жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іPythonжңәеҷЁеӯҰд№ д№ӢAdaBoostз®—жі•зҡ„зӨәдҫӢеҲҶжһҗпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
AdaBoost жҳҜиӢұж–Ү Adaptive BoostingпјҲиҮӘйҖӮеә”еўһејәпјүзҡ„зј©еҶҷпјҢз”ұ Yoav Freund е’ҢRobert Schapire еңЁ1995е№ҙжҸҗеҮәгҖӮ
AdaBoost зҡ„иҮӘйҖӮеә”еңЁдәҺеүҚдёҖдёӘеҹәжң¬еҲҶзұ»еҷЁеҲҶзұ»й”ҷиҜҜзҡ„ж ·жң¬зҡ„жқғйҮҚдјҡеҫ—еҲ°еҠ ејәпјҢеҠ ејәеҗҺзҡ„е…ЁдҪ“ж ·жң¬еҶҚж¬Ўиў«з”ЁжқҘи®ӯз»ғдёӢдёҖдёӘеҹәжң¬еҲҶзұ»еҷЁгҖӮеҗҢж—¶пјҢеңЁжҜҸдёҖиҪ®и®ӯз»ғдёӯеҠ е…ҘдёҖдёӘж–°зҡ„ејұеҲҶзұ»еҷЁпјҢзӣҙеҲ°иҫҫеҲ°жҹҗдёӘйў„е®ҡзҡ„и¶іеӨҹе°Ҹзҡ„й”ҷиҜҜзҺҮжҲ–иҫҫеҲ°йў„е…ҲжҢҮе®ҡзҡ„жңҖеӨ§иҝӯд»Јж¬Ўж•°ж—¶еҒңжӯўи®ӯз»ғгҖӮ
AdaBoost з®—жі•жҳҜдёҖз§ҚйӣҶжҲҗеӯҰд№ зҡ„з®—жі•пјҢе…¶ж ёеҝғжҖқжғіе°ұжҳҜеҜ№еӨҡдёӘжңәеҷЁеӯҰд№ жЁЎеһӢиҝӣиЎҢз»„еҗҲеҪўжҲҗдёҖдёӘзІҫеәҰжӣҙй«ҳзҡ„жЁЎеһӢпјҢеҸӮдёҺз»„еҗҲзҡ„жЁЎеһӢз§°дёәејұеӯҰд№ еҷЁгҖӮ
AdaBoost зҡ„ж ёеҝғжҖқжғіжҳҜй’ҲеҜ№еҗҢдёҖи®ӯз»ғйӣҶи®ӯз»ғдёҚеҗҢзҡ„еҲҶзұ»еҷЁпјҲејұеҲҶзұ»еҷЁпјүпјҢ然еҗҺжҠҠиҝҷдәӣејұеҲҶзұ»еҷЁйӣҶеҗҲиө·жқҘпјҢжһ„жҲҗдёҖдёӘжӣҙејәеӨ§зҡ„жңҖз»ҲеҲҶзұ»еҷЁпјҲејәеҲҶзұ»еҷЁпјүгҖӮд№ҹ е°ұжҳҜйҖҡиҝҮдёҖдәӣжүӢж®өиҺ·еҫ—еӨҡдёӘејұеҲҶзұ»еҷЁпјҢе°Ҷе®ғ们йӣҶжҲҗиө·жқҘжһ„жҲҗејәеҲҶзұ»еҷЁпјҢз»јеҗҲжүҖжңүеҲҶзұ»еҷЁзҡ„йў„жөӢеҫ—еҮәжңҖз»Ҳзҡ„з»“жһңгҖӮ
AdaBoost з®—жі•жң¬иә«жҳҜйҖҡиҝҮж”№еҸҳж•°жҚ®еҲҶеёғжқҘе®һзҺ°зҡ„пјҢе®ғж №жҚ®жҜҸж¬Ўи®ӯз»ғйӣҶдёӯжҜҸдёӘж ·жң¬зҡ„еҲҶзұ»жҳҜеҗҰжӯЈзЎ®пјҢд»ҘеҸҠдёҠж¬Ўзҡ„жҖ»дҪ“еҲҶзұ»зҡ„еҮҶзЎ®зҺҮпјҢжқҘзЎ®е®ҡжҜҸдёӘж ·жң¬зҡ„жқғеҖјгҖӮе°Ҷдҝ®ж”№иҝҮжқғеҖјзҡ„ж–°ж•°жҚ®йӣҶйҖҒз»ҷдёӢеұӮеҲҶзұ»еҷЁиҝӣиЎҢи®ӯз»ғпјҢжңҖеҗҺе°ҶжҜҸж¬Ўи®ӯз»ғеҫ—еҲ°зҡ„еҲҶзұ»еҷЁжңҖеҗҺиһҚеҗҲиө·жқҘпјҢдҪңдёәжңҖеҗҺзҡ„еҶізӯ–еҲҶзұ»еҷЁгҖӮ
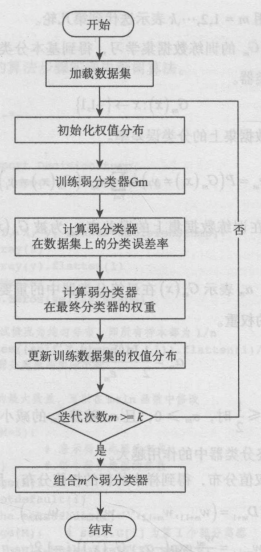
1.еҲқе§ӢеҢ–и®ӯз»ғж•°жҚ®зҡ„жқғеҖјеҲҶеёғпјҢжҜҸдёҖдёӘи®ӯз»ғж ·жң¬жңҖејҖе§Ӣж—¶йғҪиў«иөӢдәҲзӣёеҗҢзҡ„жқғеҖј 1/n
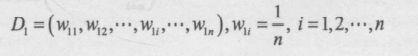
2.иҝӣиЎҢеӨҡиҪ®иҝӯд»ЈпјҢз”Ё m = 1,2,вҖҰ,k иЎЁзӨәиҝӯд»ЈеҲ°з¬¬еҮ иҪ®
