您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
urllib/urllib2默认的User-Agent是Python-urllib/2.7,容易被检查到是爬虫,所以我们要构造一个请求对象,要用到request方法。
1.查看Header信息
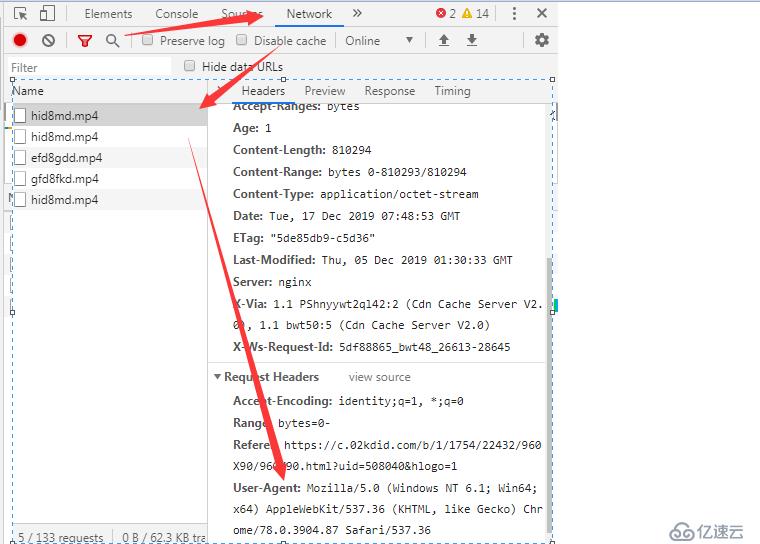
2.设置User-Agent模仿浏览器访问数据
Request总共三个参数,除了必须要有url参数,还有下面两个:
data(默认空):是伴随 url 提交的数据(比如要post的数据),同时 HTTP 请求将从 "GET"方式 改为 "POST"方式。
headers(默认空):是一个字典,包含了需要发送的HTTP报头的键值对
# _*_ coding:utf-8 _*_
import urllib2
# User-Agent是爬虫与反爬虫的第一步
ua_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
# 通过urllib2.Request()方法构造一个请求对象
request = urllib2.Request('http://www.baidu.com/',headers=ua_headers)
#向指定的url地址发送请求,并返回服务器响应的类文件对象
response = urllib2.urlopen(request)
# 服务器返回的类文件对象支持python文件对象的操作方法
# read()方法就是读取文件里的全部内容,返回字符串
html = response.read()
print html3.选择随机的Use-Agent
为了防止封IP,先生成一个user-agent列表,然后从中随机选择一个
# _*_ coding:utf-8 _*_
import urllib2
import random
url = 'http:/www.baidu.com/'
# 可以试User-Agent列表,也可以是代理列表
ua_list = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 在User-Agent列表中随机选择一个User-Agent
user_agent = random.choice(ua_list)
# 构造一个请求
request = urllib2.Request(url)
# add_header()方法添加/修改一个HTTP报头
request.add_header('User-Agent',user_agent)
#get_header()获取一个已有的HTTP报头的值,注意只能第一个字母大写,后面的要小写
print request.get_header('User-agent')4.urllib和urllib2的主要区别
urllib和urllib2都是接受URL请求的相关模块,但是提供了不同的功能,最显著的区别如下:
(1)urllib仅可以接受URL,不能创建,设置headers的request类实例;
(2)但是urllib提供urlencode()方法用来GET查询字符串的产生,而urllib2则没有(这是urllib和urllib2经常一起使用的主要原因)
(3)编码工作使用urllib的urlencode()函数,帮我们讲key:value这样的键值对转换成‘key=value’这样的字符串,解码工作可以使用urllib的unquote()
函数
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。