жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬ж–Үж‘ҳеҪ•дәҺ https://tech.meituan.com/2017/04/21/mt-leaf.html
2017е№ҙ04жңҲ21ж—Ҙ дҪңиҖ…: з…§дёң ж–Үз« й“ҫжҺҘ
дёҡеҠЎзі»з»ҹеҜ№з”ҹжҲҗе…ЁеұҖе”ҜдёҖIDзҡ„иҰҒжұӮжңүе“Әдәӣе‘ўпјҹ
е…ЁеұҖе”ҜдёҖжҖ§пјҡдёҚиғҪеҮәзҺ°йҮҚеӨҚзҡ„IDеҸ·пјҢиҝҷжҳҜжңҖеҹәжң¬зҡ„иҰҒжұӮгҖӮ
и¶ӢеҠҝйҖ’еўһпјҡдё»й”®зҡ„йҖүжӢ©еә”иҜҘе°ҪйҮҸдҪҝз”ЁжңүеәҸзҡ„дё»й”®дҝқиҜҒеҶҷе…ҘжҖ§иғҪгҖӮ
еҚ•и°ғйҖ’еўһпјҡдҝқиҜҒдёӢдёҖдёӘIDдёҖе®ҡеӨ§дәҺдёҠдёҖдёӘIDпјҢдҫӢеҰӮдәӢеҠЎзүҲжң¬еҸ·гҖҒIMеўһйҮҸж¶ҲжҒҜгҖҒжҺ’еәҸзӯүзү№ж®ҠйңҖжұӮгҖӮ
дҝЎжҒҜе®үе…ЁпјҡеҰӮжһңIDжҳҜиҝһз»ӯзҡ„пјҢе®№жҳ“иў«жҒ¶ж„Ҹз”ЁжҲ·жү’еҸ–пјҢжүҖд»ҘеңЁдёҖдәӣеә”з”ЁеңәжҷҜдёӢпјҢдјҡйңҖиҰҒIDж— и§„еҲҷгҖҒдёҚ规еҲҷгҖӮ
IDз”ҹжҲҗзі»з»ҹеә”иҜҘеҒҡеҲ°еҰӮдёӢеҮ зӮ№пјҡ
е№іеқҮ延иҝҹе’ҢTP999延иҝҹйғҪиҰҒе°ҪеҸҜиғҪдҪҺпјӣ
еҸҜз”ЁжҖ§5дёӘ9пјӣ
й«ҳQPSгҖӮ
еҮ з§ҚIDжҖ»з»“пјҡ
дёҖ.UUID
UUID(Universally Unique Identifier)зҡ„ж ҮеҮҶеһӢејҸеҢ…еҗ«32дёӘ16иҝӣеҲ¶ж•°еӯ—пјҢд»Ҙиҝһеӯ—еҸ·еҲҶдёәдә”ж®өпјҢеҪўејҸдёә8-4-4-4-12зҡ„36дёӘеӯ—з¬ҰгҖӮ
дјҳзӮ№пјҡ
жҖ§иғҪйқһеёёй«ҳпјҡжң¬ең°з”ҹжҲҗпјҢжІЎжңүзҪ‘з»ңж¶ҲиҖ—гҖӮ
зјәзӮ№пјҡ
дёҚжҳ“дәҺеӯҳеӮЁпјҡUUIDеӨӘй•ҝпјҢ16еӯ—иҠӮ128дҪҚпјҢйҖҡеёёд»Ҙ36й•ҝеәҰзҡ„еӯ—з¬ҰдёІиЎЁзӨәпјҢеҫҲеӨҡеңәжҷҜдёҚйҖӮз”ЁгҖӮ
дҝЎжҒҜдёҚе®үе…ЁпјҡеҹәдәҺMACең°еқҖз”ҹжҲҗUUIDзҡ„з®—жі•еҸҜиғҪдјҡйҖ жҲҗMACең°еқҖжі„йңІпјҢиҝҷдёӘжјҸжҙһжӣҫиў«з”ЁдәҺеҜ»жүҫжў…дёҪиҺҺз—…жҜ’зҡ„еҲ¶дҪңиҖ…дҪҚзҪ®гҖӮ
IDдҪңдёәдё»й”®ж—¶еңЁзү№е®ҡзҡ„зҺҜеўғдјҡеӯҳеңЁдёҖдәӣй—®йўҳпјҢжҜ”еҰӮеҒҡDBдё»й”®зҡ„еңәжҷҜдёӢпјҢUUIDе°ұйқһеёёдёҚйҖӮз”Ёпјҡ
в‘ MySQLе®ҳж–№жңүжҳҺзЎ®зҡ„е»әи®®дё»й”®иҰҒе°ҪйҮҸи¶Ҡзҹӯи¶ҠеҘҪ[4]пјҢ36дёӘеӯ—з¬Ұй•ҝеәҰзҡ„UUIDдёҚз¬ҰеҗҲиҰҒжұӮгҖӮ
