жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ

иҝ‘жңҹпјҢйҳҝйҮҢе·ҙе·ҙиҫҫж‘©йҷўзҡ„дёҖзҜҮи®әж–Үе…ҘйҖүи®Ўз®—жңәи§Ҷи§үйЎ¶дјҡ CVPR 2020пјҢиҜҘи®әж–ҮжҸҗеҮәдәҶдёҖдёӘйҖҡз”ЁгҖҒй«ҳжҖ§иғҪзҡ„иҮӘеҠЁй©ҫ驶жЈҖжөӢеҷЁпјҢйҰ–ж¬Ўе®һзҺ° 3D зү©дҪ“жЈҖжөӢзІҫеәҰдёҺйҖҹеәҰзҡ„е…јеҫ—пјҢжңүж•ҲжҸҗеҚҮиҮӘеҠЁй©ҫ驶系з»ҹе®үе…ЁжҖ§иғҪгҖӮ

3D зӣ®ж ҮжЈҖжөӢйңҖиҫ“еҮәзү©дҪ“зұ»еҲ«еҸҠеңЁдёүз»ҙз©әй—ҙдёӯзҡ„й•ҝе®Ҫй«ҳгҖҒж—ӢиҪ¬и§’зӯүдҝЎжҒҜ
дёҺжҷ®йҖҡзҡ„ 2D еӣҫеғҸиҜҶеҲ«еә”з”ЁдёҚеҗҢпјҢиҮӘеҠЁй©ҫ驶系з»ҹеҜ№зІҫеәҰе’ҢйҖҹеәҰзҡ„иҰҒжұӮжӣҙй«ҳпјҢжЈҖжөӢеҷЁдёҚд»…йңҖиҰҒеҝ«йҖҹиҜҶеҲ«е‘ЁеӣҙзҺҜеўғзҡ„зү©дҪ“пјҢиҝҳиҰҒеҜ№зү©дҪ“еңЁдёүз»ҙз©әй—ҙдёӯзҡ„дҪҚзҪ®еҒҡзІҫеҮҶе®ҡдҪҚгҖӮ然иҖҢпјҢзӣ®еүҚдё»жөҒзҡ„еҚ•йҳ¶ж®өжЈҖжөӢеҷЁе’ҢдёӨйҳ¶ж®өжЈҖжөӢеҷЁеқҮж— жі•е№іиЎЎжЈҖжөӢзІҫеәҰе’ҢйҖҹеәҰпјҢиҝҷжһҒеӨ§ең°йҷҗеҲ¶дәҶиҮӘеҠЁй©ҫ驶е®үе…ЁжҖ§иғҪгҖӮ
жӯӨж¬ЎпјҢиҫҫж‘©йҷўеңЁи®әж–ҮдёӯжҸҗеҮәдәҶж–°зҡ„жҖқи·ҜеҚіе°ҶдёӨйҳ¶ж®өжЈҖжөӢеҷЁдёӯеҜ№зү№еҫҒиҝӣиЎҢз»ҶзІ’еәҰеҲ»з”»зҡ„ж–№жі•йӣҶжҲҗеҲ°еҚ•йҳ¶ж®өжЈҖжөӢеҷЁгҖӮе…·дҪ“жқҘиҜҙпјҢиҫҫж‘©йҷўеңЁи®ӯз»ғдёӯеҲ©з”ЁдёҖдёӘиҫ…еҠ©зҪ‘з»ңе°ҶеҚ•йҳ¶ж®өжЈҖжөӢеҷЁдёӯзҡ„дҪ“зҙ зү№еҫҒиҪ¬еҢ–дёәзӮ№зә§зү№еҫҒпјҢ并ж–ҪеҠ дёҖе®ҡзҡ„зӣ‘зқЈдҝЎеҸ·пјҢеҗҢж—¶еңЁжЁЎеһӢжҺЁзҗҶиҝҮзЁӢдёӯиҫ…еҠ©зҪ‘з»ңж— йңҖеҸӮдёҺи®Ўз®—пјҢеӣ жӯӨпјҢеңЁдҝқйҡңйҖҹеәҰзҡ„еҗҢж—¶еҸҲжҸҗй«ҳдәҶжЈҖжөӢзІҫеәҰгҖӮ
д»ҘдёӢжҳҜ第дёҖдҪңиҖ… Chenhang He еҜ№иҜҘи®әж–ҮеҒҡеҮәзҡ„и§ЈиҜ»пјҡ
зӣ®ж ҮжЈҖжөӢжҳҜи®Ўз®—жңәи§Ҷи§үйўҶеҹҹзҡ„дј з»ҹд»»еҠЎпјҢдёҺеӣҫеғҸиҜҶеҲ«дёҚеҗҢпјҢзӣ®ж ҮжЈҖжөӢдёҚд»…йңҖиҰҒиҜҶеҲ«еҮәеӣҫеғҸдёҠеӯҳеңЁзҡ„зү©дҪ“пјҢз»ҷеҮәеҜ№еә”зҡ„зұ»еҲ«пјҢиҝҳйңҖиҰҒе°ҶиҜҘзү©дҪ“йҖҡиҝҮ Bounding box иҝӣиЎҢе®ҡдҪҚгҖӮж №жҚ®зӣ®ж ҮжЈҖжөӢйңҖиҰҒиҫ“еҮәз»“жһңзҡ„дёҚеҗҢпјҢдёҖиҲ¬е°ҶдҪҝз”Ё RGB еӣҫеғҸиҝӣиЎҢзӣ®ж ҮжЈҖжөӢпјҢиҫ“еҮәзү©дҪ“зұ»еҲ«е’ҢеңЁеӣҫеғҸдёҠ 2D bounding box зҡ„ж–№ејҸз§°дёә 2D зӣ®ж ҮжЈҖжөӢгҖӮиҖҢе°ҶдҪҝз”Ё RGB еӣҫеғҸгҖҒRGB-D ж·ұеәҰеӣҫеғҸе’ҢжҝҖе…үзӮ№дә‘пјҢиҫ“еҮәзү©дҪ“зұ»еҲ«еҸҠеңЁдёүз»ҙз©әй—ҙдёӯзҡ„й•ҝе®Ҫй«ҳгҖҒж—ӢиҪ¬и§’зӯүдҝЎжҒҜзҡ„жЈҖжөӢз§°дёә 3D зӣ®ж ҮжЈҖжөӢгҖӮ

