您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
怎么用Python可视化神器Plotly动态演示全球疫情变化趋势,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
用 Python可视化神器 Plotly
动态演示全球疫情变化趋势
各位同学早上好,我是 Lemonbit 。
近期对疫情数据进行可视化的内容比较多,今天我来用 Python 可视化申请 Plotly 对国外的疫情发展情况进行可视化,以项目实战的形式,在分析和了解国外疫情变化趋势的同时,加深大家对 Plotly 的学习应用。
在开始之前,我们先来看看最终制作的部分效果图,如果你觉得有兴趣,不妨继续往下看。
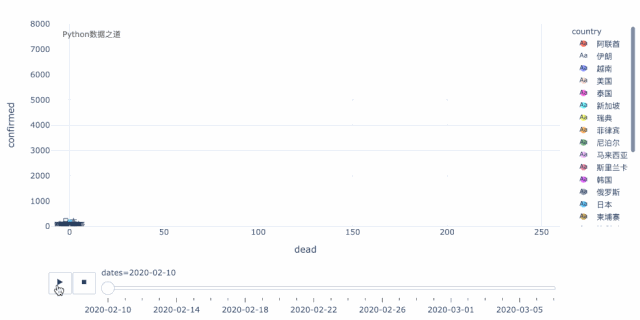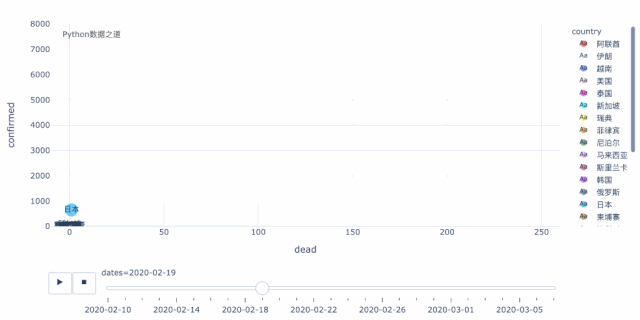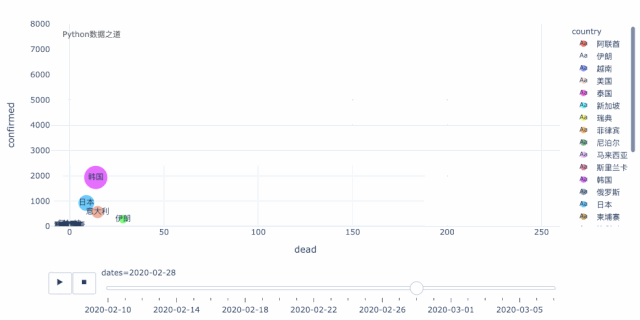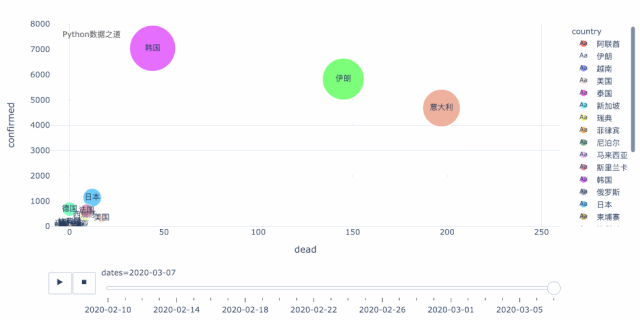
数据来源
国内的疫情,目前已逐步受到控制,各项指标已开始明显好转,但国外的情况,看起来不是太乐观,已有的作业也没有抄好,所以,本次我们主要来可视化分析国外疫情的发展情况。
疫情的数据来源于开源项目 Akshare,由于使用该项目获取数据时,有时不太稳定,可能会遇到连接失败的情况,所以,这里我提供了保存好的数据供大家使用。
准备工作
照例,还是先介绍下我运行的环境
Mac 系统
Anaconda(Python 3.7)
Jupyter Notebook
本次使用到的 Python 库包括 akshare, pandas, plotly 等,导入如下:
import akshare as ak import pandas as pd import plotly from plotly.offline import iplot, init_notebook_mode import plotly.express as px from datetime import datetime init_notebook_mode()
接着,我们读取已获得的数据,已保存的数据是截至3月7日的。
