您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
今天小编给大家分享一下Redis布隆过滤器大小的算法公式是什么的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
客户端:这个key存在吗?
服务器:不存在/不知道
本质上,布隆过滤器是一种数据结构,是一种比较巧妙的概率型数据结构。它的特点是高效地插入和查询。但我们要检查一个key是否在某个结构中存在时,通过使用布隆过滤器,我们可以快速了解到「这个key一定不存在或者可能存在」。相比于传统的List、Set、Map这些数据结构,它更加高效、占用的空间也越少,但是它返回的结果是概率性的,是不确切的。
布隆过滤器仅用于测试集合中的成员资格。使用布隆过滤器的经典示例是减少对不存在的密钥的昂贵磁盘(或网络)查找。正如我们看到的那样,布隆过滤器可以在O(k)恒定时间内搜索密钥,其中k是哈希函数的数量,测试密钥的不存在将非常快。
为了提高访问效率,我们会将一些数据放在Redis缓存中。当进行数据查询时,可以先从缓存中获取数据,无需读取数据库。这样可以有效地提升性能。
在数据查询时,首先要判断缓存中是否有数据,如果有数据,就直接从缓存中获取数据。
但如果没有数据,就需要从数据库中获取数据,然后放入缓存。如果大量访问都无法命中缓存,会造成数据库要扛较大压力,从而导致数据库崩溃。而使用布隆过滤器,当访问不存在的缓存时,可以迅速返回避免缓存或者DB crash。
HBase中存储着非常海量数据,要判断某个ROWKEYS、或者某个列是否存在,使用布隆过滤器,可以快速获取某个数据是否存在。但有一定的误判率。但如果某个key不存在,一定是准确的。
要判断某个元素是否存在其实用HashMap效率是非常高的。HashMap通过把值映射为HashMap的Key,这种方式可以实现O(1)常数级时间复杂度。
但是,如果存储的数据量非常大的时候(例如:上亿的数据),HashMap将会耗费非常大的内存大小。而且也根本无法一次性将海量的数据读进内存。
工作原理图:
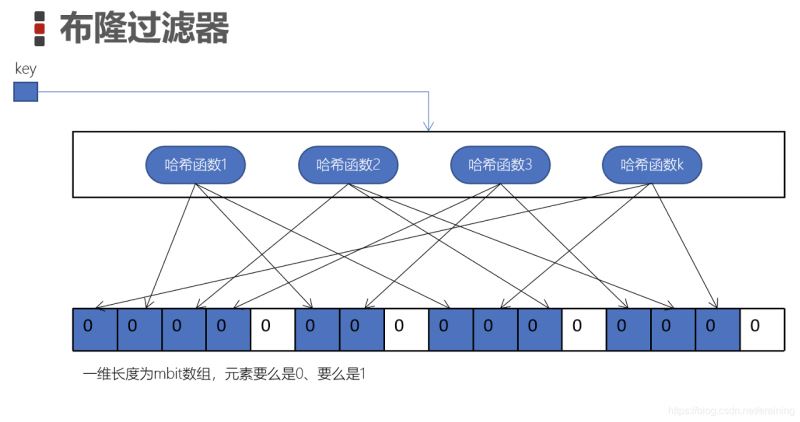
布隆过滤器是一个bit数组或者称为一个bit二进制向量
这个数组中的元素存的要么是0、要么是1
k个hash函数都是彼此独立的,并将每个hash函数计算后的结果对数组的长度m取模,并将对一个的bit设置为1(蓝色单元格)
我们将每个key都按照这种方式设置单元格,就是「布隆过滤器」
假设输入一个key,我们使用之前的k个hash函数求哈希,得到k个值
判断这k个值是否都为蓝色,如果有一个不是蓝色,那么这个key一定不存在
如果都有蓝色,那么key是可能存在(布隆过滤器会存在误判)
