жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷжңҹеҶ…е®№еҪ“дёӯе°Ҹзј–е°Ҷдјҡз»ҷеӨ§е®¶еёҰжқҘжңүе…іжҖҺд№ҲеңЁPythonйЎ№зӣ®дёӯдҪҝз”Ёlxmlеә“и§Јжһҗhtmlж–Ү件пјҢж–Үз« еҶ…е®№дё°еҜҢдё”д»Ҙдё“дёҡзҡ„и§’еәҰдёәеӨ§е®¶еҲҶжһҗе’ҢеҸҷиҝ°пјҢйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еёҢжңӣеӨ§е®¶еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
lxmlжҳҜPythonзҡ„дёҖдёӘhtml/xmlи§Јжһҗ并е»әз«Ӣdomзҡ„еә“пјҢlxmlзҡ„зү№зӮ№жҳҜеҠҹиғҪејәеӨ§пјҢжҖ§иғҪд№ҹдёҚй”ҷпјҢxmlеҢ…еҗ«дәҶElementTree пјҢhtml5lib пјҢbeautfulsoup зӯүеә“гҖӮ
дҪҝз”ЁlxmlеүҚжіЁж„ҸдәӢйЎ№пјҡе…ҲзЎ®дҝқhtmlз»ҸиҝҮдәҶutf-8и§Јз ҒпјҢеҚіcode =html.decode('utf-8', 'ignore')пјҢеҗҰеҲҷдјҡеҮәзҺ°и§ЈжһҗеҮәй”ҷжғ…еҶөгҖӮеӣ дёәдёӯж–Үиў«зј–з ҒжҲҗutf-8д№ӢеҗҺеҸҳжҲҗ '/u2541'гҖҖд№Ӣзұ»зҡ„еҪўејҸпјҢlxmlдёҖйҒҮеҲ°гҖҖ"/"е°ұдјҡи®Өдёәе…¶ж Үзӯҫз»“жқҹгҖӮ
е…·дҪ“з”Ёжі•пјҡе…ғзҙ иҠӮзӮ№ж“ҚдҪң
1гҖҒ и§ЈжһҗHTMlе»әз«ӢDOM
from lxml import etree dom = etree.HTML(html)
2гҖҒ жҹҘзңӢdomдёӯеӯҗе…ғзҙ зҡ„дёӘж•° len(dom)
3гҖҒ жҹҘзңӢжҹҗиҠӮзӮ№зҡ„еҶ…е®№пјҡetree.tostring(dom[0])
4гҖҒ иҺ·еҸ–иҠӮзӮ№зҡ„ж ҮзӯҫеҗҚз§°пјҡdom[0].tag
5гҖҒ иҺ·еҸ–жҹҗиҠӮзӮ№зҡ„зҲ¶иҠӮзӮ№пјҡdom[0].getparent()
6гҖҒ иҺ·еҸ–жҹҗиҠӮзӮ№зҡ„еұһжҖ§иҠӮзӮ№зҡ„еҶ…е®№пјҡdom[0].get("еұһжҖ§еҗҚз§°")
еҜ№xpathи·Ҝеҫ„зҡ„ж”ҜжҢҒпјҡ
XPathеҚідёәXMLи·Ҝеҫ„иҜӯиЁҖпјҢжҳҜз”ЁдёҖз§Қзұ»дјјзӣ®еҪ•ж ‘зҡ„ж–№жі•жқҘжҸҸиҝ°еңЁXMLж–ҮжЎЈдёӯзҡ„и·Ҝеҫ„гҖӮжҜ”еҰӮз”Ё"/"жқҘдҪңдёәдёҠдёӢеұӮзә§й—ҙзҡ„еҲҶйҡ”гҖӮ第дёҖдёӘ"/"иЎЁзӨәж–ҮжЎЈзҡ„ж №иҠӮзӮ№пјҲжіЁж„ҸпјҢдёҚжҳҜжҢҮж–ҮжЎЈжңҖеӨ–еұӮзҡ„tagиҠӮзӮ№пјҢиҖҢжҳҜжҢҮж–ҮжЎЈжң¬иә«пјүгҖӮжҜ”еҰӮеҜ№дәҺдёҖдёӘHTMLж–Ү件жқҘиҜҙпјҢжңҖеӨ–еұӮзҡ„иҠӮзӮ№еә”иҜҘжҳҜ"/html"гҖӮ
xpathйҖүеҸ–е…ғзҙ зҡ„ж–№ејҸпјҡ
