您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
1.hadoop:
作者:Doug Cutting
受Google三篇论文的启发
2.版本:
Apache: 官方版本(1.1.2),学习使用
Cloudera:在apache版本的基础上添加功能,实现商业用途
Yahoo:现在已经集中在apache的版本上
3.hadoop的核心项目
HDFS:(Hadoop Distributed File System) 分布式文件系统
MapReduce:并行计算框架
4.HDFS的架构(主从结构中,主节点负责管理。从节点负责操作)
主从结构(只有一个主节点namenode,可以有很多个从节点datanodes)
namenode负责:
接收用户的操作请求
维护文件系统的目录结构
管理文件与block之间的关系,block与datanode之间的关系
datanode负责:
存储文件
文件被分成block存储在磁盘上
为保证数据安全,文件会有多个副本
5.MapReduce的架构
主从结构(只有一个主节点JobTracker,可以用很多个从节点TaskTrackers)
JobTracker负责:
接收客户提交的计算任务
把计算任务分给TaskTracker执行
监控TaskTracker的执行情况
TaskTrackers负责:
执行JobTracker分配的计算任务
6.Hadoop的特点:
扩容能力(Scalable):能可靠地存储和处理千兆字节(PB)数据;
成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据;
高效率(Efficient):通过分发数据,hadoop可以在数据的所在节点上并行处理;
可性靠(Reliable):hadoop能自动地维护数据的多份副本,并且在任务失败后能自动重新部署计算任务
7.Hadoop集群的物理分布
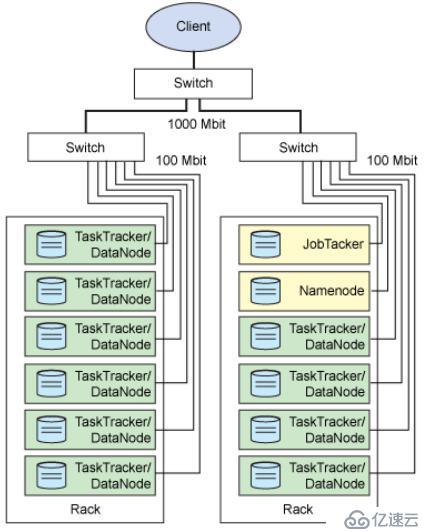
说明:
a.下方的Rack分别表示两个机柜,分别存放多个服务器,左右两机柜都连接有自己的交换机,左右两个交换机又和总的交换机连接,所以,机柜上的各个服务器之间可以互相访问;
b.机柜上两个主节点分别都独占一台服务器,而从节点组合在一起存放在一台服务器上
8.单节点物理结构
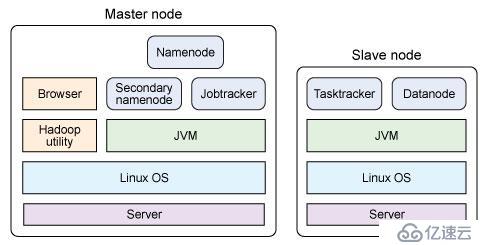
说明:左右图分别表示主节点和从节点,图中主从节点都使用linux系统的服务器,并且都运行在java虚拟机上,因为hadoop是基于java开发的
9.Hadoop部署方式
本地部署(不常用)
伪分布模式(学习使用)
集群模式(公司使用)
10.安装前准备软件
VitualVox
centos
jdk-6u24-linux-xxx.bin
hadoop-1.1.2.tar.gz
11.伪分布模式安装步骤:(6步)
关闭防火墙
修改ip
修改hostname
设置ssh自动登录
安装jdk
安装hadoop
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。