# 从 akshare 获取数据 # df_all_history = ak.epidemic_history() # 从csv文件获取数据 df_all_history = pd.read_csv('epidemic_all_20200307.csv',index_col=0) df_all_history从上面获取的数据,有些数据格式需要加以调整,对于日期,我们这里会组织两列数据,一列是时间格式的日期( ['date']),一列是字符串格式的日期 ( ['dates'])。这样设置的原因,是因为我们后续分别需要用到这两种格式的日期。
df_all = df_all_history # 将字符串格式的日期 另保存为一列 df_all['dates'] = df_all_history['date'] # 将字符串格式的日期转换为 日期格式 df_all['date'] = pd.to_datetime(df_all['date'])
获取国外的疫情数据
上面的数据,是全球的数据,我们可以把其中属于中国的剔除,就可以得到国外的数据了。
# 国外,按国家统计 df_oversea = df_all.query("country!='中国'") df_oversea.fillna(value="", inplace=True) df_oversea先来用 plotly express 看下国外疫情分国家的整体走势。
# 国外,按国家统计 df_oversea = df_all.query("country!='中国'") df_oversea.fillna(value="", inplace=True) df_oversea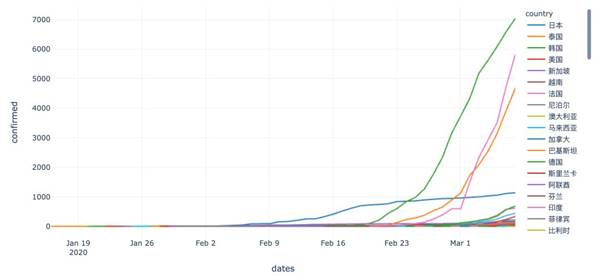
从上图可以看出,国外的疫情发展情况,大部分国家从2月10日期,发展趋势较为明显,因此,后面我们重点分析这段时间之后的情况。
# 现有数据演示从 2020年2月10日开始 df_overseadf_oversea_recent = df_oversea.set_index('date') df_oversea_recentdf_oversea_recent = df_oversea_recent['2020-02-10':] df_oversea_recent由于部分国家的数据不是从2020年2月10日开始记录的,所以要补充数据。我们可以手动新建一个 excel数据表,将补充日期的数值填充为 0 。
我这里主要补充的是伊朗的数据,因为伊朗实在是发展太快了,必须纳入分析的范围内。其他国家,如果有需要补充的,后续可以继续完善。
