жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңз”ЁFP-growthз®—жі•жһ„е»әFPж ‘вҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁз”ЁFP-growthз®—жі•жһ„е»әFPж ‘й—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқз”ЁFP-growthз®—жі•жһ„е»әFPж ‘вҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
гҖҖгҖҖFPд»ЈиЎЁйў‘з№ҒжЁЎејҸпјҲFrequent Pattern)пјҢз®—жі•дё»иҰҒеҲҶдёәдёӨдёӘжӯҘйӘӨпјҡFP-treeжһ„е»әгҖҒжҢ–жҺҳйў‘з№ҒйЎ№йӣҶгҖӮ
гҖҖгҖҖFPж ‘йҖҡиҝҮйҖҗдёӘиҜ»е…ҘдәӢеҠЎпјҢ并жҠҠдәӢеҠЎжҳ е°„еҲ°FPж ‘дёӯзҡ„дёҖжқЎи·Ҝеҫ„жқҘжһ„йҖ гҖӮз”ұдәҺдёҚеҗҢзҡ„дәӢеҠЎеҸҜиғҪдјҡжңүиӢҘе№ІдёӘзӣёеҗҢзҡ„йЎ№пјҢеӣ жӯӨе®ғ们зҡ„и·Ҝеҫ„еҸҜиғҪйғЁеҲҶйҮҚеҸ гҖӮи·Ҝеҫ„зӣёдә’йҮҚеҸ и¶ҠеӨҡпјҢдҪҝз”ЁFPж ‘з»“жһ„иҺ·еҫ—зҡ„еҺӢзј©ж•Ҳжһңи¶ҠеҘҪпјӣеҰӮжһңFPж ‘и¶іеӨҹе°ҸпјҢиғҪеӨҹеӯҳж”ҫеңЁеҶ…еӯҳдёӯпјҢе°ұеҸҜд»ҘзӣҙжҺҘд»ҺиҝҷдёӘеҶ…еӯҳдёӯзҡ„з»“жһ„жҸҗеҸ–йў‘з№ҒйЎ№йӣҶпјҢиҖҢдёҚеҝ…йҮҚеӨҚең°жү«жҸҸеӯҳж”ҫеңЁзЎ¬зӣҳдёҠзҡ„ж•°жҚ®гҖӮ
гҖҖгҖҖдёҖйў—FPж ‘еҰӮдёӢеӣҫжүҖзӨәпјҡ
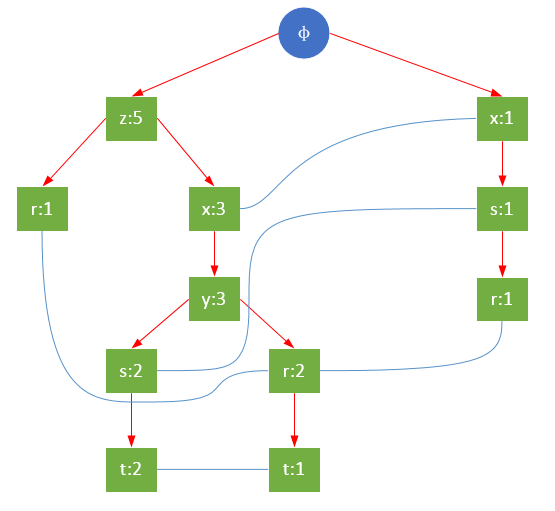
