您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
在构建模型时,调参是极为重要的一个步骤,因为只有选择最佳的参数才能构建一个最优的模型。但是应该如何确定参数的值呢?所以这里记录一下选择参数的方法,以便后期复习以及分享。
(除了贝叶斯优化等方法)其它简单的验证有两种方法:
1、通过经常使用某个模型的经验和高超的数学知识。
2、通过交叉验证的方法,逐个来验证。
很显然我是属于后者所以我需要在这里记录一下
sklearn 的 cross_val_score:
我使用是cross_val_score方法,在sklearn中可以使用这个方法。交叉验证的原理不好表述下面随手画了一个图:
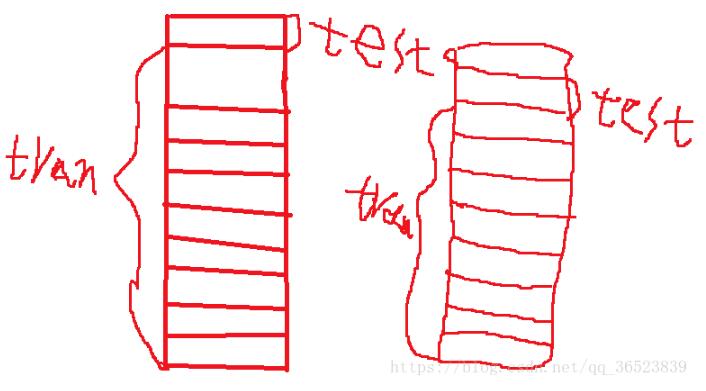
(我都没见过这么丑的图)简单说下,比如上面,我们将数据集分为10折,做一次交叉验证,实际上它是计算了十次,将每一折都当做一次测试集,其余九折当做训练集,这样循环十次。通过传入的模型,训练十次,最后将十次结果求平均值。将每个数据集都算一次
交叉验证优点:
1:交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。
2:还可以从有限的数据中获取尽可能多的有效信息。
我们如何利用它来选择参数呢?
我们可以给它加上循环,通过循环不断的改变参数,再利用交叉验证来评估不同参数模型的能力。最终选择能力最优的模型。
下面通过一个简单的实例来说明:(iris鸢尾花)
from sklearn import datasets #自带数据集
from sklearn.model_selection import train_test_split,cross_val_score #划分数据 交叉验证
from sklearn.neighbors import KNeighborsClassifier #一个简单的模型,只有K一个参数,类似K-means
import matplotlib.pyplot as plt
iris = datasets.load_iris() #加载sklearn自带的数据集
X = iris.data #这是数据
y = iris.target #这是每个数据所对应的标签
train_X,test_X,train_y,test_y = train_test_split(X,y,test_size=1/3,random_state=3) #这里划分数据以1/3的来划分 训练集训练结果 测试集测试结果
k_range = range(1,31)
cv_scores = [] #用来放每个模型的结果值
for n in k_range:
knn = KNeighborsClassifier(n) #knn模型,这里一个超参数可以做预测,当多个超参数时需要使用另一种方法GridSearchCV
scores = cross_val_score(knn,train_X,train_y,cv=10,scoring='accuracy') #cv:选择每次测试折数 accuracy:评价指标是准确度,可以省略使用默认值,具体使用参考下面。
cv_scores.append(scores.mean())
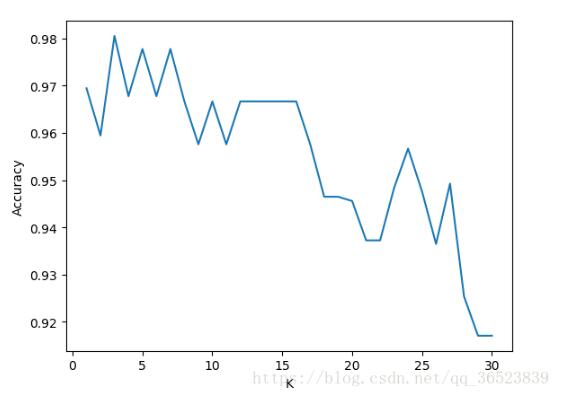
plt.plot(k_range,cv_scores)
plt.xlabel('K')
plt.ylabel('Accuracy') #通过图像选择最好的参数
plt.show()
best_knn = KNeighborsClassifier(n_neighbors=3) # 选择最优的K=3传入模型
best_knn.fit(train_X,train_y) #训练模型
print(best_knn.score(test_X,test_y)) #看看评分
最后得分0.94
关于 cross_val_score 的 scoring 参数的选择,通过查看官方文档后可以发现相关指标的选择可以在这里找到:文档。
这应该是比较简单的一个例子了,上面的注释也比较清楚,如果我表达不清楚可以问我。
补充拓展:sklearn分类算法汇总
废话不多说,上代码吧!