1гҖҒ з»қеҜ№и·Ҝеҫ„пјҢеҰӮpage.xpath("/html/body/p")пјҢе®ғдјҡжүҫеҲ°bodyиҝҷдёӘиҠӮзӮ№дёӢжүҖжңүзҡ„pж Үзӯҫ
2гҖҒ зӣёеҜ№и·Ҝеҫ„пјҢpage.xpath("//p"),е®ғдјҡжүҫеҲ°ж•ҙдёӘhtmlд»Јз ҒйҮҢзҡ„жүҖжңүpж ҮзӯҫгҖӮ

xpathзӯӣйҖүж–№ејҸпјҡ
1гҖҒ йҖүеҸ–е…ғзҙ ж—¶дёҖдёӘеҲ—иЎЁпјҢеҸҜйҖҡиҝҮзҙўеј•жҹҘжүҫ[n]
2гҖҒ йҖҡиҝҮеұһжҖ§еҖјзӯӣйҖүе…ғзҙ p =page.xpath("//p[@style='font-size:200%']")
3гҖҒ еҰӮжһңжІЎжңүеұһжҖ§еҸҜд»ҘйҖҡиҝҮtext()пјҲиҺ·еҸ–е…ғзҙ дёӯж–Үжң¬пјүгҖҒposition()пјҲиҺ·еҸ–е…ғзҙ дҪҚзҪ®пјүгҖҒlast()зӯүиҝӣиЎҢзӯӣйҖү
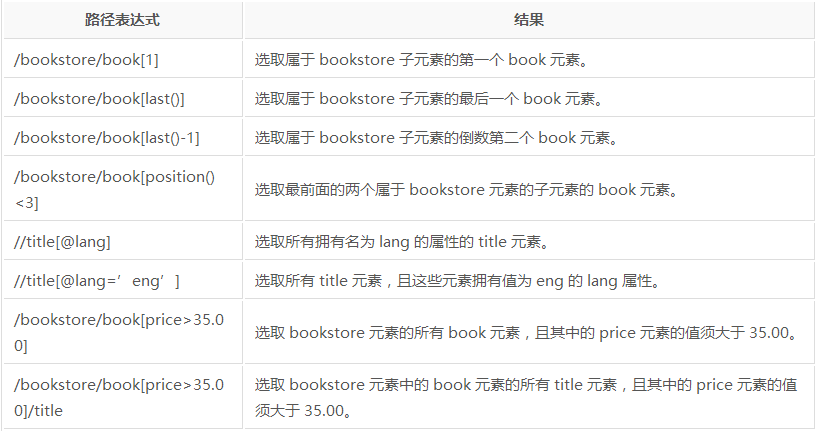
иҺ·еҸ–еұһжҖ§еҖј
dom.xpath(.//a/@href)
иҺ·еҸ–ж–Үжң¬
dom.xpath(".//a/text()")зӨәдҫӢд»Јз Ғпјҡ
#!/usr/bin/python
# -*- coding:utf-8 -*-
from scrapy.spiders import Spider
from lxml import etree
from jredu.items import JreduItem
class JreduSpider(Spider):
name = 'tt' #зҲ¬иҷ«зҡ„еҗҚеӯ—пјҢеҝ…йЎ»зҡ„пјҢе”ҜдёҖзҡ„
allowed_domains = ['sohu.com']
start_urls = [
'http://www.sohu.com'
]
def parse(self, response):
content = response.body.decode('utf-8')
dom = etree.HTML(content)
for ul in dom.xpath("//div[@class='focus-news-box']/div[@class='list16']/ul"):
lis = ul.xpath("./li")
for li in lis:
item = JreduItem() #е®ҡд№үеҜ№иұЎ
if ul.index(li) == 0:
strong = li.xpath("./a/strong/text()")
li.xpath("./a/@href")
item['title']= strong[0]
item['href'] = li.xpath("./a/@href")[0]
else:
la = li.xpath("./a[last()]/text()")
item['title'] = la[0]
item['href'] = li.xpath("./a[last()]/href")[0]
yield itemдёҠиҝ°е°ұжҳҜе°Ҹзј–дёәеӨ§е®¶еҲҶдә«зҡ„жҖҺд№ҲеңЁPythonйЎ№зӣ®дёӯдҪҝз”Ёlxmlеә“и§Јжһҗhtmlж–Ү件дәҶпјҢеҰӮжһңеҲҡеҘҪжңүзұ»дјјзҡ„з–‘жғ‘пјҢдёҚеҰЁеҸӮз…§дёҠиҝ°еҲҶжһҗиҝӣиЎҢзҗҶи§ЈгҖӮеҰӮжһңжғізҹҘйҒ“жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