жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
ELKеҲҶжһҗngx_lua_wafиҪҜ件йҳІзҒ«еўҷж—Ҙеҝ—
ngx_lua_wafд»Ӣз»ҚеҸҠйғЁзҪІеҸҜд»ҘеҸӮиҖғ
https://github.com/loveshell/ngx_lua_waf
иҝҷдёӘдёҖдёӘеҹәдәҺlua-nginx-moduleзҡ„webеә”з”ЁйҳІзҒ«еўҷпјҢдҪңиҖ…жҳҜеј дјҡжәҗпјҲID : kindleпјүпјҢеҫ®еҚҡ:@зҘһеҘҮзҡ„йӯ”жі•еёҲгҖӮ
з”ЁйҖ”пјҡ
йҳІжӯўsqlжіЁе…ҘпјҢжң¬ең°еҢ…еҗ«пјҢйғЁеҲҶжәўеҮәпјҢfuzzingжөӢиҜ•пјҢxss,Г—Г—Г—Fзӯүweb***
йҳІжӯўsvn/еӨҮд»Ҫд№Ӣзұ»ж–Ү件泄жјҸ
йҳІжӯўApacheBenchд№Ӣзұ»еҺӢеҠӣжөӢиҜ•е·Ҙе…·зҡ„***
еұҸи”Ҫеёёи§Ғзҡ„жү«жҸҸ***е·Ҙе…·пјҢжү«жҸҸеҷЁ
еұҸи”ҪејӮеёёзҡ„зҪ‘з»ңиҜ·жұӮ
еұҸи”ҪеӣҫзүҮйҷ„件зұ»зӣ®еҪ•phpжү§иЎҢжқғйҷҗ
йҳІжӯўwebshellдёҠдј
жҖ»з»“пјҡ
1пјҢNginx_lua_wafжҖ»дҪ“жқҘиҜҙеҠҹиғҪејәеӨ§пјҢзӣёжҜ”е…¶д»–иҪҜ件йҳІзҒ«еўҷModsecurityиҝҳзЁҚеҫ®з®ҖеҚ•зӮ№гҖӮ
2пјҢNgx_lua_wafзҡ„bugдё»иҰҒе°ұжҳҜйҳІзҒ«еўҷзӯ–з•ҘеҶҷзҡ„дёҚдёҘи°ЁеҜјиҮҙзҡ„пјҢдјҡйҖ жҲҗдёӨз§Қз»“жһңпјҡдёҖжҳҜйғЁеҲҶ***йҖҡиҝҮдјӘиЈ…з»•иҝҮйҳІзҒ«еўҷпјӣдәҢжҳҜйҳІзҒ«еўҷзӯ–з•Ҙй…ҚзҪ®дёҚеҪ“дјҡйҖ жҲҗиҜҜжқҖгҖӮ
3пјҢеҸҰеӨ–ж №жҚ®з«ҷзӮ№зҡ„зұ»еһӢйңҖиҰҒй…ҚзҪ®дёҚеҗҢзҡ„зӯ–з•ҘпјҢй»ҳи®Өй…ҚзҪ®еҗҺе…ЁеұҖз”ҹж•ҲгҖӮжҜ”еҰӮи®әеқӣзӯүжҜ”иҫғзү№ж®Ҡе…Ғи®ёеҫҲеӨҡhtmlжҸ’е…ҘпјҢиҝҷж ·зҡ„зӯ–з•ҘйңҖиҰҒжӣҙе®ҪжқҫгҖӮ
4пјҢжңҖеҗҺз”ҹжҲҗзҡ„hackи®°еҪ•ж—Ҙеҝ—еҸҜд»ҘйҖҡиҝҮELKеҲҶжһҗпјҢELKиҝҷиҫ№йңҖиҰҒж №жҚ®ж—Ҙеҝ—ж јејҸеҲ¶дҪңзү№ж®ҠжЁЎзүҲпјҢжӯӨжЁЎзүҲиғҪе…је®№еӨ§йғЁеҲҶж—Ҙеҝ—зұ»еһӢпјҢиҝҳжңүе°‘йғЁеҲҶе®Ңе…ЁжІЎжңү规еҫӢзҡ„ж—Ҙеҝ—еҲҶжһҗдёҚдәҶгҖӮ
5пјҢжңҖеҗҺELKиғҪеұ•зӨәж—Ҙеҝ—еҲҶжһҗз»“жһңеҲҶзұ»пјҢдҪҶжҳҜиҝҳдёҚиғҪеҢәеҲҶеҗ„з§Қruletagзұ»еһӢ***еұһдәҺе“ӘдёҖз§ҚзӣҙзҷҪзҡ„иЎЁзӨәеҮәжқҘгҖӮ
6пјҢжңҖеҗҺе»әи®®ngx_lua_wafеҰӮжһңзңҹзҡ„иҰҒз”ЁеҸҜд»ҘиҖғиҷ‘еңЁйғЁеҲҶжәҗз«ҷз«ҷзӮ№е°‘йҮҸиҜ•з”ЁпјҢеүҚз«Ҝз«ҷзӮ№дёҚе»әи®®дҪҝз”ЁпјҢзӯүеҜ№иҜҘиҪҜ件зҗҶи§Јж·ұе…ҘеҗҺжүҚеҸҜзәҝдёҠдҪҝз”ЁгҖӮ
7пјҢиЎҘе……пјҡзӣ®еүҚеҜ№ngx_lua_wafжӢ’з»қзү№е®ҡзҡ„user agentгҖҒжӢ’з»қзү№е®ҡеҗҺзјҖж–Ү件и®ҝй—®гҖҒйҳІжӯўsqlжіЁе…ҘдёүеӨ§зұ»жҜ”иҫғзҶҹжӮүгҖӮ
еҗҺз»ӯи®ЎеҲ’пјҡ
жңүдәәпјҲжӯӨдәәдәәз§°иөөзҸӯй•ҝйЎ№зӣ®ең°еқҖ https://github.com/unixhot/wafпјү еҜ№ngx_lua_wafиҝӣиЎҢдәҶдәҢж¬ЎйҮҚжһ„пјҢдё»иҰҒеҠҹиғҪжңүпјҡй»‘зҷҪеҗҚеҚ•гҖҒеҸӘи®°еҪ•***ж—Ҙеҝ—дёҚйҷҗеҲ¶и®ҝй—®пјҲж—Ҙеҝ—ж јејҸеҸҜиғҪжӣҙеҸӢеҘҪзӮ№еҫ…и§ӮеҜҹпјүгҖҒеҸҰеӨ–дҪҝз”ЁopenrestyйғЁзҪІзҡ„пјҢеҗҺжңҹи®ЎеҲ’дҪҝз”ЁдәҢж¬ЎйҮҚжһ„зҡ„wafеҶҚж¬ЎжөӢиҜ•дёӢгҖӮ
