жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҲ©з”ЁpythonжҖҺд№ҲзҲ¬еҸ–жҠ–йҹізҡ„иҜ„и®әж•°жҚ®пјҹзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
python3 дёӢиҪҪ
fiddle е®үиЈ…еҸҠй…ҚзҪ®
жүӢжңәжЁЎжӢҹеҷЁдёӢиҪҪ
жЁЎжӢҹеҷЁдёӢиҪҪеҘҪд№ӢеҗҺ, жү“ејҖжЁЎжӢҹеҷЁ
еңЁеә”з”ЁеёӮеңәдёӢиҪҪжҠ–йҹі

еҜ№жҠ–йҹіиҝӣиЎҢfiddleй…ҚзҪ®пјҢй…ҚзҪ®жҲҗеҠҹеҗҺе°ұеҸҜд»ҘеҪ“жүӢжңәдёҖж ·дҪҝз”ЁдәҶ
жҲ‘们йҡҸдҫҝжү“ејҖдёҖдёӘи§Ҷйў‘д№ӢеҗҺпјҢfiddleе°ұдјҡеҲ·ж–°ж–°зҡ„ж•°жҚ®еҢ…
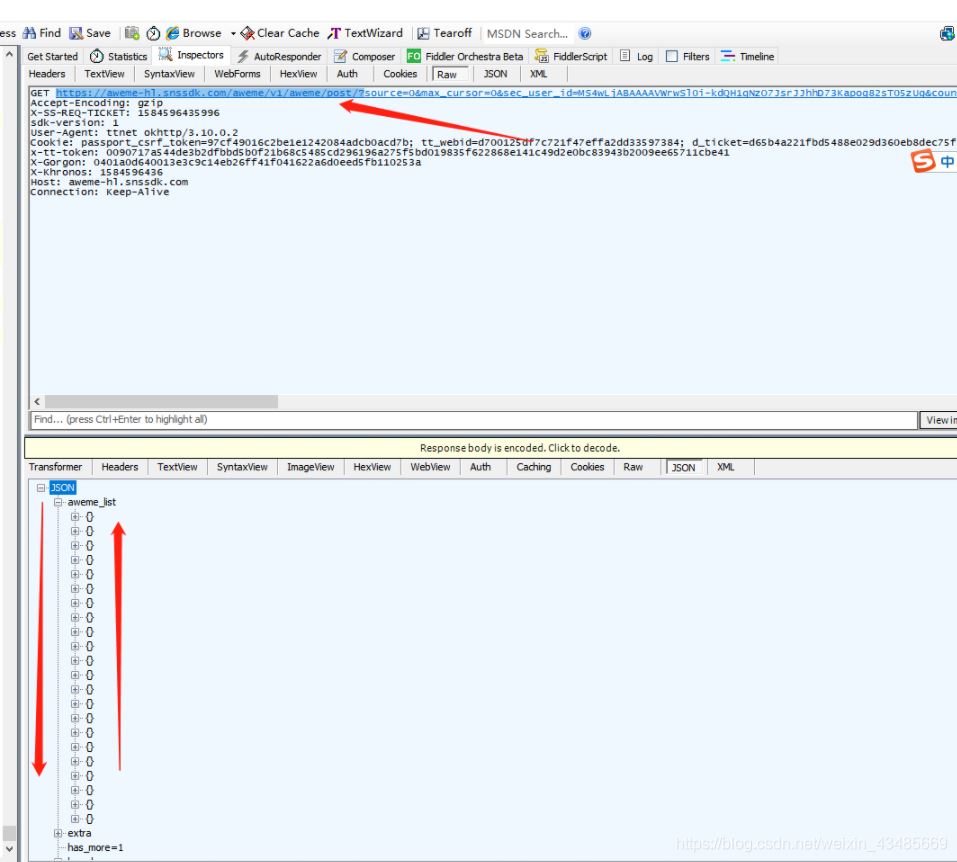
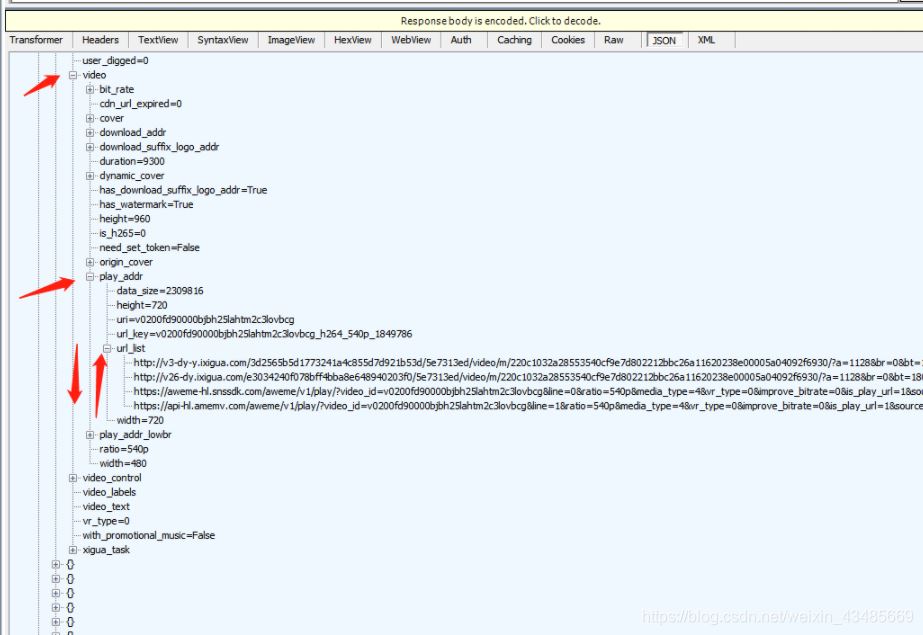
еңЁjsonдёӯжүҫеҲ°и§Ҷйў‘ең°еқҖпјҡ
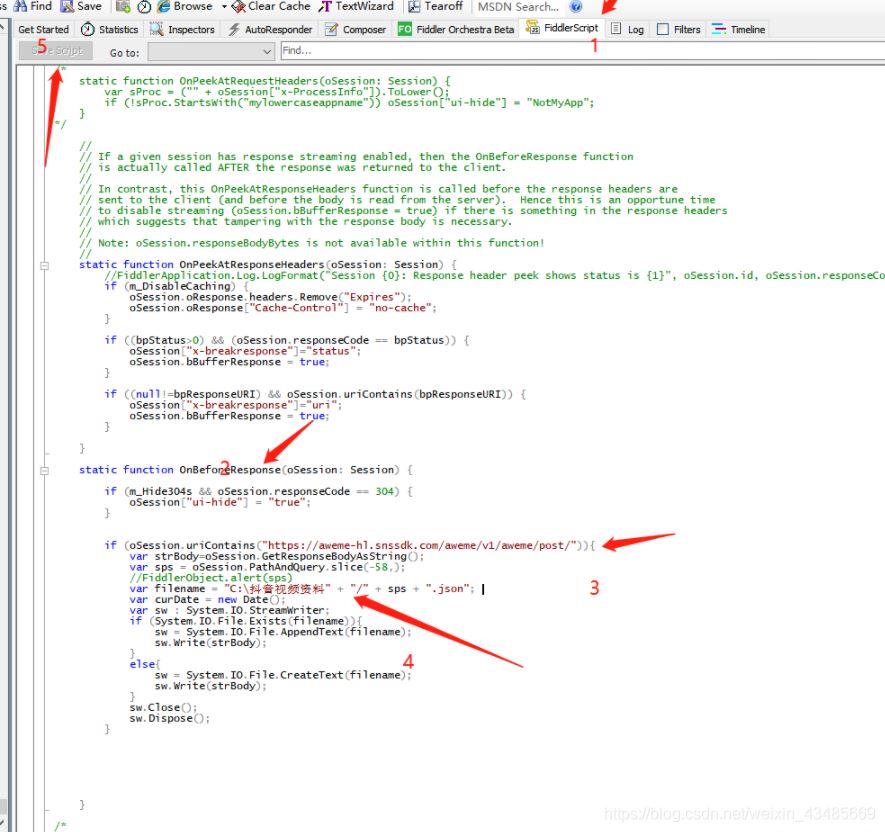
еңЁfiddlerдёӯж·»еҠ дёӢиҪҪи§Ҷйў‘д»Јз ҒпјҡжіЁж„ҸдёӨзӮ№пјҡ
пјҲ1пјүgetеҗҺйқўзҡ„и·Ҝеҫ„иҰҒйҡҸж—¶зңӢиҝӣиЎҢжӣҙжҚў
пјҲ2пјүдёӢиҪҪзҡ„и·Ҝеҫ„иҰҒеңЁfiddlerдёӢйқўиҮӘе·ұж–°е»ә
if (m_Hide304s && oSession.responseCode == 304) {
oSession["ui-hide"] = "true";
}
if (oSession.uriContains("https://aweme.snssdk.com/aweme/v1/general/search/single/")){
var strBody=oSession.GetResponseBodyAsString();
var sps = oSession.PathAndQuery.slice(-58,);
//FiddlerObject.alert(sps)
var timestamp=new Date().getTime();
var filename = "D:\жҠ–йҹіиҜ„и®әиө„ж–ҷ" + "/" + sps + timestamp + ".json";
var curDate = new Date();