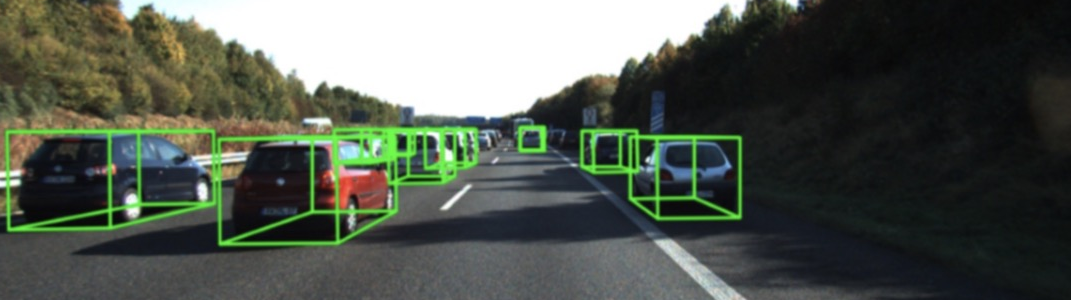
д»ҺзӮ№дә‘ж•°жҚ®иҝӣиЎҢ 3D зӣ®ж ҮжЈҖжөӢжҳҜиҮӘеҠЁй©ҫ驶пјҲAVпјүзі»з»ҹдёӯзҡ„зҡ„关键组件гҖӮдёҺд»…д»ҺеӣҫеғҸе№ійқўдј°и®Ў 2D иҫ№з•ҢжЎҶзҡ„жҷ®йҖҡ 2D зӣ®ж ҮжЈҖжөӢдёҚеҗҢпјҢAV йңҖиҰҒд»ҺзҺ°е®һдё–з•Ңдј°и®Ўжӣҙе…·дҝЎжҒҜйҮҸзҡ„ 3D иҫ№з•ҢжЎҶпјҢд»Ҙе®ҢжҲҗиҜёеҰӮи·Ҝеҫ„规еҲ’е’ҢйҒҝе…Қзў°ж’һд№Ӣзұ»зҡ„й«ҳзә§д»»еҠЎгҖӮиҝҷжҝҖеҸ‘дәҶжңҖиҝ‘еҮәзҺ°зҡ„ 3D зӣ®ж ҮжЈҖжөӢж–№жі•пјҢиҜҘж–№жі•еә”з”ЁеҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҲCNNпјүеӨ„зҗҶжқҘиҮӘй«ҳз«Ҝ LiDAR дј ж„ҹеҷЁзҡ„зӮ№дә‘ж•°жҚ®гҖӮ
зӣ®еүҚеҹәдәҺзӮ№дә‘зҡ„ 3D зү©дҪ“жЈҖжөӢдё»иҰҒжңүдёӨз§Қжһ¶жһ„пјҡ
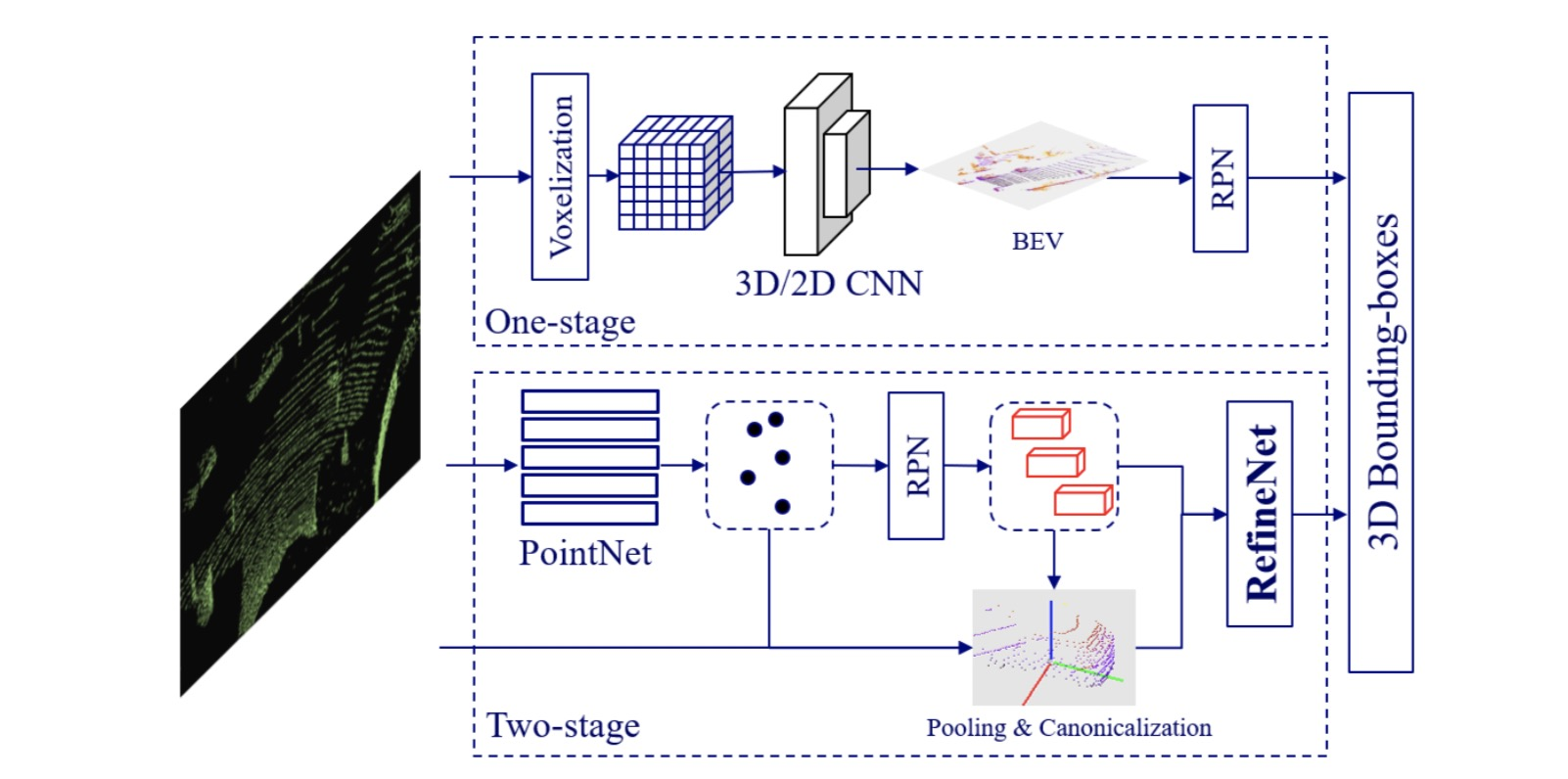
зӣ®еүҚдёҡз•Ңдё»иҰҒд»ҘеҚ•йҳ¶ж®өжЈҖжөӢеҷЁдёәдё»пјҢиҝҷж ·иғҪдҝқиҜҒжЈҖжөӢеҷЁиғҪй«ҳж•Ҳең°еңЁе®һж—¶зі»з»ҹдёҠиҝӣиЎҢгҖӮ жҲ‘们жҸҗеҮәзҡ„ж–№жЎҲе°ҶдёӨйҳ¶ж®өжЈҖжөӢеҷЁдёӯеҜ№зү№еҫҒиҝӣиЎҢз»ҶзІ’еәҰеҲ»з”»зҡ„жҖқжғіз§»жӨҚеҲ°еҚ•йҳ¶ж®өжЈҖжөӢдёӯпјҢйҖҡиҝҮеңЁи®ӯз»ғдёӯеҲ©з”ЁдёҖдёӘиҫ…еҠ©зҪ‘з»ңе°ҶеҚ•йҳ¶ж®өжЈҖжөӢеҷЁдёӯзҡ„дҪ“зҙ зү№еҫҒиҪ¬еҢ–дёәзӮ№зә§зү№еҫҒпјҢ并ж–ҪеҠ дёҖе®ҡзҡ„зӣ‘зқЈдҝЎеҸ·пјҢд»ҺиҖҢдҪҝеҫ—еҚ·з§Ҝзү№еҫҒд№ҹе…·жңүз»“жһ„ж„ҹзҹҘиғҪеҠӣпјҢиҝӣиҖҢжҸҗй«ҳжЈҖжөӢзІҫеәҰгҖӮиҖҢеңЁеҒҡжЁЎеһӢжҺЁж–ӯж—¶пјҢиҫ…еҠ©зҪ‘з»ң并дёҚеҸӮдёҺи®Ўз®—пјҲdetachedпјү, иҝӣиҖҢдҝқиҜҒдәҶеҚ•йҳ¶ж®өжЈҖжөӢеҷЁзҡ„жЈҖжөӢж•ҲзҺҮгҖӮеҸҰеӨ–жҲ‘们жҸҗеҮәдёҖдёӘе·ҘзЁӢдёҠзҡ„ж”№иҝӣпјҢPart-sensitive Warping (PSWarp), з”ЁдәҺеӨ„зҗҶеҚ•йҳ¶ж®өжЈҖжөӢеҷЁдёӯеӯҳеңЁзҡ„ вҖңжЎҶ - зҪ®дҝЎеәҰ - дёҚеҢ№й…ҚвҖқ й—®йўҳгҖӮ
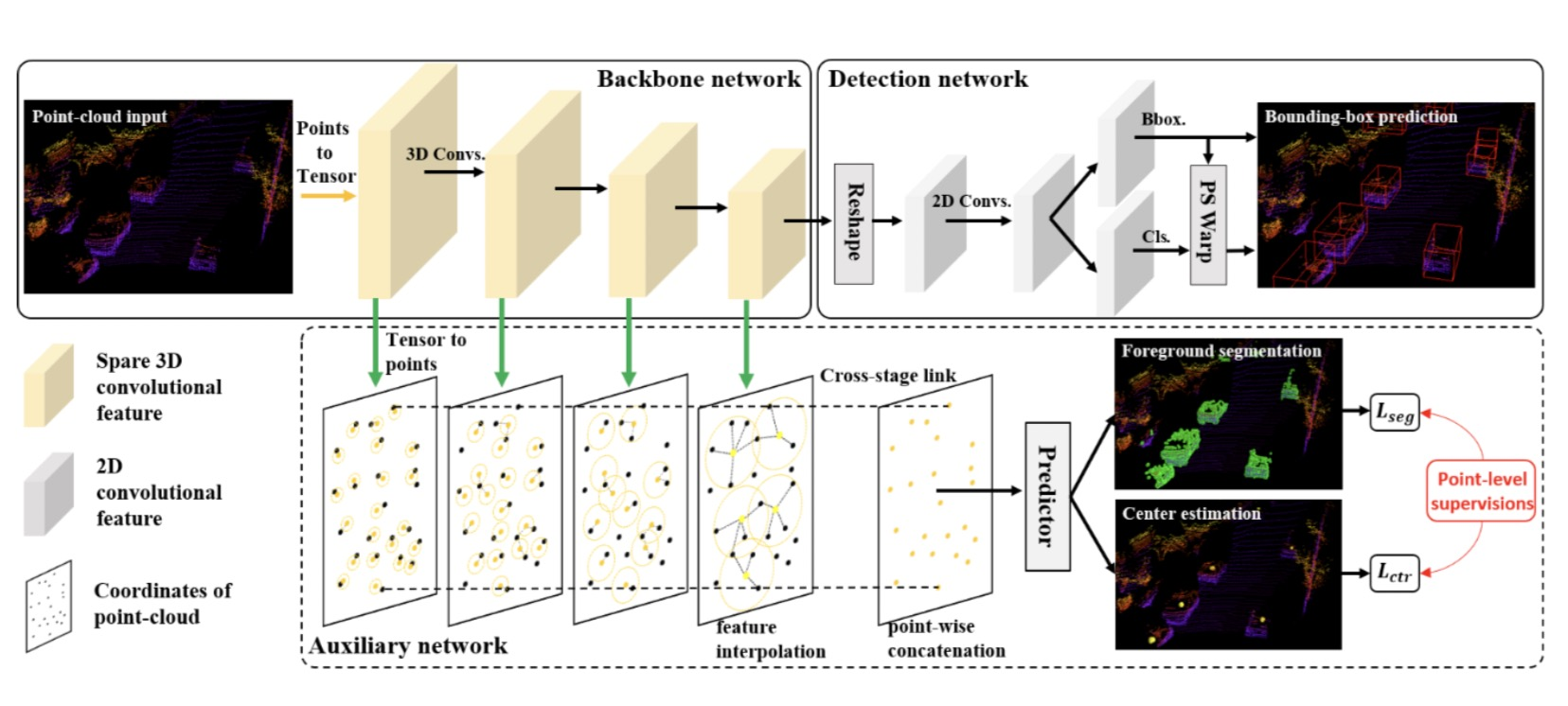
з”ЁдәҺйғЁзҪІзҡ„жЈҖжөӢеҷЁпјҢ еҚіжҺЁж–ӯзҪ‘з»ңпјҢ з”ұдёҖдёӘйӘЁе№ІзҪ‘з»ңе’ҢжЈҖжөӢеӨҙз»„жҲҗгҖӮйӘЁе№ІзҪ‘з»ңз”Ё 3D зҡ„зЁҖз–ҸзҪ‘з»ңе®һзҺ°пјҢз”ЁдәҺжҸҗеҸ–еҗ«жңүй«ҳиҜӯд№үзҡ„дҪ“зҙ зү№еҫҒгҖӮжЈҖжөӢеӨҙе°ҶдҪ“зҙ зү№еҫҒеҺӢзј©жҲҗйёҹзһ°еӣҫиЎЁзӨәпјҢ并еңЁдёҠйқўиҝҗиЎҢ 2D е…ЁеҚ·з§ҜзҪ‘з»ңжқҘйў„жөӢ 3D зү©дҪ“жЎҶгҖӮ