и®ЎеҲ’еӨ§жҰӮе®һж–ҪжӯҘйӘӨпјҡ
1пјҢдёҚиҰҒдёҖж¬ЎжҖ§йғЁзҪІдёҠзәҝпјҢе…ҲйғЁзҪІеҗҺпјҢеҸӘи®°еҪ•ж—Ҙеҝ—пјҢ然еҗҺи§ӮеҜҹе’Ңи°ғж•ҙ规еҲҷпјҢдҝқиҜҒжӯЈеёёзҡ„иҜ·жұӮдёҚдјҡиў«иҜҜйҳІгҖӮ
2пјҢдҪҝз”ЁSaltStackз®ЎзҗҶ规еҲҷеә“зҡ„жӣҙж–°гҖӮ
3пјҢдҪҝз”ЁELKStackиҝӣиЎҢж—Ҙеҝ—收йӣҶе’ҢеҲҶжһҗпјҢйқһеёёж–№дҫҝзҡ„еҸҜд»ҘеңЁKibanaдёҠеҒҡеҮәдёҖдёӘжјӮдә®зҡ„***з»ҹи®Ўзҡ„йҘјеӣҫгҖӮпјҲзӣ®еүҚд№ҹиғҪе®һзҺ°пјү
д»ҘдёӢжҳҜе…·дҪ“ж“ҚдҪңиҝҮзЁӢдёӯйңҖиҰҒжіЁж„Ҹзҡ„й—®йўҳзӮ№
дёҖпјҢELKж–°еўһй’ҲеҜ№nginx_lua_wafж—Ҙеҝ—еҲҮеҲҶзӯ–з•Ҙ
1пјҢж—Ҙеҝ—ж јејҸ
line = realIp.." ["..time.."] \""..method.." "..servername..url.."\" \""..data.."\" \""..ua.."\" \""..ruletag.."\"\n"
2пјҢж—Ҙеҝ—еҶ…е®№
192.168.200.106 [2016-07-26 16:56:17] "UA i.maicar.com/AuthenService/Frame/login.aspx?ra=0.5440098259132355" "-" "Baidu-YunGuanCe-ScanBot(ce.baidu.com)" "(HTTrack|harvest|audit|dirbuster|pangolin|nmap|sqln|-scan|hydra|Parser|libwww|BBBike|sqlmap|w3af|owasp|Nikto|fimap|havij|PycURL|zmeu|BabyKrokodil|netsparker|httperf|bench| SF/)"
3пјҢlogstash еҲҮеҲҶзӯ–з•Ҙ
жңҖе…ій”®зҡ„иҝҳжҳҜgrokжӯЈеҲҷиЎЁиҫҫејҸзҡ„д№ҰеҶҷпјҢиҝҷйҮҢз»ҷдёӨдёӘе»әи®®пјҡ
1пјүдёҖжҳҜеҸӮиҖғзі»з»ҹиҮӘеёҰзҡ„ /opt/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/patterns/
иҜҘзӣ®еҪ•дёӢжңүзі»з»ҹиҮӘеёҰзҡ„еҫҲеӨҡж—Ҙеҝ—ж јејҸзҡ„grokжӯЈеҲҷеҲҮеҲҶиҜӯжі•пјҢеҰӮпјҡ
aws bro firewalls haproxy junos mcollective mongodb postgresql redis bacula exim grok-patterns java linux-syslog mcollective-patterns nagios rails ruby
й»ҳи®ӨжІЎжңү规еҫӢзҡ„еҸӮиҖғgrok-patterns
2пјүдәҢжҳҜзҪ‘дёҠжңүдёӨдёӘgrokиҜӯжі•йӘҢиҜҒзҪ‘з«ҷпјҲйғҪеҫ—Г—Г—Г—пјү
http://grokdebug.herokuapp.com/
http://grokconstructor.appspot.com/do/match#result
д№ҹеҸҜд»ҘжүӢеҠЁйӘҢиҜҒпјҢдёҫдҫӢеҰӮдёӢ
[root@elk logstash]# /opt/logstash/bin/logstash -f /etc/logstash/test1.conf
Settings: Default pipeline workers: 4
Pipeline main started
