您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
怎么在python中使用lxml模块爬取豆瓣?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
Python是一种跨平台的、具有解释性、编译性、互动性和面向对象的脚本语言,其最初的设计是用于编写自动化脚本,随着版本的不断更新和新功能的添加,常用于用于开发独立的项目和大型项目。
步骤一:
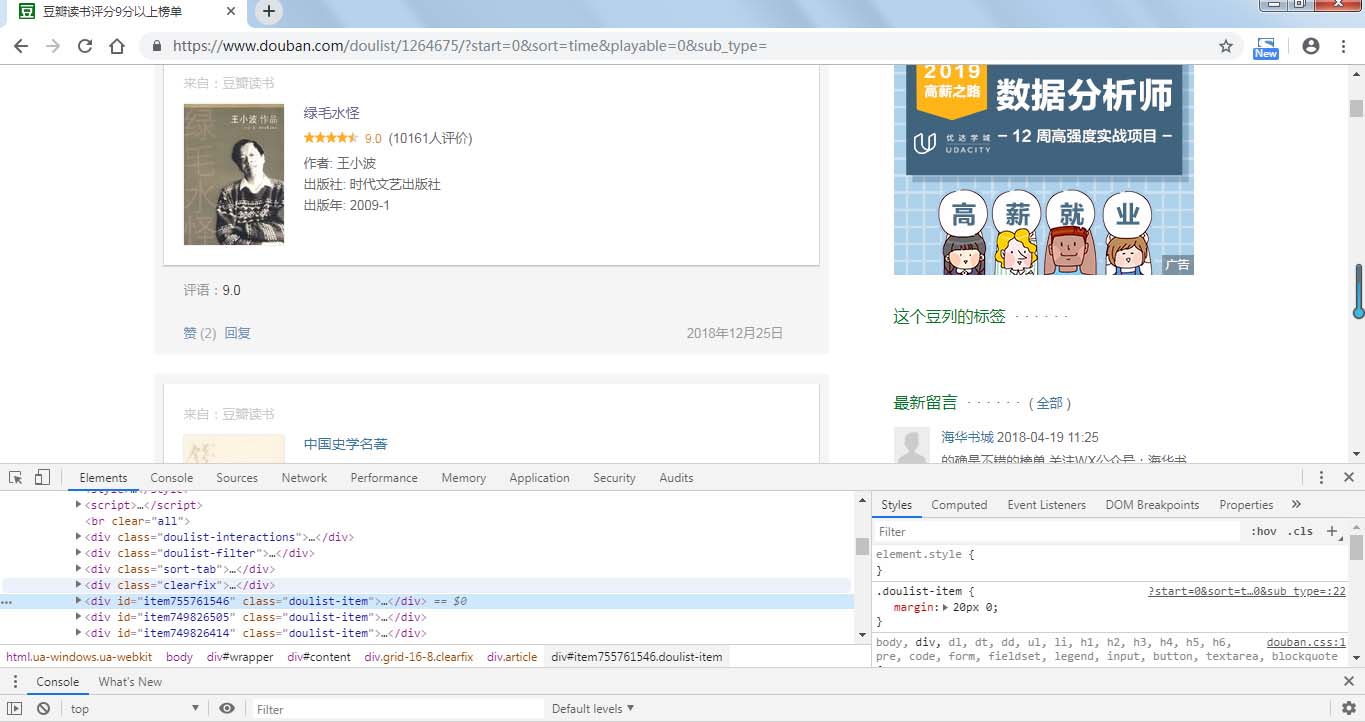
分析网页源代码可以看到,书籍信息在属性为的div标签中,打开发现,我们需要爬取的信息都在标签内部,通过xpath语法我们可以很简便的爬取所需内容。

(书籍各类信息所在标签)
所需爬取的内容在 class为post、title、rating、abstract的div标签中。
步骤二:
先定义爬取函数,爬取所需内容执行函数,并存入csv文件
具体代码如下:
import requests
from lxml import etree
import time
import csv
#信息头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
#定义爬取函数
def douban_booksrank(url):
res = requests.get(url, headers=headers)
selector = etree.HTML(res.text)
contents = selector.xpath('//div[@class="article"]/div[contains(@class,"doulist-item")]') #循环点
for content in contents:
try:
title = content.xpath('div/div[2]/div[3]/a/text()')[0] #书名
scores = content.xpath('div/div[2]/div[4]/span[2]/text()') #评分
scores.append('9.0') #因为有一些书没有评分,导致列表为空,此处添加一个默认评分,若无评分则默认为9.0
score = scores[0]
comments = content.xpath('div/div[2]/div[4]/span[3]/text()')[0] #评论数量
author = content.xpath('div/div[2]/div[5]/text()[1]')[0] #作者
publishment = content.xpath('div/div[2]/div[5]/text()[2]')[0] #出版社
pub_year = content.xpath('div/div[2]/div[5]/text()[3]')[0] #出版时间
img_url = content.xpath('div/div[2]/div[2]/a/img/@src')[0] #书本图片的网址
img = requests.get(img_url) #解析图片网址,为下面下载图片