import os
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn import preprocessing
from sklearn import neighbors
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from time import time
from sklearn.naive_bayes import MultinomialNB
from sklearn import tree
from sklearn.ensemble import GradientBoostingClassifier
#读取sklearn自带的数据集(鸢尾花)
def getData_1():
iris = datasets.load_iris()
X = iris.data #样本特征矩阵,150*4矩阵,每行一个样本,每个样本维度是4
y = iris.target #样本类别矩阵,150维行向量,每个元素代表一个样本的类别
#读取本地excel表格内的数据集(抽取每类60%样本组成训练集,剩余样本组成测试集)
#返回一个元祖,其内有4个元素(类型均为numpy.ndarray):
#(1)归一化后的训练集矩阵,每行为一个训练样本,矩阵行数=训练样本总数,矩阵列数=每个训练样本的特征数
#(2)每个训练样本的类标
#(3)归一化后的测试集矩阵,每行为一个测试样本,矩阵行数=测试样本总数,矩阵列数=每个测试样本的特征数
#(4)每个测试样本的类标
#【注】归一化采用“最大最小值”方法。
def getData_2():
fPath = 'D:\分类算法\binary_classify_data.txt'
if os.path.exists(fPath):
data = pd.read_csv(fPath,header=None,skiprows=1,names=['class0','pixel0','pixel1','pixel2','pixel3'])
X_train1, X_test1, y_train1, y_test1 = train_test_split(data, data['class0'], test_size = 0.4, random_state = 0)
min_max_scaler = preprocessing.MinMaxScaler() #归一化
X_train_minmax = min_max_scaler.fit_transform(np.array(X_train1))
X_test_minmax = min_max_scaler.fit_transform(np.array(X_test1))
return (X_train_minmax, np.array(y_train1), X_test_minmax, np.array(y_test1))
else:
print ('No such file or directory!')
#读取本地excel表格内的数据集(每类随机生成K个训练集和测试集的组合)
#【K的含义】假设一共有1000个样本,K取10,那么就将这1000个样本切分10份(一份100个),那么就产生了10个测试集
#对于每一份的测试集,剩余900个样本即作为训练集
#结果返回一个字典:键为集合编号(1train, 1trainclass, 1test, 1testclass, 2train, 2trainclass, 2test, 2testclass...),值为数据
#其中1train和1test为随机生成的第一组训练集和测试集(1trainclass和1testclass为训练样本类别和测试样本类别),其他以此类推
def getData_3():
fPath = 'D:\\分类算法\\binary_classify_data.txt'
if os.path.exists(fPath):
#读取csv文件内的数据,
dataMatrix = np.array(pd.read_csv(fPath,header=None,skiprows=1,names=['class0','pixel0','pixel1','pixel2','pixel3']))
#获取每个样本的特征以及类标
rowNum, colNum = dataMatrix.shape[0], dataMatrix.shape[1]
sampleData = []
sampleClass = []
for i in range(0, rowNum):
tempList = list(dataMatrix[i,:])
sampleClass.append(tempList[0])
sampleData.append(tempList[1:])
sampleM = np.array(sampleData) #二维矩阵,一行是一个样本,行数=样本总数,列数=样本特征数
classM = np.array(sampleClass) #一维列向量,每个元素对应每个样本所属类别
#调用StratifiedKFold方法生成训练集和测试集
skf = StratifiedKFold(n_splits = 10)
setDict = {} #创建字典,用于存储生成的训练集和测试集
count = 1
for trainI, testI in skf.split(sampleM, classM):
trainSTemp = [] #用于存储当前循环抽取出的训练样本数据
trainCTemp = [] #用于存储当前循环抽取出的训练样本类标
testSTemp = [] #用于存储当前循环抽取出的测试样本数据
testCTemp = [] #用于存储当前循环抽取出的测试样本类标
#生成训练集
trainIndex = list(trainI)
for t1 in range(0, len(trainIndex)):
trainNum = trainIndex[t1]
trainSTemp.append(list(sampleM[trainNum, :]))
trainCTemp.append(list(classM)[trainNum])
setDict[str(count) + 'train'] = np.array(trainSTemp)
setDict[str(count) + 'trainclass'] = np.array(trainCTemp)
#生成测试集
testIndex = list(testI)
for t2 in range(0, len(testIndex)):
testNum = testIndex[t2]
testSTemp.append(list(sampleM[testNum, :]))
testCTemp.append(list(classM)[testNum])
setDict[str(count) + 'test'] = np.array(testSTemp)
setDict[str(count) + 'testclass'] = np.array(testCTemp)
count += 1
return setDict
else:
print ('No such file or directory!')
