жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶеҰӮдҪ•дҪҝз”ЁmatlabйҒ—дј з®—жі•жұӮи§ЈиҪҰй—ҙи°ғеәҰй—®йўҳпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
иҪҰй—ҙи°ғеәҰжҳҜжҢҮж №жҚ®дә§е“ҒеҲ¶йҖ зҡ„еҗҲзҗҶйңҖжұӮеҲҶй…ҚеҠ е·ҘиҪҰй—ҙйЎәеәҸпјҢд»ҺиҖҢиҫҫеҲ°еҗҲзҗҶеҲ©з”Ёдә§е“ҒеҲ¶йҖ иө„жәҗгҖҒжҸҗй«ҳдјҒдёҡз»ҸжөҺж•ҲзӣҠзҡ„зӣ®зҡ„гҖӮиҪҰй—ҙи°ғеәҰй—®йўҳд»Һж•°еӯҰдёҠеҸҜд»ҘжҸҸиҝ°дёәжңүnдёӘеҫ…еҠ е·Ҙзҡ„йӣ¶д»¶иҰҒеңЁmеҸ°жңәеҷЁдёҠеҠ е·ҘгҖӮй—®йўҳйңҖиҰҒж»Ўи¶ізҡ„жқЎд»¶еҢ…жӢ¬жҜҸдёӘйӣ¶д»¶зҡ„еҗ„йҒ“е·ҘеәҸдҪҝз”ЁжҜҸеҸ°жңәеҷЁдёҚеӨҡдәҺ1ж¬ЎпјҢжҜҸдёӘйӣ¶д»¶йғҪжҢүз…§дёҖе®ҡзҡ„йЎәеәҸиҝӣиЎҢеҠ е·ҘгҖӮ
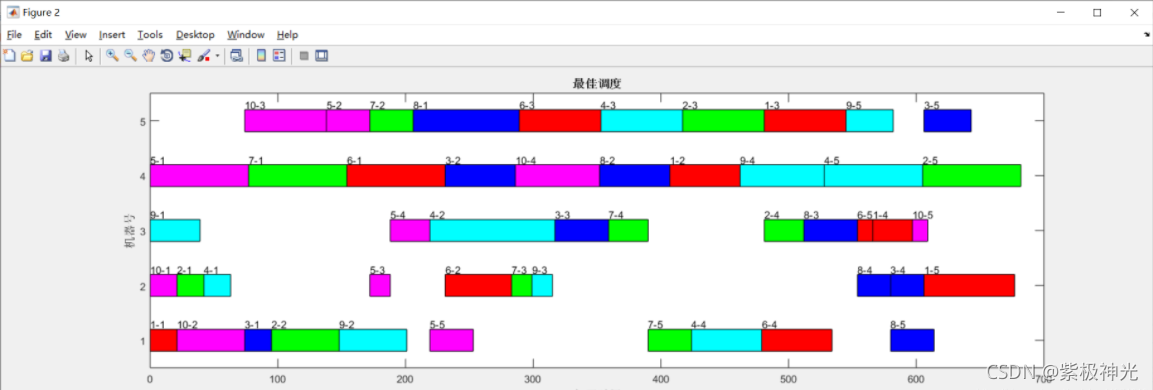
дј з»ҹдҪңдёҡиҪҰй—ҙеёҰи°ғеәҰе®һдҫӢ
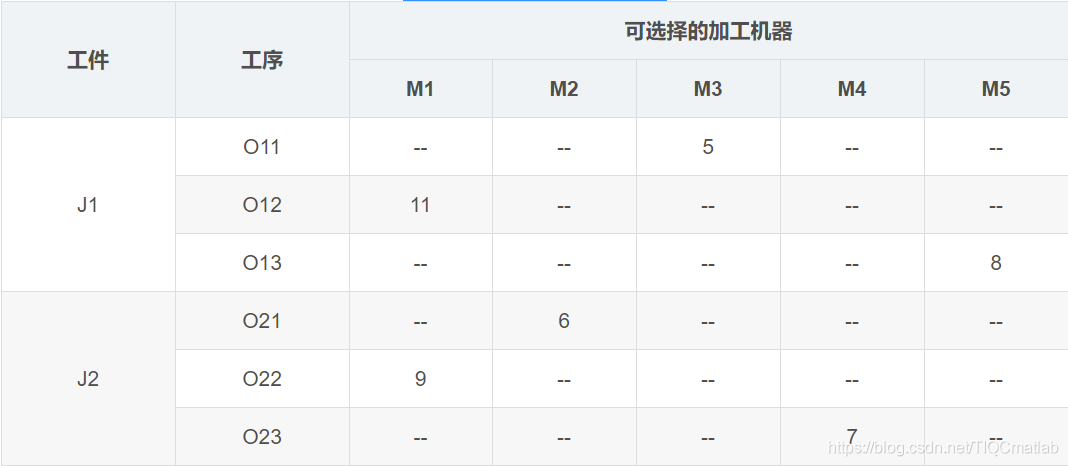
жңүиӢҘе№Іе·Ҙ件пјҢжҜҸдёӘе·Ҙ件жңүиӢҘе№Іе·ҘеәҸпјҢжңүеӨҡдёӘеҠ е·ҘжңәеҷЁпјҢдҪҶжҳҜжҜҸйҒ“е·ҘеәҸеҸӘиғҪеңЁдёҖеҸ°жңәеҷЁдёҠеҠ е·ҘгҖӮеҜ№еә”еҲ°дёҠйқўиЎЁж јдёӯзҡ„е®һдҫӢе°ұжҳҜпјҢдёӨдёӘе·Ҙ件пјҢе·Ҙ件J1жңүдёүйҒ“е·ҘеәҸпјҢе·ҘеәҸQ11еҸӘиғҪеңЁM3дёҠеҠ е·ҘпјҢеҠ е·Ҙж—¶й—ҙжҳҜ5е°Ҹж—¶гҖӮ
зәҰжқҹжҳҜеҜ№дәҺдёҖдёӘе·Ҙ件жқҘиҜҙпјҢе·ҘеәҸзҡ„зӣёеҜ№йЎәеәҸдёҚиғҪеҸҳгҖӮO11->O12->O13гҖӮжҜҸж—¶еҲ»пјҢжҜҸдёӘе·Ҙ件еҸӘиғҪеңЁдёҖеҸ°жңәеҷЁдёҠеҠ е·ҘпјӣжҜҸдёӘжңәеҷЁдёҠеҸӘиғҪжңүдёҖдёӘе·Ҙ件гҖӮ
и°ғеәҰзҡ„д»»еҠЎеҲҷжҳҜе®үжҺ’еҮәе·ҘеәҸзҡ„еҠ е·ҘйЎәеәҸпјҢеҠ е·ҘйЎәеәҸзЎ®е®ҡдәҶпјҢеӣ дёәжҜҸйҒ“е·ҘеәҸеҸӘжңүдёҖеҸ°жңәеҷЁеҸҜз”ЁпјҢеҠ е·Ҙзҡ„жңәеҷЁд№ҹе°ұзЎ®е®ҡдәҶгҖӮ
и°ғеәҰзҡ„зӣ®зҡ„жҳҜжҖ»зҡ„е®Ңе·Ҙж—¶й—ҙжңҖзҹӯпјҲд№ҹеҸҜд»ҘжҳҜе…¶д»–зӣ®ж ҮпјүгҖӮдёҫдёӘдҫӢеӯҗпјҢжҜ”еҰӮзЎ®е®ҡдәҶO21->O22->O11->O23->O12->O13зҡ„еҠ е·ҘйЎәеәҸд№ӢеҗҺпјҢжҲ‘们е°ұеҸҜд»Ҙж №жҚ®еҠ е·ҘжңәеҷЁзҡ„зәҰжқҹпјҢи®Ўз®—еҮәжҖ»зҡ„еҠ е·Ҙж—¶й—ҙгҖӮ
M2еҠ е·ҘO21ж¶ҲиҖ—6е°Ҹж—¶пјҢе·Ҙ件J2еҪ“еүҚеҠ е·Ҙж—¶й—ҙ6е°Ҹж—¶гҖӮ
M1еҠ е·ҘO22ж¶ҲиҖ—9е°Ҹж—¶пјҢе·Ҙ件J2еҪ“еүҚеҠ е·Ҙж—¶й—ҙ6+9=15е°Ҹж—¶гҖӮ
M3еҠ е·ҘO11ж¶ҲиҖ—5е°Ҹж—¶пјҢе·Ҙ件J1еҪ“еүҚеҠ е·Ҙж—¶й—ҙ5е°Ҹж—¶гҖӮ
M4еҠ е·ҘO23ж¶ҲиҖ—7е°Ҹж—¶пјҢе·Ҙ件J2еҠ е·Ҙж—¶й—ҙ15+7=22е°Ҹж—¶гҖӮ
M1еҠ е·ҘO12ж¶ҲиҖ—11е°Ҹж—¶пјҢдҪҶжҳҜиҰҒзӯүM1еҠ е·Ҙе®ҢO22д№ӢеҗҺжүҚејҖе§ӢеҠ е·ҘO12пјҢжүҖд»Ҙе·Ҙ件J1зҡ„еҪ“еүҚеҠ е·Ҙж—¶й—ҙдёәmax(5,9)+11=20е°Ҹж—¶гҖӮ