img_name_file = 'C:/Users/lenovo/Desktop/douban_books/{}.png'.format((title.strip())[:3]) #图片存储位置,图片名只取前3
#写入csv
with open('C:\\Users\lenovo\Desktop\\douban_books.csv', 'a+', newline='', encoding='utf-8')as fp: #newline 使不隔行
writer = csv.writer(fp)
writer.writerow((title, score, comments, author, publishment, pub_year, img_url))
#下载图片,为防止图片名导致格式错误,加入try...except
try:
with open(img_name_file, 'wb')as imgf:
imgf.write(img.content)
except FileNotFoundError or OSError:
pass
time.sleep(0.5) #睡眠0.5s
except IndexError:
pass
#执行程序
if __name__=='__main__':
#爬取所有书本,共22页的内容
urls = ['https://www.douban.com/doulist/1264675/?start={}&sort=time&playable=0&sub_type='.format(str(i))for i in range(0,550,25)]
#写csv首行
with open('C:\\Users\lenovo\Desktop\\douban_books.csv', 'a+', newline='', encoding='utf-8')as f:
writer = csv.writer(f)
writer.writerow(('title', 'score', 'comment', 'author', 'publishment', 'pub_year', 'img_url'))
#遍历所有网页,执行爬取程序
for url in urls:
douban_booksrank(url)爬取结果截图如下:
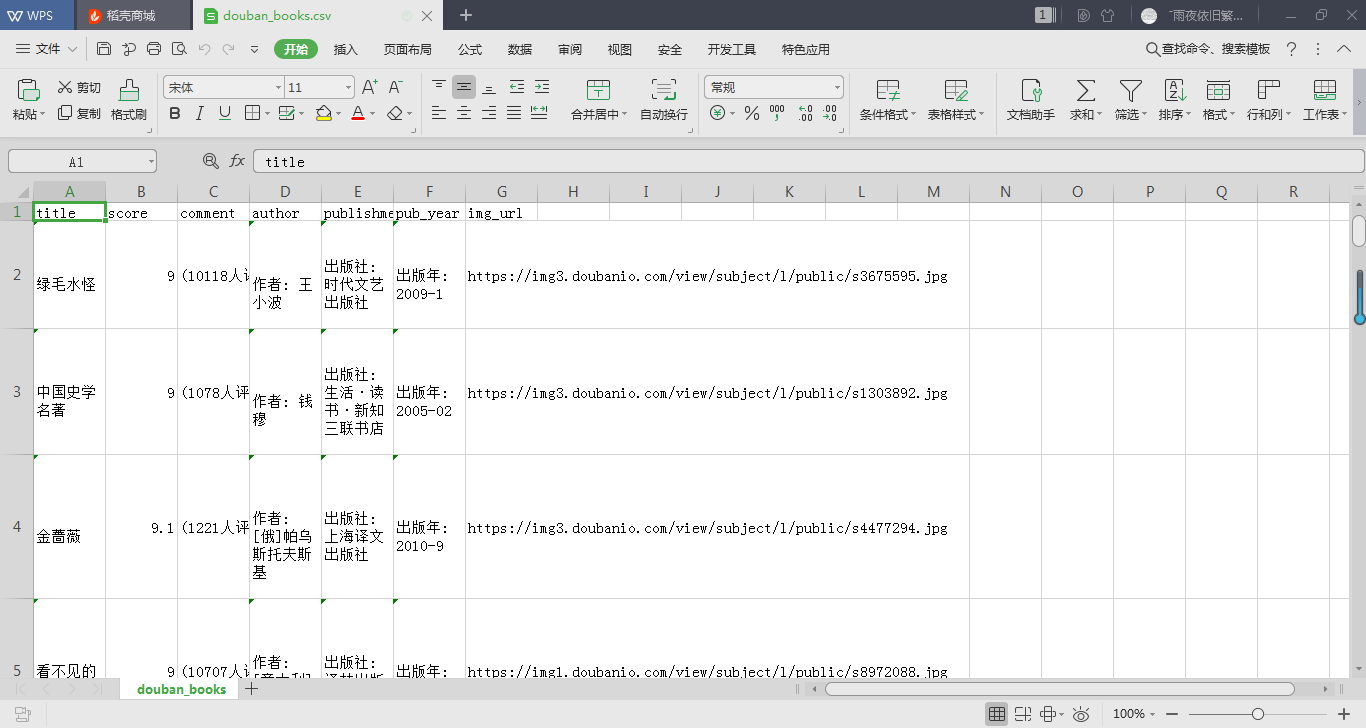
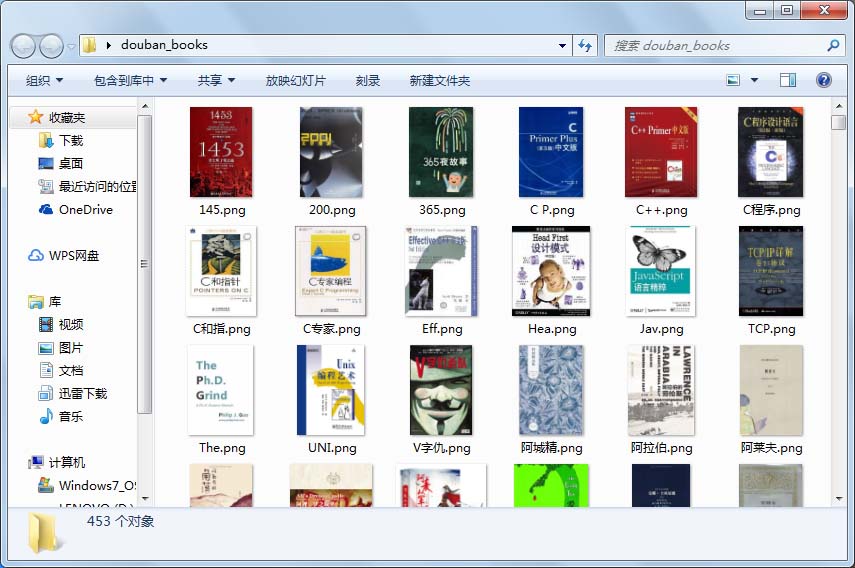
步骤三:
本次使用Python常用的数据分析库pandas来提取所需内容。pandas的read_csv()函数可以读取csv文件并根据文件格式转换为Series、DataFrame或面板对象。
此处我们提取的数据转变为DataFrame(数据帧)对象,然后通过Matplotlib绘图库来进行绘图。
具体代码如下:
from matplotlib import pyplot as plt
import pandas as pd
import re
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.subplots_adjust(wsapce=0.5, hspace=0.5) #调整subplot子图间的距离
