您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
re模块
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
转义符
正则表达式中用“\”表示转义,而python中也用“\”表示转义,当遇到特殊字符需要转义时,你要花费心思到底需要几个“\”。所以为了避免这个情况,推荐使用原生字符串类型(raw string)来书写正则表达式。
方法很简单,只需要在表达式前面加个“r”即可,如下:
r'\d{2}-\d{8}'
r'\bt\w*\b'常用函数

re.match()
从字符串的起始位置匹配,匹配成功,返回一个匹配的对象,否则返回None
语法:re.match(pattern, string, flags=0)
pattern:匹配的正则表达式
string:要匹配的字符串
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等;flags=0表示不进行特殊指定可选标志如下:
修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志

re.search()
扫描整个字符串并返回第一个成功的匹配对象,否则返回None
语法:re.search(pattern, string, flags=0)
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配(注意:仅仅是第一个)
re.findall()
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表
注意: match 和 search 是匹配一次,而findall 匹配所有
re.split()
根据正则表达式中的分隔符把字符分割为一个列表并返回成功匹配的列表.
re.sub()
用于替换字符串中的匹配项
语法: re.sub(pattern, repl, string, count=0)
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。re.compile()
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,然后就可以用编译后的正则表达式去匹配字符串
pattern : 一个字符串形式的正则表达式
flags :可选,表示匹配模式,比如忽略大小写,多行模式等贪婪匹配和非贪婪匹配
贪婪匹配:匹配尽可能多的字符; 非贪婪匹配:匹配尽可能少的字符
python的正则匹配默认是贪婪匹配
>>> re.match(r'^(\w+)(\d*)$','abc123').groups()
('abc123', '')
>>> re.match(r'^(\w+?)(\d*)$','abc123').groups()
('abc', '123')
表达式1:
\w+表示匹配字母或数字或下划线或汉字并重复1次或更多次;\d*表示匹配数字并重复0次或更多次。
分组1中(\w)是贪婪匹配,它会在满足分组2(\d*)的情况下匹配尽可能多的字符,
因为分组2(\d*)匹配0个数字也满足,所以分组1就把所有字符全部匹配掉了,分组2只能匹配空了。
表达式2:在表达式后加个?即可进行非贪婪匹配,如上面的(\w+?),
因为分组1进行非贪婪匹配,也就是满足分组2匹配的情况下,分组1尽可能少的匹配,
这样的话,上面分组2(\d*)会把所有数字(123)都匹配,所以分组1匹配到(abc)常见匹配模式
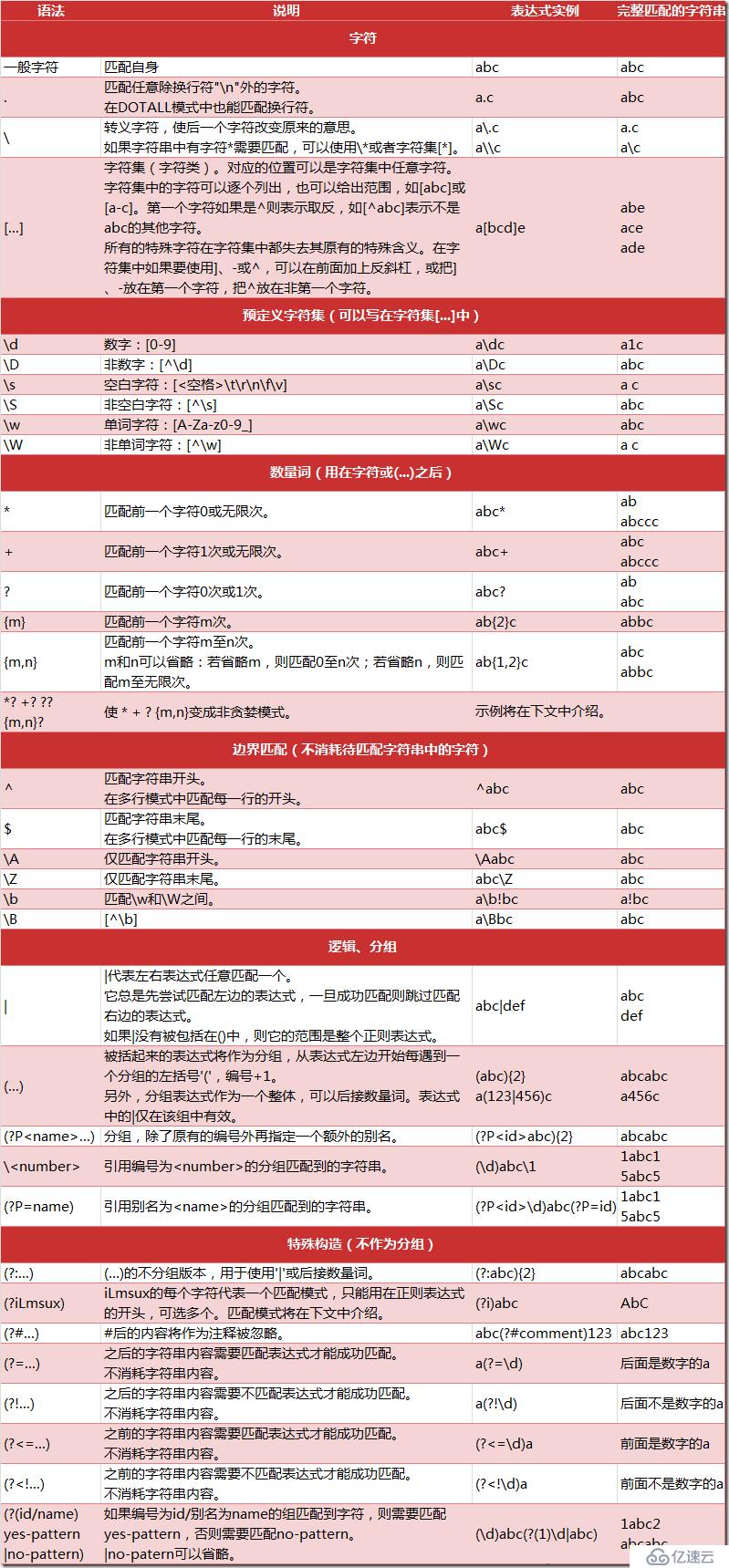
正则式需要匹配不定长的字符串,那就一定需要表示重复的指示符。Python的正则式表示重复的功能很丰富灵活。重复规则的一般的形式是在一条字符规则后面紧跟一个表示重复次数的规则,已表明需要重复前面的规则一定的次数。匹配规则举例
1.普通字符:大多数字符和字母都会和自身匹配
re.findall("alexsel","gtuanalesxalexselericapp")
['alexsel']
re.findall("alexsel","gtuanalesxalexswxericapp")
[]
re.findall("alexsel","gtuanalesxalexselwupeiqialexsel")
['alexsel', 'alexsel']2.元字符: . ^ $ * + ? { } [ ] | ( ) \
•. :匹配一个除了换行符任意一个字符
re.findall("alexsel.w","aaaalexselaw")
['alexselaw']
#一个点只能匹配一个字符^ :只有后面跟的字符串在开头,才能匹配上
re.findall("^alexsel","gtuanalesxalexselgeappalexsel")
[]
re.findall("^alexsel","alexselgtuanalesxalexselwgtappqialexsel")
['alexsel']