# 由于部分国家,数据不是从2020年2月10日开始的,所以要补充数据,数值为 0 # 数据在 excel 表格中进行补充,这里进行读取 df_oversea_buchong = pd.read_excel('epidemic_buchong.xlsx') df_oversea_buchong['dates'] = df_oversea_buchong['date'].apply(lambda x:x.strftime('%Y-%m-%d')) df_oversea_buchong.set_index('date', inplace=True) df_oversea_buchong.fillna(value="", inplace=True) print(df_oversea_buchong.info()) df_oversea_buchong将需要补充的数据弄好后,我们可以合并上面这两部分数据,一起进行分析。
# 合并补充数据 df_oversea_recentdf_oversea_recent_new = df_oversea_recent.append(df_oversea_buchong) df_oversea_recent_new.sort_index(inplace=True) df_oversea_recent_new
得到合并的数据后,首先,我们用气泡图来对变化情况进行可视化,这里用的是 plotly express 的散点图。
plotly express 现在已经合并到 plotly 中,个人觉得跟 plotly 原生内容的协同性相对 cufflinks 要好用点。
# 合并补充数据 df_oversea_recentdf_oversea_recent_new = df_oversea_recent.append(df_oversea_buchong) df_oversea_recent_new.sort_index(inplace=True) df_oversea_recent_new
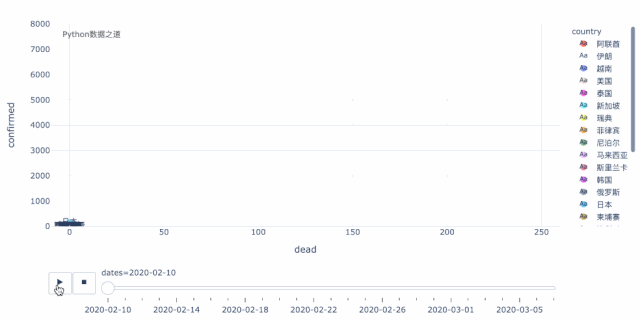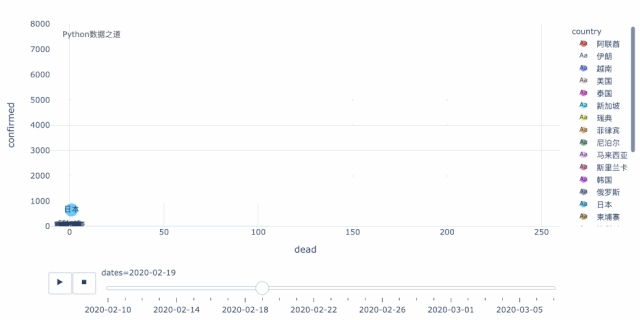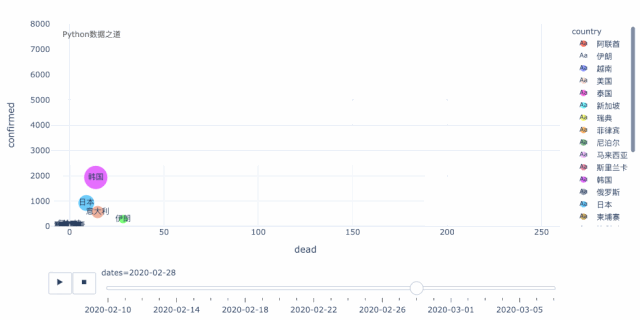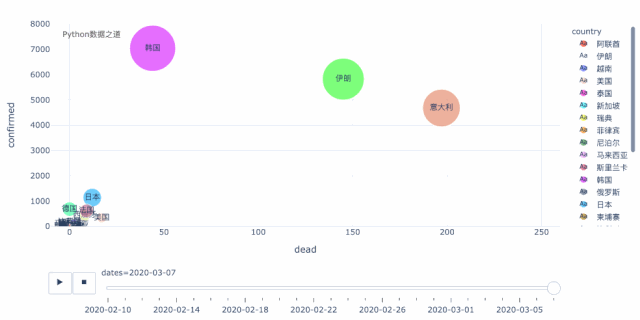