#K近邻(K Nearest Neighbor)
def KNN():
clf = neighbors.KNeighborsClassifier()
return clf
#线性鉴别分析(Linear Discriminant Analysis)
def LDA():
clf = LinearDiscriminantAnalysis()
return clf
#支持向量机(Support Vector Machine)
def SVM():
clf = svm.SVC()
return clf
#逻辑回归(Logistic Regression)
def LR():
clf = LogisticRegression()
return clf
#随机森林决策树(Random Forest)
def RF():
clf = RandomForestClassifier()
return clf
#多项式朴素贝叶斯分类器
def native_bayes_classifier():
clf = MultinomialNB(alpha = 0.01)
return clf
#决策树
def decision_tree_classifier():
clf = tree.DecisionTreeClassifier()
return clf
#GBDT
def gradient_boosting_classifier():
clf = GradientBoostingClassifier(n_estimators = 200)
return clf
#计算识别率
def getRecognitionRate(testPre, testClass):
testNum = len(testPre)
rightNum = 0
for i in range(0, testNum):
if testClass[i] == testPre[i]:
rightNum += 1
return float(rightNum) / float(testNum)
#report函数,将调参的详细结果存储到本地F盘(路径可自行修改,其中n_top是指定输出前多少个最优参数组合以及该组合的模型得分)
def report(results, n_top=5488):
f = open('F:/grid_search_rf.txt', 'w')
for i in range(1, n_top + 1):
candidates = np.flatnonzero(results['rank_test_score'] == i)
for candidate in candidates:
f.write("Model with rank: {0}".format(i) + '\n')
f.write("Mean validation score: {0:.3f} (std: {1:.3f})".format(
results['mean_test_score'][candidate],
results['std_test_score'][candidate]) + '\n')
f.write("Parameters: {0}".format(results['params'][candidate]) + '\n')
f.write("\n")
f.close()
#自动调参(以随机森林为例)
def selectRFParam():
clf_RF = RF()
param_grid = {"max_depth": [3,15],
"min_samples_split": [3, 5, 10],
"min_samples_leaf": [3, 5, 10],
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
"n_estimators": range(10,50,10)}
# "class_weight": [{0:1,1:13.24503311,2:1.315789474,3:12.42236025,4:8.163265306,5:31.25,6:4.77326969,7:19.41747573}],
# "max_features": range(3,10),
# "warm_start": [True, False],
# "oob_score": [True, False],
# "verbose": [True, False]}
grid_search = GridSearchCV(clf_RF, param_grid=param_grid, n_jobs=4)
start = time()
T = getData_2() #获取数据集
grid_search.fit(T[0], T[1]) #传入训练集矩阵和训练样本类标
print("GridSearchCV took %.2f seconds for %d candidate parameter settings."
