е…ҘдәҶдёҖиҮҙжҖ§Hashз®—жі•гҖӮиҜҘз®—жі•еҜ№2^32 еҸ–жЁЎпјҢе°ҶHashеҖјз©әй—ҙз»„жҲҗиҷҡжӢҹзҡ„еңҶзҺҜпјҢж•ҙдёӘеңҶзҺҜжҢүйЎәж—¶й’Ҳж–№еҗ‘з»„з»ҮпјҢжҜҸдёӘиҠӮзӮ№дҫқж¬Ўдёә0гҖҒ1гҖҒ2...2^32-1пјҢд№ӢеҗҺе°ҶжҜҸдёӘжңҚеҠЎеҷЁиҝӣиЎҢHashиҝҗз®—пјҢзЎ®е®ҡжңҚеҠЎеҷЁеңЁиҝҷдёӘHashзҺҜдёҠзҡ„ең°еқҖпјҢзЎ®е®ҡдәҶжңҚеҠЎеҷЁең°еқҖеҗҺпјҢеҜ№ж•°жҚ®дҪҝз”ЁеҗҢж ·зҡ„Hashз®—жі•пјҢе°Ҷж•°жҚ®е®ҡдҪҚеҲ°зү№е®ҡзҡ„RedisжңҚеҠЎеҷЁдёҠгҖӮеҰӮжһңе®ҡдҪҚеҲ°зҡ„ең°ж–№жІЎжңүRedisжңҚеҠЎеҷЁе®һдҫӢпјҢеҲҷ继з»ӯйЎәж—¶й’ҲеҜ»жүҫпјҢжүҫеҲ°зҡ„第дёҖеҸ°жңҚеҠЎеҷЁеҚіиҜҘж•°жҚ®жңҖз»Ҳзҡ„жңҚеҠЎеҷЁдҪҚзҪ®гҖӮ
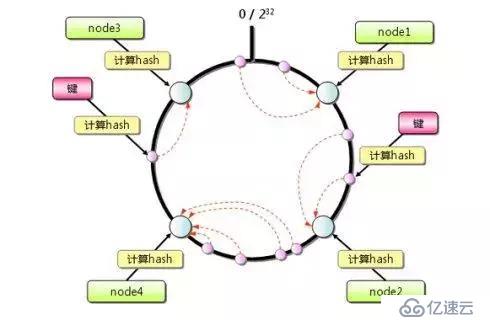
HashзҺҜзҡ„ж•°жҚ®еҖҫж–ңй—®йўҳ
HashзҺҜеңЁжңҚеҠЎеҷЁиҠӮзӮ№еҫҲе°‘зҡ„ж—¶еҖҷпјҢе®№жҳ“йҒҮеҲ°жңҚеҠЎеҷЁиҠӮзӮ№дёҚеқҮеҢҖзҡ„й—®йўҳпјҢиҝҷдјҡйҖ жҲҗж•°жҚ®еҖҫж–ңпјҢж•°жҚ®еҖҫж–ңжҢҮзҡ„жҳҜиў«зј“еӯҳзҡ„еҜ№иұЎеӨ§йғЁеҲҶйӣҶдёӯеңЁRedisйӣҶзҫӨзҡ„е…¶дёӯдёҖеҸ°жҲ–еҮ еҸ°жңҚеҠЎеҷЁдёҠгҖӮ
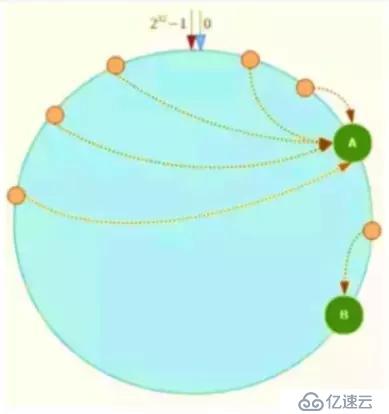
еҰӮдёҠеӣҫпјҢдёҖиҮҙжҖ§Hashз®—жі•иҝҗз®—еҗҺзҡ„ж•°жҚ®еӨ§йғЁеҲҶиў«еӯҳж”ҫеңЁAиҠӮзӮ№дёҠпјҢиҖҢBиҠӮзӮ№еҸӘеӯҳж”ҫдәҶе°‘йҮҸзҡ„ж•°жҚ®пјҢд№…иҖҢд№…д№ӢAиҠӮзӮ№е°Ҷиў«ж’‘зҲҶгҖӮ
й’ҲеҜ№иҝҷдёҖй—®йўҳпјҢеҸҜд»Ҙеј•е…ҘиҷҡжӢҹиҠӮзӮ№и§ЈеҶігҖӮз®ҖеҚ•ең°иҜҙпјҢе°ұжҳҜдёәжҜҸдёҖдёӘжңҚеҠЎеҷЁиҠӮзӮ№и®Ўз®—еӨҡдёӘHashпјҢжҜҸдёӘи®Ўз®—з»“жһңдҪҚзҪ®йғҪж”ҫзҪ®дёҖдёӘжӯӨжңҚеҠЎеҷЁиҠӮзӮ№пјҢз§°дёәиҷҡжӢҹиҠӮзӮ№пјҢеҸҜд»ҘеңЁжңҚеҠЎеҷЁIPжҲ–иҖ…дё»жңәеҗҚеҗҺж”ҫзҪ®дёҖдёӘзј–еҸ·е®һзҺ°гҖӮ
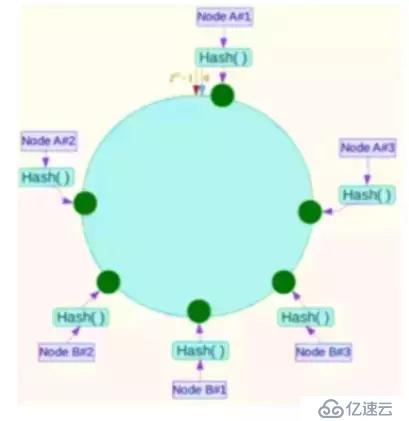
дҫӢеҰӮдёҠеӣҫпјҡе°ҶNodeAе’ҢNodeBдёӨдёӘиҠӮзӮ№еҲҶдёәNode A#1-A#3 NodeB#1-B#3гҖӮ
з»“иҜӯ
иҝҷзҜҮеҮҶ(tou)еӨҮ(lan)дәҶзӣёеҪ“д№…зҡ„ж—¶й—ҙпјҢеӣ дёәжңүдәӣдёңиҘҝжҖ»ж„ҹи§үиҮӘе·ұжӢҝдёҚеҮҶдёҚж•ўеҫҖдёҠеҶҷпјҢе·®зӮ№иҮӘй—ӯпјҢе°ұз®—зҺ°еңЁеҸ‘еҮәжқҘдәҶд№ҹж„ҹи§үжңүеҫҲеӨҡең°ж–№жҳҜйңҖиҰҒж”№еҠЁзҡ„гҖӮеҰӮжһңжңүеҗҢеӯҰи§үеҫ—е“ӘйҮҢеҶҷзҡ„дёҚеҜ№еҠІзҡ„пјҢиҜ„и®әеҢәжҲ–иҖ…з§ҒиҒҠжҲ‘...е—ҜпјҢжҲ‘дёҚиҰҒдҪ и§үеҫ—пјҢжҲ‘иҰҒжҲ‘и§үеҫ—гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