#"^"这个符号控制开头,所以写在开头$ :只有它前面的字符串在检测的字符串的最后,才能匹配上
re.findall("alexsel$","alexselseguanalesxalexselganapp")
[]
re.findall("alexsel$","alexselgtaanalesxalexsssiqialexsel")
['alexsel']*:它控制它前面那个字符,他前面那个字符出现0到多个都可以匹配上
re.findall("alexsel*","aaaalexse")
['alexse']
re.findall("alexsel*","aaaalexsel")
['alexsel']
re.findall("alexsel*","aaaalexsellllll")
['alexsellllll']+:匹配前面那个字符1到多次
re.findall("alexsel+","aaaalexselll")
['aleselll']
re.findall("alexsel+","aaaalexsel")
['alexsel']
re.findall("alexsel+","aaaalexse")
[]? :匹配前面那个字符0到1个,多余的只匹配一个
re.findall("alexsel?","aaaalexse")
['ale']
re.findall("alexsel?","aaaalexsel")
['alexsel']
re.findall("alexsel?","aaaalexsellll")
['alexsel']{} :控制它前面一个字符的匹配个数,可以有区间(闭区间),有区间的情况下按照多的匹配
re.findall("alexsel{3}","aaaalexselllll")
['alexselll']
re.findall("alexsel{3}","aaaalexsell")
[]
re.findall("alexsel{3}","aaaalexse")
[]
re.findall("alexsel{3}","aaaalexselll")
['alexselll']
re.findall("alexsel{3,5}","aaaalexsellllllll")
['alexselllll']
re.findall("alexsel{3,5}","aaaalexselll")
['alexselll']
re.findall("alexsel{3,5}","aaaalexsell")
[]\ :
后面跟元字符去除特殊功能,
后面跟普通字符实现特殊功能。
引用序号对应的字组所匹配的字符串 (一个括号为一个组)。
在开头加上 r 表示不转义。
#\2 就相当于第二个组(eric)
re.search(r"(alexsel)(eric)com\2","alexselericcomeric").group()
'alexselericcomeric'
re.search(r"(alexsel)(eric)com\1","alexselericcomalex").group()
'alexselericcomalex'
re.search(r"(alexsel)(eric)com\1\2","alexselericcomalexseleric").group()
'alexselericcomalexeric'\d :匹配任何十进制数;它相当于类[0-9]
re.findall("\d","aaazz1111344444c")
['1', '1', '1', '1', '3', '4', '4', '4', '4', '4']
re.findall("\d\d","aaazz1111344444c")
['11', '11', '34', '44', '44']
re.findall("\d0","aaazz1111344444c")
[]
re.findall("\d3","aaazz1111344444c")
['13']
re.findall("\d4","aaazz1111344444c")
['34', '44', '44']\D :匹配任何非数字字符;它相当于类[^0-9]
re.findall("\D","aaazz1111344444c")
['a', 'a', 'a', 'z', 'z', 'c']
re.findall("\D\D","aaazz1111344444c")
['aa', 'az']
re.findall("\D\d\D","aaazz1111344444c")
[]
re.findall("\D\d\D","aaazz1z111344444c")
['z1z']\s :匹配任何空白字符;它相当于类[ \t\n\r\f\v]
re.findall("\s","aazz1 z11..34c")
[' ']\S :匹配任何非空白字符;它相当于类[^ \t\n\r\f\v]
\w :匹配任何字母数字字符;他相当于类[a-zA-Z0-9_]
re.findall("\w","aazz1z11..34c")
