您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文小编为大家详细介绍“python爬虫字体加密问题怎么解决”,内容详细,步骤清晰,细节处理妥当,希望这篇“python爬虫字体加密问题怎么解决”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
抛出问题

我们看到这个号码是在页面上正常显示的

F12 又是这样就比较麻烦,不能直接获取.
用requests库也是获取不到正常想要的 源码的,因为字体加密了.
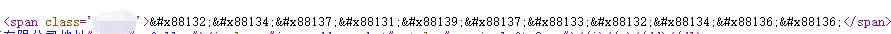
查看页面源代码又是这样的.所以就是我们想怎么解密呢.
获取到真正的源码
找到对应的字体库
进行解析操作.
为什么用webdriver,因为
requests拿不到真正的源码.
from selenium import webdriver
# --- 进行chrome的配置
options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images": 2} # 设置无图模式
options.add_experimental_option("prefs", prefs)
options.add_argument("service_args = ['–ignore-ssl-errors = true', '–ssl-protocol = TLSv1']")
options.binary_location = r'C:\Program Files\Google\Chrome\Application\chrome.exe'
# ---- chrome进行端口接管调用
options.add_argument('-incognito')
driver = webdriver.Chrome(options=options)
driver.set_page_load_timeout(5)
# --- 设置宽和高位置
driver.maximize_window()
# --- 拦截webdriver检测代码
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",
{"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""})找到对应的字体库


这上面进行申明了告诉了我们这个是字体
base64,然后就是那下来然后生成文件.
# 示例 import base64 # 省略了很长的... b64_code = 'AAEAAAAKAIAAAwAgT1MvMla19RMAAACsAAAAYGNtYXAGQAPOAAABDAAAAa5nbHlmZrwdwAAAArwAAAakaGVhZBQx4JoAAAlgAAAANmhoZWEFswFxAAAJmAAAACRobXR4DVYBYgAACbwAAAAubG9jYQwQCnYAAAnsAAAAIm1heHAAFABOAAAKEAAAACBuYW1lUuodRwAACjAAAAGecG9zdDHgxUkAAAvQAAAAdAAEAgsBkAAFAAACmQLMAAAAjwKZAswAAAHrADMBCQAAAgAGAwAAAAAAAAAAAAEQAAAAAAAAAAAAAABQZkVkAMAAI4EEAyz/LABcAywA1AAAAAEAAAAAAxgAAAAAACAAAQAAAAQAAAADAAAAJAABAAAAAABcAAMAAQAAACQAAwAKAAABYgAEADgAAAAKAAgAAgACACMAKwAtAC///wAAACMAKgAtAC/e/9j/1//WAAEAAAAAAAAAAAAAAAABBgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAAAAAAAAgMABAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAMAAAAAABMAAAAAAAAAAUAAAAjAAAAIwAAAAEAAAAqAAAAKwAAAAIAAAAtAAAALQAAAAQAAAAvAAAALwAAAAUACID7AAiBBAAAAAYAAAACACIAAAEyAqoAAwAHAAA3ESERJzMRIyIBEO7MzAACqv1WIgJmAAAAAgAdAAACIALbABsAHwAAARUjByM3IwcjNyM1MzcjNTM3MwczNzMHMxUjByMzNyMB/4AmSCZrJ0knZnQjdoQkSSVrJkkmYnAitWwkbAEUR83Nzc1HuUjGxsbGSLm5AAAAAQAkAKQB3gI2ABEAABM3FyczBzcXBxcHJxcjNwcnNyQumSJzJZkun58umSRyIZguoAGXZ26mpGpmKClma6anbWYqAAABAEMAkwH6AkoACwAAARUjNSM1MzUzFTMVAUNKtrZKtwFKt7dJt7dJAAAAAAEAGgFCASQBrQADAAATNSEVGgEKAUJrawAAAAABAAD/gwEnAwoAAwAAFycTM0pK30h9AQOGAAAAAgAj//YCGgLmABMAJwAAARQOAiMiLgI1ND4CMzIeAgUUHgIzMj4CNTQuAiMiDgICGhw9X0NGYDwaGjxgR0JfPRz+qAgUJB0cJBUHBxQkHB0kFQgBb1WLYzY2Y4xVVYpiNTVii1VKc08qKk9zSklzTykpT3MAAAAAAQArAAACCgLfACEAADc1MzI+AjURDgMjIi4CNT4DPwEzERQeAjsBFWRUDRMNBhQiIB8PDRUQChAiJiwaSHIFCxUQUgA3Bg8aEwIBGCccDwoUHBEEDBIbEjX9mhAZEQg3AAAAAAEAJAAAAg4C5gArAAABFA4EDwEzMjY/ATMHITU3PgM1NCYjIgYVIi4CNTQ+AjMyHgIB9AsYKDtPM2fvHy0JCD0G/hyYLz0jDiomNCodMCMTHThUODpXPB4CPBgtMDZATjFhJCMf12qaMU5HRSg6NllYCxgnGxwyJhcYLD8AAAAAAQAd//YCDgLmAEQAABciLgI1ND4CMxQeAjMyPgI1NC4CKwE1MzI+AjU0JiMiDgIVIiY1ND4CMzIeAhUUDgIHHgMVFA4C+TpTNhkOGB8SEiEvHBktIxUVKDsnP0MhMSAQKyobIxMHQEUdOVQ4N1c+IRgqOSIfQTUiL01kChQiLRgTHhUKITEhEA4iOiweMSMUQBUoOCE4PxstOR4tLxsvJBQWKz4oIzouIgwFGSo/LD5VNBYAAgAOAAACKQLbABgAIwAAJRUUHgI7ARUhNTMyPgI9ASE1ATMRMxUlNDY3DgMPATMBvw0XHxEN/pkcEh5XDf7lASKPav8AAwQFFhkXBorUvz8YHQ8FNzcFDx0YPz4B3v4nQ/YtaDAMKiwoCeUAAQAp//YCBgLbADoAADcyPgI1NCYjIg4CBycTIRcjJy4DKwEUDgIPAT4DMzIeAhUUDgIjIi4CNTQ2MxQeAuwZLiIVSUMTIBsYCy8gAYQFOwgCBgsQDNUCAgMBCAgZHiIPPGBFJTBNXy85UDIXLSUMGis+ECVAL0xLAwUHAxIBYrojCQ4KBgEQGyISXgMGBAMcNlI3Q1o3GBUiLRgkIxYsIxYAAAACAC7/9gIZAuYALAA8AAABIg4CBz4DMzIeAhUUDgIjIi4CNTQ+AjMyHgIVFA4CIzQuAgMiDgIHFB4CMzI2NTQmAUkeMSMVAwobIysaL0s2HR48WDs5XUMlJEhuSjJFKxMNHS4iBg8bNw4fHBgGEh5pFygtMgKpJEVkQQcNCwcdN04yN1tBJCpWg1lVk20/EyAoFhAdFg0XLyYY/tkIDhIJSWpEIFBZU0wAAAAAAQAtAAACGwLbAAsAADcBISIGDwEjNyEVAakBEf7yHBwDBj4FAen+5QACbBsZNNcy/VcAAAMAH//2Ah5C5gAlADkATQAANzQ+AjcuATU0PgIzMh5CFRQOAgceAxUUDgIjIi4CFzI+AjU0LgInDgMVFB4CEzQuAiMiDgIVFB4CFz4