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(strBody);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(strBody);
}
sw.Close();
sw.Dispose();жӯӨж®өд»Јз Ғж”ҫеҲ°fiddlerдёӯзҡ„scriptзҡ„responseдёӯпјҢеҰӮдёӢеӣҫпјҡж·»еҠ еҘҪд№ӢеҗҺеҲ«еҝҳи®°дҝқеӯҳпјҒпјҒ
зЁӢеәҸжү§иЎҢд»Јз Ғпјҡ
import os
import json
import time
import requests
import re
import csv
class Douyin(object):
def __init__(self):
pass
self.url1 = 'https://aweme.snssdk.com/aweme/v2/comment/list/?aweme_id=6885929189950737676&cursor=0&count=20&address_book_access=1&gps_access=1&forward_page_type=1&channel_id=0&city=310000&hotsoon_filtered_count=0&hotsoon_has_more=0&follower_count=0&is_familiar=0&page_source=0&os_api=25&device_type=VOG-AL00&ssmix=a&manifest_version_code=110301&dpi=240&uuid=868594157367551&app_name=aweme&version_name=11.3.0&ts=1603350069&cpu_support64=false&app_type=normal&ac=wifi&host_abi=armeabi-v7a&channel=aweGW&update_version_code=11309900&_rticket=1603350070959&device_platform=android&iid=1758845207590062&version_code=110300&mac_address=b0%3Ac4%3A2d%3Ad0%3Aed%3A38&cdid=7974198e-c4c0-49c2-bfaa-43686052706e&openudid=d0c6cffa7067bedd&device_id=844047245117672&resolution=720*1280&device_brand=HUAWEI&language=zh&os_version=7.1.2&aid=1128&mcc_mnc=46000'