еңЁи®ӯз»ғйҳ¶ж®өпјҢжҲ‘们жҸҗеҮәдёҖдёӘиҫ…еҠ©зҪ‘з»ңжқҘжҠҪеҸ–йӘЁе№ІзҪ‘з»ңдёӯй—ҙеұӮзҡ„еҚ·з§Ҝзү№еҫҒпјҢ并е°Ҷиҝҷдәӣзү№еҫҒиҪ¬еҢ–жҲҗзӮ№зә§зү№еҫҒ (point-wise feature)гҖӮеңЁе®һзҺ°дёҠпјҢжҲ‘们е°ҶеҚ·з§Ҝзү№еҫҒдёӯзҡ„йқһйӣ¶дҝЎеҸ·жҳ е°„еҲ°еҺҹе§Ӣзҡ„зӮ№дә‘з©әй—ҙдёӯпјҢ 然еҗҺеңЁжҜҸдёӘзӮ№дёҠиҝӣиЎҢжҸ’еҖјпјҢиҝҷж ·жҲ‘们е°ұиғҪиҺ·еҸ–еҚ·з§Ҝзү№еҫҒзҡ„зӮ№зә§иЎЁзӨәгҖӮ д»Ө {():j=0,вҖҰ,M} дёәеҚ·з§Ҝзү№еҫҒеңЁз©әй—ҙдёӯзҡ„иЎЁзӨә, {:i=0,вҖҰ,N}дёәеҺҹе§ӢзӮ№дә‘, еҲҷеҚ·з§Ҝзү№еҫҒеңЁеҺҹе§ӢзӮ№дёҠзҡ„иЎЁзӨә зӯүдәҺ
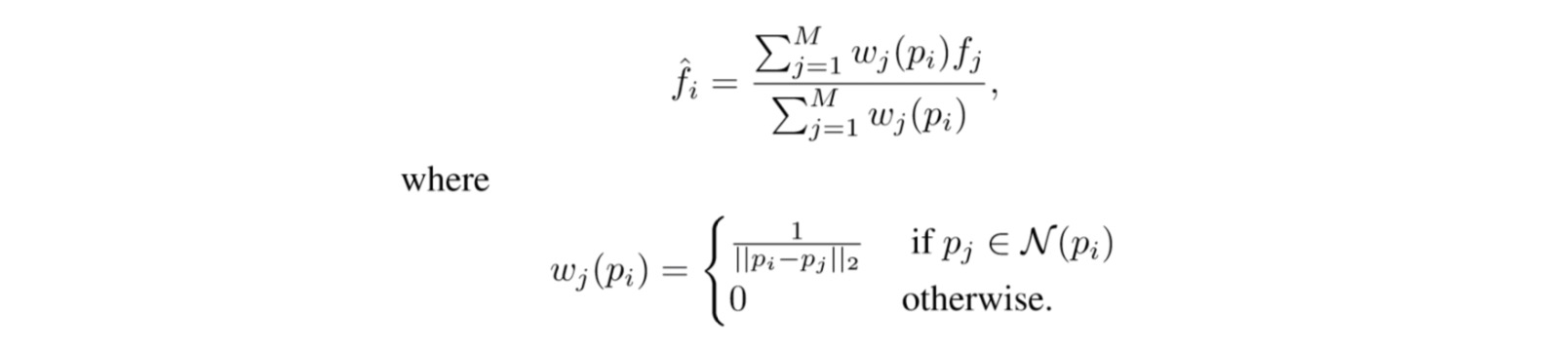
жҲ‘们жҸҗеҮәдёӨз§ҚеҹәдәҺзӮ№зә§зү№еҫҒзҡ„зӣ‘зқЈзӯ–з•ҘжқҘеё®еҠ©еҚ·з§Ҝзү№еҫҒиҺ·еҫ—еҫҲеҘҪзҡ„з»“жһ„ж„ҹзҹҘеҠӣпјҢдёҖдёӘеүҚжҷҜеҲҶеүІд»»еҠЎпјҢдёҖдёӘдёӯеҝғзӮ№еӣһеҪ’д»»еҠЎгҖӮ
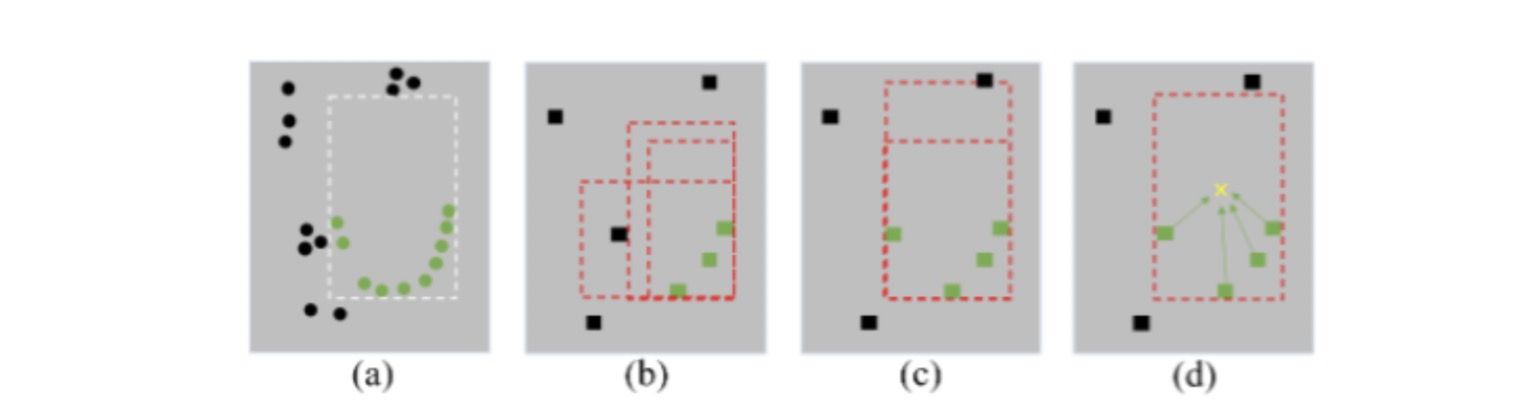
е…·дҪ“жқҘиҜҙпјҢзӣёжҜ”дәҺ PointNet зү№еҫҒжҸҗеҸ–еҷЁ (a)пјҢ еҚ·з§ҜзҪ‘з»ңдёӯзҡ„еҚ·з§Ҝж“ҚдҪңе’ҢдёӢйҮҮж ·дјҡйҖ жҲҗзӮ№дә‘з»“жһ„зҡ„з ҙеқҸпјҲbпјүдҪҝеҫ—зү№еҫҒеҜ№зү©дҪ“зҡ„иҫ№з•ҢдёҺеҶ…йғЁз»“жһ„дёҚж•Ҹж„ҹгҖӮжҲ‘们еҲ©з”ЁеҲҶеүІд»»еҠЎжқҘдҝқиҜҒйғЁеҲҶеҚ·з§Ҝзү№еҫҒеңЁдёӢйҮҮж ·ж—¶дёҚдјҡиў«иғҢжҷҜзү№еҫҒеҪұе“Қ В©пјҢд»ҺиҖҢеҠ ејәеҜ№иҫ№з•Ңзҡ„ж„ҹзҹҘгҖӮжҲ‘们еҲ©з”ЁдёӯеҝғзӮ№еӣһеҪ’д»»еҠЎжқҘеҠ ејәеҚ·з§Ҝзү№еҫҒеҜ№зү©дҪ“еҶ…йғЁз»“жһ„зҡ„ж„ҹзҹҘиғҪеҠӣ (d)пјҢдҪҝеҫ—еңЁе°‘йҮҸзӮ№зҡ„жғ…еҶөдёӢд№ҹиғҪеҗҲзҗҶзҡ„жҺЁж–ӯеҮәзү©дҪ“зҡ„жҪңеңЁеӨ§е°ҸгҖҒеҪўзҠ¶гҖӮжҲ‘们дҪҝз”Ё focal loss е’Ң smooth-l1 еҜ№еҲҶеүІд»»еҠЎдёҺдёӯеҝғеӣһеҪ’д»»еҠЎеҲҶиҫЁиҝӣиЎҢдјҳеҢ–гҖӮ
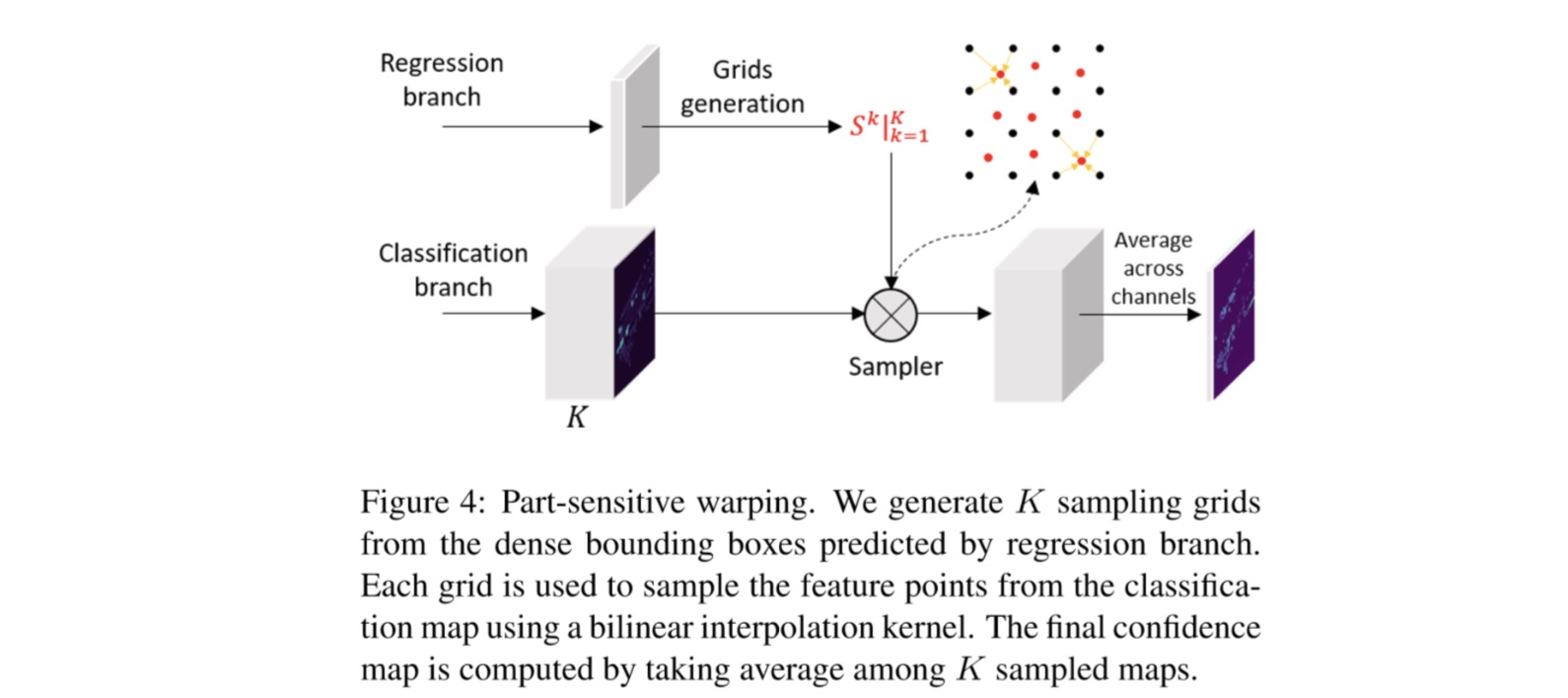
еңЁеҚ•йҳ¶ж®өжЈҖжөӢдёӯпјҢ feature map е’Ң anchor зҡ„еҜ№йҪҗй—®йўҳжҳҜжҷ®йҒҚеӯҳеңЁзҡ„й—®йўҳпјҢ иҝҷж ·дјҡеҜјиҮҙйў„жөӢеҮәжқҘзҡ„иҫ№з•ҢжЎҶзҡ„е®ҡдҪҚиҙЁйҮҸдёҺзҪ®дҝЎеәҰдёҚеҢ№й…ҚпјҢиҝҷдјҡеҪұе“ҚеңЁеҗҺеӨ„зҗҶйҳ¶ж®өпјҲNMSпјүж—¶пјҢ й«ҳзҪ®дҝЎеәҰдҪҶдҪҺе®ҡдҪҚиҙЁйҮҸзҡ„жЎҶиў«дҝқз•ҷпјҢ иҖҢе®ҡдҪҚиҙЁйҮҸй«ҳеҚҙзҪ®дҝЎеәҰдҪҺзҡ„жЎҶиў«дёўејғгҖӮеңЁ two-stage зҡ„зӣ®ж ҮжЈҖжөӢз®—жі•дёӯпјҢRPN жҸҗеҸ– proposalпјҢ然еҗҺдјҡеңЁ feature map дёҠеҜ№еә”зҡ„зҡ„дҪҚзҪ®жҸҗеҸ–зү№еҫҒпјҲroi-pooling жҲ–иҖ… roi-alignпјүпјҢиҝҷдёӘж—¶еҖҷж–°зҡ„зү№еҫҒе’ҢеҜ№еә”зҡ„ proposal жҳҜеҜ№йҪҗзҡ„гҖӮжҲ‘们жҸҗеҮәдәҶдёҖдёӘеҹәдәҺ PSRoIAlign зҡ„ж”№иҝӣпјҢPart-sensitive Warping (PSWarp), з”ЁжқҘеҜ№йў„жөӢжЎҶиҝӣиЎҢйҮҚжү“еҲҶгҖӮ