в‘Ў еҜ№MySQLзҙўеј•дёҚеҲ©пјҡеҰӮжһңдҪңдёәж•°жҚ®еә“дё»й”®пјҢеңЁInnoDBеј•ж“ҺдёӢпјҢUUIDзҡ„ж— еәҸжҖ§еҸҜиғҪдјҡеј•иө·ж•°жҚ®дҪҚзҪ®йў‘з№ҒеҸҳеҠЁпјҢдёҘйҮҚеҪұе“ҚжҖ§иғҪгҖӮ
дәҢ.зұ»snowflakeж–№жЎҲ
иҝҷз§Қж–№жЎҲеӨ§иҮҙжқҘиҜҙжҳҜдёҖз§Қд»ҘеҲ’еҲҶе‘ҪеҗҚз©әй—ҙпјҲUUIDд№ҹз®—пјҢз”ұдәҺжҜ”иҫғеёёи§ҒпјҢжүҖд»ҘеҚ•зӢ¬еҲҶжһҗпјүжқҘз”ҹжҲҗIDзҡ„дёҖз§Қз®—жі•пјҢиҝҷз§Қж–№жЎҲжҠҠ64-bitеҲҶеҲ«еҲ’еҲҶжҲҗеӨҡж®өпјҢеҲҶејҖжқҘж ҮзӨәжңәеҷЁгҖҒж—¶й—ҙзӯү
иҝҷз§Қж–№ејҸзҡ„дјҳзјәзӮ№жҳҜпјҡ
дјҳзӮ№пјҡ
жҜ«з§’ж•°еңЁй«ҳдҪҚпјҢиҮӘеўһеәҸеҲ—еңЁдҪҺдҪҚпјҢж•ҙдёӘIDйғҪжҳҜи¶ӢеҠҝйҖ’еўһзҡ„гҖӮ
дёҚдҫқиө–ж•°жҚ®еә“зӯү第дёүж–№зі»з»ҹпјҢд»ҘжңҚеҠЎзҡ„ж–№ејҸйғЁзҪІпјҢзЁіе®ҡжҖ§жӣҙй«ҳпјҢз”ҹжҲҗIDзҡ„жҖ§иғҪд№ҹжҳҜйқһеёёй«ҳзҡ„гҖӮ
еҸҜд»Ҙж №жҚ®иҮӘиә«дёҡеҠЎзү№жҖ§еҲҶй…ҚbitдҪҚпјҢйқһеёёзҒөжҙ»гҖӮ
зјәзӮ№пјҡ
ејәдҫқиө–жңәеҷЁж—¶й’ҹпјҢеҰӮжһңжңәеҷЁдёҠж—¶й’ҹеӣһжӢЁпјҢдјҡеҜјиҮҙеҸ‘еҸ·йҮҚеӨҚжҲ–иҖ…жңҚеҠЎдјҡеӨ„дәҺдёҚеҸҜз”ЁзҠ¶жҖҒгҖӮ
дёүгҖӮж•°жҚ®еә“з”ҹжҲҗ
д»ҘMySQLдёҫдҫӢпјҢеҲ©з”Ёз»ҷеӯ—ж®өи®ҫзҪ®auto_increment_incrementе’Ңauto_increment_offsetжқҘдҝқиҜҒIDиҮӘеўһпјҢжҜҸж¬ЎдёҡеҠЎдҪҝз”ЁдёӢеҲ—SQLиҜ»еҶҷMySQLеҫ—еҲ°IDеҸ·гҖӮ
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;
иҝҷз§Қж–№жЎҲзҡ„дјҳзјәзӮ№еҰӮдёӢпјҡ
дјҳзӮ№пјҡ
йқһеёёз®ҖеҚ•пјҢеҲ©з”ЁзҺ°жңүж•°жҚ®еә“зі»з»ҹзҡ„еҠҹиғҪе®һзҺ°пјҢжҲҗжң¬е°ҸпјҢжңүDBAдё“дёҡз»ҙжҠӨгҖӮ
IDеҸ·еҚ•и°ғиҮӘеўһпјҢеҸҜд»Ҙе®һзҺ°дёҖдәӣеҜ№IDжңүзү№ж®ҠиҰҒжұӮзҡ„дёҡеҠЎгҖӮ
зјәзӮ№пјҡ
ејәдҫқиө–DBпјҢеҪ“DBејӮеёёж—¶ж•ҙдёӘзі»з»ҹдёҚеҸҜз”ЁпјҢеұһдәҺиҮҙе‘Ҫй—®йўҳгҖӮй…ҚзҪ®дё»д»ҺеӨҚеҲ¶еҸҜд»Ҙе°ҪеҸҜиғҪзҡ„еўһеҠ еҸҜз”ЁжҖ§пјҢдҪҶжҳҜж•°жҚ®дёҖиҮҙжҖ§еңЁзү№ж®Ҡжғ…еҶөдёӢйҡҫд»ҘдҝқиҜҒгҖӮдё»д»ҺеҲҮжҚўж—¶зҡ„дёҚдёҖиҮҙеҸҜиғҪдјҡеҜјиҮҙйҮҚеӨҚеҸ‘еҸ·гҖӮ