self.url2 = 'https://aweme.snssdk.com/aweme/v2/comment/list/?aweme_id=6885163969477086479&cursor=0&count=20'
self.header = {
'Accept-Encoding': 'gzip',
'X-SS-REQ-TICKET': '1603350070957',
'sdk-version': '1',
'Cookie': 'install_id=1758845207590062; ttreq=1$34f012b99d70a66f681dc3d1f0b438fc1b161af3; d_ticket=77247c94236bf8055c233f8cabb6a5ddf3231; odin_tt=fccb20add45a15f08a2519eadcaaf22cba4b3f8f1fceec300a088407c2daf81ea76b260ef6c81dbc86dfedfea011f68c25238f9b3984fe4f5909441dfd1cc9c2; sid_guard=6de18a966e69dcbbf076f629a2ef6511%7C1603345424%7C5184000%7CMon%2C+21-Dec-2020+05%3A43%3A44+GMT; uid_tt=ba98af780b4e337f01463cf98a8afafd; sid_tt=6de18a966e69dcbbf076f629a2ef6511; sessionid=6de18a966e69dcbbf076f629a2ef6511',
'x-tt-token': '006de18a966e69dcbbf076f629a2ef651189d3f6f73fd3d6319b543d50d2e2e5a4cf3e383f8da81f07e049bcf850de07d331',
'X-Gorgon': '0404d8210000a6a3dca0dbc6b11483a82420c9a94dd050a3e511',
'X-Khronos': '1603350070',
'Host': 'aweme.nssdk.com',
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36',
}
self.add = 'D:\жҠ–йҹіиҜ„и®әиө„ж–ҷ'
self.videos_list = os.listdir('D:\жҠ–йҹіиҜ„и®әиө„ж–ҷ')