гҖҖгҖҖйҖҡеёёпјҢFPж ‘зҡ„еӨ§е°ҸжҜ”жңӘеҺӢзј©зҡ„ж•°жҚ®е°ҸпјҢеӣ дёәж•°жҚ®зҡ„дәӢеҠЎеёёеёёе…ұдә«дёҖдәӣе…ұеҗҢйЎ№пјҢеңЁжңҖеҘҪзҡ„жғ…еҶөдёӢпјҢжүҖжңүзҡ„дәӢеҠЎйғҪе…·жңүзӣёеҗҢзҡ„йЎ№йӣҶпјҢFPж ‘еҸӘеҢ…еҗ«дёҖжқЎиҠӮзӮ№и·Ҝеҫ„пјӣеҪ“жҜҸдёӘдәӢеҠЎйғҪе…·жңүе”ҜдёҖйЎ№йӣҶж—¶пјҢеҜјиҮҙжңҖеқҸжғ…еҶөеҸ‘з”ҹпјҢз”ұдәҺдәӢеҠЎдёҚеҢ…еҗ«д»»дҪ•е…ұеҗҢйЎ№пјҢFPж ‘зҡ„еӨ§е°Ҹе®һйҷ…дёҠдёҺеҺҹж•°жҚ®зҡ„еӨ§е°ҸдёҖж ·гҖӮ
гҖҖгҖҖFPж ‘зҡ„ж №иҠӮзӮ№з”ЁПҶиЎЁзӨәпјҢе…¶дҪҷиҠӮзӮ№еҢ…жӢ¬дёҖдёӘж•°жҚ®йЎ№е’ҢиҜҘж•°жҚ®йЎ№еңЁжң¬и·Ҝеҫ„дёҠзҡ„ж”ҜжҢҒеәҰпјӣжҜҸжқЎи·Ҝеҫ„йғҪжҳҜдёҖжқЎи®ӯз»ғж•°жҚ®дёӯж»Ўи¶іжңҖе°Ҹж”ҜжҢҒеәҰзҡ„ж•°жҚ®йЎ№йӣҶпјӣFPж ‘иҝҳе°ҶжүҖжңүзӣёеҗҢйЎ№иҝһжҺҘжҲҗй“ҫиЎЁпјҢдёҠеӣҫдёӯз”Ёи“қиүІиҝһзәҝиЎЁзӨәгҖӮ
гҖҖгҖҖдёәдәҶеҝ«йҖҹи®ҝй—®ж ‘дёӯзҡ„зӣёеҗҢйЎ№пјҢиҝҳйңҖиҰҒз»ҙжҠӨдёҖдёӘиҝһжҺҘе…·жңүзӣёеҗҢйЎ№зҡ„иҠӮзӮ№зҡ„жҢҮй’ҲеҲ—иЎЁпјҲheadTableпјүпјҢжҜҸдёӘеҲ—иЎЁе…ғзҙ еҢ…жӢ¬пјҡж•°жҚ®йЎ№гҖҒиҜҘйЎ№зҡ„е…ЁеұҖжңҖе°Ҹж”ҜжҢҒеәҰгҖҒжҢҮеҗ‘FPж ‘дёӯиҜҘйЎ№й“ҫиЎЁзҡ„иЎЁеӨҙзҡ„жҢҮй’ҲгҖӮ
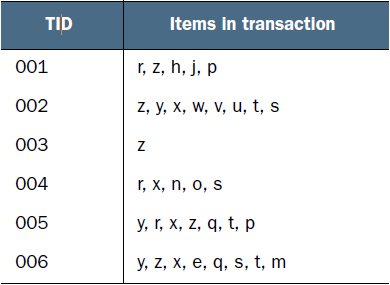
гҖҖгҖҖзҺ°еңЁжңүеҰӮдёӢж•°жҚ®пјҡ
 гҖҖгҖҖ
гҖҖгҖҖ
FP-growthз®—жі•йңҖиҰҒеҜ№еҺҹе§Ӣи®ӯз»ғйӣҶжү«жҸҸдёӨйҒҚд»Ҙжһ„е»әFPж ‘гҖӮ
гҖҖгҖҖ第дёҖж¬Ўжү«жҸҸпјҢиҝҮж»ӨжҺүжүҖжңүдёҚж»Ўи¶іжңҖе°Ҹж”ҜжҢҒеәҰзҡ„йЎ№пјӣеҜ№дәҺж»Ўи¶іжңҖе°Ҹж”ҜжҢҒеәҰзҡ„йЎ№пјҢжҢүз…§е…ЁеұҖжңҖе°Ҹж”ҜжҢҒеәҰжҺ’еәҸпјҢеңЁжӯӨеҹәзЎҖдёҠпјҢдёәдәҶеӨ„зҗҶж–№дҫҝпјҢд№ҹеҸҜд»ҘжҢүз…§йЎ№зҡ„е…ій”®еӯ—еҶҚж¬ЎжҺ’еәҸгҖӮ