从上面这个动态图可以清晰的看出,当前,在海外的国家中,韩国、伊朗、意大利三个国家最为严重。这三个国家中,就增长趋势而言,伊朗和意大利又比韩国要更明显,目前韩国的增长有所放缓,而伊朗和意大利还处于快速增长的过程中,后续情况不容乐观。
此外,在这个图中,另外还有几个国家值得关注,日本,除去钻石号之外,从数据来看,本土的增长目前还算是在稍微较好的范围内。反倒是,德国、法国、西班牙,个人觉得已成逐步壮大之势,不得不防。
而且,由于整个欧盟国家之间,人员是自由流通的,现在看来,整个欧盟很可能会成为疫情的重灾区,其影响巨大。
上图左下角的这些国家的走势,我们可以拉近来看,走势如下,这样,对于 德国、法国、西班牙就会看的更明显了。
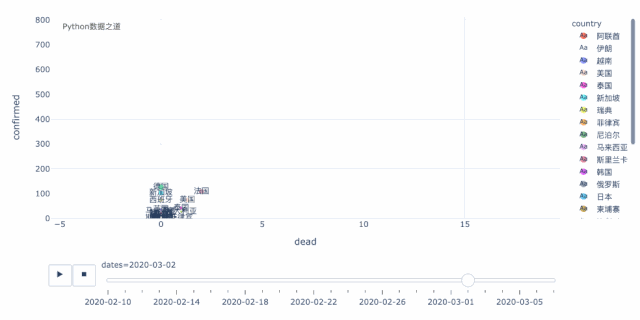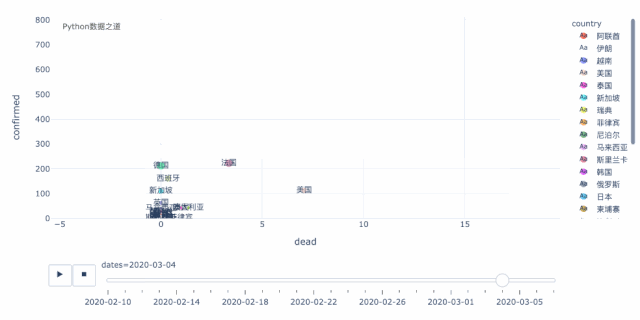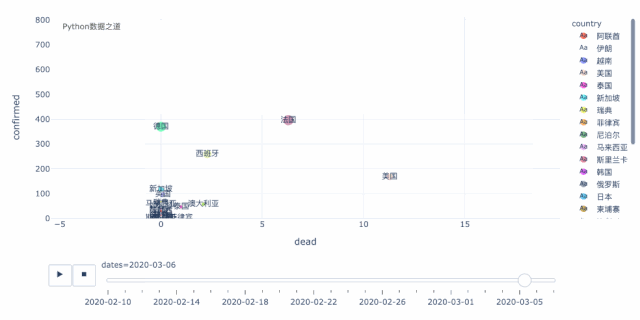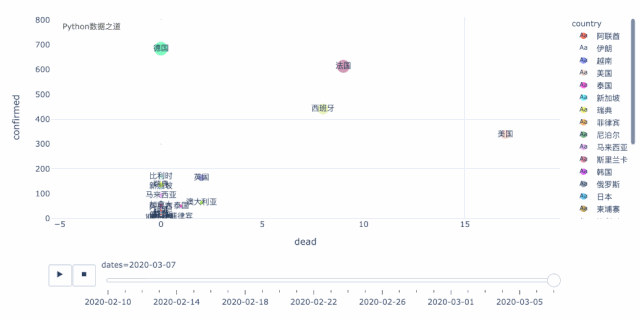
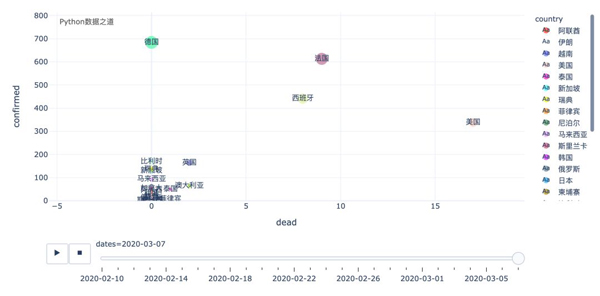
这里,还有一个国家,就是美国,虽然从数据以及增长情况来看,好像美国还好,但恐怕实际情况,要糟糕很多。
上面是以气泡图的方式来演示变化过程,我们也可以以柱状图的形式来演示,效果如下:
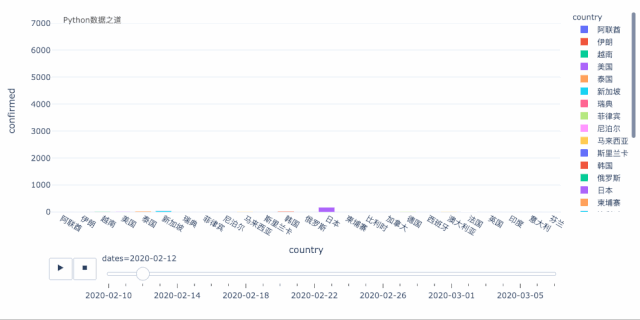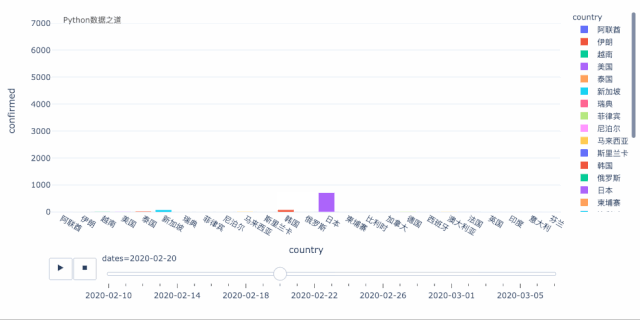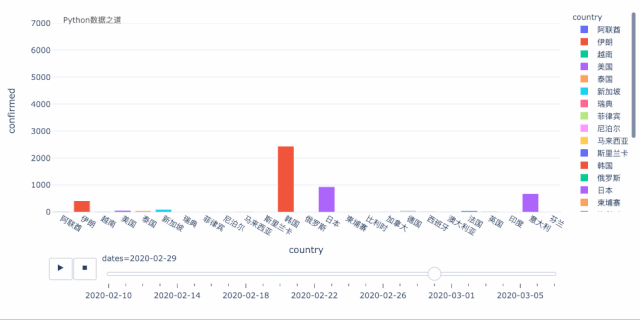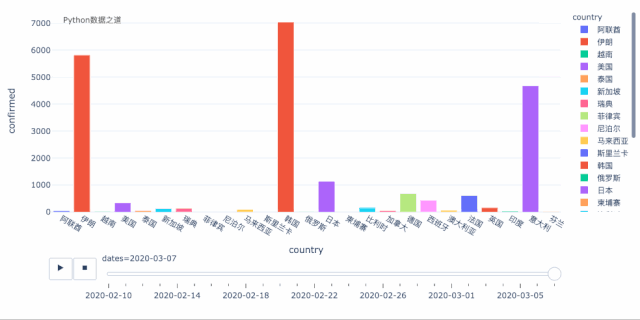
关于上面的效果图,各位可以自行研究下,欢迎交流。
需要说明的是,代码是在 Jupyter Notebook 中运行的, 如果是在 PyCharm 等 IDE 中运行,需要稍微修改下代码。
最后,再次感谢开源项目 Akshare 提供了数据接口。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。