M5еҠ е·ҘO13ж¶ҲиҖ—8е°Ҹж—¶пјҢе·Ҙ件J2еҠ е·Ҙж—¶й—ҙ20+8=28е°Ҹж—¶гҖӮ
жҖ»зҡ„е®Ңе·Ҙж—¶й—ҙе°ұжҳҜmax(22,28)=28е°Ҹж—¶гҖӮ
2 жҹ”жҖ§дҪңдёҡиҪҰй—ҙи°ғеәҰ
жҹ”жҖ§дҪңдёҡиҪҰй—ҙеёҰи°ғеәҰе®һдҫӢпјҲеҸӮиҖғиҮӘй«ҳдә®иҖҒеёҲи®әж–Ү
гҖҠж”№иҝӣйҒ—дј з®—жі•жұӮи§Јжҹ”жҖ§дҪңдёҡиҪҰй—ҙи°ғеәҰй—®йўҳгҖӢ——жңәжў°е·ҘзЁӢеӯҰжҠҘпјү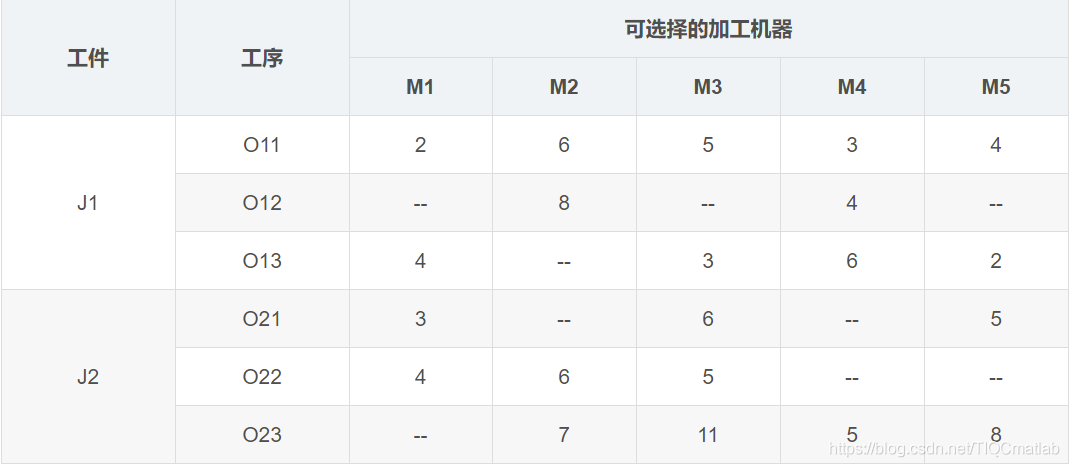
зӣёжҜ”дәҺдј з»ҹдҪңдёҡиҪҰй—ҙи°ғеәҰпјҢжҹ”жҖ§дҪңдёҡиҪҰй—ҙи°ғеәҰж”ҫе®ҪдәҶеҜ№еҠ е·ҘжңәеҷЁзҡ„зәҰжқҹпјҢжӣҙз¬ҰеҗҲзҺ°е®һз”ҹдә§жғ…еҶөпјҢжҜҸдёӘе·ҘеәҸеҸҜйҖүеҠ е·ҘжңәеҷЁеҸҳжҲҗдәҶеӨҡдёӘпјҢеҸҜд»Ҙз”ұеӨҡдёӘеҠ е·ҘжңәеҷЁдёӯзҡ„дёҖдёӘеҠ е·ҘгҖӮжҜ”еҰӮдёҠиЎЁдёӯзҡ„е®һдҫӢпјҢJ1зҡ„O12е·ҘеәҸеҸҜд»ҘйҖүжӢ©M2е’ҢM4еҠ е·ҘпјҢеҠ е·Ҙж—¶й—ҙеҲҶеҲ«жҳҜ8е°Ҹж—¶е’Ң4е°Ҹж—¶пјҢдҪҶжҳҜ并дёҚдёҖе®ҡйҖүжӢ©M4еҠ е·ҘпјҢжңҖеҗҺеҫ—еҮәжқҘзҡ„жҖ»зҡ„е®Ңе·Ҙж—¶й—ҙе°ұжӣҙзҹӯпјҢжүҖд»ҘпјҢйңҖиҰҒи°ғеәҰз®—жі•жұӮи§ЈдјҳеҢ–гҖӮ
зӣёжҜ”дәҺдј з»ҹдҪңдёҡиҪҰй—ҙпјҢжҹ”жҖ§иҪҰй—ҙдҪңдёҡи°ғеәҰзҡ„и°ғеәҰд»»еҠЎдёҚд»…иҰҒзЎ®е®ҡе·ҘеәҸзҡ„еҠ е·ҘйЎәеәҸпјҢиҖҢдё”йңҖиҰҒзЎ®е®ҡжҜҸйҒ“е·ҘеәҸзҡ„жңәеҷЁеҲҶй…ҚгҖӮжҜ”еҰӮпјҢзЎ®е®ҡдәҶO21->O22->O11->O23->O12->O13зҡ„еҠ е·ҘйЎәеәҸпјҢжҲ‘们并дёҚиғҪзӣёеә”е·ҘеәҸзҡ„еҠ е·ҘжңәеҷЁпјҢжүҖд»Ҙиҝҳеә”иҜҘзЎ®е®ҡеҜ№еә”зҡ„[M1гҖҒM3гҖҒM5]->[M1гҖҒM2гҖҒM3]->[M1гҖҒM2гҖҒM3гҖҒM4гҖҒM5]->[M2гҖҒM3гҖҒM4гҖҒM5]->[M2гҖҒM4]->[M1гҖҒM3гҖҒM4гҖҒM5]зҡ„жңәеҷЁз»„еҗҲгҖӮи°ғеәҰзҡ„зӣ®зҡ„иҝҳжҳҜжҖ»зҡ„е®Ңе·Ҙж—¶й—ҙжңҖзҹӯпјҲд№ҹеҸҜд»ҘжҳҜе…¶д»–зӣ®ж ҮпјҢжҜ”еҰӮжңәеҷЁжңҖеӨ§иҙҹиҚ·жңҖзҹӯгҖҒжҖ»зҡ„жңәеҷЁиҙҹиҚ·жңҖзҹӯпјү
йҒ—дј з®—жі•пјҲGenetic AlgorithmпјҢGAпјүжҳҜиҝӣеҢ–и®Ўз®—зҡ„дёҖйғЁеҲҶпјҢжҳҜжЁЎжӢҹиҫҫе°”ж–Үзҡ„йҒ—дј йҖүжӢ©е’ҢиҮӘ然ж·ҳжұ°зҡ„з”ҹзү©иҝӣеҢ–иҝҮзЁӢзҡ„и®Ўз®—жЁЎеһӢпјҢжҳҜдёҖз§ҚйҖҡиҝҮжЁЎжӢҹиҮӘ然иҝӣеҢ–иҝҮзЁӢжҗңзҙўжңҖдјҳи§Јзҡ„ж–№жі•гҖӮиҜҘз®—жі•з®ҖеҚ•гҖҒйҖҡз”ЁпјҢйІҒжЈ’жҖ§ејәпјҢйҖӮдәҺ并иЎҢеӨ„зҗҶгҖӮ
йҒ—дј з®—жі•жҳҜдёҖзұ»еҸҜз”ЁдәҺеӨҚжқӮзі»з»ҹдјҳеҢ–зҡ„е…·жңүйІҒжЈ’жҖ§зҡ„жҗңзҙўз®—жі•пјҢдёҺдј з»ҹзҡ„дјҳеҢ–з®—жі•зӣёжҜ”пјҢе…·жңүд»ҘдёӢзү№зӮ№пјҡ