3.дҪҝз”Ёе…·жңүжқғеҖјеҲҶеёғ Gm зҡ„и®ӯз»ғж•°жҚ®йӣҶеӯҰд№ пјҢеҫ—еҲ°еҹәжң¬еҲҶзұ»еҷЁ
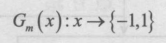
4.и®Ўз®— Gm(x) еңЁи®ӯз»ғж•°жҚ®йӣҶдёҠзҡ„еҲҶзұ»иҜҜе·®зҺҮ

5.и®Ўз®— Gm(x) зҡ„зі»ж•°пјҢamиЎЁзӨә Gm(x) еңЁжңҖз»ҲеҲҶзұ»еҷЁдёӯзҡ„йҮҚиҰҒзЁӢеәҰ
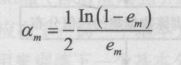
6.жӣҙж–°и®ӯз»ғж•°жҚ®йӣҶзҡ„жқғеҖјеҲҶеёғпјҢеҫ—еҲ°ж ·жң¬зҡ„ж–°зҡ„жқғеҖјеҲҶеёғпјҢз”ЁдәҺдёӢдёҖиҪ®иҝӯд»Ј
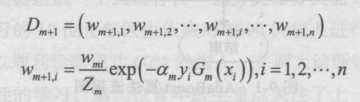
7.з»„еҗҲеҗ„дёӘејұеҲҶзұ»еҷЁ
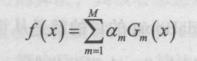
from numpy import *
import matplotlib.pyplot as plt
# еҠ иҪҪж•°жҚ®йӣҶ
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t'))
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
# иҝ”еӣһеҲҶзұ»йў„жөӢз»“жһң ж №жҚ®йҳҲеҖјжүҖд»ҘжңүдёӨз§Қиҝ”еӣһжғ…еҶө
def stumpClassify(dataMatrix, dimen, threshVal, threshIneq):
retArray = ones((shape(dataMatrix)[0], 1))
if threshIneq == 'lt':
retArray[dataMatrix[:, dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:, dimen] > threshVal] = -1.0
return retArray
# иҝ”еӣһ иҜҘејұеҲҶзұ»еҷЁеҚ•еұӮеҶізӯ–ж ‘зҡ„дҝЎжҒҜ жӣҙж–°Dеҗ‘йҮҸзҡ„й”ҷиҜҜзҺҮ жӣҙж–°Dеҗ‘йҮҸзҡ„йў„жөӢзӣ®ж Ү
def buildStump(dataArr, classLabels, D):
dataMatrix = mat(dataArr)
labelMat = mat(classLabels).T
m, n = shape(dataMatrix)
numSteps = 10.0
bestStump = {} # еӯ—е…ёз”ЁдәҺдҝқеӯҳжҜҸдёӘеҲҶзұ»еҷЁдҝЎжҒҜ
bestClasEst = mat(zeros((m, 1)))
minError = inf # еҲқе§ӢеҢ–жңҖе°ҸиҜҜе·®жңҖеӨ§
for i in range(n): # зү№еҫҒеҫӘзҺҜ пјҲдёүеұӮеҫӘзҺҜпјҢйҒҚеҺҶжүҖжңүзҡ„еҸҜиғҪжҖ§пјү
rangeMin = dataMatrix[:, i].min()
rangeMax = dataMatrix[:, i].max()
stepSize = (rangeMax - rangeMin) / numSteps # (еӨ§-е°Ҹ)/еҲҶеүІж•° еҫ—еҲ°жңҖе°ҸеҖјеҲ°жңҖеӨ§еҖјйңҖиҰҒзҡ„жҜҸдёҖж®өи·қзҰ»
for j in range(-1, int(numSteps) + 1): # йҒҚеҺҶжӯҘй•ҝ жңҖе°ҸеҖјеҲ°жңҖеӨ§еҖјзҡ„йңҖиҰҒж¬Ўж•°