IDеҸ‘еҸ·жҖ§иғҪ瓶йўҲйҷҗеҲ¶еңЁеҚ•еҸ°MySQLзҡ„иҜ»еҶҷжҖ§иғҪгҖӮ
еҜ№дәҺMySQLжҖ§иғҪй—®йўҳпјҢеҸҜз”ЁеҰӮдёӢж–№жЎҲи§ЈеҶіпјҡеңЁеҲҶеёғејҸзі»з»ҹдёӯжҲ‘们еҸҜд»ҘеӨҡйғЁзҪІеҮ еҸ°жңәеҷЁпјҢжҜҸеҸ°жңәеҷЁи®ҫзҪ®дёҚеҗҢзҡ„еҲқе§ӢеҖјпјҢдё”жӯҘй•ҝе’ҢжңәеҷЁж•°зӣёзӯүгҖӮ
жҜ”еҰӮжңүдёӨеҸ°жңәеҷЁгҖӮи®ҫзҪ®жӯҘй•ҝstepдёә2пјҢTicketServer1зҡ„еҲқе§ӢеҖјдёә1пјҲ1пјҢ3пјҢ5пјҢ7пјҢ9пјҢ11вҖҰпјүгҖҒTicketServer2зҡ„еҲқе§ӢеҖјдёә2пјҲ2пјҢ4пјҢ6пјҢ8пјҢ10вҖҰпјүгҖӮ
иҝҷжҳҜFlickrеӣўйҳҹеңЁ2010е№ҙж’°ж–Үд»Ӣз»Қзҡ„дёҖз§Қдё»й”®з”ҹжҲҗзӯ–з•ҘпјҲTicket Servers: Distributed Unique Primary Keys on the Cheap пјүгҖӮ
еҰӮдёӢжүҖзӨәпјҢдёәдәҶе®һзҺ°дёҠиҝ°ж–№жЎҲеҲҶеҲ«и®ҫзҪ®дёӨеҸ°жңәеҷЁеҜ№еә”зҡ„еҸӮж•°пјҢTicketServer1д»Һ1ејҖе§ӢеҸ‘еҸ·пјҢTicketServer2д»Һ2ејҖе§ӢеҸ‘еҸ·пјҢдёӨеҸ°жңәеҷЁжҜҸж¬ЎеҸ‘еҸ·д№ӢеҗҺйғҪйҖ’еўһ2гҖӮ
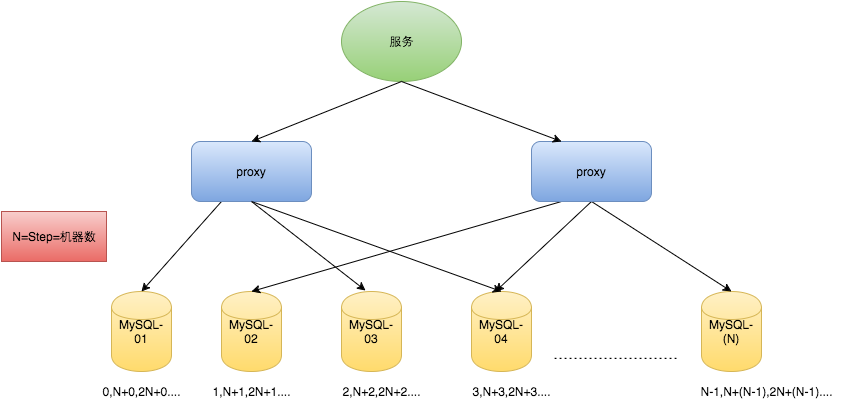
иҝҷз§Қжһ¶жһ„иІҢдјјиғҪеӨҹж»Ўи¶іжҖ§иғҪзҡ„йңҖжұӮпјҢдҪҶжңүд»ҘдёӢеҮ дёӘзјәзӮ№пјҡ
LeafиҝҷдёӘеҗҚеӯ—жҳҜжқҘиҮӘеҫ·еӣҪе“ІеӯҰ家гҖҒж•°еӯҰ家иҺұеёғе°јиҢЁзҡ„дёҖеҸҘиҜқпјҡ >There are no two identical leaves in the world > вҖңдё–з•ҢдёҠжІЎжңүдёӨзүҮзӣёеҗҢзҡ„ж ‘еҸ¶вҖқ
з»јеҗҲеҜ№жҜ”дёҠиҝ°еҮ з§Қж–№жЎҲпјҢжҜҸз§Қж–№жЎҲйғҪдёҚе®Ңе…Ёз¬ҰеҗҲжҲ‘们зҡ„иҰҒжұӮгҖӮжүҖд»ҘLeafеҲҶеҲ«еңЁдёҠиҝ°з¬¬дәҢз§Қе’Ң第дёүз§Қж–№жЎҲдёҠеҒҡдәҶзӣёеә”зҡ„дјҳеҢ–пјҢе®һзҺ°дәҶLeaf-segmentе’ҢLeaf-snowflakeж–№жЎҲгҖӮ
第дёҖз§ҚLeaf-segmentж–№жЎҲпјҢеңЁдҪҝз”Ёж•°жҚ®еә“зҡ„ж–№жЎҲдёҠпјҢеҒҡдәҶеҰӮдёӢж”№еҸҳпјҡ - еҺҹж–№жЎҲжҜҸж¬ЎиҺ·еҸ–IDйғҪеҫ—иҜ»еҶҷдёҖж¬Ўж•°жҚ®еә“пјҢйҖ жҲҗж•°жҚ®еә“еҺӢеҠӣеӨ§гҖӮж”№дёәеҲ©з”Ёproxy serverжү№йҮҸиҺ·еҸ–пјҢжҜҸж¬ЎиҺ·еҸ–дёҖдёӘsegment(stepеҶіе®ҡеӨ§е°Ҹ)еҸ·ж®өзҡ„еҖјгҖӮз”Ёе®Ңд№ӢеҗҺеҶҚеҺ»ж•°жҚ®еә“иҺ·еҸ–ж–°зҡ„еҸ·ж®өпјҢеҸҜд»ҘеӨ§еӨ§зҡ„еҮҸиҪ»ж•°жҚ®еә“зҡ„еҺӢеҠӣгҖӮ - еҗ„дёӘдёҡеҠЎдёҚеҗҢзҡ„еҸ‘еҸ·йңҖжұӮз”Ёbiz_tagеӯ—ж®өжқҘеҢәеҲҶпјҢжҜҸдёӘbiz-tagзҡ„IDиҺ·еҸ–зӣёдә’йҡ”зҰ»пјҢдә’дёҚеҪұе“ҚгҖӮеҰӮжһңд»ҘеҗҺжңүжҖ§иғҪйңҖжұӮйңҖиҰҒеҜ№ж•°жҚ®еә“жү©е®№пјҢдёҚйңҖиҰҒдёҠиҝ°жҸҸиҝ°зҡ„еӨҚжқӮзҡ„жү©е®№ж“ҚдҪңпјҢеҸӘйңҖиҰҒеҜ№biz_tagеҲҶеә“еҲҶиЎЁе°ұиЎҢгҖӮ
ж•°жҚ®еә“иЎЁи®ҫи®ЎеҰӮдёӢпјҡ
+-------------+--------------+------+-----+-------------------+-----------------------------+| Field | Type | Null | Key | Default | Extra | +-------------+--------------+------+-----+-------------------+-----------------------------+| biz_tag | varchar(128) | NO | PRI | | | | max_id | bigint(20) | NO | | 1 | | | step | int(11) | NO | | NULL | | | desc | varchar(256) | YES | | NULL | | | update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP | +-------------+--------------+------+-----+-------------------+-----------------------------+
йҮҚиҰҒеӯ—ж®өиҜҙжҳҺпјҡbiz_tagз”ЁжқҘеҢәеҲҶдёҡеҠЎпјҢmax_idиЎЁзӨәиҜҘbiz_tagзӣ®еүҚжүҖиў«еҲҶй…Қзҡ„IDеҸ·ж®өзҡ„жңҖеӨ§еҖјпјҢstepиЎЁзӨәжҜҸж¬ЎеҲҶй…Қзҡ„еҸ·ж®өй•ҝеәҰгҖӮеҺҹжқҘиҺ·еҸ–IDжҜҸж¬ЎйғҪйңҖиҰҒеҶҷж•°жҚ®еә“пјҢзҺ°еңЁеҸӘйңҖиҰҒжҠҠstepи®ҫзҪ®еҫ—и¶іеӨҹеӨ§пјҢжҜ”еҰӮ1000гҖӮйӮЈд№ҲеҸӘжңүеҪ“1000дёӘеҸ·иў«ж¶ҲиҖ—е®ҢдәҶд№ӢеҗҺжүҚдјҡеҺ»йҮҚж–°иҜ»еҶҷдёҖж¬Ўж•°жҚ®еә“гҖӮиҜ»еҶҷж•°жҚ®еә“зҡ„йў‘зҺҮд»Һ1еҮҸе°ҸеҲ°дәҶ1/stepпјҢеӨ§иҮҙжһ¶жһ„еҰӮдёӢеӣҫжүҖзӨәпјҡ
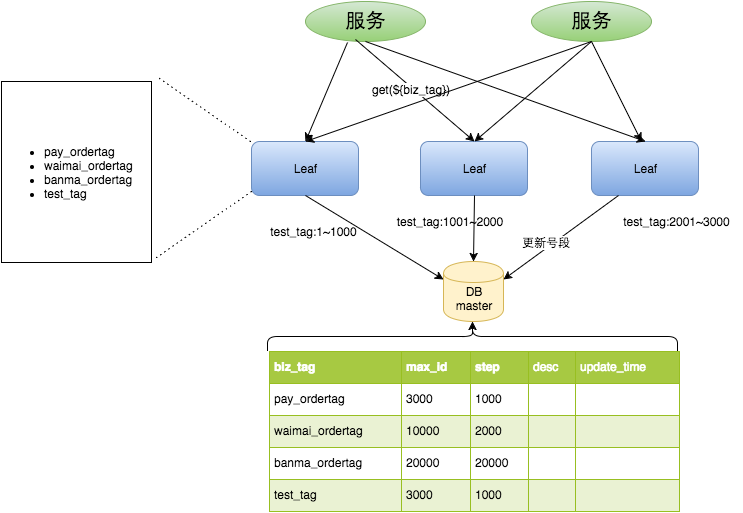