192.168.200.106 [2016-07-26 16:56:17] "UA i.maicar.com/AuthenService/Frame/login.aspx?ra=0.5440098259132355" "-" "Baidu-YunGuanCe-ScanBot(ce.baidu.com)" "(HTTrack|harvest|audit|dirbuster|pangolin|nmap|sqln|-scan|hydra|Parser|libwww|BBBike|sqlmap|w3af|owasp|Nikto|fimap|havij|PycURL|zmeu|BabyKrokodil|netsparker|httperf|bench| SF/)"
{
"message" => "192.168.200.106 [2016-07-26 16:56:17] \"UA i.maicar.com/AuthenService/Frame/login.aspx?ra=0.5440098259132355\" \"-\" \"Baidu-YunGuanCe-ScanBot(ce.baidu.com)\" \"(HTTrack|harvest|audit|dirbuster|pangolin|nmap|sqln|-scan|hydra|Parser|libwww|BBBike|sqlmap|w3af|owasp|Nikto|fimap|havij|PycURL|zmeu|BabyKrokodil|netsparker|httperf|bench| SF/)\"",
"@version" => "1",
"@timestamp" => "2016-07-28T10:05:43.763Z",
"host" => "0.0.0.0",
"realip" => "192.168.200.106",
"time" => "2016-07-26 16:56:17",
"method" => "UA",
"servername" => "i.maicar.com",
"url" => "/AuthenService/Frame/login.aspx?ra=0.5440098259132355",
"data" => "-",
"useragent" => "Baidu-YunGuanCe-ScanBot(ce.baidu.com)",
"ruletag" => "(HTTrack|harvest|audit|dirbuster|pangolin|nmap|sqln|-scan|hydra|Parser|libwww|BBBike|sqlmap|w3af|owasp|Nikto|fimap|havij|PycURL|zmeu|BabyKrokodil|netsparker|httperf|bench| SF/)"
}е…¶дёӯtest1.confеҶ…е®№еҰӮдёӢпјҡ
input{stdin{}}
filter {
grok {
match => {
"message" =>"%{IPV4:realip}\s+\[%{TIMESTAMP_ISO8601:time}\]\s+\"%{WORD:method}\s+%{HOSTNAME:servername}(?<url>[^\"]+)\"\s+\"(?<data>[^\"]+)\"\s+\"(?<useragent>[^\"]+)\"\s+\"(?<ruletag>[^\"]+)\""
}
}
}
output{stdout{codec=>rubydebug}}жңҖеҗҺзәҝдёҠеҲҮеҲҶзӯ–з•ҘеҰӮдёӢпјҡ
filter {
if [type] == "waf194" {
grok {
match => [
"message" , "%{IPV4:realip}\s+\[%{TIMESTAMP_ISO8601:time}\]\s+\"%{WORD:method}\s+%{HOSTNAME:servername}(?<url>[^\"]+)\"\s+\"(?<data>[^\"]+)\"\s+\"(?<useragent>[^\"]+)\"\s+\"(?<ruletag>[^\"]+)\""
]
remove_field => [ "message" ]
}
}
}дәҢпјҢELKж–°еўһй’ҲеҜ№nginx_lua_wafж—Ҙеҝ—зҡ„зҙўеј•жЁЎзүҲ
е…¶дёӯжңҖе…ій”®й—®йўҳжҳҜеӨҡдёӘзҙўеј•жЁЎзүҲе…ұеӯҳзҡ„й—®йўҳпјҢд»ҘеүҚжҖ»жҳҜеҗҺеҠ зҙўеј•жЁЎзүҲдјҡиҰҶзӣ–еҺҹжқҘзҡ„пјҢеҸӮиҖғhttp://mojijs.com/2015/08/204352/index.html и®ҫзҪ®tempalte_nameжқҘеҢәеҲҶдёҚеҗҢзҡ„зҙўеј•жЁЎзүҲгҖӮ
иҫ“еҮәжЁЎзүҲй…ҚзҪ®еҰӮдёӢпјҡ
output {