DHxUoOCE9QRg4W0I2UjcbEyQzIC5BKBMkQ2E+QF4+Hf4aKx4QESU4KBEeFQ0RHit6DBgkFxUhFgsOHCkbExsSCLshNSslESNaPCRDNCAbMEInHi8nIRAXLTI2HzFLNBwfNUhiEyIvHBkpIyISCx0jLBseMiMUAgQWKyEUER8qGBsoIBkNCxkgKAAAAAIAJP/2Ag8C5gAoADYAABciLgI1NDY3HgMzMjY3DgMjIi4CNTQ+AjMyHgIVFA4CAzI2NzQuAiMiBhUUFukvQCgRGBoHFR4nGkVKBQwdJS0aLEo1HiA9Vzc3XkUmIUdvHyU1DxEcKBgsMDAKFCAqFhYfBRcoHRGVkw8ZEwobNk80N1tCJChUglpVlG9AAW4lH0JePB1WV0dJAAAAAAEAAAABAACt4Ie1Xw889QALBAAAAAAA2XTOiAAAAADZdM6IAAD/gwIpAwoAAAAIAAIAAAAAAAAAAQAAAyz/LABcAj0AAAAAAikAAQAAAAAAAAAAAAAAAAAAAAcBdgAiAj0AHQICACQCPQBDAT4AGgEnAAACPQAjACsAJAAdAA4AKQAuAC0AHwAkAAAAAAAUAEQAZgB8AIoAmADUAQYBRgGgAdYCKAJ+ApgDBANSAAAAAQAAABAATgADAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAwAlgABAAAAAAABAA0AAAABAAAAAAACAAYADQABAAAAAAADAA0AEwABAAAAAAAEAA0AIAABAAAAAAAFAB4ALQABAAAAAAAGAA0ASwADAAEECQABABoAWAADAAEECQACAAwAcgADAAEECQADABoAfgADAAEECQAEABoAmAADAAEECQAFADwAsgADAAEECQAGABoA7kxlZVRyZWVzaGFkb3dNZWRpdW1MZWVUcmVlc2hhZG93TGVlVHJlZXNoYWRvd1ZlcnNpb24gMS4wOyBGb250RWRpdG9yICh3MS4wKUxlZVRyZWVzaGFkb3cATABlAGUAVAByAGUAZQBzAGgAYQBkAG8AdwBNAGUAZABpAHUAbQBMAGUAZQBUAHIAZQBlAHMAaABhAGQAbwB3AEwAZQBlAFQAcgBlAGUAcwBoAGEAZABvAHcAVgBlAHIAcwBpAG8AbgAgADEALgAwADsAIABGAG8AbgB0AEUAZABpAHQAbwByACAAKAB2ADEALgAwACkATABlAGUAVAByAGUAZQBzAGgAYQBkAG8AdwAAAAIAAAAAAAAAMgAAAAAAAAAAAAAAAAAAAAAAAAAAABAAEAAAAAYADQAOABAAEgECAQMBBAEFAQYBBwEIAQkBCgELBHplcm8Db25lA3R3bwV0aHJlZQRmb3VyBGZpdmUDc2l4BXNldmVuBWVpZ2h0BG5pbmU=' with open('font.ttf', 'wb') as f: f.write(base64.decodebytes(b64_code.encode())) from fontTools.ttLib import TTFont # 导包 font = TTFont('font.ttf') font.saveXML('font.xml')
# 简单封装下
import base64
def w_tff(one_html):
res_tff = re.findall(r';base64,(.*?)"', one_html, re.S)
if res_tff and len(res_tff) == 1:
new_res_ttf = res_tff[0]
with open('123_new_ttf.ttf', 'wb') as f:
f.write(base64.decodebytes(new_res_ttf.encode()))读取文件找到里面的对应关系,就是 你这个数字的格式 是存储在.ttf文件里的.