test_tagеңЁз¬¬дёҖеҸ°LeafжңәеҷЁдёҠжҳҜ1~1000зҡ„еҸ·ж®өпјҢеҪ“иҝҷдёӘеҸ·ж®өз”Ёе®Ңж—¶пјҢдјҡеҺ»еҠ иҪҪеҸҰдёҖдёӘй•ҝеәҰдёәstep=1000зҡ„еҸ·ж®өпјҢеҒҮи®ҫеҸҰеӨ–дёӨеҸ°еҸ·ж®өйғҪжІЎжңүжӣҙж–°пјҢиҝҷдёӘж—¶еҖҷ第дёҖеҸ°жңәеҷЁж–°еҠ иҪҪзҡ„еҸ·ж®өе°ұеә”иҜҘжҳҜ3001~4000гҖӮеҗҢж—¶ж•°жҚ®еә“еҜ№еә”зҡ„biz_tagиҝҷжқЎж•°жҚ®зҡ„max_idдјҡд»Һ3000иў«жӣҙж–°жҲҗ4000пјҢжӣҙж–°еҸ·ж®өзҡ„SQLиҜӯеҸҘеҰӮдёӢпјҡ
BeginUPDATE table SET max_id=max_id+step WHERE biz_tag=xxxSELECT tag, max_id, step FROM table WHERE biz_tag=xxxCommit
иҝҷз§ҚжЁЎејҸжңүд»ҘдёӢдјҳзјәзӮ№пјҡ
дјҳзӮ№пјҡ
зјәзӮ№пјҡ
еҜ№дәҺ第дәҢдёӘзјәзӮ№пјҢLeaf-segmentеҒҡдәҶдёҖдәӣдјҳеҢ–пјҢз®ҖеҚ•зҡ„иҜҙе°ұжҳҜпјҡ
Leaf еҸ–еҸ·ж®өзҡ„ж—¶жңәжҳҜеңЁеҸ·ж®өж¶ҲиҖ—е®Ңзҡ„ж—¶еҖҷиҝӣиЎҢзҡ„пјҢд№ҹе°ұж„Ҹе‘ізқҖеҸ·ж®өдёҙз•ҢзӮ№зҡ„IDдёӢеҸ‘ж—¶й—ҙеҸ–еҶідәҺдёӢдёҖж¬Ўд»ҺDBеҸ–еӣһеҸ·ж®өзҡ„ж—¶й—ҙпјҢ并且еңЁиҝҷжңҹй—ҙиҝӣжқҘзҡ„иҜ·жұӮд№ҹдјҡеӣ дёәDBеҸ·ж®өжІЎжңүеҸ–еӣһжқҘпјҢеҜјиҮҙзәҝзЁӢйҳ»еЎһгҖӮеҰӮжһңиҜ·жұӮDBзҡ„зҪ‘з»ңе’ҢDBзҡ„жҖ§иғҪзЁіе®ҡпјҢиҝҷз§Қжғ…еҶөеҜ№зі»з»ҹзҡ„еҪұе“ҚжҳҜдёҚеӨ§зҡ„пјҢдҪҶжҳҜеҒҮеҰӮеҸ–DBзҡ„ж—¶еҖҷзҪ‘з»ңеҸ‘з”ҹжҠ–еҠЁпјҢжҲ–иҖ…DBеҸ‘з”ҹж…ўжҹҘиҜўе°ұдјҡеҜјиҮҙж•ҙдёӘзі»з»ҹзҡ„е“Қеә”ж—¶й—ҙеҸҳж…ўгҖӮ
дёәжӯӨпјҢжҲ‘们еёҢжңӣDBеҸ–еҸ·ж®өзҡ„иҝҮзЁӢиғҪеӨҹеҒҡеҲ°ж— йҳ»еЎһпјҢдёҚйңҖиҰҒеңЁDBеҸ–еҸ·ж®өзҡ„ж—¶еҖҷйҳ»еЎһиҜ·жұӮзәҝзЁӢпјҢеҚіеҪ“еҸ·ж®өж¶Ҳиҙ№еҲ°жҹҗдёӘзӮ№ж—¶е°ұејӮжӯҘзҡ„жҠҠдёӢдёҖдёӘеҸ·ж®өеҠ иҪҪеҲ°еҶ…еӯҳдёӯгҖӮиҖҢдёҚйңҖиҰҒзӯүеҲ°еҸ·ж®өз”Ёе°Ҫзҡ„ж—¶еҖҷжүҚеҺ»жӣҙж–°еҸ·ж®өгҖӮиҝҷж ·еҒҡе°ұеҸҜд»ҘеҫҲеӨ§зЁӢеәҰдёҠзҡ„йҷҚдҪҺзі»з»ҹзҡ„TP999жҢҮж ҮгҖӮиҜҰз»Ҷе®һзҺ°еҰӮдёӢеӣҫжүҖзӨәпјҡ
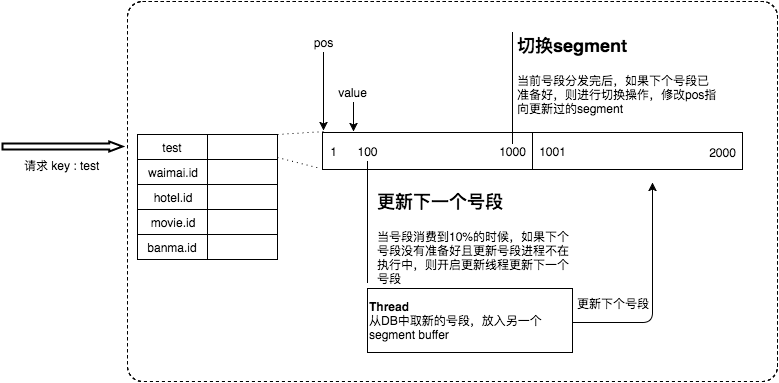