elasticsearch {
hosts => ["192.168.88.187:9200","192.168.88.188:9200","192.168.88.189:9200"]
sniffing => false
manage_template => true
template => "/opt/logstash/templates/logstashwaf.json"
template_overwrite => true
template_name => "logstashwaf.json"
index => "logstash-%{type}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
flush_size => 10000
}
}е…·дҪ“logstashwaf.jsonй…ҚзҪ®еҰӮдёӢпјҢиҝҷдёӘжҳҜзӣҙжҺҘеҸӮиҖғе®ҳж–№зҡ„elasticsearch-logstash.jsonпјҢе°ұдҝ®ж”№дәҶtemplateеҗҚеӯ—пјҢй…ҚзҪ®йҮҢйқўеҸӘиҰҒжҳҜstringзұ»еһӢзҡ„йғҪеҒҡдәҶдёҚеҲҶиҜҚпјҢеӣ дёәеҒҡи§Ҷеӣҫж—¶дёҚеҲҶиҜҚдёҖжқҘеҸҜд»ҘиҠӮзңҒеҶ…еӯҳпјҢдәҢжқҘеҗ‘urlпјҢagentпјҢruletagзӯүзӯүй•ҝstingsеҸӘжңүдёҚеҲҶиҜҚжүҚиғҪзІҫзЎ®еҢ№й…ҚпјҢйӮЈз§ҚеҲҶиҜҚзҡ„жЁЎзіҠеҢ№й…Қз”ЁдёҚдёҠгҖӮеҸҰеӨ–еҰӮжһңеҸӘиҰҒжҹҗдәӣstringеӯ—ж®өж·»еҠ дёҚеҲҶиҜҚпјҢд№ҹеҸҜд»Ҙдҝ®ж”№"match" : "*",дёәе…·дҪ“зҡ„еӯ—ж®өпјҢеҰӮпјҡ
"match_pattern": "regex", #жӯӨиЎҢдёәж–°еўһеҠ "match" : "(realip)|(mothod)(servername)|(url)|(data)|(useragent)|(ruletag)",
зәҝдёҠжҖ»дҪ“й…ҚзҪ®еҰӮдёӢпјҡ
{
"template" : "logstash-waf194*",
"settings" : {
"index.refresh_interval" : "5s"
},
"mappings" : {
"_default_" : {
"_all" : {"enabled" : true, "omit_norms" : true},
"dynamic_templates" : [ {
"message_field" : {
"match" : "message",
"match_mapping_type" : "string",
"mapping" : {
"type" : "string", "index" : "analyzed", "omit_norms" : true
}
}
}, {
"string_fields" : {
"match" : "*",
"match_mapping_type" : "string",
"mapping" : {
"type" : "string", "index" : "analyzed", "omit_norms" : true,
"fields" : {
"raw" : {"type": "string", "index" : "not_analyzed", "ignore_above" : 256}
}
}
}
} ],
"properties" : {
"@version": { "type": "string", "index": "not_analyzed" },
"geoip" : {
"type" : "object",
"dynamic": true,
"properties" : {
"location" : { "type" : "geo_point" }
}
}
}
}
}
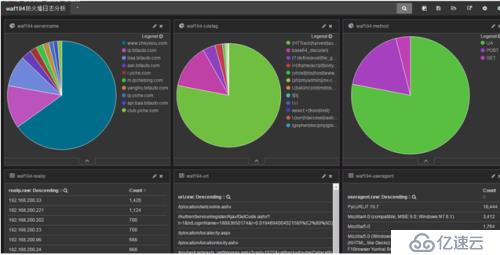
}дёүпјҢNgx_lua_wafз”ҹжҲҗзҡ„hackж—Ҙеҝ—ELKдёҠеұ•зӨәеҰӮдёӢ
е…¶дёӯеҲ¶дҪңи§ҶеӣҫеҲ¶дҪңжЁЎзүҲзӯүйғҪзңҒз•Ҙ
еҲҶжһҗе°ҸйғЁеҲҶж—Ҙеҝ—з»“жһңеҰӮдёӢпјҡ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