еҰӮдёҠеӣҫпјҢ жҲ‘们йҰ–е…Ҳдҝ®ж”№жңҖеҗҺзҡ„еҲҶзұ»еұӮд»Ҙз”ҹжҲҗ K дёӘйғЁеҲҶж•Ҹж„ҹзҡ„зү№еҫҒеӣҫпјҢз”Ё{X_kпјҡk = 1,2пјҢвҖҰпјҢK}иЎЁзӨәпјҢжҜҸдёӘеӣҫйғҪзј–з ҒеҜ№иұЎзҡ„зү№е®ҡйғЁеҲҶзҡ„дҝЎжҒҜгҖӮдҫӢеҰӮпјҢеңЁ K = 4 зҡ„жғ…еҶөдёӢпјҢдјҡз”ҹжҲҗ {е·ҰдёҠпјҢеҸідёҠпјҢе·ҰдёӢпјҢеҸідёӢ} еӣӣдёӘеұҖйғЁж•Ҹж„ҹзҡ„зү№еҫҒеӣҫгҖӮеҗҢж—¶пјҢжҲ‘们е°ҶжҜҸдёӘйў„жөӢиҫ№з•ҢжЎҶеҲ’еҲҶдёә K дёӘеӯҗзӘ—еҸЈпјҢ然еҗҺйҖүжӢ©жҜҸдёӘеӯҗзӘ—еҸЈзҡ„дёӯеҝғдҪҚзҪ®дҪңдёәйҮҮж ·зӮ№гҖӮиҝҷж ·пјҢжҲ‘们еҸҜд»Ҙз”ҹжҲҗ K дёӘйҮҮж ·зҪ‘ж ј{S^kпјҡk = 1,2пјҢвҖҰпјҢK}пјҢжҜҸдёӘйҮҮж ·зҪ‘ж јйғҪдёҺиҜҘеұҖйғЁеҜ№еә”зҡ„зү№еҫҒеӣҫзӣёе…іиҒ”гҖӮеҰӮеӣҫжүҖзӨәпјҢжҲ‘们еҲ©з”ЁйҮҮж ·еҷЁпјҢ з”Ёз”ҹжҲҗзҡ„йҮҮж ·зҪ‘ж јеңЁеҜ№еә”зҡ„еұҖйғЁж•Ҹж„ҹзү№еҫҒеӣҫдёҠиҝӣиЎҢйҮҮж ·пјҢз”ҹжҲҗеҜ№йҪҗеҘҪзҡ„зү№еҫҒеӣҫгҖӮжңҖз»ҲиғҪеҸҚжҳ зҪ®дҝЎеәҰзҡ„зү№еҫҒеӣҫеҲҷжҳҜ K дёӘеҜ№йҪҗеҘҪзү№еҫҒеӣҫзҡ„е№іеқҮгҖӮ
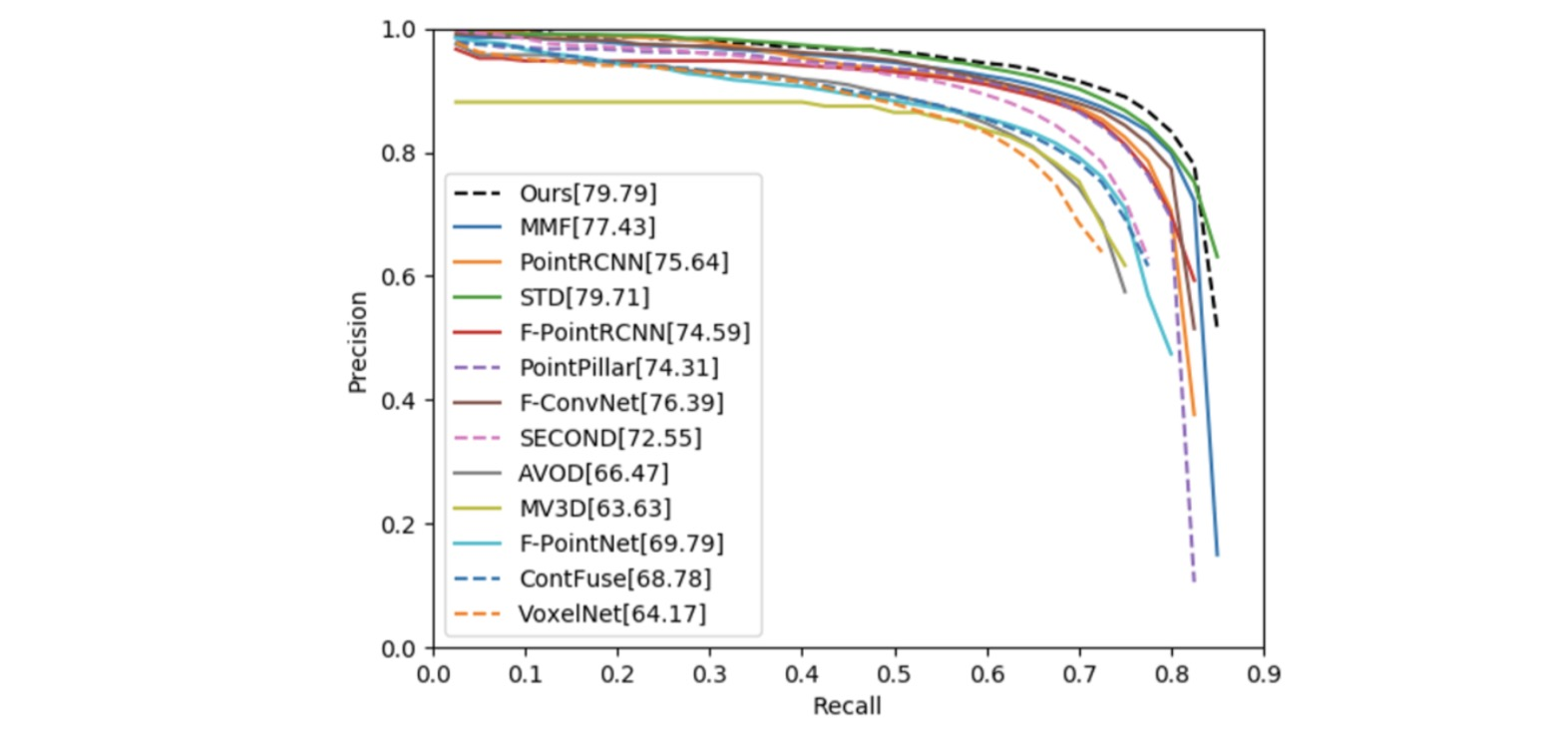