йҮҮз”ЁеҸҢbufferзҡ„ж–№ејҸпјҢLeafжңҚеҠЎеҶ…йғЁжңүдёӨдёӘеҸ·ж®өзј“еӯҳеҢәsegmentгҖӮеҪ“еүҚеҸ·ж®өе·ІдёӢеҸ‘10%ж—¶пјҢеҰӮжһңдёӢдёҖдёӘеҸ·ж®өжңӘжӣҙж–°пјҢеҲҷеҸҰеҗҜдёҖдёӘжӣҙж–°зәҝзЁӢеҺ»жӣҙж–°дёӢдёҖдёӘеҸ·ж®өгҖӮеҪ“еүҚеҸ·ж®өе…ЁйғЁдёӢеҸ‘е®ҢеҗҺпјҢеҰӮжһңдёӢдёӘеҸ·ж®өеҮҶеӨҮеҘҪдәҶеҲҷеҲҮжҚўеҲ°дёӢдёӘеҸ·ж®өдёәеҪ“еүҚsegmentжҺҘзқҖдёӢеҸ‘пјҢеҫӘзҺҜеҫҖеӨҚгҖӮ
жҜҸдёӘbiz-tagйғҪжңүж¶Ҳиҙ№йҖҹеәҰзӣ‘жҺ§пјҢйҖҡеёёжҺЁиҚҗsegmentй•ҝеәҰи®ҫзҪ®дёәжңҚеҠЎй«ҳеі°жңҹеҸ‘еҸ·QPSзҡ„600еҖҚпјҲ10еҲҶй’ҹпјүпјҢиҝҷж ·еҚідҪҝDBе®•жңәпјҢLeafд»ҚиғҪжҢҒз»ӯеҸ‘еҸ·10-20еҲҶй’ҹдёҚеҸ—еҪұе“ҚгҖӮ
жҜҸж¬ЎиҜ·жұӮжқҘдёҙж—¶йғҪдјҡеҲӨж–ӯдёӢдёӘеҸ·ж®өзҡ„зҠ¶жҖҒпјҢд»ҺиҖҢжӣҙж–°жӯӨеҸ·ж®өпјҢжүҖд»ҘеҒ¶е°”зҡ„зҪ‘з»ңжҠ–еҠЁдёҚдјҡеҪұе“ҚдёӢдёӘеҸ·ж®өзҡ„жӣҙж–°гҖӮ
еҜ№дәҺ第дёүзӮ№вҖңDBеҸҜз”ЁжҖ§вҖқй—®йўҳпјҢжҲ‘们зӣ®еүҚйҮҮз”ЁдёҖдё»дёӨд»Һзҡ„ж–№ејҸпјҢеҗҢж—¶еҲҶжңәжҲҝйғЁзҪІпјҢMasterе’ҢSlaveд№Ӣй—ҙйҮҮз”Ё еҚҠеҗҢжӯҘж–№ејҸ[5] еҗҢжӯҘж•°жҚ®гҖӮеҗҢж—¶дҪҝз”Ёе…¬еҸёAtlasж•°жҚ®еә“дёӯй—ҙ件(е·ІејҖжәҗпјҢж”№еҗҚдёә DBProxy )еҒҡдё»д»ҺеҲҮжҚўгҖӮеҪ“然иҝҷз§Қж–№жЎҲеңЁдёҖдәӣжғ…еҶөдјҡйҖҖеҢ–жҲҗејӮжӯҘжЁЎејҸпјҢз”ҡиҮіеңЁ йқһеёёжһҒз«Ҝ жғ…еҶөдёӢд»Қ然дјҡйҖ жҲҗж•°жҚ®дёҚдёҖиҮҙзҡ„жғ…еҶөпјҢдҪҶжҳҜеҮәзҺ°зҡ„жҰӮзҺҮйқһеёёе°ҸгҖӮеҰӮжһңдҪ зҡ„зі»з»ҹиҰҒдҝқиҜҒ100%зҡ„ж•°жҚ®ејәдёҖиҮҙпјҢеҸҜд»ҘйҖүжӢ©дҪҝз”ЁвҖңзұ»Paxosз®—жі•вҖқе®һзҺ°зҡ„ејәдёҖиҮҙMySQLж–№жЎҲпјҢеҰӮMySQL 5.7еүҚж®өж—¶й—ҙеҲҡеҲҡGAзҡ„ MySQL Group Replication гҖӮдҪҶжҳҜиҝҗз»ҙжҲҗжң¬е’ҢзІҫеҠӣйғҪдјҡзӣёеә”зҡ„еўһеҠ пјҢж №жҚ®е®һйҷ…жғ…еҶөйҖүеһӢеҚіеҸҜгҖӮ
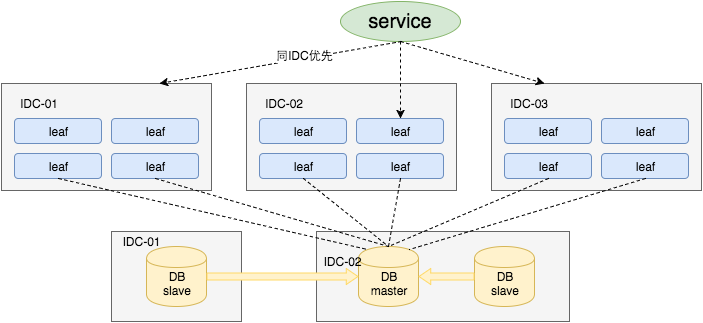
еҗҢж—¶LeafжңҚеҠЎеҲҶIDCйғЁзҪІпјҢеҶ…йғЁзҡ„жңҚеҠЎеҢ–жЎҶжһ¶жҳҜвҖңMTthrift RPCвҖқгҖӮжңҚеҠЎи°ғз”Ёзҡ„ж—¶еҖҷпјҢж №жҚ®иҙҹиҪҪеқҮиЎЎз®—жі•дјҡдјҳе…Ҳи°ғз”ЁеҗҢжңәжҲҝзҡ„LeafжңҚеҠЎгҖӮеңЁиҜҘIDCеҶ…LeafжңҚеҠЎдёҚеҸҜз”Ёзҡ„ж—¶еҖҷжүҚдјҡйҖүжӢ©е…¶д»–жңәжҲҝзҡ„LeafжңҚеҠЎгҖӮеҗҢж—¶жңҚеҠЎжІ»зҗҶе№іеҸ°OCTOиҝҳжҸҗдҫӣдәҶй’ҲеҜ№жңҚеҠЎзҡ„иҝҮиҪҪдҝқжҠӨгҖҒдёҖй”®жҲӘжөҒгҖҒеҠЁжҖҒжөҒйҮҸеҲҶй…ҚзӯүеҜ№жңҚеҠЎзҡ„дҝқжҠӨжҺӘж–ҪгҖӮ