第дёҖж¬Ўжү«жҸҸзҡ„еҗҺзҡ„з»“жһң
гҖҖгҖҖ第дәҢж¬Ўжү«жҸҸпјҢжһ„йҖ FPж ‘гҖӮ
гҖҖгҖҖеҸӮдёҺжү«жҸҸзҡ„жҳҜиҝҮж»ӨеҗҺзҡ„ж•°жҚ®пјҢеҰӮжһңжҹҗдёӘж•°жҚ®йЎ№жҳҜ第дёҖж¬ЎйҒҮеҲ°пјҢеҲҷеҲӣе»әиҜҘиҠӮзӮ№пјҢ并еңЁheadTableдёӯж·»еҠ дёҖдёӘжҢҮеҗ‘иҜҘиҠӮзӮ№зҡ„жҢҮй’ҲпјӣеҗҰеҲҷжҢүи·Ҝеҫ„жүҫеҲ°иҜҘйЎ№еҜ№еә”зҡ„иҠӮзӮ№пјҢдҝ®ж”№иҠӮзӮ№дҝЎжҒҜгҖӮе…·дҪ“иҝҮзЁӢеҰӮдёӢжүҖзӨәпјҡ
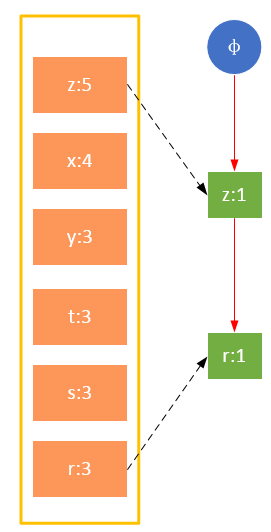
дәӢеҠЎ001пјҢ{z,x}
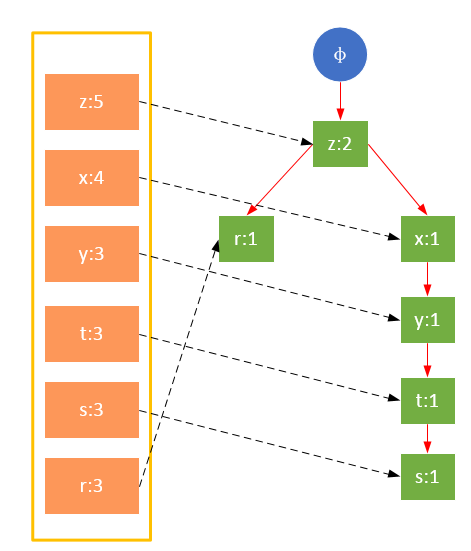
дәӢеҠЎ002пјҢ{z,x,y,t,s}
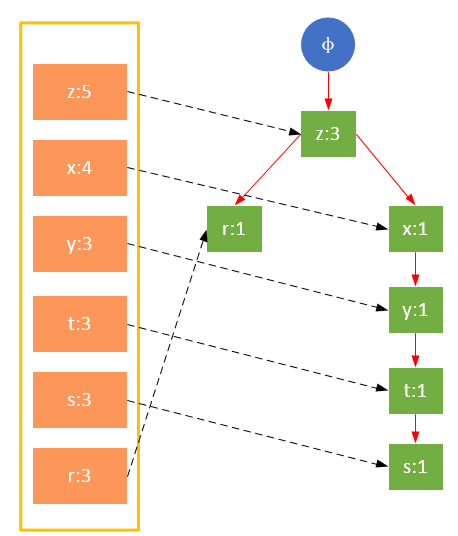
дәӢеҠЎ003пјҢ{z}
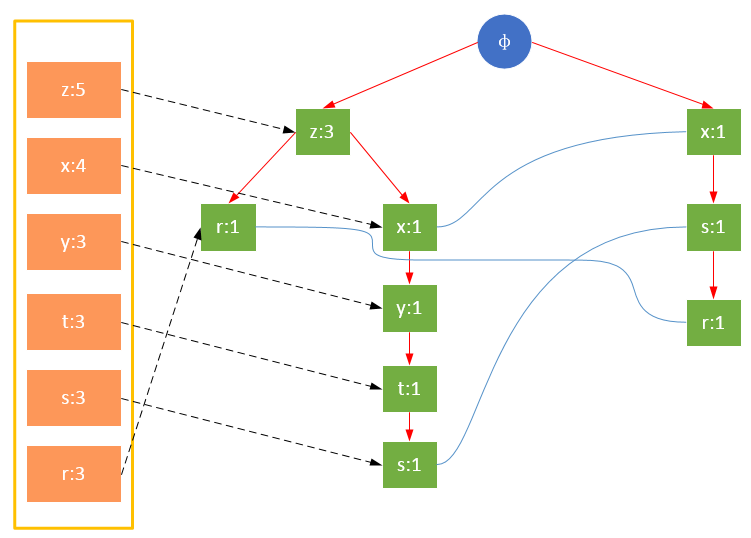
дәӢеҠЎ004пјҢ{x,s,r}
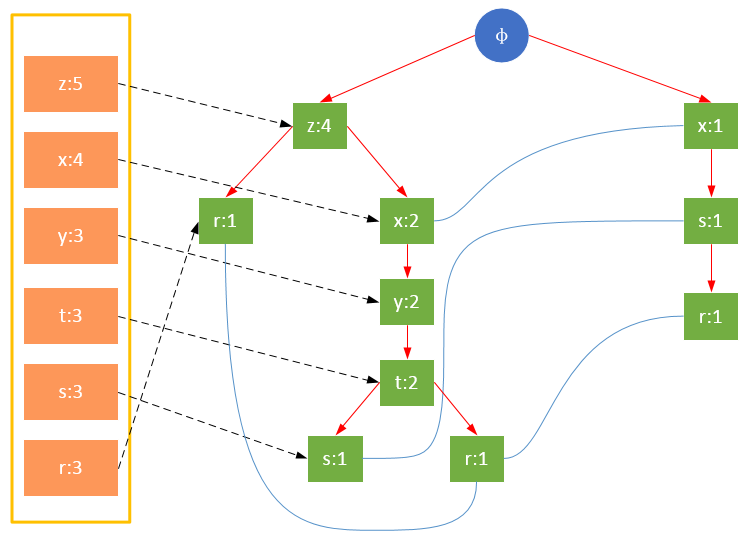
дәӢеҠЎ005пјҢ{z,x,y,t,r}
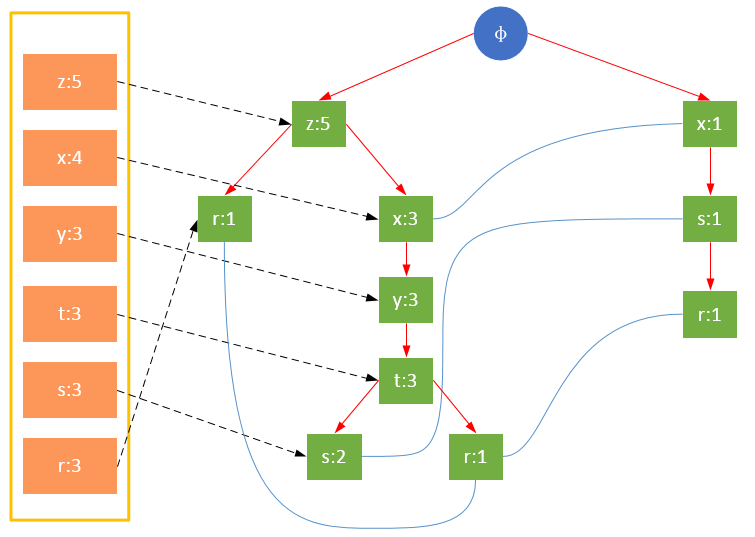
дәӢеҠЎ006пјҢ{z,x,y,t,s}
гҖҖгҖҖд»ҺдёҠйқўеҸҜд»ҘзңӢеҮәпјҢheadTable并дёҚжҳҜйҡҸзқҖFPTreeдёҖиө·еҲӣе»әпјҢиҖҢжҳҜеңЁз¬¬дёҖж¬Ўжү«жҸҸж—¶е°ұе·Із»ҸеҲӣе»әе®ҢжҜ•пјҢеңЁеҲӣе»әFPTreeж—¶еҸӘйңҖиҰҒе°ҶжҢҮй’ҲжҢҮеҗ‘зӣёеә”иҠӮзӮ№еҚіеҸҜгҖӮд»ҺдәӢеҠЎ004ејҖе§ӢпјҢйңҖиҰҒеҲӣе»әиҠӮзӮ№й—ҙзҡ„иҝһжҺҘпјҢдҪҝдёҚеҗҢи·Ҝеҫ„дёҠзҡ„зӣёеҗҢйЎ№иҝһжҺҘжҲҗй“ҫиЎЁгҖӮ
гҖҖгҖҖд»Јз ҒеҰӮдёӢпјҡ