пјҲ1пјүд»ҘеҶізӯ–еҸҳйҮҸзҡ„зј–з ҒдҪңдёәиҝҗз®—еҜ№иұЎгҖӮдј з»ҹзҡ„дјҳеҢ–з®—жі•еҫҖеҫҖзӣҙжҺҘеҲ©з”ЁеҶізӯ–еҸҳйҮҸзҡ„е®һйҷ…еҖјжң¬иә«жқҘиҝӣиЎҢдјҳеҢ–и®Ўз®—пјҢдҪҶйҒ—дј з®—жі•жҳҜдҪҝз”ЁеҶізӯ–еҸҳйҮҸзҡ„жҹҗз§ҚеҪўејҸзҡ„зј–з ҒдҪңдёәиҝҗз®—еҜ№иұЎгҖӮиҝҷз§ҚеҜ№еҶізӯ–еҸҳйҮҸзҡ„зј–з ҒеӨ„зҗҶж–№ејҸпјҢдҪҝеҫ—жҲ‘们еңЁдјҳеҢ–и®Ўз®—дёӯеҸҜеҖҹйүҙз”ҹзү©еӯҰдёӯжҹ“иүІдҪ“е’Ңеҹәеӣ зӯүжҰӮеҝөпјҢеҸҜд»ҘжЁЎд»ҝиҮӘ然з•Ңдёӯз”ҹзү©зҡ„йҒ—дј е’ҢиҝӣеҢ–жҝҖеҠұпјҢд№ҹеҸҜд»ҘеҫҲж–№дҫҝең°еә”з”ЁйҒ—дј ж“ҚдҪңз®—еӯҗгҖӮ
пјҲ2пјүзӣҙжҺҘд»ҘйҖӮеә”еәҰдҪңдёәжҗңзҙўдҝЎжҒҜгҖӮдј з»ҹзҡ„дјҳеҢ–з®—жі•дёҚд»…йңҖиҰҒеҲ©з”Ёзӣ®ж ҮеҮҪж•°еҖјпјҢиҖҢдё”жҗңзҙўиҝҮзЁӢеҫҖеҫҖеҸ—зӣ®ж ҮеҮҪж•°зҡ„иҝһз»ӯжҖ§зәҰжқҹпјҢжңүеҸҜиғҪиҝҳйңҖиҰҒж»Ўи¶івҖңзӣ®ж ҮеҮҪж•°зҡ„еҜјж•°еҝ…йЎ»еӯҳеңЁвҖқзҡ„иҰҒжұӮд»ҘзЎ®е®ҡжҗңзҙўж–№еҗ‘гҖӮйҒ—дј з®—жі•д»…дҪҝз”Ёз”ұзӣ®ж ҮеҮҪж•°еҖјеҸҳжҚўжқҘзҡ„йҖӮеә”еәҰеҮҪж•°еҖје°ұеҸҜзЎ®е®ҡиҝӣдёҖжӯҘзҡ„жҗңзҙўиҢғеӣҙпјҢж— йңҖзӣ®ж ҮеҮҪж•°зҡ„еҜјж•°еҖјзӯүе…¶д»–иҫ…еҠ©дҝЎжҒҜгҖӮзӣҙжҺҘеҲ©з”Ёзӣ®ж ҮеҮҪж•°еҖјжҲ–дёӘдҪ“йҖӮеә”еәҰеҖјд№ҹеҸҜд»Ҙе°ҶжҗңзҙўиҢғеӣҙйӣҶдёӯеҲ°йҖӮеә”еәҰиҫғй«ҳйғЁеҲҶзҡ„жҗңзҙўз©әй—ҙдёӯпјҢд»ҺиҖҢжҸҗй«ҳжҗңзҙўж•ҲзҺҮгҖӮ
пјҲ3пјүдҪҝз”ЁеӨҡдёӘзӮ№зҡ„жҗңзҙўдҝЎжҒҜпјҢе…·жңүйҡҗеҗ«е№¶иЎҢжҖ§гҖӮдј з»ҹзҡ„дјҳеҢ–з®—жі•еҫҖеҫҖжҳҜд»Һи§Јз©әй—ҙзҡ„дёҖдёӘеҲқе§ӢзӮ№ејҖе§ӢжңҖдјҳи§Јзҡ„иҝӯд»ЈжҗңзҙўиҝҮзЁӢгҖӮеҚ•дёӘзӮ№жүҖжҸҗдҫӣзҡ„жҗңзҙўдҝЎжҒҜдёҚеӨҡпјҢжүҖд»Ҙжҗңзҙўж•ҲзҺҮдёҚй«ҳпјҢиҝҳжңүеҸҜиғҪйҷ·е…ҘеұҖйғЁжңҖдјҳи§ЈиҖҢеҒңж»һпјӣйҒ—дј з®—жі•д»Һз”ұеҫҲеӨҡдёӘдҪ“з»„жҲҗзҡ„еҲқе§Ӣз§ҚзҫӨејҖе§ӢжңҖдјҳи§Јзҡ„жҗңзҙўиҝҮзЁӢпјҢиҖҢдёҚжҳҜд»ҺеҚ•дёӘдёӘдҪ“ејҖе§ӢжҗңзҙўгҖӮеҜ№еҲқе§ӢзҫӨдҪ“иҝӣиЎҢзҡ„гҖҒйҖүжӢ©гҖҒдәӨеҸүгҖҒеҸҳејӮзӯүиҝҗз®—пјҢдә§з”ҹеҮәж–°дёҖд»ЈзҫӨдҪ“пјҢе…¶дёӯеҢ…жӢ¬дәҶи®ёеӨҡзҫӨдҪ“дҝЎжҒҜгҖӮиҝҷдәӣдҝЎжҒҜеҸҜд»ҘйҒҝе…ҚжҗңзҙўдёҖдәӣдёҚеҝ…иҰҒзҡ„зӮ№пјҢд»ҺиҖҢйҒҝе…Қйҷ·е…ҘеұҖйғЁжңҖдјҳпјҢйҖҗжӯҘйҖјиҝ‘е…ЁеұҖжңҖдјҳи§ЈгҖӮ
