您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章的内容主要围绕大数据中异步下拉树使用要求及实际操作是什么进行讲述,文章内容清晰易懂,条理清晰,非常适合新手学习,值得大家去阅读。感兴趣的朋友可以跟随小编一起阅读吧。希望大家通过这篇文章有所收获!
问题:
参数模板中当数据量大时会出现下拉树加载慢的情况,对此润乾 5.0 提出了异步下拉树编辑风格针对这个情况进行优化。
优化原理:
使用异步下拉树,初始时只加载首层节点的数据,当展开某子节点时,再加载它的子节点数据,不展现的就不加载。
特别注意:产品提供的异步下拉树 对数据表结构要求很严格,不是任何一个数据表建立的数据集都可以直接用的
具体介绍:
以润乾报表中的订单表为例来说明,如果使用下拉树编辑风格 那么只需要指定的每层节点的取值 及除首层外的过滤表达式。
但是,如要使用异步下拉树需要满足如下表结构: select 真实值字段 , 显示值字段 from …
而订单表中地区 城市都是一个独立的字段不符合上述表结构 如果要用异步下拉树优化 那就需要把地区 城市整理成一个字段 每个值对应一个唯一的编码 然后再增加一个 father 字段 fathet 字段中 地区对应值为空 城市 对应值为所在地区的编号
最终整理后的数据表结构图如下:
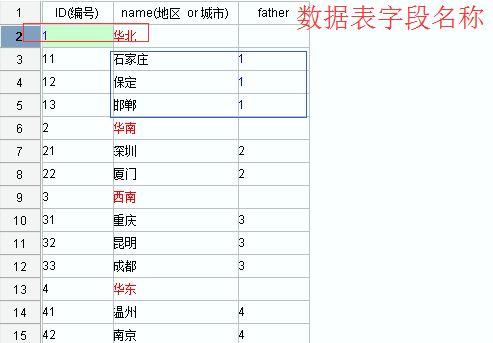
为满足此表结构可以选择直接新建一个数据表,或者通过其他工具实现,比如润乾的集算器
满足如上需求后 报表参数模板关于异步下拉树部分设置如下:
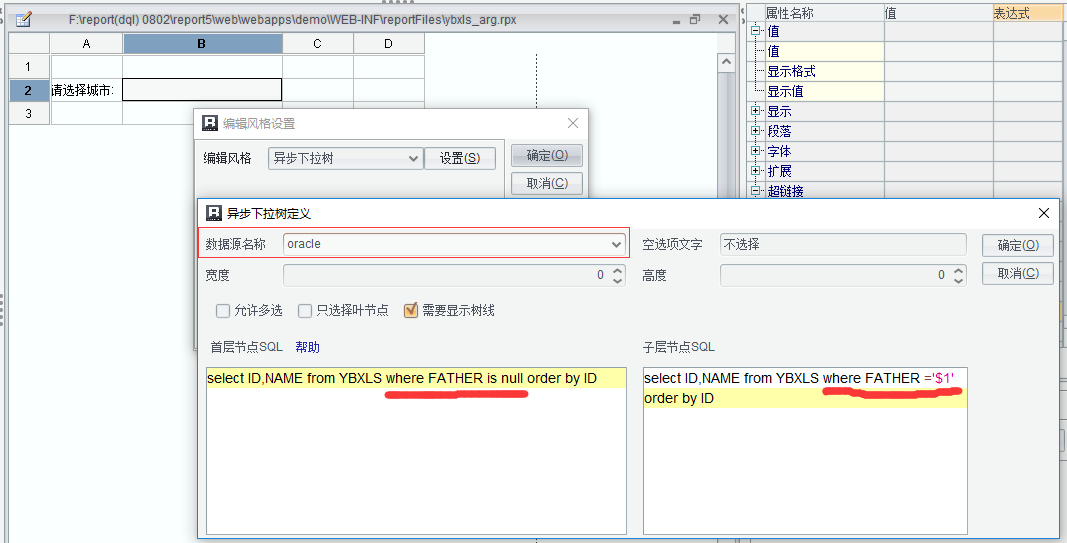
注释:
1. 首层节点 SQL select ID,NAME from YBXLS where FATHER is null order by ID –通过为空的 father 值 查出首层节点值
2. 子层节点 SQL select ID,NAME from YBXLS where FATHER =’$1’order by ID –$1 符号代表上层节点值
其他关于参数模板的设置可以参考润乾自带初级教程进行设置。
特别注意:异步下拉树的单元格不能使用自动换行属性,否则会导致下拉属性不可用。
感谢你的阅读,相信你对“大数据中异步下拉树使用要求及实际操作是什么”这一问题有一定的了解,快去动手实践吧,如果想了解更多相关知识点,可以关注亿速云网站!小编会继续为大家带来更好的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。