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
fset = frozenset(trans)
retDict.setdefault(fset, 0)
retDict[fset] += 1
return retDict
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
self.parent = parentNode
self.children = {}
def inc(self, numOccur):
self.count += numOccur
def disp(self, ind=1):
print(' ' * ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind + 1)
def createTree(dataSet, minSup=1):
headerTable = {}
#жӯӨдёҖж¬ЎйҒҚеҺҶж•°жҚ®йӣҶпјҢ и®°еҪ•жҜҸдёӘж•°жҚ®йЎ№зҡ„ж”ҜжҢҒеәҰ
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + 1
#ж №жҚ®жңҖе°Ҹж”ҜжҢҒеәҰиҝҮж»Ө
lessThanMinsup = list(filter(lambda k:headerTable[k] < minSup, headerTable.keys()))
for k in lessThanMinsup: del(headerTable[k])
freqItemSet = set(headerTable.keys())
#еҰӮжһңжүҖжңүж•°жҚ®йғҪдёҚж»Ўи¶іжңҖе°Ҹж”ҜжҢҒеәҰпјҢиҝ”еӣһNone, None
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
headerTable[k] = [headerTable[k], None]
retTree = treeNode('ПҶ', 1, None)
#第дәҢж¬ЎйҒҚеҺҶж•°жҚ®йӣҶпјҢжһ„е»әfp-tree
for tranSet, count in dataSet.items():
#ж №жҚ®жңҖе°Ҹж”ҜжҢҒеәҰеӨ„зҗҶдёҖжқЎи®ӯз»ғж ·жң¬пјҢkey:ж ·жң¬дёӯзҡ„дёҖдёӘж ·дҫӢпјҢvalue:иҜҘж ·дҫӢзҡ„зҡ„е…ЁеұҖж”ҜжҢҒеәҰ
localD = {}
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0]
if len(localD) > 0:
#ж №жҚ®е…ЁеұҖйў‘з№ҒйЎ№еҜ№жҜҸдёӘдәӢеҠЎдёӯзҡ„ж•°жҚ®иҝӣиЎҢжҺ’еәҸ,зӯүд»·дәҺ order by p[1] desc, p[0] desc
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: (p[1],p[0]), reverse=True)]
updateTree(orderedItems, retTree, headerTable, count)
return retTree, headerTable
def updateTree(items, inTree, headerTable, count):
if items[0] in inTree.children: # check if orderedItems[0] in retTree.children
inTree.children[items[0]].inc(count) # incrament count
else: # add items[0] to inTree.children
inTree.children[items[0]] = treeNode(items[0], count, inTree)
if headerTable[items[0]][1] == None: # update header table
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1: # call updateTree() with remaining ordered items
updateTree(items[1:], inTree.children[items[0]], headerTable, count)
def updateHeader(nodeToTest, targetNode): # this version does not use recursion
while (nodeToTest.nodeLink != None): # Do not use recursion to traverse a linked list!