pd.set_option('display.max_rows', None) #设置使dataframe 所有行都显示
df = pd.read_csv('C:\\Users\lenovo\Desktop\\douban_books.csv') #读取csv文件,并赋为dataframe对象
comment = re.findall('\((.*?)人评价', str(df.comment), re.S) #使用正则表达式获取评论人数
#将comment的元素化为整型
new_comment = []
for i in comment:
new_comment.append(int(i))
pub_year = re.findall(r'\d{4}', str(df.pub_year),re.S) #获取书籍出版年份
#同上
new_pubyear = []
for n in pub_year:
new_pubyear.append(int(n))
#绘图
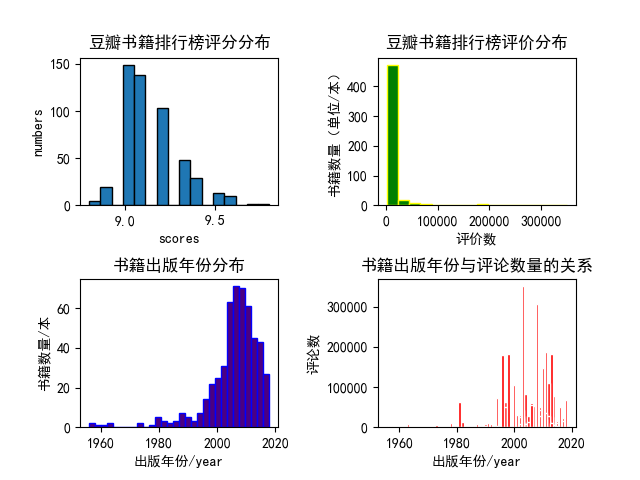
#1、绘制书籍评分范围的直方图
plt.subplot(2,2,1)
plt.hist(df.score, bins=16, edgecolor='black')
plt.title('豆瓣书籍排行榜评分分布', fontweight=700)
plt.xlabel('scores')
plt.ylabel('numbers')
#绘制书籍评论数量的直方分布图
plt.subplot(222)
plt.hist(new_comment, bins=16, color='green', edgecolor='yellow')
plt.title('豆瓣书籍排行榜评价分布', fontweight=700)
plt.xlabel('评价数')
plt.ylabel('书籍数量(单位/本)')
#绘制书籍出版年份分布图
plt.subplot(2,2,3)
plt.hist(new_pubyear, bins=30, color='indigo',edgecolor='blue')
plt.title('书籍出版年份分布', fontweight=700)
plt.xlabel('出版年份/year')
plt.ylabel('书籍数量/本')
#寻找关系
plt.subplot(224)
plt.bar(new_pubyear,new_comment, color='red', edgecolor='white')
plt.title('书籍出版年份与评论数量的关系', fontweight=700)
plt.xlabel('出版年份/year')
plt.ylabel('评论数')
plt.savefig('C:\\Users\lenovo\Desktop\\douban_books_analysis.png') #保存图片
plt.show()这里需要注意的是,使用了正则表达式来提取评论数和出版年份,将其中的符号和文字等剔除。
分析结果如下:
看完上述内容,你们掌握怎么在python中使用lxml模块爬取豆瓣的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。