пјҲ4пјү дҪҝз”ЁжҰӮзҺҮжҗңзҙўиҖҢйқһзЎ®е®ҡжҖ§и§„еҲҷгҖӮдј з»ҹзҡ„дјҳеҢ–з®—жі•еҫҖеҫҖдҪҝз”ЁзЎ®е®ҡжҖ§зҡ„жҗңзҙўж–№жі•пјҢдёҖдёӘжҗңзҙўзӮ№еҲ°еҸҰдёҖдёӘжҗңзҙўзӮ№зҡ„иҪ¬з§»жңүзЎ®е®ҡзҡ„иҪ¬з§»ж–№еҗ‘е’ҢиҪ¬з§»е…ізі»пјҢиҝҷз§ҚзЎ®е®ҡжҖ§еҸҜиғҪдҪҝеҫ—жҗңзҙўиҫҫдёҚеҲ°жңҖдјҳеә—пјҢйҷҗеҲ¶дәҶз®—жі•зҡ„еә”з”ЁиҢғеӣҙгҖӮйҒ—дј з®—жі•жҳҜдёҖз§ҚиҮӘйҖӮеә”жҗңзҙўжҠҖжңҜпјҢе…¶йҖүжӢ©гҖҒдәӨеҸүгҖҒеҸҳејӮзӯүиҝҗз®—йғҪжҳҜд»ҘдёҖз§ҚжҰӮзҺҮж–№ејҸиҝӣиЎҢзҡ„пјҢеўһеҠ дәҶжҗңзҙўиҝҮзЁӢзҡ„зҒөжҙ»жҖ§пјҢиҖҢдё”иғҪд»ҘиҫғеӨ§жҰӮзҺҮ收ж•ӣдәҺжңҖдјҳи§ЈпјҢе…·жңүиҫғеҘҪзҡ„е…ЁеұҖдјҳеҢ–жұӮи§ЈиғҪеҠӣгҖӮдҪҶпјҢдәӨеҸүжҰӮзҺҮгҖҒеҸҳејӮжҰӮзҺҮзӯүеҸӮж•°д№ҹдјҡеҪұе“Қз®—жі•зҡ„жҗңзҙўз»“жһңе’Ңжҗңзҙўж•ҲзҺҮпјҢжүҖд»ҘеҰӮдҪ•йҖүжӢ©йҒ—дј з®—жі•зҡ„еҸӮж•°еңЁе…¶еә”з”ЁдёӯжҳҜдёҖдёӘжҜ”иҫғйҮҚиҰҒзҡ„й—®йўҳгҖӮ
з»јдёҠпјҢз”ұдәҺйҒ—дј з®—жі•зҡ„ж•ҙдҪ“жҗңзҙўзӯ–з•Ҙе’ҢдјҳеҢ–жҗңзҙўж–№ејҸеңЁи®Ўз®—ж—¶дёҚдҫқиө–дәҺжўҜеәҰдҝЎжҒҜжҲ–е…¶д»–иҫ…еҠ©зҹҘиҜҶпјҢеҸӘйңҖиҰҒжұӮи§ЈеҪұе“Қжҗңзҙўж–№еҗ‘зҡ„зӣ®ж ҮеҮҪж•°е’Ңзӣёеә”зҡ„йҖӮеә”еәҰеҮҪж•°пјҢжүҖд»ҘйҒ—дј з®—жі•жҸҗдҫӣдәҶдёҖз§ҚжұӮи§ЈеӨҚжқӮзі»з»ҹй—®йўҳзҡ„йҖҡз”ЁжЎҶжһ¶гҖӮе®ғдёҚдҫқиө–дәҺй—®йўҳзҡ„е…·дҪ“йўҶеҹҹпјҢеҜ№й—®йўҳзҡ„з§Қзұ»жңүеҫҲејәзҡ„йІҒжЈ’жҖ§пјҢжүҖд»Ҙе№ҝжіӣеә”з”ЁдәҺеҗ„з§ҚйўҶеҹҹпјҢеҢ…жӢ¬пјҡеҮҪж•°дјҳеҢ–гҖҒз»„еҗҲдјҳеҢ–з”ҹдә§и°ғеәҰй—®йўҳгҖҒиҮӘеҠЁжҺ§еҲ¶
гҖҒжңәеҷЁдәәеӯҰгҖҒеӣҫеғҸеӨ„зҗҶпјҲеӣҫеғҸжҒўеӨҚгҖҒеӣҫеғҸиҫ№зјҳзү№еҫҒжҸҗеҸ–…)гҖҒдәәе·Ҙз”ҹе‘ҪгҖҒйҒ—дј зј–зЁӢгҖҒжңәеҷЁеӯҰд№ гҖӮ
еҹәжң¬йҒ—дј з®—жі•пјҲSimple Genetic Algorithms,SGAпјүеҸӘдҪҝз”ЁйҖүжӢ©з®—еӯҗгҖҒдәӨеҸүз®—еӯҗе’ҢеҸҳејӮз®—еӯҗиҝҷдёүз§ҚйҒ—дј з®—еӯҗпјҢиҝӣеҢ–иҝҮзЁӢз®ҖеҚ•пјҢжҳҜе…¶д»–йҒ—дј з®—жі•зҡ„еҹәзЎҖгҖӮ
йҖҡиҝҮйҡҸжңәж–№ејҸдә§з”ҹиӢҘе№Із”ұзЎ®е®ҡй•ҝеәҰпјҲй•ҝеәҰдёҺеҫ…жұӮи§Јй—®йўҳзҡ„зІҫеәҰжңүе…іпјүзј–з Ғзҡ„еҲқе§ӢзҫӨдҪ“пјӣ
йҖҡиҝҮйҖӮеә”еәҰеҮҪж•°еҜ№жҜҸдёӘдёӘдҪ“иҝӣиЎҢиҜ„д»·пјҢйҖүжӢ©йҖӮеә”еәҰеҖјй«ҳзҡ„дёӘдҪ“еҸӮдёҺйҒ—дј ж“ҚдҪңпјҢйҖӮеә”еәҰдҪҺзҡ„дёӘдҪ“иў«ж·ҳжұ°пјӣ
з»ҸйҒ—дј ж“ҚдҪңпјҲеӨҚеҲ¶гҖҒдәӨеҸүгҖҒеҸҳејӮпјүзҡ„дёӘдҪ“йӣҶеҗҲеҪўжҲҗж–°дёҖд»Јз§ҚзҫӨпјҢзӣҙеҲ°ж»Ўи¶іеҒңжӯўеҮҶеҲҷпјҲиҝӣеҢ–д»Јж•°GEN>=?пјүпјӣ
е°ҶеҗҺд»ЈдёӯеҸҳзҺ°жңҖеҘҪзҡ„дёӘдҪ“дҪңдёәйҒ—дј з®—жі•зҡ„жү§иЎҢз»“жһңгҖӮ
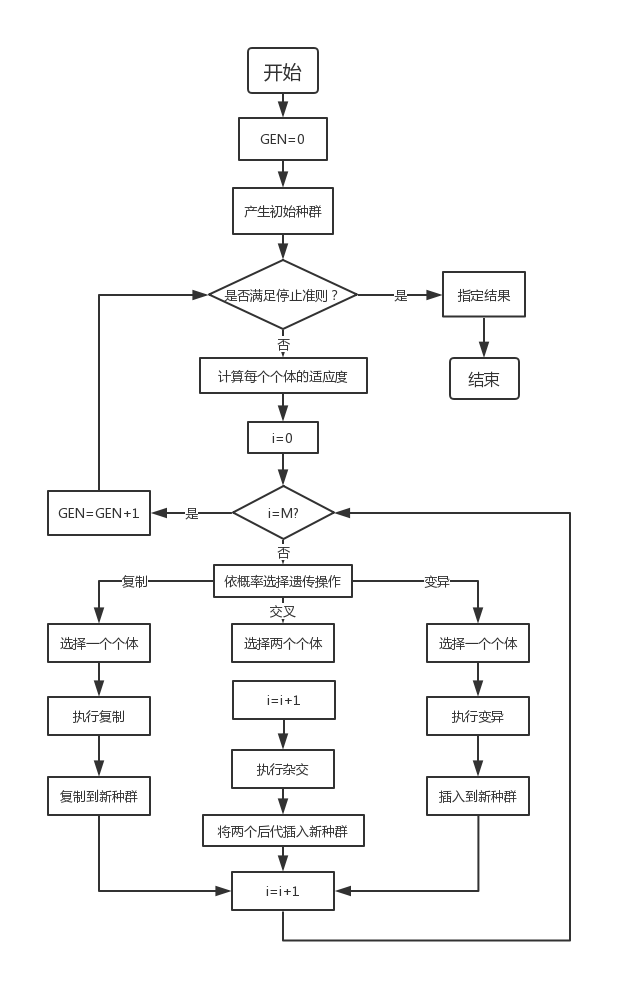
е…¶дёӯпјҢGENжҳҜеҪ“еүҚд»Јж•°пјӣMжҳҜз§ҚзҫӨ规模пјҢiд»ЈиЎЁз§ҚзҫӨж•°йҮҸгҖӮ
еҹәжң¬йҒ—дј з®—жі•пјҲSGAпјүз”ұзј–з ҒгҖҒйҖӮеә”еәҰеҮҪж•°гҖҒйҒ—дј з®—еӯҗпјҲйҖүжӢ©гҖҒдәӨеҸүгҖҒеҸҳејӮпјүеҸҠиҝҗиЎҢеҸӮж•°з»„жҲҗгҖӮ
пјҲ1пјүдәҢиҝӣеҲ¶зј–з Ғ
дәҢиҝӣеҲ¶зј–з Ғзҡ„еӯ—з¬ҰдёІй•ҝеәҰдёҺй—®йўҳжүҖжұӮи§Јзҡ„зІҫеәҰжңүе…ігҖӮйңҖиҰҒдҝқиҜҒжүҖжұӮи§Јз©әй—ҙеҶ…зҡ„жҜҸдёҖдёӘдёӘдҪ“йғҪеҸҜд»Ҙиў«зј–з ҒгҖӮ
дјҳзӮ№пјҡзј–гҖҒи§Јз Ғж“ҚдҪңз®ҖеҚ•пјҢйҒ—дј гҖҒдәӨеҸүдҫҝдәҺе®һзҺ°
зјәзӮ№пјҡй•ҝеәҰеӨ§
пјҲ2пјүе…¶д»–зј–з Ғж–№жі•
ж јйӣ·з ҒгҖҒжө®зӮ№ж•°зј–з ҒгҖҒз¬ҰеҸ·зј–з ҒгҖҒеӨҡеҸӮж•°зј–з Ғзӯү
йҖӮеә”еәҰеҮҪж•°иҰҒжңүж•ҲеҸҚжҳ жҜҸдёҖдёӘжҹ“иүІдҪ“дёҺй—®йўҳзҡ„жңҖдјҳи§Јжҹ“иүІдҪ“д№Ӣй—ҙзҡ„е·®и·қгҖӮ

дәӨеҸүиҝҗз®—жҳҜжҢҮеҜ№дёӨдёӘзӣёдә’й…ҚеҜ№зҡ„жҹ“иүІдҪ“жҢүжҹҗз§Қж–№ејҸзӣёдә’дәӨжҚўе…¶йғЁеҲҶеҹәеӣ пјҢд»ҺиҖҢеҪўжҲҗдёӨдёӘж–°зҡ„дёӘдҪ“пјӣдәӨеҸүиҝҗз®—жҳҜйҒ—дј з®—жі•еҢәеҲ«дәҺе…¶д»–иҝӣеҢ–з®—жі•зҡ„йҮҚиҰҒзү№еҫҒпјҢжҳҜдә§з”ҹж–°дёӘдҪ“зҡ„дё»иҰҒж–№жі•гҖӮеңЁдәӨеҸүд№ӢеүҚйңҖиҰҒе°ҶзҫӨдҪ“дёӯзҡ„дёӘдҪ“иҝӣиЎҢй…ҚеҜ№пјҢдёҖиҲ¬йҮҮеҸ–йҡҸжңәй…ҚеҜ№еҺҹеҲҷгҖӮ
еёёз”Ёзҡ„дәӨеҸүж–№ејҸпјҡ
еҚ•зӮ№дәӨеҸү
еҸҢзӮ№дәӨеҸүпјҲеӨҡзӮ№дәӨеҸүпјҢдәӨеҸүзӮ№ж•°и¶ҠеӨҡпјҢдёӘдҪ“зҡ„з»“жһ„иў«з ҙеқҸзҡ„еҸҜиғҪжҖ§и¶ҠеӨ§пјҢдёҖиҲ¬дёҚйҮҮз”ЁеӨҡзӮ№дәӨеҸүзҡ„ж–№ејҸпјү
еқҮеҢҖдәӨеҸү
з®—жңҜдәӨеҸү
йҒ—дј з®—жі•дёӯзҡ„еҸҳејӮиҝҗз®—жҳҜжҢҮе°ҶдёӘдҪ“жҹ“иүІдҪ“зј–з ҒдёІдёӯзҡ„жҹҗдәӣеҹәеӣ еә§дёҠзҡ„еҹәеӣ еҖјз”ЁиҜҘеҹәеӣ еә§зҡ„е…¶д»–зӯүдҪҚеҹәеӣ жқҘжӣҝжҚўпјҢд»ҺиҖҢеҪўжҲҗдёҖдёӘж–°зҡ„дёӘдҪ“гҖӮ
е°ұйҒ—дј з®—жі•иҝҗз®—иҝҮзЁӢдёӯдә§з”ҹж–°дёӘдҪ“зҡ„иғҪеҠӣж–№йқўжқҘиҜҙпјҢдәӨеҸүиҝҗз®—жҳҜдә§з”ҹж–°дёӘдҪ“зҡ„дё»иҰҒж–№жі•пјҢе®ғеҶіе®ҡдәҶйҒ—дј з®—жі•зҡ„е…ЁеұҖжҗңзҙўиғҪеҠӣпјӣиҖҢеҸҳејӮиҝҗз®—еҸӘжҳҜдә§з”ҹж–°дёӘдҪ“зҡ„иҫ…еҠ©ж–№жі•пјҢдҪҶд№ҹжҳҜеҝ…дёҚеҸҜе°‘зҡ„дёҖдёӘиҝҗз®—жӯҘйӘӨпјҢе®ғеҶіе®ҡдәҶйҒ—дј з®—жі•зҡ„еұҖйғЁжҗңзҙўиғҪеҠӣгҖӮдәӨеҸүз®—еӯҗдёҺеҸҳејӮз®—еӯҗзҡ„е…ұеҗҢй…ҚеҗҲе®ҢжҲҗдәҶе…¶еҜ№жҗңзҙўз©әй—ҙзҡ„е…ЁеұҖжҗңзҙўе’ҢеұҖйғЁжҗңзҙўпјҢд»ҺиҖҢдҪҝйҒ—дј з®—жі•иғҪд»ҘиүҜеҘҪзҡ„жҗңзҙўжҖ§иғҪе®ҢжҲҗжңҖдјҳеҢ–й—®йўҳзҡ„еҜ»дјҳиҝҮзЁӢгҖӮ


е…·жңүдҪҺйҳ¶гҖҒе®ҡд№үй•ҝеәҰзҹӯпјҢдё”йҖӮеә”еәҰеҖјй«ҳдәҺзҫӨдҪ“е№іеқҮйҖӮеә”еәҰеҖјзҡ„жЁЎејҸз§°дёәеҹәеӣ еқ—жҲ–з§ҜжңЁеқ—гҖӮ