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
simpDat = loadSimpDat()
dictDat = createInitSet(simpDat)
myFPTree,myheader = createTree(dictDat, 3)
myFPTree.disp()гҖҖгҖҖдёҠйқўзҡ„д»Јз ҒеңЁз¬¬дёҖж¬Ўжү«жҸҸеҗҺ并没жңүе°ҶжҜҸжқЎи®ӯз»ғж•°жҚ®иҝҮж»ӨеҗҺзҡ„йЎ№жҺ’еәҸпјҢиҖҢжҳҜе°ҶжҺ’еәҸж”ҫеңЁдәҶ第дәҢж¬Ўжү«жҸҸж—¶пјҢиҝҷеҸҜд»Ҙз®ҖеҢ–д»Јз Ғзҡ„еӨҚжқӮеәҰгҖӮ
гҖҖгҖҖжҺ§еҲ¶еҸ°дҝЎжҒҜпјҡ

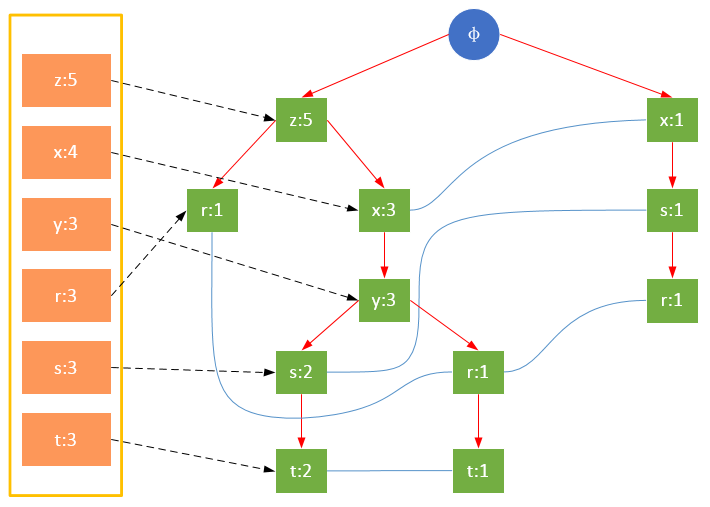
гҖҖгҖҖеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢеҜ№йЎ№зҡ„е…ій”®еӯ—жҺ’еәҸе°ҶдјҡеҪұе“ҚFPж ‘зҡ„з»“жһ„гҖӮдёӢйқўдёӨеӣҫжҳҜзӣёеҗҢи®ӯз»ғйӣҶз”ҹжҲҗзҡ„FPж ‘пјҢеӣҫ1йҷӨдәҶжҢүз…§жңҖе°Ҹж”ҜжҢҒеәҰжҺ’еәҸеӨ–пјҢжңӘеҜ№йЎ№еҒҡд»»дҪ•еӨ„зҗҶпјӣеӣҫ2еҲҷе°ҶйЎ№жҢүз…§е…ій”®еӯ—иҝӣиЎҢдәҶйҷҚеәҸжҺ’еәҸгҖӮж ‘зҡ„з»“жһ„д№ҹе°ҶеҪұе“ҚеҗҺз»ӯеҸ‘зҺ°йў‘з№ҒйЎ№зҡ„з»“жһңгҖӮ
еӣҫ1 жңӘеҜ№йЎ№зҡ„е…ій”®еӯ—жҺ’еәҸ
еӣҫ2 еҜ№йЎ№зҡ„е…ій”®еӯ—йҷҚеәҸжҺ’еәҸ
еҲ°жӯӨпјҢе…ідәҺвҖңз”ЁFP-growthз®—жі•жһ„е»әFPж ‘вҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