因为如果输入对象很多,而集合比较小的情况,会导致集合中大多位置都会被描蓝,那么检查某个key时候为蓝色时,刚好某个位置正好被设置为蓝色了,此时,会错误认为该key在集合中
示例:
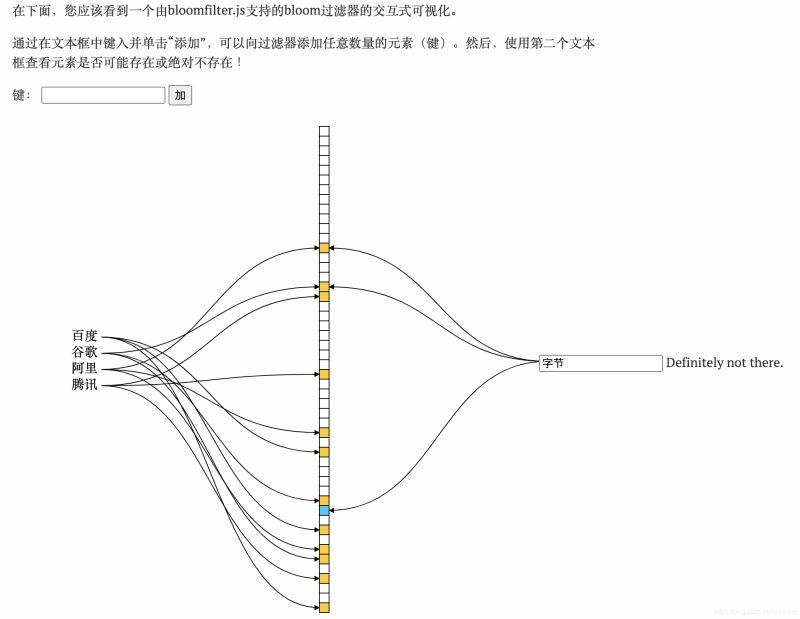
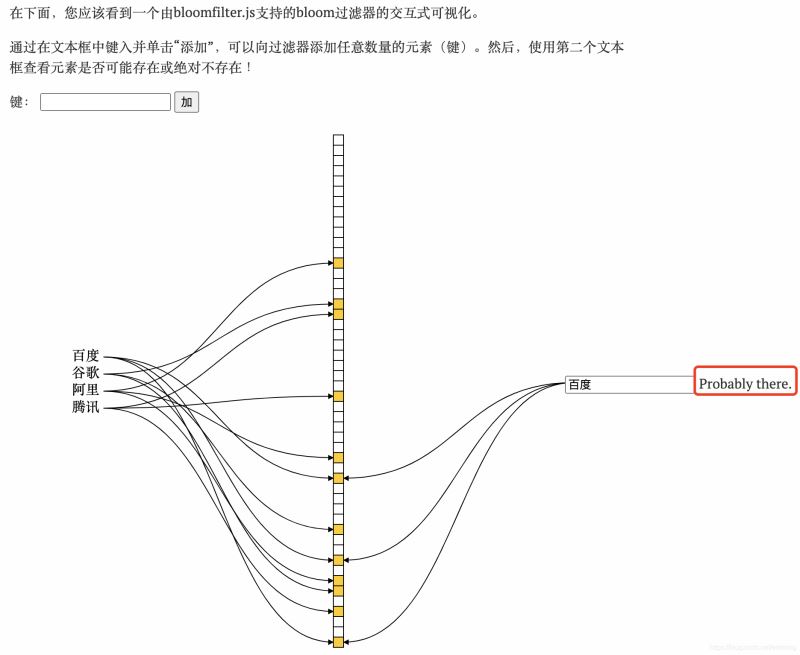
传统的布隆过滤器并不支持删除操作。但是名为 Counting Bloom filter 的变种可以用来测试元素计数个数是否绝对小于某个阈值,它支持元素删除。详细理解可以参考文章Counting Bloom Filter 的原理和实现, 写的很详细。
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。

从上图可以看出,增加哈希函数k的数量将大大降低错误率p。
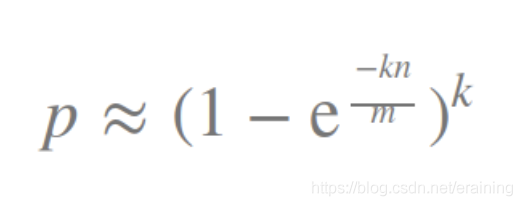
好像是WTF?不用担心,实际上我们实际上需要确定我们的m和k。因此,如果我们自己设置容错值p和元素数n,则可以使用以下公式来计算这些参数:
我们可以根据过滤器的大小m,哈希函数的数量k和插入的元素的数量n来计算误报率p,公式如下:由上面,又怎么选择适合业务的 k 和 m 值呢?
公式:
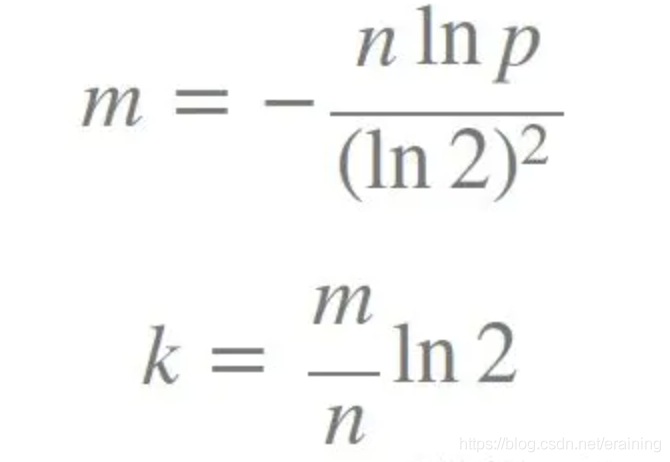
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
至于如何推导这个公式,我在知乎发布的文章有涉及,感兴趣可以看看,不感兴趣的话记住上面这个公式就行了。
我还要在这里提到另一个重要的观点。由于使用Bloom筛选器的唯一目的是搜索速度更快,所以我们不能使用慢速哈希函数,对吗?加密散列函数(例如Sha-1,MD5)对于bloom过滤器不是一个好选择,因为它们有点慢。因此,从更快的哈希函数实现中更好的选择是murmur,fnv系列哈希,Jenkins哈希和HashMix。
在给定的示例中您已经看到,我们可以使用它来警告用户输入弱密码。
您可以使用布隆过滤器,以防止用户从访问恶意网站。
您可以先使用Bloom Bloom筛选器进行廉价的查找检查,而不用查询SQL数据库来检查是否存在具有特定电子邮件的用户。如果电子邮件不存在,那就太好了!如果确实存在,则可能必须对数据库进行额外的查询。您也可以执行同样的操作来搜索“用户名已被占用”。
您可以根据网站访问者的IP地址保留一个Bloom过滤器,以检查您网站的用户是“回头用户”还是“新用户”。“回头用户”的一些误报不会伤害您,对吗?
您也可以通过使用Bloom过滤器跟踪词典单词来进行拼写检查。
以上就是“Redis布隆过滤器大小的算法公式是什么”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。