for inequal in ['lt', 'gt']: # еңЁеӨ§дәҺе’Ңе°ҸдәҺд№Ӣй—ҙеҲҮжҚў
threshVal = (rangeMin + float(j) * stepSize) # жңҖе°ҸеҖј+ж¬Ўж•°*жӯҘй•ҝ жҜҸдёҖж¬Ўд»ҺжңҖе°ҸеҖјиө°зҡ„й•ҝеәҰ
predictedVals = stumpClassify(dataMatrix, i, threshVal,
inequal) # жңҖдјҳйў„жөӢзӣ®ж ҮеҖј з”ЁдәҺдёҺзӣ®ж ҮеҖјжҜ”иҫғеҫ—еҲ°иҜҜе·®
errArr = mat(ones((m, 1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T * errArr
if weightedError < minError: # йҖүеҮәжңҖе°Ҹй”ҷиҜҜзҡ„йӮЈдёӘзү№еҫҒ
minError = weightedError # жңҖе°ҸиҜҜе·® еҗҺйқўз”ЁжқҘжӣҙж–°DжқғеҖјзҡ„
bestClasEst = predictedVals.copy() # жңҖдјҳйў„жөӢеҖј
bestStump['dim'] = i # зү№еҫҒ
bestStump['thresh'] = threshVal # еҲ°жңҖе°ҸеҖјзҡ„и·қзҰ» пјҲеҫ—еҲ°жңҖдјҳйў„жөӢеҖјзҡ„йӮЈдёӘи·қзҰ»пјү
bestStump['ineq'] = inequal # еӨ§дәҺиҝҳжҳҜе°ҸдәҺ жңҖдјҳи·қзҰ»дёә-1
return bestStump, minError, bestClasEst
# еҫӘзҺҜжһ„е»әnumItдёӘејұеҲҶзұ»еҷЁ
def adaBoostTrainDS(dataArr, classLabels, numIt=40):
weakClassArr = [] # дҝқеӯҳејұеҲҶзұ»еҷЁж•°з»„
m = shape(dataArr)[0]
D = mat(ones((m, 1)) / m) # Dеҗ‘йҮҸ жҜҸжқЎж ·жң¬жүҖеҜ№еә”зҡ„дёҖдёӘжқғйҮҚ
aggClassEst = mat(zeros((m, 1))) # з»ҹи®Ўзұ»еҲ«дј°и®ЎзҙҜз§ҜеҖј
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D)
alpha = float(0.5 * log((1.0 - error) / max(error, 1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) # еҠ е…ҘеҚ•еұӮеҶізӯ–ж ‘
# еҫ—еҲ°иҝҗз®—е…¬ејҸдёӯзҡ„еҗ‘йҮҸ+/-ОұпјҢйў„жөӢжӯЈзЎ®дёә-ОұпјҢй”ҷиҜҜеҲҷ+ОұгҖӮжҜҸжқЎж ·жң¬дёҖдёӘОұ
# multiplyеҜ№еә”дҪҚзҪ®зӣёд№ҳ иҝҷйҮҢеҫҲиҒӘжҳҺпјҢз”Ё-1*зңҹе®һзӣ®ж ҮеҖј*йў„жөӢеҖјпјҢе®һзҺ°дәҶй”ҷиҜҜеҲҶзұ»еҲҷ-пјҢжӯЈзЎ®еҲҷ+
expon = multiply(-1 * alpha * mat(classLabels).T, classEst)
D = multiply(D, exp(expon)) # иҝҷдёүжӯҘдёәжӣҙж–°жҰӮзҺҮеҲҶеёғDеҗ‘йҮҸ жӢҶеҲҶејҖжқҘдәҶпјҢжҜҸдёҖжӯҘдёҺе…¬ејҸзӣёеҗҢ
D = D / D.sum()
# и®Ўз®—еҒңжӯўжқЎд»¶й”ҷиҜҜзҺҮ=0 д»ҘеҸҠи®Ўз®—жҜҸж¬Ўзҡ„aggClassEstзұ»еҲ«дј°и®ЎзҙҜи®ЎеҖј
aggClassEst += alpha * classEst
# еҫҲиҒӘжҳҺзҡ„и®Ўз®—ж–№жі• и®Ўз®—еҫ—еҲ°й”ҷиҜҜзҡ„дёӘж•°пјҢеҗ‘йҮҸдёӯдёә1еҲҷй”ҷиҜҜеҖј
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T, ones((m, 1))) # signиҝ”еӣһж•°еҖјзҡ„жӯЈиҙҹз¬ҰеҸ·пјҢд»Ҙ1гҖҒ-1иЎЁзӨә
errorRate = aggErrors.sum() / m # й”ҷиҜҜдёӘж•°/жҖ»дёӘж•°
# print("й”ҷиҜҜзҺҮпјҡ", errorRate)
if errorRate == 0.0:
break
return weakClassArr, aggClassEst
# йў„жөӢ зҙҜеҠ еӨҡдёӘејұеҲҶзұ»еҷЁиҺ·еҫ—йў„жөӢеҖј*иҜҘalpha еҫ—еҲ°з»“жһң
def adaClassify(datToClass, classifierArr): # classifierArrжҳҜе…ғз»„пјҢжүҖд»ҘеңЁеҸ–еҖјж—¶йңҖиҰҒжіЁж„Ҹ
dataMatrix = mat(datToClass)
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m, 1)))
# еҫӘзҺҜжүҖжңүејұеҲҶзұ»еҷЁ
for i in range(len(classifierArr[0])):
# иҺ·еҫ—йў„жөӢз»“жһң
classEst = stumpClassify(dataMatrix, classifierArr[0][i]['dim'], classifierArr[0][i]['thresh'],
classifierArr[0][i]['ineq'])
# иҜҘеҲҶзұ»еҷЁОұ*йў„жөӢз»“жһң з”ЁдәҺзҙҜеҠ еҫ—еҲ°жңҖз»Ҳзҡ„жӯЈиҙҹеҲӨж–ӯжқЎд»¶
aggClassEst += classifierArr[0][i]['alpha'] * classEst # иҝҷйҮҢе°ұжҳҜйӣҶеҗҲжүҖжңүејұеҲҶзұ»еҷЁзҡ„ж„Ҹи§ҒпјҢеҫ—еҲ°жңҖз»Ҳзҡ„ж„Ҹи§Ғ
return sign(aggClassEst) # жҸҗеҸ–ж•°жҚ®з¬ҰеҸ·
# ROCжӣІзәҝпјҢзұ»еҲ«зҙҜи®ЎеҖјгҖҒзӣ®ж Үж Үзӯҫ
def plotROC(predStrengths, classLabels):
cur = (1.0, 1.0) # жҜҸж¬Ўз”»зәҝзҡ„иө·зӮ№жёёж ҮзӮ№
ySum = 0.0 # з”ЁдәҺи®Ўз®—AUCзҡ„еҖј зҹ©еҪўйқўз§Ҝзҡ„й«ҳеәҰзҙҜи®ЎеҖј
numPosClas = sum(array(classLabels) == 1.0) # жүҖжңүзңҹе®һжӯЈдҫӢ зЎ®е®ҡдәҶеңЁyеқҗж ҮиҪҙдёҠзҡ„жӯҘиҝӣж•°зӣ®
yStep = 1 / float(numPosClas) # 1/жүҖжңүзңҹе®һжӯЈдҫӢ yиҪҙдёҠзҡ„жӯҘй•ҝ
xStep = 1 / float(len(classLabels) - numPosClas) # 1/жүҖжңүзңҹе®һеҸҚдҫӢ xиҪҙдёҠзҡ„жӯҘй•ҝ
sortedIndicies = predStrengths.argsort() # иҺ·еҫ—зҙҜи®ЎеҖјеҗ‘йҮҸд»Һе°ҸеҲ°еӨ§жҺ’еәҸзҡ„дёӢиЎЁindex [50,88,2,71...]