з§ҜжңЁеқ—еҒҮи®ҫпјҡдёӘдҪ“зҡ„еҹәеӣ еқ—йҖҡиҝҮйҖүжӢ©гҖҒдәӨеҸүгҖҒеҸҳејӮзӯүйҒ—дј з®—еӯҗзҡ„дҪңз”ЁпјҢиғҪеӨҹзӣёдә’жӢјжҺҘеңЁдёҖиө·пјҢеҪўжҲҗйҖӮеә”еәҰжӣҙй«ҳзҡ„дёӘдҪ“зј–з ҒдёІгҖӮ
з§ҜжңЁеқ—еҒҮи®ҫиҜҙжҳҺдәҶз”ЁйҒ—дј з®—жі•жұӮи§Јеҗ„зұ»й—®йўҳзҡ„еҹәжң¬жҖқжғіпјҢеҚійҖҡиҝҮз§ҜжңЁеқ—зӣҙжҺҘзӣёдә’жӢјжҺҘеңЁдёҖиө·иғҪеӨҹдә§з”ҹжӣҙеҘҪзҡ„и§ЈгҖӮ
clc;clear
%% дёӢиҪҪж•°жҚ®
% еҠ е·Ҙж•°жҚ®еҢ…жӢ¬еҠ е·Ҙж—¶й—ҙпјҢеҠ е·ҘжңәеҷЁпјҢжңәеҷЁж•°пјҢеҗ„жңәеҷЁжқғйҮҚпјҢе·Ҙ件数пјҢеҗ„е·Ҙ件еҜ№еә”зҡ„е·ҘеәҸж•°
load data operation_time operation_machine num_machine machine_weight num_job num_op
%% еҹәжң¬еҸӮж•°
MAXGEN = 200; % жңҖеӨ§иҝӯд»Јж¬Ўж•°
Ps = 0.8; % йҖүжӢ©зҺҮ
Pc = 0.7; % дәӨеҸүзҺҮ
Pm = 0.3; % еҸҳејӮзҺҮ
sizepop = 200; % дёӘдҪ“ж•°зӣ®
e = 0.5; % зӣ®ж ҮеҖјжқғйҮҚ
trace = zeros(2,MAXGEN);
%% ===========================з§ҚзҫӨеҲқе§ӢеҢ–============================
total_op_num=sum(num_op);
chroms=initialization(num_op,num_job,total_op_num,sizepop,operation_machine,operation_time);
[Z,~,~]=fitness(chroms,num_machine,e,num_job,num_op);
%% ============================иҝӯд»ЈиҝҮзЁӢ=============================
for gen=1:MAXGEN
fprintf('еҪ“еүҚиҝӯд»Јж¬Ўж•°пјҡ'),disp(gen)
% иҪ®зӣҳиөҢйҖүжӢ©
chroms_new=selection(chroms,Z,Ps);
% дәӨеҸүж“ҚдҪң
chroms_new=crossover(chroms_new,Pc,total_op_num,num_job,num_op);
% еҸҳејӮж“ҚдҪң
chroms_new=mutation(chroms_new,total_op_num,Pm,num_machine,e,num_job,num_op,operation_machine,operation_time);
% и®Ўз®—йҖүжӢ©дәӨеҸүеҸҳејӮеҗҺдёӘдҪ“зҡ„йҖӮеә”еәҰ
[Z_new,~,~]=fitness(chroms_new,num_machine,e,num_job,num_op);
% ж №жҚ®йҖӮеә”еәҰеңЁеҺҹз§ҚзҫӨе’ҢйҒ—дј ж“ҚдҪңеҗҺзҡ„з§ҚзҫӨдёӯйҖүеҮәsizepopдёӘжӣҙдјҳдёӘдҪ“
[chroms,Z,chrom_best]=update_chroms(chroms,chroms_new,Z,Z_new,sizepop);
% и®°еҪ•жҜҸд»Јзҡ„жңҖдјҳйҖӮеә”еәҰдёҺе№іеқҮйҖӮеә”еәҰ
trace(1, gen)=Z(1);
trace(2, gen)=mean(Z);
% жӣҙж–°е…ЁеұҖжңҖдјҳйҖӮеә”еәҰ
if gen==1 || MinVal>trace(1,gen)
MinVal=trace(1,gen);