def parse(self):
'й“ҫжҺҘ,еҶ…е®№,еҸ‘еёғдәәжҳөз§°пјҢеҸ‘еёғж—¶й—ҙпјҢзӮ№иөһж•°пјҢиҜ„и®әж•°пјҢеҲҶдә«ж•°'
lists = []
for vid in self.videos_list:
a = open('D:\жҠ–йҹіиҜ„и®әиө„ж–ҷ\{}'.format(vid),encoding='utf-8')
content = json.load(a)
for con in content['data']:
meta = {}
try:
meta['title'] = con['aweme_info']['desc']
meta['author_name'] = con['aweme_info']['author']['nickname']
meta['u_name'] = con['aweme_info']['author']['unique_id']
meta['create_time'] = con['aweme_info']['create_time']
timeArray = time.localtime(meta['create_time'])
meta['create_time'] = time.strftime("%Y--%m--%d %H:%M:%S", timeArray)
meta['digg_count'] = con['aweme_info']['statistics']['digg_count']
meta['comment_count'] = con['aweme_info']['statistics']['comment_count']
meta['share_count'] = con['aweme_info']['statistics']['share_count']
meta['share_url'] = con['aweme_info']['share_url']
except:
meta['title'] = ''
meta['author_name'] = ''
meta['u_name'] = ''
meta['create_time'] = ''
meta['digg_count'] = ''
meta['comment_count'] = ''
meta['share_count'] = ''
meta['share_url'] = ''
if meta['u_name'] == '':
try:
meta['u_name'] = con['aweme_info']['music']['owner_handle']