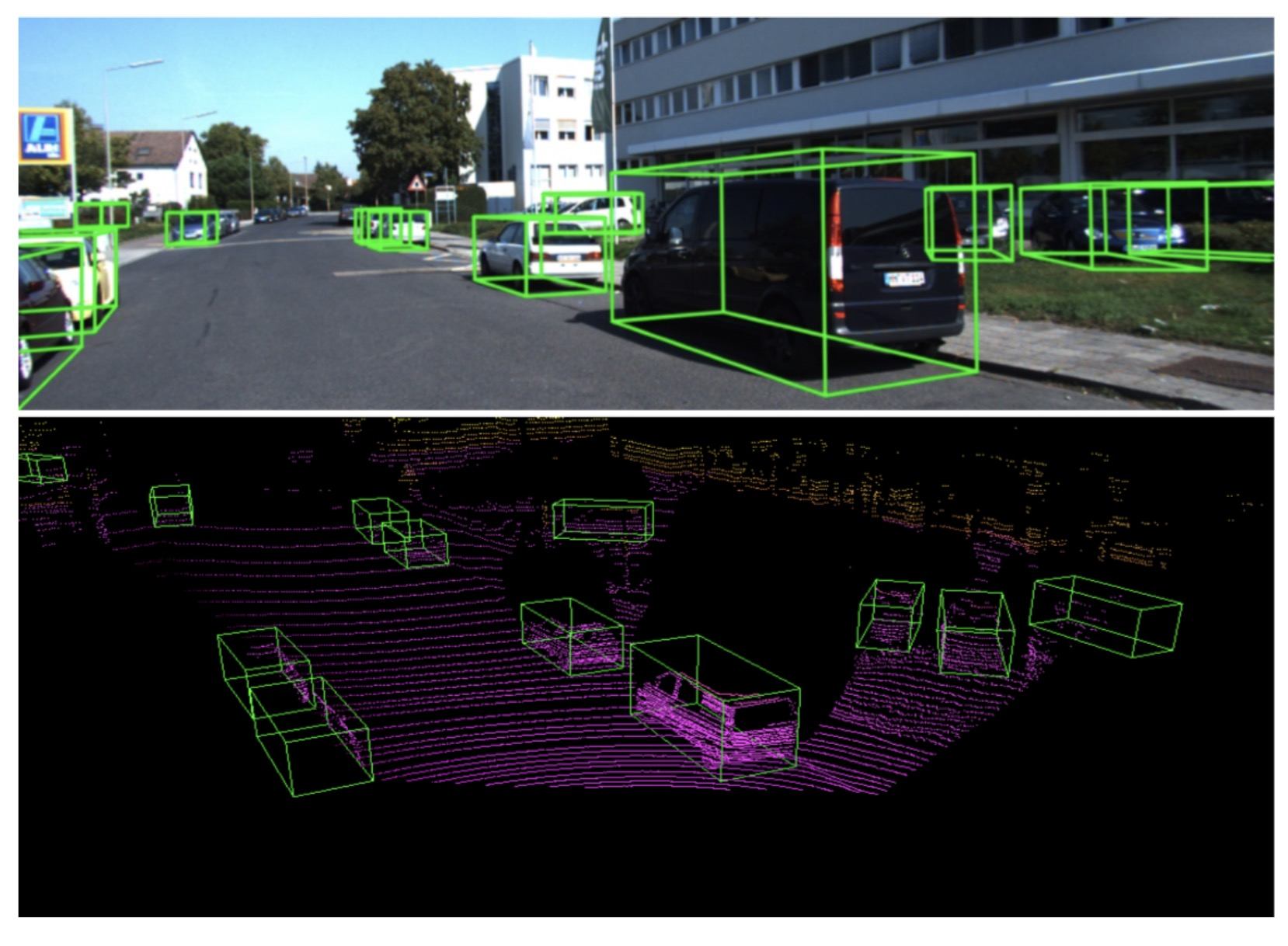
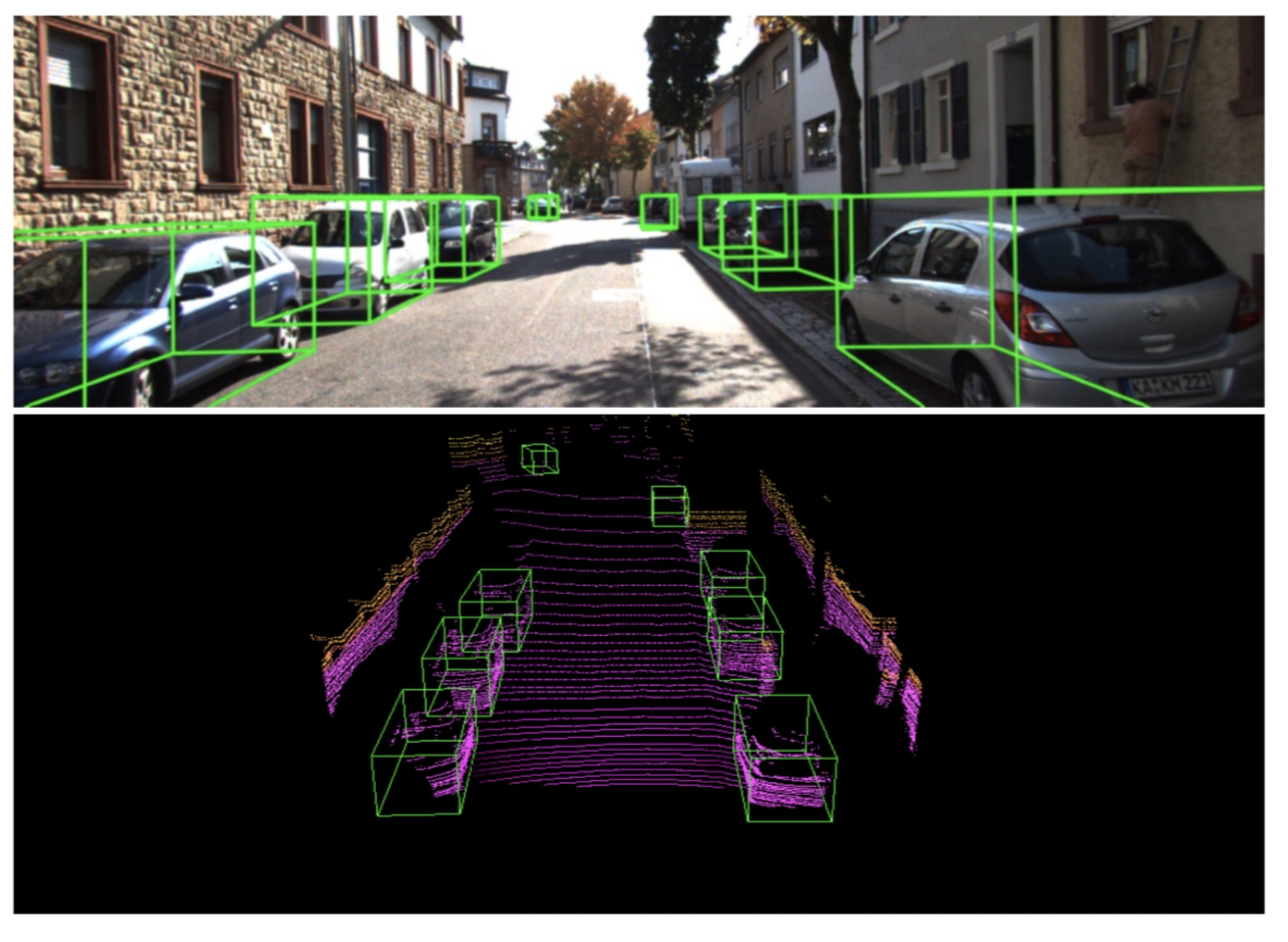
жҲ‘们жҸҗеҮәзҡ„ж–№жі• (й»‘иүІ) еңЁ KITTI ж•°жҚ®еә“дёҠзҡ„ PR CurveпјҢ е…¶дёӯе®һзәҝдёәдёӨйҳ¶ж®өж–№жі•пјҢ иҷҡзәҝдёәеҚ•йҳ¶ж®өж–№жі•гҖӮ еҸҜд»ҘзңӢеҲ°жҲ‘们дҪңдёәеҚ•йҳ¶ж®өж–№жі•иғҪеӨҹиҫҫеҲ°дёӨйҳ¶ж®өж–№жі•жүҚиғҪиҫҫеҲ°зҡ„зІҫеәҰгҖӮ
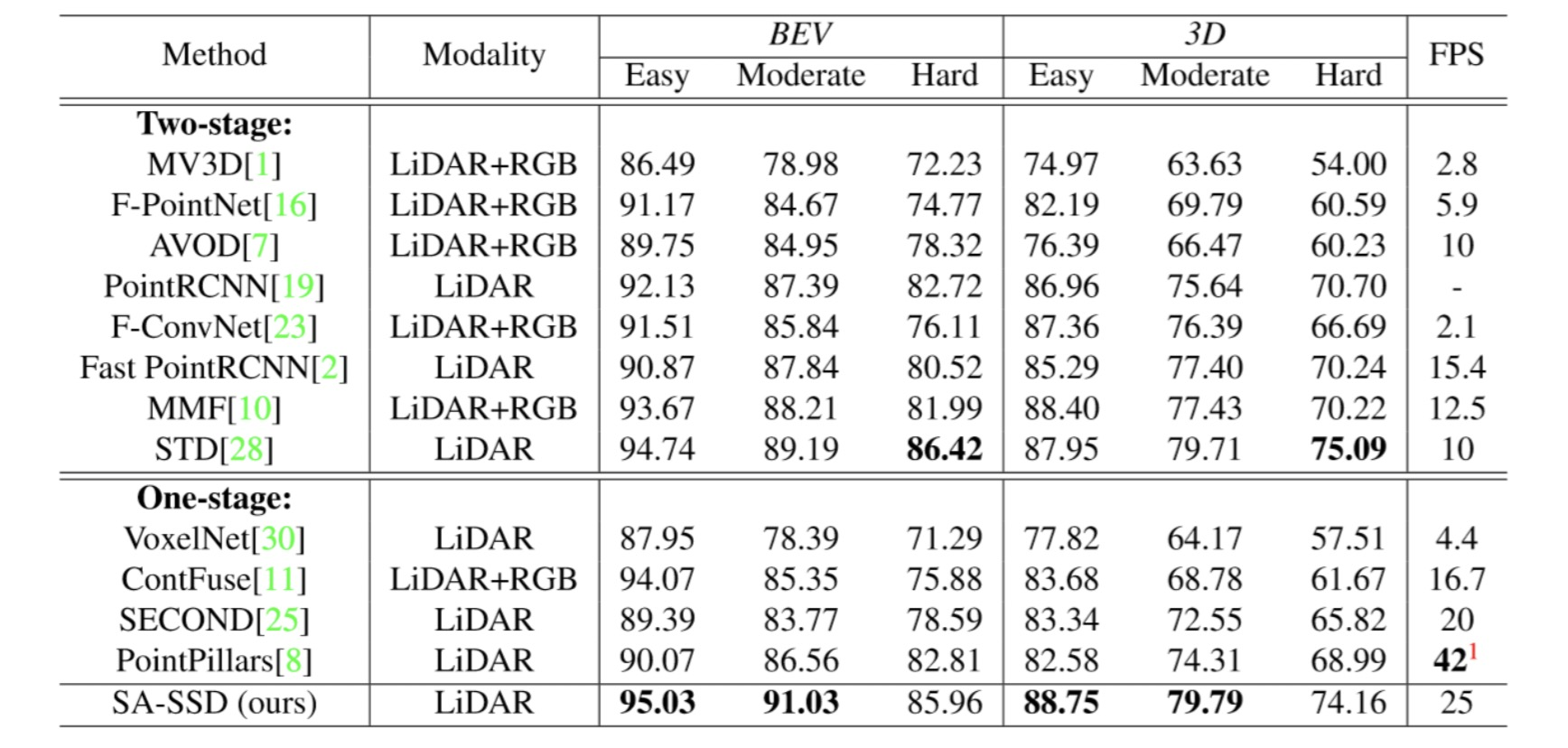
еңЁ KITTI йёҹзһ° (BEV) е’Ң 3D жөӢиҜ•йӣҶзҡ„ж•ҲжһңгҖӮдјҳзӮ№жҳҜеңЁдҝқжҢҒзІҫеәҰзҡ„еҗҢж—¶пјҢдёҚеўһеҠ йўқеӨ–зҡ„и®Ўз®—йҮҸпјҢиғҪиҫҫеҲ° 25FPS зҡ„жЈҖжөӢйҖҹеәҰгҖӮ

第дёҖдҪңиҖ…дёәиҫҫж‘©йҷўз ”究е®һд№ з”ҹ Chenhang HeпјҢе…¶д»–дҪңиҖ…еҲҶеҲ«еҲҶеҲ«дёәиҫҫж‘©йҷўй«ҳзә§з ”究е‘ҳгҖҒIEEE Fellow еҚҺе…ҲиғңпјҢиҫҫж‘©йҷўй«ҳзә§з ”究е‘ҳгҖҒйҰҷжёҜзҗҶе·ҘеӨ§еӯҰз”өеӯҗи®Ўз®—еӯҰзі»и®Іеә§ж•ҷжҺҲгҖҒIEEE Fellow еј зЈҠпјҢиҫҫж‘©йҷўиө„ж·ұ算法专家黄е»әејәеҸҠиҫҫж‘©йҷўз ”究е®һд№ з”ҹ Hui ZengгҖӮ
еҺҹж–Үй“ҫжҺҘпјҡ https://developer.aliyun.com/article/752688
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