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
# еҫӘзҺҜжүҖжңүзҡ„зҙҜи®ЎеҖј д»Һе°ҸеҲ°еӨ§
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0 # иӢҘдёәдёҖдёӘзңҹжӯЈдҫӢпјҢеҲҷжІҝyйҷҚдёҖдёӘжӯҘй•ҝпјҢеҚідёҚж–ӯйҷҚдҪҺзңҹйҳізҺҮпјӣ
delY = yStep # иӢҘдёәдёҖдёӘйқһзңҹжӯЈдҫӢпјҢеҲҷжІҝxйҖҖдёҖдёӘжӯҘй•ҝпјҢ尖笑йҳізҺҮ
else:
delX = xStep
delY = 0
ySum += cur[1] # еҗ‘дёӢ移еҠЁдёҖж¬ЎпјҢеҲҷзҙҜи®ЎдёҖдёӘй«ҳеәҰгҖӮе®ҪеәҰдёҚеҸҳпјҢжҲ‘们еҸӘи®Ўз®—й«ҳеәҰ
ax.plot([cur[0], cur[0] - delX], [cur[1], cur[1] - delY], c='b') # е§Ӣз»ҲдјҡжңүдёҖдёӘзӮ№жҳҜжІЎжңүж”№еҸҳзҡ„
cur = (cur[0] - delX, cur[1] - delY)
ax.plot([0, 1], [0, 1], 'b--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve for AdaBoost horse colic detection system')
ax.axis([0, 1, 0, 1])
plt.show()
print("the Area Under the Curve is: ", ySum * xStep) # AUCйқўз§ҜжҲ‘们д»Ҙ й«ҳ*дҪҺ зҡ„зҹ©еҪўжқҘи®Ўз®—
# жөӢиҜ•жӯЈзЎ®зҺҮ
datArr, labelArr = loadDataSet('horseColicTraining2.txt')
classifierArr = adaBoostTrainDS(datArr, labelArr, 15)
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
prediction10 = adaClassify(testArr, classifierArr)
errArr = mat(ones((67, 1))) # дёҖе…ұжңү67дёӘж ·жң¬
cnt = errArr[prediction10 != mat(testLabelArr).T].sum()
print(cnt / 67)
# з”»еҮәROCжӣІзәҝ
datArr, labelArr = loadDataSet('horseColicTraining2.txt')
classifierArray, aggClassEst = adaBoostTrainDS(datArr, labelArr, 10)
plotROC(aggClassEst.T, labelArr)жқғеҖјжӣҙж–°ж–№жі•зҡ„ж”№иҝӣ