function [Z,machine_weight,pvals] = fitness(chroms,num_machine,e,num_job,num_op)
sizepop=size(chroms,1);
pvals=cell(1,sizepop);
Z1=zeros(1,sizepop);
Z2=Z1;
total_op_num=sum(num_op); % жҖ»е·ҘеәҸж•°
for k=1:sizepop
chrom=chroms(k,:);
machine=zeros(1,num_machine); % и®°еҪ•еҗ„жңәеҷЁеҸҳеҢ–ж—¶й—ҙ
job=zeros(1,num_job); % и®°еҪ•еҗ„е·Ҙ件еҸҳеҢ–ж—¶й—ҙ
machine_time=zeros(1,num_machine); % и®Ўз®—еҗ„жңәеҷЁзҡ„е®һйҷ…еҠ е·Ҙж—¶й—ҙ
pval=zeros(2,total_op_num); % и®°еҪ•еҗ„е·ҘеәҸејҖе§Ӣе’Ңз»“жқҹж—¶й—ҙ
for i=1:total_op_num
% жңәеҷЁж—¶й—ҙеӨ§дәҺе·Ҙ件时й—ҙ
if machine(chrom(total_op_num+i))>=job(chrom(i))
pval(1,i)=machine(chrom(total_op_num+i)); % и®°еҪ•е·Ҙ件ејҖе§Ӣж—¶й—ҙ
machine(chrom(total_op_num+i))=machine(chrom(total_op_num+i))+chrom(total_op_num*2+i);
job(chrom(i))=machine(chrom(total_op_num+i));
pval(2,i)=machine(chrom(total_op_num+i)); % и®°еҪ•е·Ҙ件结жқҹж—¶й—ҙ
% жңәеҷЁж—¶й—ҙе°ҸдәҺе·Ҙ件时й—ҙ
else
pval(1,i)=job(chrom(i));
job(chrom(i))=job(chrom(i))+chrom(total_op_num*2+i);
machine(chrom(total_op_num+i))=job(chrom(i));
pval(2,i)=job(chrom(i));
end
machine_time(chrom(total_op_num+i))=machine_time(chrom(total_op_num+i))+chrom(total_op_num*2+i);
end
Z1(k)=max(machine); % жңҖеӨ§жңәеҷЁж—¶й—ҙеҖјпјҢеҜ№еә”makespan
% machine_weight=machine_time/sum(machine_time); % и®Ўз®—еҗ„жңәеҷЁзҡ„иҙҹиҚ·
machine_weight=machine_time;
Z2(k)=max(machine_weight)-min(machine_weight);
pvals{k}=pval;
end
% min_makespan=min(Z1);%жүҖжңүжҹ“иүІдҪ“зҡ„makespanжңҖдјҳеҖј
% max_makespan=max(Z1);
% min_weight=min(Z2);%иҙҹиҪҪжңҖдјҳеҖј
% max_weight=max(Z2);
% Z=e*((Z1-min_makespan)./(max_makespan-min_makespan))+(1-e)*((Z2-min_weight)./(max_weight-min_weight));%и®Ўз®—йҖӮеә”еәҰ
Z=e*Z1+(1-e)*Z2;
function [ chroms_new] = crossover(chroms,Pc,total_op_num,num_job,num_op)
size_chrom=size(chroms,1); % жҹ“иүІдҪ“ж•°
chroms_new=chroms;
%% йқўеҗ‘е·ҘеәҸз Ғзҡ„дәӨеҸүж“ҚдҪң
for i=1:2:size_chrom-1
if Pc>rand
% зҲ¶д»Јжҹ“иүІдҪ“
parent1=chroms(i,:);