% (time() - start, len(grid_search.cv_results_['params'])))
report(grid_search.cv_results_)
#“主”函数1(KFold方法生成K个训练集和测试集,即数据集采用getData_3()函数获取,计算这K个组合的平均识别率)
def totalAlgorithm_1():
#获取各个分类器
clf_KNN = KNN()
clf_LDA = LDA()
clf_SVM = SVM()
clf_LR = LR()
clf_RF = RF()
clf_NBC = native_bayes_classifier()
clf_DTC = decision_tree_classifier()
clf_GBDT = gradient_boosting_classifier()
#获取训练集和测试集
setDict = getData_3()
setNums = len(setDict.keys()) / 4 #一共生成了setNums个训练集和setNums个测试集,它们之间是一一对应关系
#定义变量,用于将每个分类器的所有识别率累加
KNN_rate = 0.0
LDA_rate = 0.0
SVM_rate = 0.0
LR_rate = 0.0
RF_rate = 0.0
NBC_rate = 0.0
DTC_rate = 0.0
GBDT_rate = 0.0
for i in range(1, int(setNums + 1)):
trainMatrix = setDict[str(i) + 'train']
trainClass = setDict[str(i) + 'trainclass']
testMatrix = setDict[str(i) + 'test']
testClass = setDict[str(i) + 'testclass']
#输入训练样本
clf_KNN.fit(trainMatrix, trainClass)
clf_LDA.fit(trainMatrix, trainClass)
clf_SVM.fit(trainMatrix, trainClass)
clf_LR.fit(trainMatrix, trainClass)
clf_RF.fit(trainMatrix, trainClass)
clf_NBC.fit(trainMatrix, trainClass)
clf_DTC.fit(trainMatrix, trainClass)
clf_GBDT.fit(trainMatrix, trainClass)
#计算识别率
KNN_rate += getRecognitionRate(clf_KNN.predict(testMatrix), testClass)
LDA_rate += getRecognitionRate(clf_LDA.predict(testMatrix), testClass)
SVM_rate += getRecognitionRate(clf_SVM.predict(testMatrix), testClass)
LR_rate += getRecognitionRate(clf_LR.predict(testMatrix), testClass)
RF_rate += getRecognitionRate(clf_RF.predict(testMatrix), testClass)
NBC_rate += getRecognitionRate(clf_NBC.predict(testMatrix), testClass)
DTC_rate += getRecognitionRate(clf_DTC.predict(testMatrix), testClass)
GBDT_rate += getRecognitionRate(clf_GBDT.predict(testMatrix), testClass)
#输出各个分类器的平均识别率(K个训练集测试集,计算平均)
print
print
print
print('K Nearest Neighbor mean recognition rate: ', KNN_rate / float(setNums))
print('Linear Discriminant Analysis mean recognition rate: ', LDA_rate / float(setNums))
print('Support Vector Machine mean recognition rate: ', SVM_rate / float(setNums))
print('Logistic Regression mean recognition rate: ', LR_rate / float(setNums))
print('Random Forest mean recognition rate: ', RF_rate / float(setNums))
print('Native Bayes Classifier mean recognition rate: ', NBC_rate / float(setNums))
print('Decision Tree Classifier mean recognition rate: ', DTC_rate / float(setNums))
print('Gradient Boosting Decision Tree mean recognition rate: ', GBDT_rate / float(setNums))
#“主”函数2(每类前x%作为训练集,剩余作为测试集,即数据集用getData_2()方法获取,计算识别率)
def totalAlgorithm_2():
#获取各个分类器
clf_KNN = KNN()
clf_LDA = LDA()
clf_SVM = SVM()
clf_LR = LR()
clf_RF = RF()
clf_NBC = native_bayes_classifier()
clf_DTC = decision_tree_classifier()
clf_GBDT = gradient_boosting_classifier()
#获取训练集和测试集
T = getData_2()
trainMatrix, trainClass, testMatrix, testClass = T[0], T[1], T[2], T[3]
#输入训练样本
clf_KNN.fit(trainMatrix, trainClass)
clf_LDA.fit(trainMatrix, trainClass)
clf_SVM.fit(trainMatrix, trainClass)
clf_LR.fit(trainMatrix, trainClass)
clf_RF.fit(trainMatrix, trainClass)
clf_NBC.fit(trainMatrix, trainClass)
clf_DTC.fit(trainMatrix, trainClass)
clf_GBDT.fit(trainMatrix, trainClass)
#输出各个分类器的识别率
print('K Nearest Neighbor recognition rate: ', getRecognitionRate(clf_KNN.predict(testMatrix), testClass))
print('Linear Discriminant Analysis recognition rate: ', getRecognitionRate(clf_LDA.predict(testMatrix), testClass))
print('Support Vector Machine recognition rate: ', getRecognitionRate(clf_SVM.predict(testMatrix), testClass))
print('Logistic Regression recognition rate: ', getRecognitionRate(clf_LR.predict(testMatrix), testClass))
print('Random Forest recognition rate: ', getRecognitionRate(clf_RF.predict(testMatrix), testClass))
print('Native Bayes Classifier recognition rate: ', getRecognitionRate(clf_NBC.predict(testMatrix), testClass))
print('Decision Tree Classifier recognition rate: ', getRecognitionRate(clf_DTC.predict(testMatrix), testClass))
print('Gradient Boosting Decision Tree recognition rate: ', getRecognitionRate(clf_GBDT.predict(testMatrix), testClass))
if __name__ == '__main__':
print('K个训练集和测试集的平均识别率')
totalAlgorithm_1()
print('每类前x%训练,剩余测试,各个模型的识别率')
totalAlgorithm_2()
selectRFParam()
print('随机森林参数调优完成!')
以上都是个人理解,如果有问题还望指出。希望大家多多支持亿速云!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。