['a', 'a', 'z', 'z', '1', 'z', '1', '1', '3', '4', 'c']\W :匹配任何非字母数字字符;它相当于类[^a-zA-Z0-9_]
\b :匹配一个单词边界,也就是指单词和空格间的位置
re.findall(r"\babc\b","abc sdsadasabcasdsadasdabcasdsa")
['abc']
re.findall(r"\balexsel\b","abc alexsel abcasdsadasdabcasdsa")
['alexsel']
re.findall("\\balexsel\\b","abc alexsel abcasdsadasdabcasdsa")
['alexsel']
re.findall("\balexsel\b","abc alexsel abcasdsadasdabcasdsa")
[]() :把括号内字符作为一个整体去处理
re.search(r"a(\d+)","a222bz1144c").group()
'a222'
re.findall("(ab)*","aabz1144c")
['', 'ab', '', '', '', '', '', '', ''] #将括号里的字符串作为整和后面字符逐个进行匹配,在这里就首先将后面字符串里的a和ab进
#行匹配,开头匹配成功,在看看后面是a,和ab中的第二个不匹配,然后就看后面字符串中的第二个a,和ab匹配,首先a匹配成功,b也匹配成功,拿到匹配
#然后在看后面字符串中的第三个是b,开头匹配失败,到第四个,后面依次
re.search(r"a(\d+)","a222bz1144c").group()
'a222'
re.search(r"a(\d+?)","a222bz1144c").group() +的最小次数为1
'a2'
re.search(r"a(\d*?)","a222bz1144c").group() *的最小次数为0
'a'
#非贪婪匹配模式 加? ,但是如果后面还有匹配字符,就无法实现非贪婪匹配
#(如果前后均有匹配条件,则无法实现非贪婪模式)
re.findall(r"a(\d+?)b","aa2017666bz1144c")
['2017666']
re.search(r"a(\d*?)b","a222bz1144c").group()
'a222b'
re.search(r"a(\d+?)b","a277722bz1144c").group()
'a277722b'元字符在字符集里就代表字符,没有特殊意义(有几个例外)
re.findall("a[.]d","aaaacd")
[]
re.findall("a[.]d","aaaa.d")
['a.d']例外
[-] [^] []
[-] 匹配单个字符,a到z所有的字符
re.findall("[a-z]","aaaa.d")
['a', 'a', 'a', 'a', 'd']
re.findall("[a-z]","aaazzzzzaaccc")
['a', 'a', 'a', 'z', 'z', 'z', 'z', 'z', 'a', 'a', 'c', 'c', 'c']
re.findall("[1-3]","aaazz1111344444c")
['1', '1', '1', '1', '3'][^] 匹配除了这个范围里的字符,(^在这里有 非 的意思)
re.findall("[^1-3]","aaazz1111344444c")
['a', 'a', 'a', 'z', 'z', '4', '4', '4', '4', '4', 'c']
re.findall("[^1-4]","aaazz1111344444c")
['a', 'a', 'a', 'z', 'z', 'c'][]
re.findall("[\d]","aazz1144c")
['1', '1', '4', '4']我们首先考察的元字符是"[" 和 "]"。它们常用来指定一个字符类别,所谓字符类 别就是你想匹配的一个字符集。字符可以单个列出,也可以用“-”号分隔的两个给定 字符来表示一个字符区间。例如,[abc] 将匹配"a", "b", 或 "c"中的任意一个字 符;也可以用区间[a-c]来表示同一字符集,和前者效果一致。如果你只想匹配小写 字母,那么 RE 应写成 [a-z],元字符在类别里并不起作用。例如,[akm$]将匹配字符"a", "k", "m", 或 "$" 中 的任意一个;"$"通常用作元字符,但在字符类别里,其特性被除去,恢复成普通字符。
单词边界
re.findall(r"\babc","abcsd abc")
['abc', 'abc']
re.findall(r"abc\b","abcsd abc")
['abc']
re.findall(r"abc\b","abcsd abc*")
['abc']
re.findall(r"\babc","*abcsd*abc")
['abc', 'abc']#检测单词边界不一定就是空格,还可以是除了字母以外的特殊字符
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。