您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
参考http://hadoop.apache.org/docs/r2.7.6/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
eclipse 新建maven项目
pom 文件内容
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hadoop_mapreduce</groupId>
<artifactId>WordCount</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>WordCount</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.0</version>
</dependency>
<!-- <dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-alpha-HBase-2.0</version>
</dependency>
-->
<!-- https://mvnrepository.com/artifact/org.apache.phoenix/phoenix-core -->
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>C:\Program Files\Java\jdk1.8.0_151\lib\tools.jar</systemPath>
</dependency>
</dependencies>
</project>
注: 只需要hadoop-client包,如果引入hbase相关的包,很可能出现包冲突,运行会出现异常。
WordCount类代码
package hadoop_mapreduce.WordCount;
import java.io.IOException;
import java.io.InterruptedIOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount{
public static class TokenizerMapper
extends Mapper<Object,Text,Text,IntWritable>{
private final static IntWritable one =new IntWritable(1);
private Text word = new Text();
public void map(Object key,Text value,Context context) throws IOException,InterruptedIOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer (value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException,InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
//public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException
{
/*
* IntWritable intwritable = new IntWritable(1);
Text text = new Text("abc");
System.out.println(text.toString());
System.out.println(text.getLength());
System.out.println(intwritable.get());
System.out.println(intwritable);
StringTokenizer itr = new StringTokenizer ("www baidu com");
while(itr.hasMoreTokens()) {
System.out.println(itr.nextToken()); hdfs://192.168.50.107:8020/input hdfs://192.168.50.107:8020/output
*/
//String path = WordCount.class.getResource("/").toString();
//System.out.println("path = " + path);
System.out.println("Connection end");
//System.setProperty("hadoop.home.dir", "file://192.168.50.107/home/hadoop-user/hadoop-2.8.0");
//String StringInput = "hdfs://192.168.50.107:8020/input/a.txt";
//String StringOutput = "hdfs://192.168.50.107:8020/output/b.txt";
Configuration conf = new Configuration();
//conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
//conf.addResource("classpath:core-site.xml");
//conf.addResource("classpath:hdfs-site.xml");
//conf.addResource("classpath:mapred-site.xml");
//conf.set("HADOOP_HOME", "/home/hadoop-user/hadoop-2.8.0");
Job job = Job.getInstance(conf,"word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//FileInputFormat.addInputPath(job, new Path(StringInput));
//FileOutputFormat.setOutputPath(job, new Path(StringOutput));
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
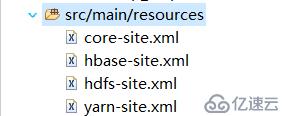
连接hadoop的配置文件位置如图
eclipse执行运行会报错: HADOOP_HOME and hadoop.home.dir are unset.
编译打包,放入linux系统
mvn clean
mvn compile
mvn pacakge
我将打包生成的WordCount-0.0.1-SNAPSHOT.jar放到了/home/hadoop-user/work目录
在linux 运行 hadoop jar WordCount-0.0.1-SNAPSHOT.jar hadoop_mapreduce.WordCount.WordCount hdfs://192.168.50.107:8020/input hdfs://192.168.50.107:8020/output
注: 我这里如果不带类路径就会报错,找不到WordCount类。把要分析的文件放入hdfs的input目录中,Output目录不用自己创建。最后生成的分析结果会存在于output目录中
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。