parent2=chroms(i+1,:);
Job=randperm(num_job);
% е°Ҷе·Ҙ件йҡҸжңәеҲҶжҲҗдёӨдёӘйӣҶеҗҲ
J1=Job(1:round(num_job/2));
J2=Job(length(J1)+1:end);
% еӯҗд»Јжҹ“иүІдҪ“
child1=parent1;
child2=parent2;
op_p1=[];
op_p2=[];
for j=1:length(J2)
%жүҫеҮәзҲ¶д»ЈдёӯJ2зүҮж®өеҜ№еә”зҡ„дҪҚзҪ®
op_p1=[op_p1,find(parent1(1:total_op_num)==J2(j))];
op_p2=[op_p2,find(parent2(1:total_op_num)==J2(j))];
end
op_s1=sort(op_p1);
op_s2=sort(op_p2);
% еӯҗд»Ј1дәӨжҚўJ2зүҮж®өзҡ„еҹәеӣ пјҢжңәеҷЁз ҒеҜ№еә”дҪҚзҪ®зҡ„еҹәеӣ пјҢе·Ҙж—¶з ҒеҜ№еә”дҪҚзҪ®зҡ„еҹәеӣ
child1(op_s1)=parent2(op_s2);
child1(total_op_num+op_s1)=parent2(total_op_num+op_s2);
child1(total_op_num*2+op_s1)=parent2(total_op_num*2+op_s2);
% еӯҗд»Ј2еҗҢзҗҶ
child2(op_s2)=parent1(op_s1);
child2(total_op_num+op_s2)=parent1(total_op_num+op_s1);
child2(total_op_num*2+op_s2)=parent1(total_op_num*2+op_s1);
chroms_new(i,:)=child1;
chroms_new(i+1,:)=child2;
end
end
%% йқўеҗ‘жңәеҷЁз Ғзҡ„дәӨеҸүж“ҚдҪң
for k=1:2:size_chrom-1
if Pc>rand
parent1=chroms_new(k,:);
parent2=chroms_new(k+1,:);
child1=parent1;
child2=parent2;
% йҡҸжңәдә§з”ҹдёҺжҹ“иүІдҪ“й•ҝеәҰзӣёзӯүзҡ„0,1еәҸеҲ—
rand0_1=randi([0,1],1,total_op_num);
for n=1:num_job
ind_0=find(rand0_1(num_op(n)*(n-1)+1:num_op(n)*n)==0);
if ~isempty(ind_0)
temp1=find(parent1(1:total_op_num)==n);
temp2=find(parent2(1:total_op_num)==n);
child1(total_op_num+temp1(ind_0))=parent2(total_op_num+temp2(ind_0));
child2(total_op_num+temp2(ind_0))=parent1(total_op_num+temp1(ind_0));
child1(total_op_num*2+temp1(ind_0))=parent2(total_op_num*2+temp2(ind_0));
child2(total_op_num*2+temp2(ind_0))=parent1(total_op_num*2+temp1(ind_0));
end
end
chroms_new(k,:)=child1;
chroms_new(k+1,:)=child2;
end
end
end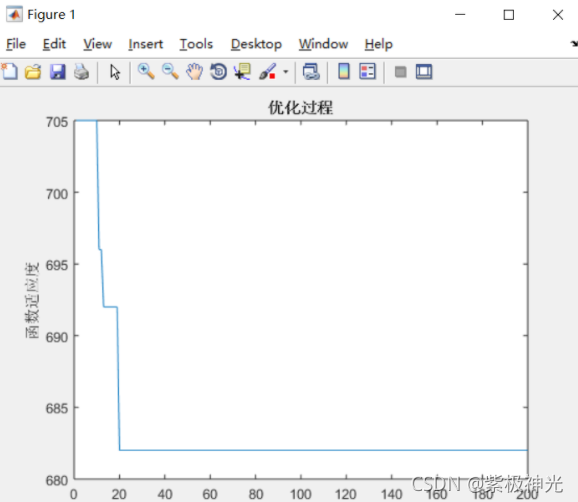
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңеҰӮдҪ•дҪҝз”ЁmatlabйҒ—дј з®—жі•жұӮи§ЈиҪҰй—ҙи°ғеәҰй—®йўҳвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