Leaf-segmentж–№жЎҲеҸҜд»Ҙз”ҹжҲҗи¶ӢеҠҝйҖ’еўһзҡ„IDпјҢеҗҢж—¶IDеҸ·жҳҜеҸҜи®Ўз®—зҡ„пјҢдёҚйҖӮз”ЁдәҺи®ўеҚ•IDз”ҹжҲҗеңәжҷҜпјҢжҜ”еҰӮз«һеҜ№еңЁдёӨеӨ©дёӯеҚҲ12зӮ№еҲҶеҲ«дёӢеҚ•пјҢйҖҡиҝҮи®ўеҚ•idеҸ·зӣёеҮҸе°ұиғҪеӨ§иҮҙи®Ўз®—еҮәе…¬еҸёдёҖеӨ©зҡ„и®ўеҚ•йҮҸпјҢиҝҷдёӘжҳҜдёҚиғҪеҝҚеҸ—зҡ„гҖӮйқўеҜ№иҝҷдёҖй—®йўҳпјҢжҲ‘们жҸҗдҫӣдәҶ Leaf-snowflakeж–№жЎҲгҖӮ
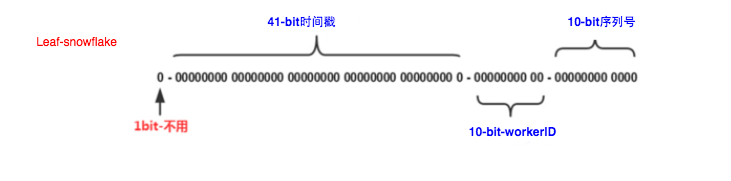
Leaf-snowflakeж–№жЎҲе®Ңе…ЁжІҝз”Ёsnowflakeж–№жЎҲзҡ„bitдҪҚи®ҫи®ЎпјҢеҚіжҳҜвҖң1+41+10+12вҖқзҡ„ж–№ејҸз»„иЈ…IDеҸ·гҖӮеҜ№дәҺworkerIDзҡ„еҲҶй…ҚпјҢеҪ“жңҚеҠЎйӣҶзҫӨж•°йҮҸиҫғе°Ҹзҡ„жғ…еҶөдёӢпјҢе®Ңе…ЁеҸҜд»ҘжүӢеҠЁй…ҚзҪ®гҖӮLeafжңҚеҠЎи§„жЁЎиҫғеӨ§пјҢеҠЁжүӢй…ҚзҪ®жҲҗжң¬еӨӘй«ҳгҖӮжүҖд»ҘдҪҝз”ЁZookeeperжҢҒд№…йЎәеәҸиҠӮзӮ№зҡ„зү№жҖ§иҮӘеҠЁеҜ№snowflakeиҠӮзӮ№й…ҚзҪ®wokerIDгҖӮLeaf-snowflakeжҳҜжҢүз…§дёӢйқўеҮ дёӘжӯҘйӘӨеҗҜеҠЁзҡ„пјҡ
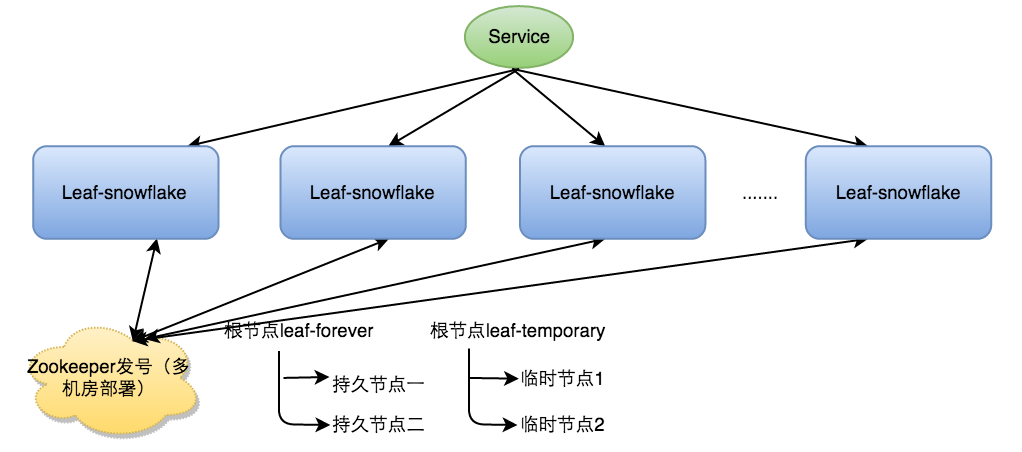
йҷӨдәҶжҜҸж¬ЎдјҡеҺ»ZKжӢҝж•°жҚ®д»ҘеӨ–пјҢд№ҹдјҡеңЁжң¬жңәж–Ү件系з»ҹдёҠзј“еӯҳдёҖдёӘworkerIDж–Ү件гҖӮеҪ“ZooKeeperеҮәзҺ°й—®йўҳпјҢжҒ°еҘҪжңәеҷЁеҮәзҺ°й—®йўҳйңҖиҰҒйҮҚеҗҜж—¶пјҢиғҪдҝқиҜҒжңҚеҠЎиғҪеӨҹжӯЈеёёеҗҜеҠЁгҖӮиҝҷж ·еҒҡеҲ°дәҶеҜ№дёү方组件зҡ„ејұдҫқиө–гҖӮдёҖе®ҡзЁӢеәҰдёҠжҸҗй«ҳдәҶSLA
еӣ дёәиҝҷз§Қж–№жЎҲдҫқиө–ж—¶й—ҙпјҢеҰӮжһңжңәеҷЁзҡ„ж—¶й’ҹеҸ‘з”ҹдәҶеӣһжӢЁпјҢйӮЈд№Ҳе°ұдјҡжңүеҸҜиғҪз”ҹжҲҗйҮҚеӨҚзҡ„IDеҸ·пјҢйңҖиҰҒи§ЈеҶіж—¶й’ҹеӣһйҖҖзҡ„й—®йўҳгҖӮ
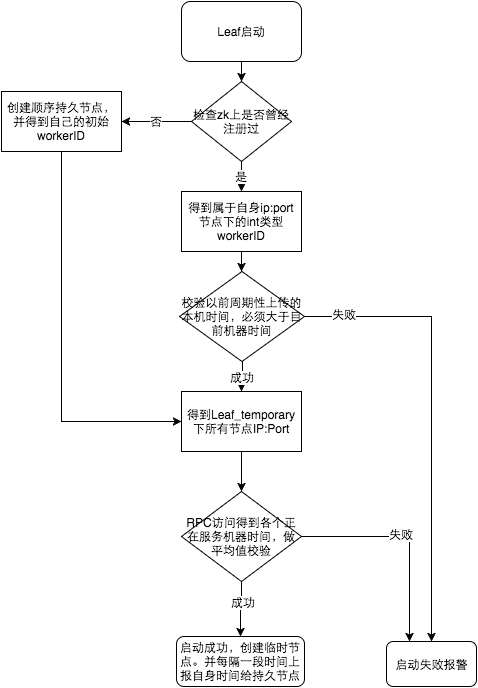
еҸӮи§ҒдёҠеӣҫж•ҙдёӘеҗҜеҠЁжөҒзЁӢеӣҫпјҢжңҚеҠЎеҗҜеҠЁж—¶йҰ–е…ҲжЈҖжҹҘиҮӘе·ұжҳҜеҗҰеҶҷиҝҮZooKeeper leaf_foreverиҠӮзӮ№пјҡ