from fontTools.ttLib import TTFont
def get_num_phone(es_str: str):
# 加载字体生成映射关系
path = '123_new_ttf.ttf'
font = TTFont(path)
# font.saveXML('font.xml') # 生成xml文件
# 得到映射关系
bestcmap = font.getBestCmap()
ss = {}
for key, value in bestcmap.items():
keys = hex(key).replace('0x', '').replace("&#x", "") # 10进制转16进制
if value == "zero":
value = 0
elif value == "one":
value = 1
elif value == "one":
value = 1
elif value == "two":
value = 2
elif value == "three":
value = 3
elif value == "four":
value = 4
elif value == "five":
value = 5
elif value == "six":
value = 6
elif value == "seven":
value = 7
elif value == "eight":
value = 8
elif value == "nine":
value = 9
elif value == "hyphen":
value = "-"
ss.update({
keys: value
})
need_re = es_str
list_phone = ""
try:
for item in need_re.split(";"):
if item:
new_item = item.replace("&#x", "")
list_phone += "".join(str(ss[new_item]))
if not list_phone or len(list_phone) < 2:
return None
return list_phone
except Exception as e:
return None<cmap> <tableVersion version="0"/> <cmap_format_4 platformID="0" platEncID="3" language="0"> <map code="0x23" name="numbersign"/><!-- NUMBER SIGN --> <map code="0x2a" name="asterisk"/><!-- ASTERISK --> <map code="0x2b" name="plus"/><!-- PLUS SIGN --> <map code="0x2d" name="hyphen"/><!-- HYPHEN-MINUS --> <map code="0x2f" name="slash"/><!-- SOLIDUS --> </cmap_format_4> <cmap_format_0 platformID="1" platEncID="0" language="0"> <map code="0x23" name="numbersign"/> <map code="0x2a" name="asterisk"/> <map code="0x2b" name="plus"/> <map code="0x2d" name="hyphen"/> <map code="0x2f" name="slash"/> </cmap_format_0> <cmap_format_4 platformID="3" platEncID="1" language="0"> <map code="0x23" name="numbersign"/><!-- NUMBER SIGN --> <map code="0x2a" name="asterisk"/><!-- ASTERISK --> <map code="0x2b" name="plus"/><!-- PLUS SIGN --> <map code="0x2d" name="hyphen"/><!-- HYPHEN-MINUS --> <map code="0x2f" name="slash"/><!-- SOLIDUS --> </cmap_format_4> <cmap_format_12 platformID="3" platEncID="10" format="12" reserved="0" length="76" language="0" nGroups="5"> <map code="0x23" name="numbersign"/><!-- NUMBER SIGN --> <map code="0x2a" name="asterisk"/><!-- ASTERISK --> <map code="0x2b" name="plus"/><!-- PLUS SIGN --> <map code="0x2d" name="hyphen"/><!-- HYPHEN-MINUS --> <map code="0x2f" name="slash"/><!-- SOLIDUS --> <map code="0x880fb" name="zero"/><!-- ???? --> <map code="0x880fc" name="one"/><!-- ???? --> <map code="0x880fd" name="two"/><!-- ???? --> <map code="0x880fe" name="three"/><!-- ???? --> <map code="0x880ff" name="four"/><!-- ???? --> <map code="0x88100" name="five"/><!-- ???? --> <map code="0x88101" name="six"/><!-- ???? --> <map code="0x88102" name="seven"/><!-- ???? --> <map code="0x88103" name="eight"/><!-- ???? --> <map code="0x88104" name="nine"/><!-- ???? --> </cmap_format_12> </cmap>
读取ttf文件,(再生成xml文件,第一次寻找映射关系是需要做的)
font.getBestCmap() 获取映射关系表
我们观察 xml文件的cmap段进行研究 ,可以看到我们明确需要的结果
keys = hex(key).replace('0x', '').replace("&#x", "") 10进制转16进制 ,会得到映射关系表 {'23': 'numbersign', '2a': 'asterisk', '2b': 'plus', '2d': '-', '2f': 'slash', '8826e': 0, '8826f': 1, '88270': 2, '88271': 3, '88272': 4, '88273': 5, '88274': 6, '88275': 7, '88276': 8, '88277': 9}
和从页面上那些来的结果 进行 逐个匹配调整就行了.
webdriver拿下来的页面源码有可能有点问题,所以我用了 soup_text = bs4.BeautifulSoup(driver.page_source, 'lxml').text 的方法来处理源代码 (import bs4)其他的就是一些小细节上的问题了.基本的思路就是这样的.
读到这里,这篇“python爬虫字体加密问题怎么解决”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。