except:
meta['u_name'] = ''
if meta['title'] == '':
pass
else:
lists.append(meta)
# print(meta)
return lists
def save_data(self, meta):
header = ['share_url', 'title', 'author_name', 'u_name', 'create_time', 'digg_count', 'comment_count', 'share_count']
print(meta)
with open('test.csv', 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=header)
writer.writeheader() # еҶҷе…ҘеҲ—еҗҚ
writer.writerows(meta)
def run(self):
meta = self.parse()
self.save_data(meta)
if __name__ == '__main__':
douyin = Douyin()
douyin.run()иҝҗиЎҢд»Јз ҒеҗҺеңЁд»Јз Ғжү§иЎҢзӣ®еҪ•дёӢдјҡз”ҹжҲҗдёҖдёӘexcel
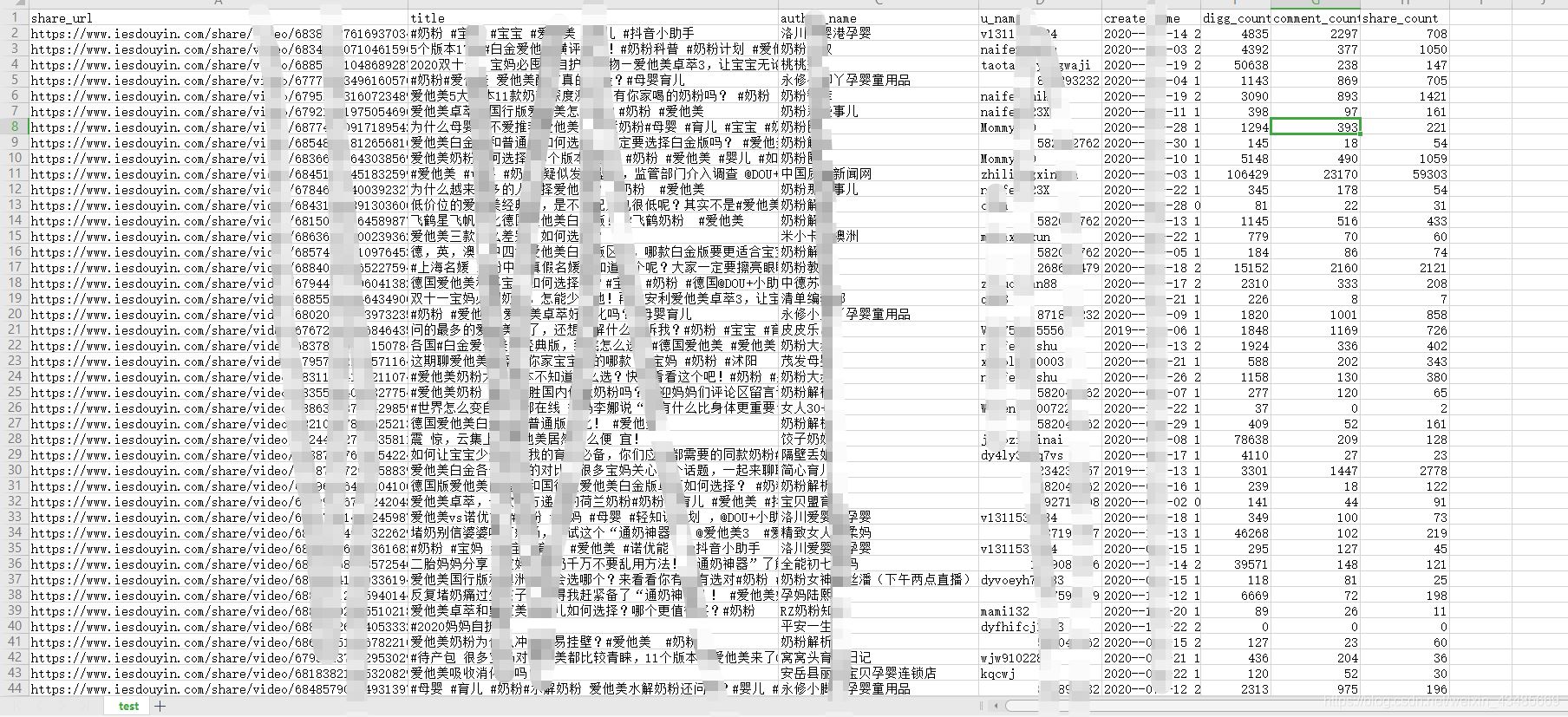
psпјҡжҠ–йҹідёҚдјҡдёҖж¬ЎжҖ§иҝ”еӣһж•ҙдёӘиҜ„и®әж•°жҚ®еҢ…пјҢжҜҸж¬ЎеҫҖдёӢж»‘еҠЁиҜ„и®әеҢәдјҡеӨҡеҮә26жқЎиҜ„и®әж•°жҚ®пјҢжҲ‘们е°ұеҸҜд»ҘеҲ©з”ЁжЁЎжӢҹеҷЁиҝӣиЎҢж»‘еҠЁж“ҚдҪңгҖӮ
зӮ№еҮ» жӣҙеӨҡ>йј ж Үе®Ҹ
зӮ№еҮ»еҪ•еұҸд№ӢеҗҺпјҢз”Ёйј ж ҮеҫҖдёӢж»‘еҠЁдёҖж¬ЎйЎөйқў

зӮ№еҮ»еҒңжӯўпјҢе°ұдјҡе°ҶдҪ еҲҡжүҚзҡ„ж“ҚдҪңдҝқеӯҳдёӢжқҘ
зӮ№еҮ»и®ҫзҪ® еҸҜд»ҘеҜ№еҲҡжүҚзҡ„ж“ҚдҪңиҝӣиЎҢеҫӘзҺҜж’ӯж”ҫпјҢд»ҺиҖҢиҫҫеҲ°иҮӘеҠЁеҲ·ж–°иҜ„и®әеҢәгҖӮ

зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎеҲ©з”ЁpythonжҖҺд№ҲзҲ¬еҸ–жҠ–йҹізҡ„иҜ„и®әж•°жҚ®зҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