з”ұдәҺејәдҫқиө–ж—¶й’ҹпјҢеҜ№ж—¶й—ҙзҡ„иҰҒжұӮжҜ”иҫғж•Ҹж„ҹпјҢеңЁжңәеҷЁе·ҘдҪңж—¶NTPеҗҢжӯҘд№ҹдјҡйҖ жҲҗз§’зә§еҲ«зҡ„еӣһйҖҖпјҢе»әи®®еҸҜд»ҘзӣҙжҺҘе…ій—ӯNTPеҗҢжӯҘгҖӮиҰҒд№ҲеңЁж—¶й’ҹеӣһжӢЁзҡ„ж—¶еҖҷзӣҙжҺҘдёҚжҸҗдҫӣжңҚеҠЎзӣҙжҺҘиҝ”еӣһERROR_CODEпјҢзӯүж—¶й’ҹиҝҪдёҠеҚіеҸҜгҖӮ жҲ–иҖ…еҒҡдёҖеұӮйҮҚиҜ•пјҢ然еҗҺдёҠжҠҘжҠҘиӯҰзі»з»ҹпјҢжӣҙжҲ–иҖ…жҳҜеҸ‘зҺ°жңүж—¶й’ҹеӣһжӢЁд№ӢеҗҺиҮӘеҠЁж‘ҳйҷӨжң¬иә«иҠӮзӮ№е№¶жҠҘиӯҰ пјҢеҰӮдёӢпјҡ
//еҸ‘з”ҹдәҶеӣһжӢЁпјҢжӯӨеҲ»ж—¶й—ҙе°ҸдәҺдёҠж¬ЎеҸ‘еҸ·ж—¶й—ҙ
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp; if (offset <= 5) { try { //ж—¶й—ҙеҒҸе·®еӨ§е°Ҹе°ҸдәҺ5msпјҢеҲҷзӯүеҫ…дёӨеҖҚж—¶й—ҙ
wait(offset << 1);//wait
timestamp = timeGen(); if (timestamp < lastTimestamp) { //иҝҳжҳҜе°ҸдәҺпјҢжҠӣејӮ常并дёҠжҠҘ
throwClockBackwardsEx(timestamp);
}
} catch (InterruptedException e) {
throw e;
}
} else { //throw
throwClockBackwardsEx(timestamp);
}
} //еҲҶй…ҚID
д»ҺдёҠзәҝжғ…еҶөжқҘзңӢпјҢеңЁ2017е№ҙй—°з§’еҮәзҺ°йӮЈдёҖж¬ЎеҮәзҺ°иҝҮйғЁеҲҶжңәеҷЁеӣһжӢЁпјҢз”ұдәҺLeaf-snowflakeзҡ„зӯ–з•ҘдҝқиҜҒпјҢжҲҗеҠҹйҒҝе…ҚдәҶеҜ№дёҡеҠЎйҖ жҲҗзҡ„еҪұе“ҚгҖӮ
LeafеңЁзҫҺеӣўзӮ№иҜ„е…¬еҸёеҶ…йғЁжңҚеҠЎеҢ…еҗ«йҮ‘иһҚгҖҒж”Ҝд»ҳдәӨжҳ“гҖҒйӨҗйҘ®гҖҒеӨ–еҚ–гҖҒй…’еә—ж—…жёёгҖҒзҢ«зңјз”өеҪұзӯүдј—еӨҡдёҡеҠЎзәҝгҖӮзӣ®еүҚLeafзҡ„жҖ§иғҪеңЁ4C8Gзҡ„жңәеҷЁдёҠQPSиғҪеҺӢжөӢеҲ°иҝ‘5w/sпјҢTP999 1msпјҢе·Із»ҸиғҪеӨҹж»Ўи¶іеӨ§йғЁеҲҶзҡ„дёҡеҠЎзҡ„йңҖжұӮгҖӮжҜҸеӨ©жҸҗдҫӣдәҝж•°йҮҸзә§зҡ„и°ғз”ЁйҮҸпјҢдҪңдёәе…¬еҸёеҶ…йғЁе…¬е…ұзҡ„еҹәзЎҖжҠҖжңҜи®ҫж–ҪпјҢеҝ…йЎ»дҝқиҜҒй«ҳSLAе’Ңй«ҳжҖ§иғҪзҡ„жңҚеҠЎпјҢжҲ‘们зӣ®еүҚиҝҳд»…д»…иҫҫеҲ°дәҶеҸҠж јзәҝпјҢиҝҳжңүеҫҲеӨҡжҸҗй«ҳзҡ„з©әй—ҙгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