еңЁе®һйҷ…и®ӯз»ғиҝҮзЁӢдёӯеҸҜиғҪеӯҳеңЁжӯЈиҙҹж ·жң¬еӨұиЎЎзҡ„й—®йўҳпјҢеҲҶзұ»еҷЁдјҡиҝҮдәҺе…іжіЁеӨ§е®№йҮҸж ·жң¬пјҢеҜјиҮҙеҲҶзұ»еҷЁдёҚиғҪиҫғеҘҪең°е®ҢжҲҗеҢәеҲҶе°Ҹж ·жң¬зҡ„зӣ®зҡ„гҖӮжӯӨж—¶еҸҜд»ҘйҖӮеәҰеўһеӨ§е°Ҹж ·жң¬зҡ„жқғйҮҚдҪҝйҮҚеҝғиҫҫеҲ°е№іиЎЎгҖӮеңЁе®һйҷ…и®ӯз»ғдёӯиҝҳдјҡеҮәзҺ°еӣ°йҡҫж ·жң¬жқғйҮҚиҝҮй«ҳиҖҢеҸ‘з”ҹиҝҮжӢҹеҗҲзҡ„й—®йўҳпјҢеӣ жӯӨжңүеҝ…иҰҒи®ҫзҪ®еӣ°йҡҫж ·жң¬еҲҶзұ»зҡ„жқғеҖјдёҠйҷҗгҖӮ
и®ӯз»ғж–№жі•зҡ„ж”№иҝӣ
AdaBoostз®—жі•з”ұдәҺе…¶еӨҡж¬Ўиҝӯд»Ји®ӯз»ғеҲҶзұ»еҷЁзҡ„еҺҹеӣ пјҢи®ӯз»ғж—¶й—ҙдёҖиҲ¬дјҡжҜ”еҲ«зҡ„еҲҶзұ»еҷЁй•ҝгҖӮеҜ№жӯӨдёҖиҲ¬еҸҜд»ҘйҮҮз”Ёе®һзҺ°AdaBoostзҡ„并иЎҢи®Ўз®—жҲ–иҖ…и®ӯз»ғиҝҮзЁӢдёӯеҠЁжҖҒеү”йҷӨжҺүжқғйҮҚеҒҸе°Ҹзҡ„ж ·жң¬д»ҘеҠ йҖҹи®ӯз»ғиҝҮзЁӢгҖӮ
еӨҡз®—жі•з»“еҗҲзҡ„ж”№иҝӣ
йҷӨдәҶд»ҘдёҠз®—жі•еӨ–пјҢAdaBoostиҝҳеҸҜд»ҘиҖғиҷ‘дёҺе…¶е®ғз®—жі•з»“еҗҲдә§з”ҹж–°зҡ„з®—жі•пјҢеҰӮеңЁи®ӯз»ғиҝҮзЁӢдёӯдҪҝз”ЁSVMз®—жі•еҠ йҖҹжҢ‘йҖүз®ҖеҚ•еҲҶзұ»еҷЁжқҘжӣҝд»ЈеҺҹе§ӢAdaBoostдёӯзҡ„з©·дёҫжі•жҢ‘йҖүз®ҖеҚ•зҡ„еҲҶзұ»еҷЁгҖӮ
pythonзҡ„дә”еӨ§зү№зӮ№пјҡ1.з®ҖеҚ•жҳ“еӯҰпјҢејҖеҸ‘зЁӢеәҸж—¶пјҢдё“жіЁзҡ„жҳҜи§ЈеҶій—®йўҳ,иҖҢдёҚжҳҜжҗһжҳҺзҷҪиҜӯиЁҖжң¬иә«гҖӮ2.йқўеҗ‘еҜ№иұЎпјҢдёҺе…¶д»–дё»иҰҒзҡ„иҜӯиЁҖеҰӮC++е’ҢJavaзӣёжҜ”, Pythonд»ҘдёҖз§ҚйқһеёёејәеӨ§еҸҲз®ҖеҚ•зҡ„ж–№ејҸе®һзҺ°йқўеҗ‘еҜ№иұЎзј–зЁӢгҖӮ3.еҸҜ移жӨҚжҖ§пјҢPythonзЁӢеәҸж— йңҖдҝ®ж”№е°ұеҸҜд»ҘеңЁеҗ„з§Қе№іеҸ°дёҠиҝҗиЎҢгҖӮ4.и§ЈйҮҠжҖ§пјҢPythonиҜӯиЁҖеҶҷзҡ„зЁӢеәҸдёҚйңҖиҰҒзј–иҜ‘жҲҗдәҢиҝӣеҲ¶д»Јз Ғ,еҸҜд»ҘзӣҙжҺҘд»Һжәҗд»Јз ҒиҝҗиЎҢзЁӢеәҸгҖӮ5.ејҖжәҗпјҢPythonжҳҜ FLOSS(иҮӘз”ұ/ејҖж”ҫжәҗз ҒиҪҜ件)д№ӢдёҖгҖӮ
е…ідәҺвҖңPythonжңәеҷЁеӯҰд№ д№ӢAdaBoostз®—жі•зҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